




目录
选题意义背景
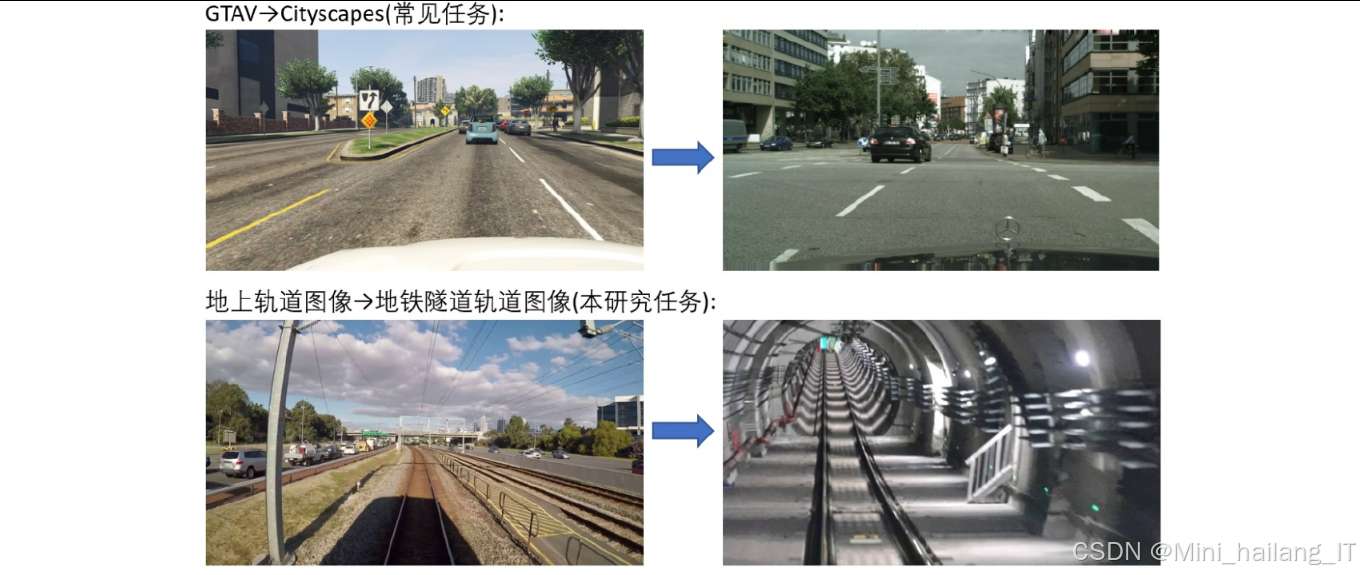
随着城市化进程的加速和公共交通需求的增长,地铁作为一种高效、安全的城市轨道交通方式,在现代城市交通体系中扮演着越来越重要的角色。为了进一步提升地铁运行的安全性、效率和智能化水平,地铁无人驾驶技术成为当前轨道交通领域的研究热点。轨道线分割作为地铁无人驾驶环境感知系统中的基础任务,其准确性和实时性直接影响到列车的定位、导航和路径规划等关键功能,对于保障地铁运行安全具有重要意义。
地铁轨道线分割任务具有独特的挑战性。首先,地铁隧道环境光线昏暗、对比度低,且存在大量金属反光、阴影和噪声干扰,使得轨道线特征提取变得困难。其次,地铁轨道线相比一般道路场景中的车道线更为细小,且在不同场景(如隧道、站台、车辆段等)中表现出较大的形态差异,这对分割模型的精细分割能力提出了更高要求。此外,地铁场景数据获取和标注成本高昂,导致缺乏大规模高质量的标注数据集,这进一步增加了模型训练的难度。

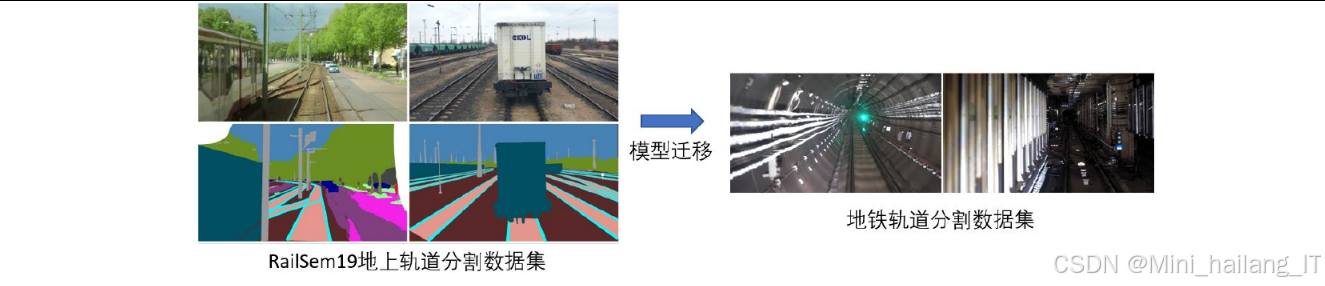
近年来,深度学习技术在计算机视觉领域取得了突破性进展,特别是在语义分割任务中展现出优异的性能。从早期的全卷积网络(FCN)到后来的DeepLab系列、PSPNet、SegFormer等模型,分割精度不断提升。然而,这些模型大多需要大量标注数据进行监督学习,而在地铁场景中获取足够的标注数据往往面临诸多困难。非监督域迁移学习为地铁轨道线分割提供了新的思路。该方法利用已有标注的源域数据(如地上铁路场景)训练模型,然后通过域迁移技术将模型适应到无标注的目标域(地铁隧道场景),从而减少对目标域标注数据的依赖。然而,现有的非监督域迁移方法主要针对城市道路场景设计,对于地上铁路到地铁隧道这种域间差异较大的场景适应性有限。
数据集
数据来源
本研究构建的地铁轨道线分割数据集是目前首个专门针对地铁场景的轨道线分割数据集,数据主要通过以下方式获取:
-
实地采集:研究团队与地铁运营单位合作,在实际地铁线路上使用高分辨率相机(分辨率为1280×720)进行数据采集。采集过程中,相机安装在地铁列车前端,模拟司机视角,确保数据的真实性和实用性。

-
数据筛选与去重:原始采集数据中包含大量重复或质量不佳的图像,研究人员通过以下步骤进行筛选和去重:
- 基于图像相似度计算,去除连续采集的高度相似图像
- 过滤模糊、曝光不足或过曝的图像
- 确保数据集中包含不同场景、不同光照条件下的图像样本
-
数据增强:为了扩充数据集规模和增强模型的泛化能力,研究团队对原始图像进行了多种数据增强操作,包括:
- 水平翻转
- 旋转(±10度范围内)
- 亮度调整
- 对比度变化
数据格式规模
本研究构建的地铁轨道线分割数据集包含5630张图像,具体数据格式和规模如下:
-
图像格式:所有图像均为JPG格式,分辨率统一为1280×720像素,3通道RGB彩色图像。
-
标注格式:采用像素级语义分割标注,每个像素被标记为特定类别。标注文件采用PNG格式,其中每个像素的数值代表其类别标签。

-
数据集分割:为了进行模型训练、验证和测试,数据集按照以下比例进行分割:
- 训练集:4130张图像(约73.4%)
- 验证集:1000张图像(约17.8%)
- 测试集:500张图像(约8.9%)
类别定义
地铁轨道线分割数据集定义了三个类别,分别是:
-
背景类(类别0):包含隧道墙壁、站台设施、轨道周边杂物等非轨道相关区域。
-
列车可行驶区域(类别1):包括铁轨之间的道床区域,是列车车轮实际接触和行驶的区域。
-
铁轨类(类别2):指铁轨本身,包括钢轨、轨枕等轨道核心组件。
需要特别说明的是,在处理RailSem19源域数据集时,研究团队只保留了与本任务相关的轨道和列车可行驶区域类别,将其他类别全部重新标记为背景类,以保证源域和目标域数据的一致性。
数据分割策略
为了确保模型训练的有效性和评估的准确性,本研究采用了以下数据分割策略:
-
场景多样性保证:在数据分割过程中,确保训练集、验证集和测试集中均包含各种典型场景(隧道、站台、车辆段等),避免场景分布不均衡导致的模型过拟合。
-
难度梯度划分:根据图像复杂度和分割难度,将数据样本划分为简单、中等和困难三个等级,并在各数据集中保持适当比例,以全面评估模型性能。
-
时间序列分割:为了避免模型学习到特定序列的特征而非轨道线本身的特征,在分割时确保同一连续序列的图像不会同时出现在训练集和测试集中。
数据预处理
在模型训练前,研究团队对数据进行了一系列预处理操作,以提高模型训练效果:
-
图像归一化:将图像像素值归一化到[0, 1]区间,以加快模型收敛速度。
-
标签权重计算:由于数据集中各类别像素数量分布不均衡(背景类像素远多于前景类),研究团队计算了类别权重,在损失函数中对不同类别赋予不同权重,以平衡训练过程。具体设置为:背景类别权重w₀=1,列车可行驶区域类权重w₁=1,轨道类权重w₂=2。
-
数据增强策略:
- 随机裁剪:从原始图像中随机裁剪512×512大小的区域进行训练,增加模型对不同尺度目标的适应能力
- 随机翻转:以50%的概率对图像进行水平翻转,增强模型的旋转不变性
- 随机旋转:在±10度范围内随机旋转图像,提高模型对轨道线不同角度的识别能力
- 随机亮度/对比度调整:模拟不同光照条件下的图像变化
-
批次数据组织:在非监督域迁移实验中,为了保证模型收敛的稳定性,每个训练批次(mini-batch)由目标域图像和源域图像按1:1比例组成,确保模型在进行域迁移时不会完全忘记源域的特征。
通过以上数据集构建和预处理工作,本研究为地铁轨道线分割任务提供了高质量的训练数据,为后续模型开发和算法验证奠定了坚实基础。该数据集的构建不仅满足了本研究的需求,也为地铁无人驾驶领域的相关研究提供了有价值的数据资源。
功能模块
本研究的地铁轨道线分割系统包含多个核心功能模块,每个模块负责特定的任务,共同构成了完整的分割和域迁移流程。以下是对各功能模块的详细介绍:
基于浅层特征感知的分割网络模块
该模块是整个系统的基础,负责对输入图像进行特征提取和像素级分类。其主要技术思路和实现过程如下:
-
网络架构设计:
- 采用改进的HarDNet作为骨干网络,结合U-Net编码器-解码器结构
- 针对地铁轨道线细小、特征不明显的特点,优化了浅层特征提取部分
- 增加了浅层特征通道数量,增强对轨道线边缘和细节的感知能力
-
特征提取流程:
- 编码器部分:通过多个卷积层和池化层逐步提取图像特征,生成多尺度特征图
- 特征融合:在编码器不同深度提取的特征图被送入特征融合模块,通过跳跃连接与解码器部分的特征进行融合
