




目录
1. 选题意义背景
宫颈癌是全球女性最常见的恶性肿瘤之一,严重威胁着女性健康。根据全球癌症统计数据,宫颈癌在女性癌症发病率中位居前列,每年新增病例超过60万,死亡病例约30万,其中发展中国家占比高达80%。传统的宫颈癌筛查主要依赖巴氏涂片检查和液基细胞学检查(TCT),这些方法需要专业病理医师在显微镜下手动观察细胞形态,存在以下局限性:首先,人工筛查效率低下,一位经验丰富的病理医师平均每小时仅能审阅约30张涂片;其次,诊断结果严重依赖医师的经验和主观判断,不同医师之间的诊断一致性仅为60%-70%;此外,长期目视观察容易导致疲劳,进一步降低诊断准确率。随着医疗大数据的积累和人工智能技术的发展,基于深度学习的宫颈癌自动筛查技术逐渐成为研究热点,有望解决传统筛查方法中存在的效率低、主观性强等问题。
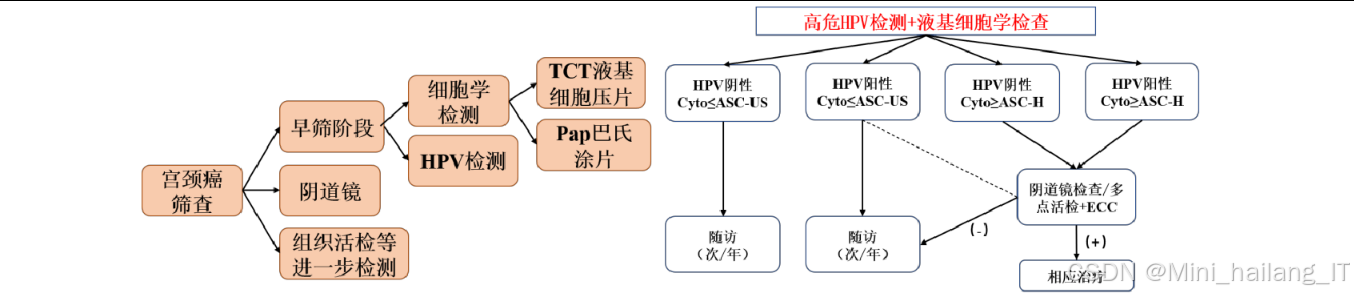
深度学习在医学图像分析领域取得了突破性进展。特别是在宫颈癌筛查方面,研究人员提出了多种基于卷积神经网络的宫颈癌细胞检测和分类方法。然而,现有的研究仍面临诸多挑战:首先,宫颈癌细胞图像具有背景复杂、细胞形态多变、小目标占比高等特点,传统目标检测算法在这类场景下表现不佳;其次,高质量的标注数据集获取困难且成本高昂,限制了监督学习方法的应用;此外,现有的单一检测或分类模型难以同时满足查全率和查准率的要求,影响了临床实用性。
近年来,注意力机制和自监督学习的发展为解决上述问题提供了新思路。注意力机制能够帮助模型聚焦于图像中的关键区域,提高对小目标的检测能力;自监督学习则可以充分利用大量未标注数据进行预训练,减轻对标注数据的依赖,结合注意力机制和自监督学习的方法在医学图像分析领域取得了显著成效。基于此,本项目旨在探索一种融合注意力机制、自适应空间特征融合和对比自监督学习的宫颈癌细胞图像识别方法,以提高宫颈癌自动筛查的准确性和效率。
数据集
数据获取
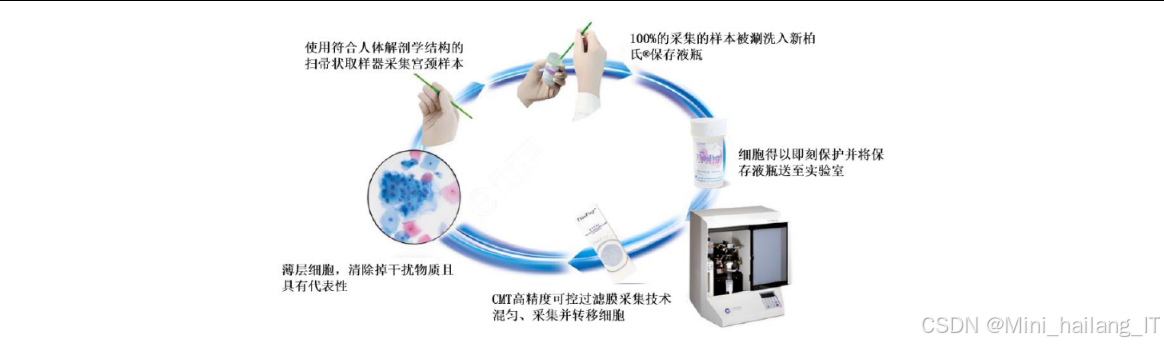
本研究使用的宫颈癌细胞数据集数据集包含了大量从临床实际采集的宫颈细胞样本,具有较高的真实性和代表性。数据采集过程严格遵循医学伦理规范,所有样本均经过匿名化处理,确保患者隐私安全。数据集的获取采用了以下步骤:首先,通过液基细胞学检查(TCT)采集患者的宫颈细胞样本;然后,使用全自动细胞制片机对样本进行制片和染色处理;接着,通过数字病理切片扫描仪将制备好的细胞涂片扫描成数字化图像;最后,由经验丰富的病理医师对数字图像中的异常细胞进行标注。
数据格式与数据规模
数据集采用标准的数字病理切片(Whole Slide Image, WSI)格式,原始图像分辨率较高,通常在5万×5万像素以上。为了便于模型训练和评估,研究团队对WSI进行了切片处理,将其分割为大小为512×512像素的子图像。最终,数据集包含2483张子图像,涵盖了正常宫颈细胞和各种类型的异常细胞。