- 解码器部分:通过上采样和反卷积操作逐步恢复图像分辨率,结合编码器传递的细节信息,生成最终的分割预测图
-
优化策略:
- 针对地铁轨道线的特性,调整了网络各层的卷积核数量分配,增加浅层卷积核数量
- 采用批归一化(Batch Normalization)和ReLU激活函数,加速模型收敛并提高特征表达能力
- 使用带权重的交叉熵损失函数,平衡各类别像素数量不均的问题
该模块在保证分割精度的同时,通过轻量化设计实现了高效推理,能够满足地铁无人驾驶系统对实时性的要求。实验结果表明,改进后的HarDNet模型在地铁轨道线分割数据集上的MIOU达到78.16%,推理速度达到81fps,成功实现了分割精度与计算效率的平衡。
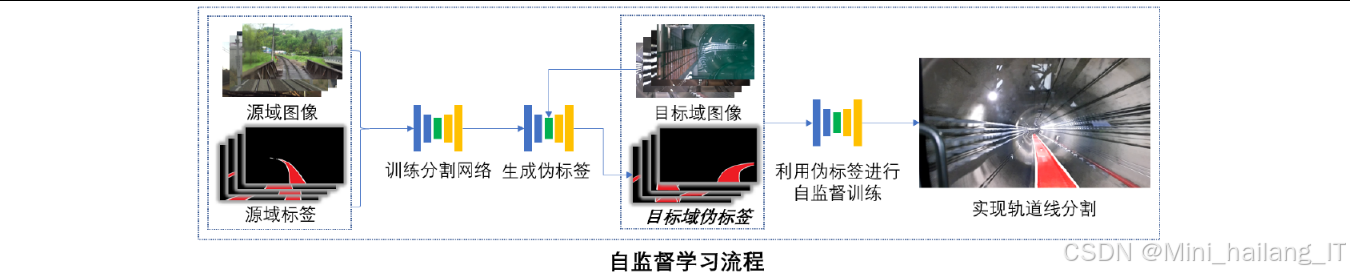
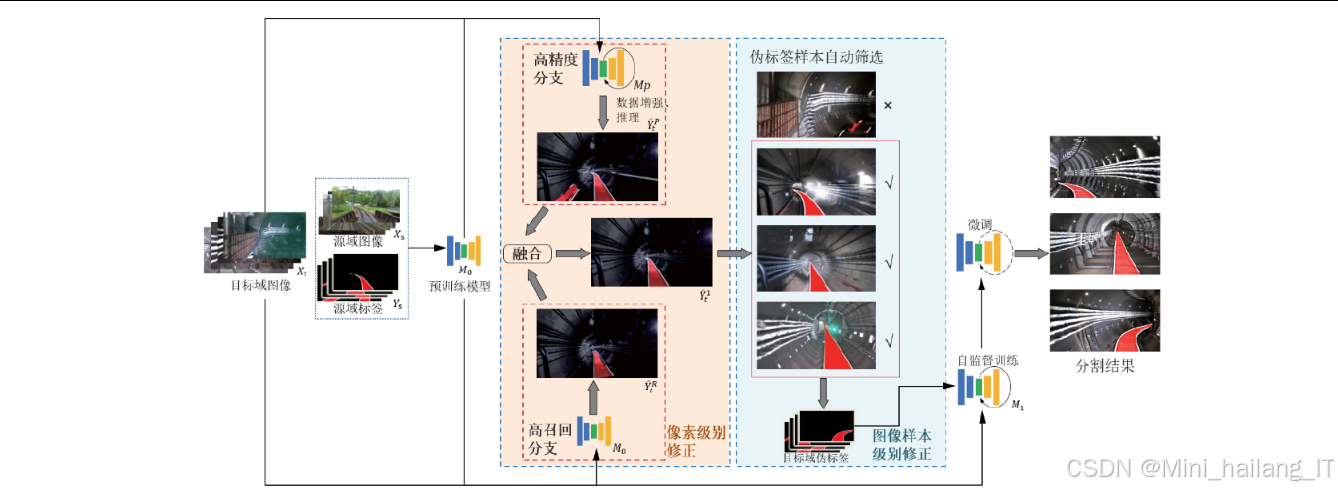
伪标签多级修正模块
该模块针对非监督域迁移过程中伪标签质量差的问题,提出了从微观到宏观的多级修正策略。其技术思路和实现流程如下:
-
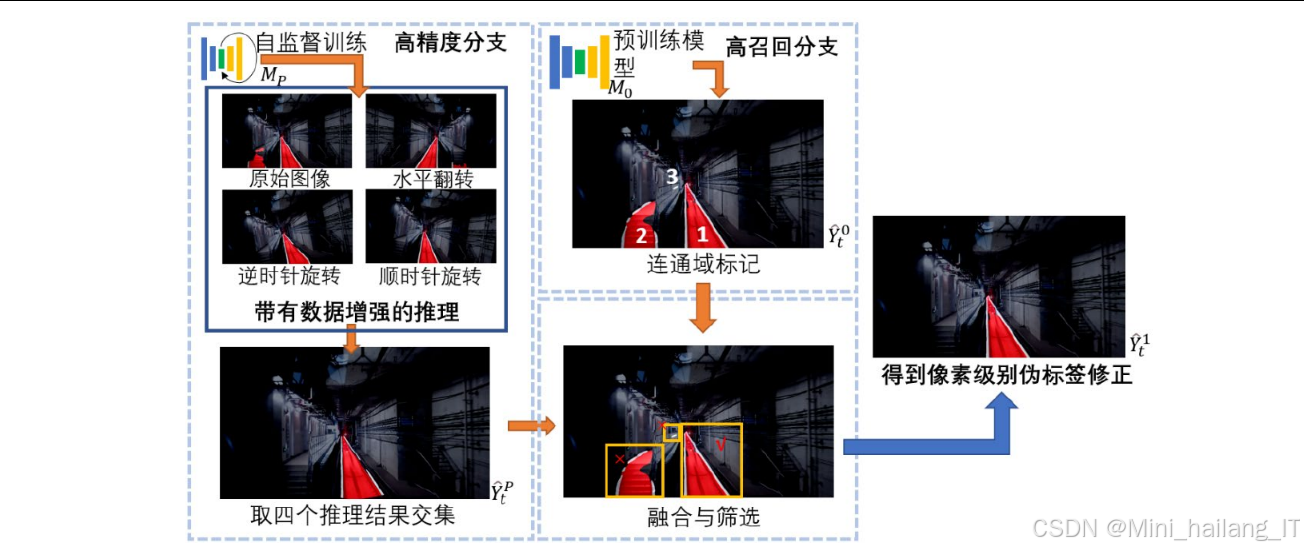
像素级别伪标签修正:
- 高精度分支:利用测试时数据增强(TTA)技术,对目标域图像进行多次推理(原始图像、水平翻转、顺时针旋转10度、逆时针旋转10度),然后对每个像素点的分类结果取交集,确保分割结果的高准确性
- 高召回分支:利用预训练模型直接对目标域图像进行推理,充分利用其高召回率特性,保证轨道区域不被遗漏
- 双分支融合算法:基于图形连通域标记,以高精度分支结果为参考,剔除高召回分支中误分割的区域。通过计算连通域交集面积比率(阈值设为0.2),判断是否保留特定区域,实现精度与召回率的平衡
-
图像样本级别伪标签修正:
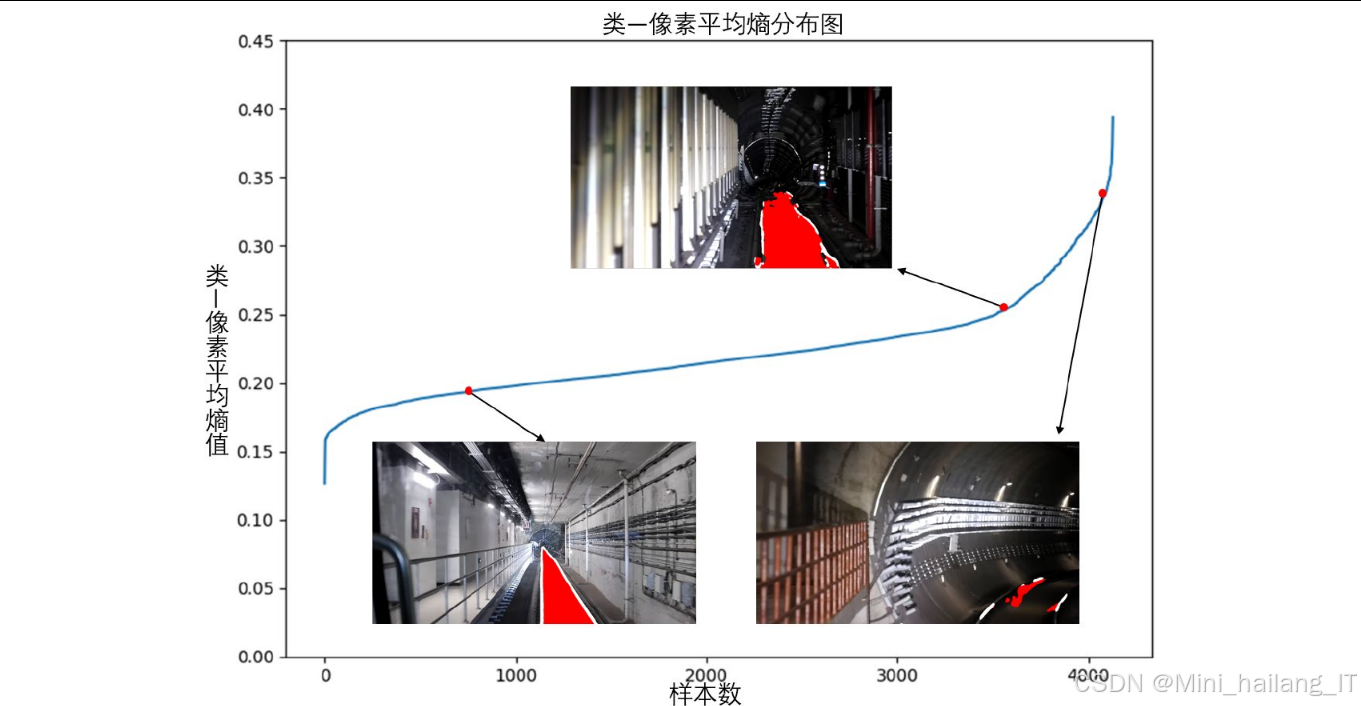
- 基于信息熵的质量评估:提出"类—像素平均熵"评价标准,计算伪标签中前景类别像素点的平均信息熵,熵值越低表示伪标签质量越高
- K-means聚类筛选:使用K-means算法(k=2)将伪标签样本分为高质量和低质量两簇,只保留高质量伪标签用于后续自训练
- 自训练与微调:利用筛选后的高质量伪标签对模型进行自训练,然后使用自训练后的模型对所有目标域图像生成新的伪标签,进行低学习率微调,充分利用所有数据
该模块通过多级修正策略显著提升了伪标签质量,解决了传统自训练方法在域间差异大的场景中性能不佳的问题。实验结果表明,经过伪标签多级修正的方法,其分割性能相比现有方法有明显提升,特别是在铁轨类别上的IOU提高了2.14%。
基于知识蒸馏的域迁移模块
该模块创新性地将知识蒸馏技术应用于非监督域迁移分割任务,充分利用教师模型的强大特征提取能力和迁移性能。其技术思路和实现过程如下:
-
教师-学生模型架构:
- 教师模型:选用基于Vision-Transformer的SegFormer模型,利用其强大的特征提取能力和迁移性能
- 学生模型:采用改进后的HarDNet轻量化模型,保证最终模型的实时推理能力
-
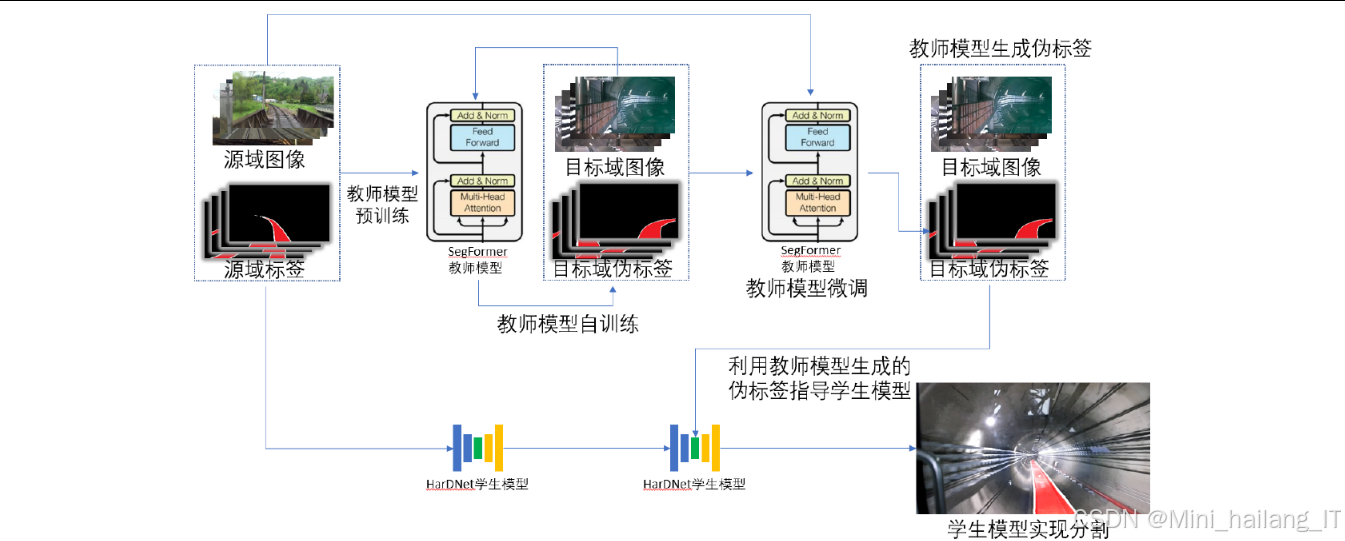
教师模型训练流程:
- 预训练阶段:在源域数据集上进行监督学习,学习基础的轨道线特征表示
- 自训练阶段:利用预训练模型在目标域生成伪标签,结合源域数据进行自训练,实现初步域适应
- 微调阶段:使用测试时增强(TTA)技术生成更高质量的伪标签,对教师模型进行低学习率微调,进一步提升性能
-
知识蒸馏过程:
- 伪标签生成:使用训练好的教师模型对目标域图像进行推理,生成高质量伪标签
- 学生模型学习:学生模型在源域数据上预训练后,利用教师模型生成的伪标签进行训练,学习教师模型的特征提取能力
- 损失函数设计:采用带权重的交叉熵损失函数,确保学生模型能够有效学习教师模型的知识
-
教师模型选择与优化:
- 通过对不同参数量的SegFormer模型(B0-B5)进行对比实验,确定SegFormerB3为最佳教师模型
- 验证了基于Vision-Transformer的模型相比CNN模型(如HRNet)在域迁移任务中的优越性
该模块通过知识蒸馏框架,成功将强大的Vision-Transformer模型的能力迁移到轻量级CNN模型中,实现了分割性能和计算效率的双赢。实验结果显示,基于知识蒸馏的方法在地铁轨道线分割数据集上的MIOU达到70.38%,相比现有的非监督域迁移方法有显著提升。
算法理论
本研究涉及多个关键算法理论,包括语义分割基础理论、非监督域迁移学习理论、伪标签修正理论以及知识蒸馏理论等。以下是对这些理论的详细阐述:
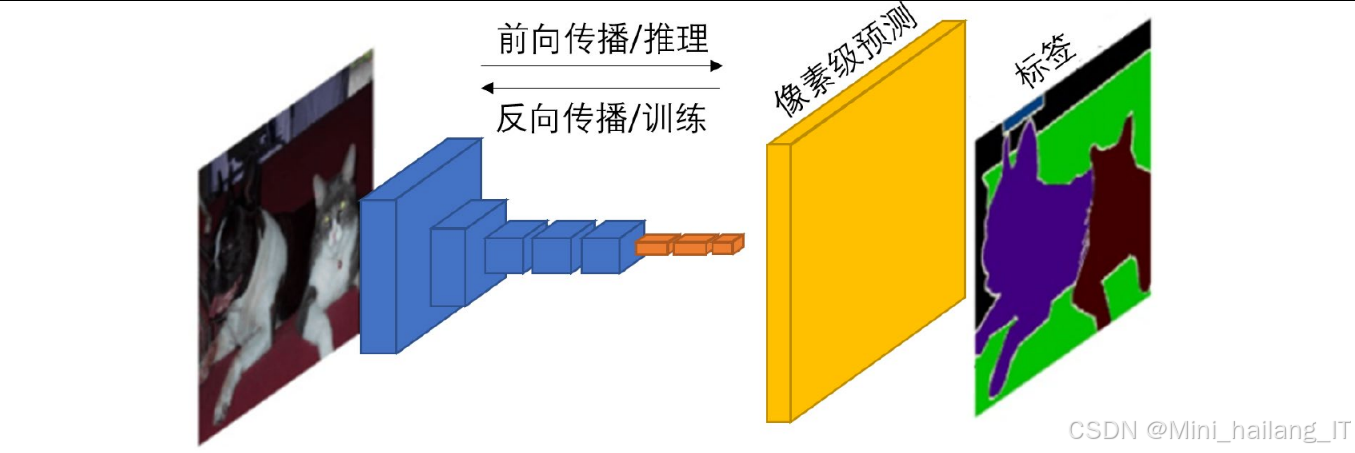
语义分割基础理论
语义分割是计算机视觉中的基础任务,旨在为图像中的每个像素分配一个类别标签。本研究中的语义分割算法基于深度学习技术,主要涉及以下核心理论:
-
全卷积网络(FCN)理论:
- FCN将传统CNN中的全连接层替换为卷积层,实现端到端的像素级预测
- 通过上采样技术(如反卷积)恢复图像分辨率,生成与输入图像尺寸相同的分割图
- 本研究中的分割网络继承了FCN的基本思想,通过编码器-解码器结构实现像素级分割
-
编码器-解码器架构:
- 编码器负责特征提取,通过卷积和池化操作逐步降低分辨率,增加感受野
- 解码器负责分辨率恢复,通过上采样和反卷积操作逐步恢复图像尺寸
- 跳跃连接(Skip Connection)用于将编码器不同深度的特征传递到解码器,保留细节信息
- 本研究采用U-Net风格的编码器-解码器架构,特别强化了浅层特征的传递
-
损失函数设计:
- 采用带权重的像素级交叉熵损失函数,解决类别不平衡问题
- 损失函数形式为:L = -∑pixels ∑c=0^2 w_c * y_c * log(p_c)
- 其中w_c为类别权重,y_c为one-hot标签,p_c为预测概率
- 本研究中设置w₀=1, w₁=1, w₂=2,以增强对轨道类别的学习
-
评估指标理论:
- 均交并比(MIOU):计算预测结果与真实标签的交集与并集之比的平均值
- 公式:MIOU = (1/k)∑(TP/(FP+FN+TP)),其中k为类别数
- 本研究中仅计算前景类(列车可行驶区域和铁轨)的MIOU
非监督域迁移学习理论
非监督域迁移学习旨在将模型从有标注的源域适应到无标注的目标域,主要涉及以下理论:
-
域适应基本原理:
- 域适应假设源域和目标域数据分布不同但相关,通过特征对齐或模型适应减少域间差异
- 在语义分割任务中,域适应的目标是使模型能够在目标域图像上产生准确的分割结果
- 本研究中,源域为地上铁路场景,目标域为地铁隧道场景,两者存在较大的域间差异
-
对抗学习域适应:
- 基于生成对抗网络(GAN)的思想,通过域判别器和特征提取器的对抗训练实现特征对齐
- 特征提取器尝试生成域不变的特征表示,域判别器尝试区分特征来自哪个域
- 本研究对比了AdaptSeg、CyCADA等基于对抗学习的域适应方法
-
自训练域适应:
- 利用模型在目标域上的预测结果(伪标签)进行自监督学习
- 核心思想是迭代更新模型和伪标签,逐步提高分割精度
- 本研究中的伪标签多级修正方法和知识蒸馏方法均基于自训练思想
-
域间差异度量:
- 最大均值差异(MMD):度量两个分布在再生希尔伯特空间中的距离
- 对抗损失:通过域判别器的损失间接度量域间差异
- 本研究通过实验验证了不同域适应方法在处理地铁轨道线域迁移任务中的效果
伪标签修正
伪标签质量直接影响自训练的效果,本研究提出的多级伪标签修正方法基于以下理论:
-
伪标签噪声分析:
- 伪标签中的噪声主要来源:模型在目标域上的错误预测、域间差异导致的特征偏移、小样本导致的过拟合
- 噪声类型:误分类噪声(背景被误分为前景)、漏分类噪声(前景被误分为背景)、边界模糊噪声(类别边界不清晰)
-
像素级别修正理论:
- 测试时数据增强(TTA)原理:通过对同一图像进行多种变换并融合预测结果,减少模型预测的随机性,提高预测准确性
- 交集操作理论基础:多次预测结果的交集区域具有较高的可信度,因为只有在各种变换下都被一致分类的像素才会被保留
- 连通域分析理论:通过分析图像中的连通区域,可以识别和修正不合理的分割区域。连通域面积、形状、位置等特征可以用于判断分割结果的合理性
-
图像级别筛选理论:
- 信息熵理论:信息熵是度量不确定性的标准,伪标签中像素的熵值反映了模型对该像素分类的不确定程度
- 聚类分析理论:基于K-means等聚类算法,可以将伪标签样本按质量自动分为不同类别
- 本研究中的"类—像素平均熵":H̄ = (1/Nc)∑∑-p_c*log(p_c),其中Nc为前景像素数量,p_c为像素被分类为类别c的置信度
-
融合算法理论:
- 基于规则的融合:通过预设规则(如面积比率阈值)融合不同分支的结果
- 自适应权重融合:根据不同分支的可靠性动态调整融合权重
- 本研究采用基于连通域面积比率的融合规则,比率阈值设为0.2
知识蒸馏
知识蒸馏作为将复杂模型(教师)知识迁移到简单模型(学生)的技术,其核心原理由Hinton等人提出。该方法通过训练学生模型模拟教师模型行为,利用包含类别间关系的软标签传递更丰富信息,损失函数通常由软标签损失(蒸馏损失)和硬标签损失(监督损失)两部分组成。在非监督域迁移场景中,知识蒸馏采用教师-学生架构,其中教师模型作为性能强大但计算复杂度高的模型提供高质量监督信号,学生模型作为轻量级模型负责高效推理,知识迁移可通过输出层或中间层特征实现。
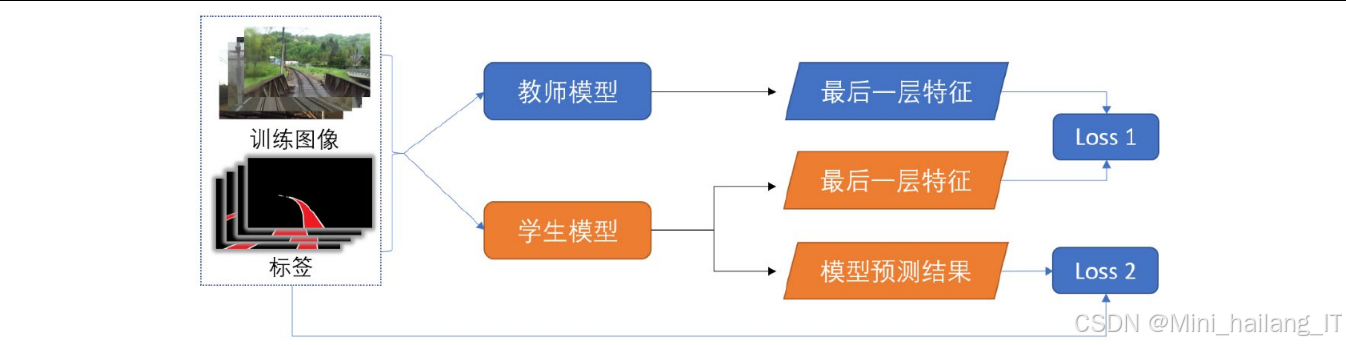
在无标注数据的非监督知识蒸馏过程中,系统完全利用教师模型生成的伪标签作为学生模型的监督信息,无需真实标签参与训练。本研究中设计的非监督知识蒸馏流程为:教师模型自训练→生成伪标签→学生模型学习伪标签。为确保知识迁移的有效性,研究选择基于自注意力机制的Vision-Transformer架构(具体为SegFormer作为教师模型),其强大的特征表达能力和良好迁移性使其能将从大量数据中学到的知识有效迁移到地铁轨道线分割等新场景。
作为模型压缩与加速的重要方法,知识蒸馏通过让轻量级模型学习复杂模型的决策边界和特征表示,实现在保持性能的同时降低模型复杂度。本研究中,通过知识蒸馏技术使轻量级的HarDNet模型在保持高效推理的同时获得接近SegFormer的性能,成功解决了地铁轨道线非监督域迁移分割中的关键问题,实现了从地上铁路场景到地铁隧道场景的高效域适应,为类似场景下的非监督域迁移任务提供了有价值的参考。
核心代码
以下是本研究中关键算法模块的核心代码实现,展示了模型构建、伪标签修正和知识蒸馏的具体实现方法:
基于浅层特征感知的分割网络实现
基于浅层特征感知的分割网络,主要特点是针对地铁轨道线细小的特性,增强了浅层特征提取能力。代码中对HarDNet进行了以下改进:首先,在浅层HarDBlock中增加了通道数量和层数,以增强对轨道线细节的感知能力;其次,在解码器部分增强了浅层特征的融合,通过跳跃连接将最浅层的特征直接传递到解码器,保留更多细节信息;最后,调整了网络各层的参数配置,使其更适合地铁轨道线分割任务。实验证明,这些改进显著提升了模型对轨道线特别是细小铁轨的分割能力。
import torch
import torch.nn as nn
import torch.nn.functional as F
# 改进的HarDNet块定义
class HarDBlock(nn.Module):
def __init__(self, in_channels, growth_rate, grmul, n_layers, keepBase=False, residual_out=False, dwconv=False):
super().__init__()
self.keepBase = keepBase
self.links = []
self.layer_list = nn.ModuleList()
# 增加浅层特征通道数,增强轨道线细节感知
if n_layers == 1:
growth_rate = growth_rate * 2 # 浅层特征通道数翻倍
for i in range(n_layers):
out_channels = int(growth_rate * grmul)
self.layer_list.append(nn.Sequential(
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, bias=False) if not dwconv else
nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1, groups=in_channels, bias=False),
nn.Conv2d(in_channels if dwconv else out_channels, out_channels, kernel_size=1, bias=False) if dwconv else nn.Identity()
))
self.links.append(i)
in_channels += out_channels
self.residual_out = residual_out
self.out_channels = in_channels
def forward(self, x):
x_list = [x]
for layer in self.layer_list:
x_list.append(layer(torch.cat([x_list[i] for i in self.links], 1)))
if self.keepBase:
x = torch.cat([x] + x_list[1:], 1)
else:
x = torch.cat(x_list[1:], 1)
if self.residual_out:
x = x + x_list[0]
return x
# 基于浅层特征感知的分割网络
class LightweightSegmentationNet(nn.Module):
def __init__(self, num_classes=3):
super().__init__()
# 浅层特征提取部分 - 增强设计
self.first_conv = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(48),
nn.ReLU(inplace=True)
)
# 编码器部分 - 使用改进的HarDNet
self.stage1 = HarDBlock(48, 24, 1.7, 8) # 浅层增加通道数和层数
self.trans1 = nn.Sequential(
nn.BatchNorm2d(self.stage1.out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(self.stage1.out_channels, 240, kernel_size=1, bias=False),
nn.AvgPool2d(kernel_size=2)
)
self.stage2 = HarDBlock(240, 24, 1.8, 8)
self.trans2 = nn.Sequential(
nn.BatchNorm2d(self.stage2.out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(self.stage2.out_channels, 480, kernel_size=1, bias=False),
nn.AvgPool2d(kernel_size=2)
)
self.stage3 = HarDBlock(480, 24, 1.9, 8)
# 解码器部分 - 增强细节恢复
self.upconv1 = nn.ConvTranspose2d(self.stage3.out_channels, 240, kernel_size=2, stride=2)
self.decoder1 = nn.Sequential(
nn.Conv2d(480, 240, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(240),
nn.ReLU(inplace=True)
)
self.upconv2 = nn.ConvTranspose2d(240, 120, kernel_size=2, stride=2)
self.decoder2 = nn.Sequential(
nn.Conv2d(168, 120, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(120),
nn.ReLU(inplace=True)
)
# 最终分割头
self.final_conv = nn.Conv2d(120, num_classes, kernel_size=1)
def forward(self, x):
# 浅层特征提取
x0 = self.first_conv(x)
# 编码器路径
x1 = self.stage1(x0)
x2 = self.trans1(x1)
x3 = self.stage2(x2)
x4 = self.trans2(x3)
x5 = self.stage3(x4)
# 解码器路径 - 增强浅层特征融合
y = self.upconv1(x5)
y = torch.cat([y, x3], dim=1)
y = self.decoder1(y)
y = self.upconv2(y)
# 特殊处理:浅层特征直接连接,增强细节保留
x0_small = F.interpolate(x0, size=y.shape[2:], mode='bilinear', align_corners=False)
y = torch.cat([y, x0_small], dim=1)
y = self.decoder2(y)
# 最终分割
y = F.interpolate(y, size=x.shape[2:], mode='bilinear', align_corners=False)
y = self.final_conv(y)
return y
伪标签多级修正算法实现
伪标签多级修正算法,包括像素级别修正和图像样本级别修正两个主要部分。在像素级别修正中,通过高精度分支和高召回分支分别优化分割精度和召回率,然后使用基于连通域的融合算法将两者结果结合。在图像样本级别修正中,通过计算"类—像素平均熵"评价伪标签质量,并使用K-means聚类自动筛选出高质量伪标签。该算法通过从微观到宏观的多级修正策略,有效提升了伪标签质量,解决了传统自训练方法在域间差异大的场景中性能不佳的问题。
import numpy as np
from scipy.ndimage import label, find_objects
def precision_branch(model, image, device='cuda'):
"""高精度分支:通过TTA技术生成高精度伪标签"""
model.eval()
with torch.no_grad():
# 原始图像推理
outputs = model(image.to(device))
pred = F.softmax(outputs, dim=1).cpu().numpy()
pred_argmax = np.argmax(pred, axis=1)
# 水平翻转推理
flip_image = torch.flip(image, dims=[3])
flip_outputs = model(flip_image.to(device))
flip_pred = F.softmax(flip_outputs, dim=1).cpu().numpy()
flip_pred_argmax = np.argmax(flip_pred, axis=1)
flip_pred_argmax = np.flip(flip_pred_argmax, axis=2)
# 顺时针旋转10度推理
rot10_image = F.rotate(image, 10, mode='bilinear', align_corners=False)
rot10_outputs = model(rot10_image.to(device))
rot10_pred = F.softmax(rot10_outputs, dim=1).cpu().numpy()
rot10_pred_argmax = np.argmax(rot10_pred, axis=1)
rot10_pred_argmax = F.rotate(torch.from_numpy(rot10_pred_argmax).float(), -10,
mode='nearest', align_corners=False).numpy().astype(np.int64)
# 逆时针旋转10度推理
rot_neg10_image = F.rotate(image, -10, mode='bilinear', align_corners=False)
rot_neg10_outputs = model(rot_neg10_image.to(device))
rot_neg10_pred = F.softmax(rot_neg10_outputs, dim=1).cpu().numpy()
rot_neg10_pred_argmax = np.argmax(rot_neg10_pred, axis=1)
rot_neg10_pred_argmax = F.rotate(torch.from_numpy(rot_neg10_pred_argmax).float(), 10,
mode='nearest', align_corners=False).numpy().astype(np.int64)
# 取交集:只有在所有变换下都被分类为同一前景类的像素才保留
precision_mask = np.ones_like(pred_argmax)
for i in range(len(pred_argmax)):
# 找到所有预测一致的前景像素
一致区域 = (pred_argmax[i] == flip_pred_argmax[i]) & \
(pred_argmax[i] == rot10_pred_argmax[i]) & \
(pred_argmax[i] == rot_neg10_pred_argmax[i]) & \
(pred_argmax[i] != 0) # 只保留前景类
# 其他像素标记为背景
precision_mask[i] = pred_argmax[i] *一致区域
return precision_mask
def recall_branch(model, image, device='cuda'):
"""高召回分支:直接使用模型推理获取高召回伪标签"""
model.eval()
with torch.no_grad():
outputs = model(image.to(device))
pred = F.softmax(outputs, dim=1).cpu().numpy()
pred_argmax = np.argmax(pred, axis=1)
return pred_argmax
def pseudo_label_fusion(precision_mask, recall_mask, threshold=0.2):
"""伪标签融合:利用高精度分支结果修正高召回分支结果"""
fused_mask = recall_mask.copy()
for i in range(len(recall_mask)):
# 对高召回分支结果进行连通域分析
labeled_array, num_features = label(recall_mask[i] != 0)
# 遍历每个连通域
for region_idx in range(1, num_features + 1):
# 获取连通域位置
region_mask = labeled_array == region_idx
region_coords = find_objects(region_mask)[0]
if region_coords is None:
continue
# 计算连通域与高精度分支结果的交集面积比率
overlap = region_mask & (precision_mask[i] != 0)
overlap_area = np.sum(overlap)
region_area = np.sum(region_mask)
# 如果比率低于阈值,将该连通域标记为背景
if region_area > 0 and (overlap_area / region_area) < threshold:
fused_mask[i][region_mask] = 0
return fused_mask
def calculate_class_pixel_entropy(pseudo_labels, model, images, device='cuda'):
"""计算类-像素平均熵,用于评价伪标签质量"""
model.eval()
entropy_scores = []
with torch.no_grad():
for i in range(len(images)):
# 获取模型对当前图像的概率预测
outputs = model(images[i:i+1].to(device))
probs = F.softmax(outputs, dim=1).cpu().numpy()[0]
# 获取伪标签中的前景像素
foreground_mask = pseudo_labels[i] != 0
foreground_pixels = np.sum(foreground_mask)
if foreground_pixels == 0:
entropy_scores.append(1.0) # 无前景像素的图像赋予高熵值
continue
# 计算前景像素的平均熵
total_entropy = 0
class_count = 0
for c in range(1, probs.shape[0]): # 只考虑前景类
class_mask = (pseudo_labels[i] == c) & foreground_mask
class_pixels = np.sum(class_mask)
if class_pixels > 0:
class_count += 1
# 计算该类像素的熵
class_probs = probs[c, class_mask]
class_entropy = -np.sum(class_probs * np.log(class_probs + 1e-10))
total_entropy += class_entropy
# 计算类-像素平均熵
if class_count > 0:
avg_entropy = total_entropy / (foreground_pixels * class_count)
else:
avg_entropy = 1.0
entropy_scores.append(avg_entropy)
return entropy_scores
def select_high_quality_pseudo_labels(pseudo_labels, entropy_scores):
"""基于K-means聚类筛选高质量伪标签"""
from sklearn.cluster import KMeans
# 使用K-means将伪标签分为两类
kmeans = KMeans(n_clusters=2, random_state=42)
cluster_labels = kmeans.fit_predict(np.array(entropy_scores).reshape(-1, 1))
# 确定哪一类是高质量伪标签(熵值较低的一类)
cluster_centers = kmeans.cluster_centers_.flatten()
high_quality_cluster = 0 if cluster_centers[0] < cluster_centers[1] else 1
# 筛选高质量伪标签
high_quality_indices = np.where(cluster_labels == high_quality_cluster)[0]
return high_quality_indices
基于知识蒸馏的非监督域迁移实现
基于知识蒸馏的非监督域迁移方法,包括教师模型训练、教师模型微调、伪标签生成和学生模型知识蒸馏训练四个主要步骤。在教师模型训练阶段,使用源域数据和目标域伪标签进行联合训练;在微调阶段,利用TTA技术生成更高质量的伪标签进一步优化教师模型;然后,使用训练好的教师模型对目标域数据生成高质量伪标签;最后,学生模型通过学习这些伪标签,获得教师模型的分割能力和迁移性能。该实现充分利用了Vision-Transformer模型(SegFormer)的强大特征提取能力和迁移性能,同时保持了学生模型(改进后的HarDNet)的高效推理特性,实现了性能和效率的平衡。
import torch
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
def train_teacher_model(teacher_model, source_dataloader, target_dataloader, num_epochs=80, lr=0.0001, device='cuda'):
"""训练教师模型(SegFormer)"""
teacher_model.to(device)
optimizer = optim.Adam(teacher_model.parameters(), lr=lr)
# 带权重的交叉熵损失函数
class_weights = torch.tensor([1.0, 1.0, 2.0]).to(device)
criterion = nn.CrossEntropyLoss(weight=class_weights)
for epoch in range(num_epochs):
teacher_model.train()
running_loss = 0.0
# 组合源域和目标域数据
for (source_images, source_labels), (target_images, _) in zip(source_dataloader, target_dataloader):
source_images, source_labels = source_images.to(device), source_labels.to(device)
target_images = target_images.to(device)
# 清零梯度
optimizer.zero_grad()
# 源域前向传播
source_outputs = teacher_model(source_images)
source_loss = criterion(source_outputs, source_labels)
# 目标域伪标签生成和自训练
with torch.no_grad():
target_pseudo_labels = torch.argmax(teacher_model(target_images), dim=1)
target_outputs = teacher_model(target_images)
target_loss = criterion(target_outputs, target_pseudo_labels)
# 组合损失(源域损失权重0.2,目标域损失权重1.0)
loss = 0.2 * source_loss + 1.0 * target_loss
# 反向传播和优化
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch+1}/{num_epochs}, Loss: {running_loss/len(source_dataloader):.4f}')
return teacher_model
def teacher_fine_tuning(teacher_model, target_dataloader, num_epochs=40, lr=0.00001, device='cuda'):
"""教师模型微调:使用TTA生成高质量伪标签"""
teacher_model.to(device)
optimizer = optim.Adam(teacher_model.parameters(), lr=lr)
class_weights = torch.tensor([1.0, 1.0, 2.0]).to(device)
criterion = nn.CrossEntropyLoss(weight=class_weights)
for epoch in range(num_epochs):
teacher_model.train()
running_loss = 0.0
for target_images, _ in target_dataloader:
target_images = target_images.to(device)
# 使用TTA生成高质量伪标签
with torch.no_grad():
# 原始图像
outputs = teacher_model(target_images)
probs = F.softmax(outputs, dim=1)
# 水平翻转
flip_outputs = teacher_model(torch.flip(target_images, dims=[3]))
flip_probs = F.softmax(torch.flip(flip_outputs, dims=[3]), dim=1)
# 旋转
rot10_outputs = teacher_model(F.rotate(target_images, 10, mode='bilinear', align_corners=False))
rot10_probs = F.softmax(F.rotate(rot10_outputs, -10, mode='bilinear', align_corners=False), dim=1)
# 融合多个预测结果
fused_probs = (probs + flip_probs + rot10_probs) / 3
pseudo_labels = torch.argmax(fused_probs, dim=1)
# 清零梯度
optimizer.zero_grad()
# 前向传播
outputs = teacher_model(target_images)
loss = criterion(outputs, pseudo_labels)
# 反向传播和优化
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Finetuning Epoch {epoch+1}/{num_epochs}, Loss: {running_loss/len(target_dataloader):.4f}')
return teacher_model
def generate_teacher_pseudo_labels(teacher_model, target_dataloader, device='cuda'):
"""使用教师模型生成伪标签"""
teacher_model.eval()
all_pseudo_labels = []
all_target_images = []
with torch.no_grad():
for target_images, _ in target_dataloader:
target_images = target_images.to(device)
# 生成伪标签
outputs = teacher_model(target_images)
pseudo_labels = torch.argmax(outputs, dim=1)
all_pseudo_labels.append(pseudo_labels.cpu())
all_target_images.append(target_images.cpu())
return torch.cat(all_target_images), torch.cat(all_pseudo_labels)
def knowledge_distillation_training(student_model, teacher_pseudo_dataset, num_epochs=50, lr=0.001, device='cuda'):
"""知识蒸馏训练:学生模型学习教师模型生成的伪标签"""
student_model.to(device)
# 创建数据加载器
dataloader = DataLoader(teacher_pseudo_dataset, batch_size=16, shuffle=True)
optimizer = optim.Adam(student_model.parameters(), lr=lr)
class_weights = torch.tensor([1.0, 1.0, 2.0]).to(device)
criterion = nn.CrossEntropyLoss(weight=class_weights)
for epoch in range(num_epochs):
student_model.train()
running_loss = 0.0
for images, pseudo_labels in dataloader:
images, pseudo_labels = images.to(device), pseudo_labels.to(device)
# 清零梯度
optimizer.zero_grad()
# 前向传播
outputs = student_model(images)
loss = criterion(outputs, pseudo_labels)
# 反向传播和优化
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Distillation Epoch {epoch+1}/{num_epochs}, Loss: {running_loss/len(dataloader):.4f}')
return student_model
重难点和创新点
本研究在地铁轨道线非监督域迁移分割领域取得了多项重要成果,主要的重难点和创新点如下:
难点
-
地铁轨道线的细微特征识别:地铁轨道线特别是铁轨部分在图像中表现为细小的线条,且在昏暗的隧道环境中对比度低,如何准确识别这些细微特征是一个主要难点。
-
大域间差异的适应:从地上铁路场景到地铁隧道场景存在显著的域间差异,包括光照条件、场景结构、轨道形态等多方面的不同,传统的域适应方法难以有效处理这种大差异场景。
-
伪标签质量控制:在非监督域迁移中,伪标签质量直接决定了模型性能。如何在缺乏真实标签的情况下生成高质量伪标签,并有效过滤噪声,是一个关键难题。
创新点
-
基于浅层特征感知的分割网络设计:
- 针对地铁轨道线细微的特点,创新性地优化了分割网络的浅层特征提取能力
- 通过增加浅层卷积核数量和优化特征融合策略,增强了对轨道线细节的感知
- 实验证明,该设计使模型在保持轻量化的同时,显著提升了对铁轨等细微目标的分割能力
-
地铁轨道线分割数据集构建:
- 构建了首个专门针对地铁场景的轨道线分割数据集,包含5630张覆盖多种地铁场景的图像
- 数据集涵盖隧道、站台、车辆段等典型场景,为地铁轨道线分割研究提供了重要的数据基础
- 该数据集的构建填补了地铁场景分割数据的空白,为相关研究提供了参考
-
基于知识蒸馏的非监督域迁移方法:
- 首次将知识蒸馏技术应用于地铁轨道线非监督域迁移分割任务
- 构建了基于Vision-Transformer的教师模型和轻量化CNN的学生模型架构
- 利用教师模型强大的特征提取能力和迁移性能,提升学生模型在目标域的分割性能
- 通过实验验证了不同教师模型的效果,确定了最优的模型组合
-
跨模态知识迁移验证:
- 验证了基于Vision-Transformer的模型相比传统CNN模型在域迁移任务中的优越性
- 证明了预训练的视觉Transformer模型可以将从自然图像中学到的知识有效迁移到地铁场景
- 为视觉Transformer在特定领域任务中的应用提供了新的思路
这些创新点共同构成了本研究的技术特色,不仅解决了地铁轨道线分割和非监督域迁移中的关键问题,也为类似场景下的计算机视觉任务提供了有价值的参考。特别是在伪标签修正和知识蒸馏方面的创新,为解决小样本学习和域适应问题提供了新的技术路径。
总结
本研究针对地铁轨道线分割这一地铁无人驾驶中的基础任务,系统性地解决了数据标注困难、域间差异大、分割精度与实时性平衡等关键问题,取得了多项重要成果。
-
构建了首个专门针对地铁场景的轨道线分割数据集,包含5630张覆盖多种地铁场景的图像。该数据集涵盖隧道、站台、车辆段等典型场景,为地铁轨道线分割研究提供了重要的数据基础,填补了相关领域数据的空白。
-
针对地铁轨道线细微、特征不明显的特点,本研究提出了基于浅层特征感知的分割网络模型。通过优化网络架构和特征提取策略,该模型在保持轻量化的同时,显著提升了对轨道线特别是细小铁轨的分割能力。实验结果表明,改进后的模型在地铁轨道线分割数据集上的MIOU达到78.16%,推理速度达到81fps,成功实现了分割精度与计算效率的平衡。
-
非监督域迁移方法:基于伪标签多级修正的方法和基于知识蒸馏的方法。伪标签多级修正方法通过像素级别和图像样本级别的多级修正策略,有效提升了伪标签质量;基于知识蒸馏的方法则创新性地利用Vision-Transformer模型的强大特征提取能力和迁移性能,指导轻量化CNN模型进行学习。实验结果显示,基于知识蒸馏的方法在地铁轨道线非监督域迁移分割任务上的MIOU达到70.38%,显著优于现有的非监督域迁移方法。
本研究探索了适用于地铁轨道线分割的高效算法,提出了新的伪标签修正和知识蒸馏方法,丰富了计算机视觉在特定领域应用的理论体系。在应用层面,本研究的成果可以直接应用于地铁无人驾驶环境感知系统,为列车的定位、导航和路径规划提供可靠的技术支持,推动地铁无人驾驶技术的发展和应用。
未来的研究方向主要包括:将研究成果部署到真实的地铁无人驾驶系统中,进行实际环境下的验证和优化;进一步改进非监督域迁移方法,使其在更多场景中都能取得良好效果;研究模型在线学习和自适应能力,使分割模型能够根据实际运行数据不断优化和迭代。
参考文献
[1] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2020: 3431-3440.
[2] Chen L C, Papandreou G, Kokkinos I, et al. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(4): 834-848.
[3] Xie E, Wang W, Yu Z, et al. SegFormer: Simple and efficient design for semantic segmentation with transformers[J]. Advances in Neural Information Processing Systems, 2022, 35.
[4] Chao P, Kao C Y, Ruan Y S, et al. Hardnet: A low memory traffic network[C]//Proceedings of the IEEE International Conference on Computer Vision. 2022: 3552-3561.
[5] Tsai Y H, Hung W C, Schulter S, et al. Learning to adapt structured output space for semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2021: 7472-7481.
[6] Hoffman J, Tzeng E, Park T, et al. Cycada: Cycle-consistent adversarial domain adaptation[C]//International Conference on Machine Learning. PMLR, 2022: 1989-1998.
[7] Zhang P, Zhang B, Zhang T, et al. Prototypical pseudo label denoising and target structure learning for domain adaptive semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2022: 12414-12424.
[8] Zendel O, Murschitz M, Zeilinger M, et al. Railsem19: A dataset for semantic rail scene understanding[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 2023: 0-0.

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









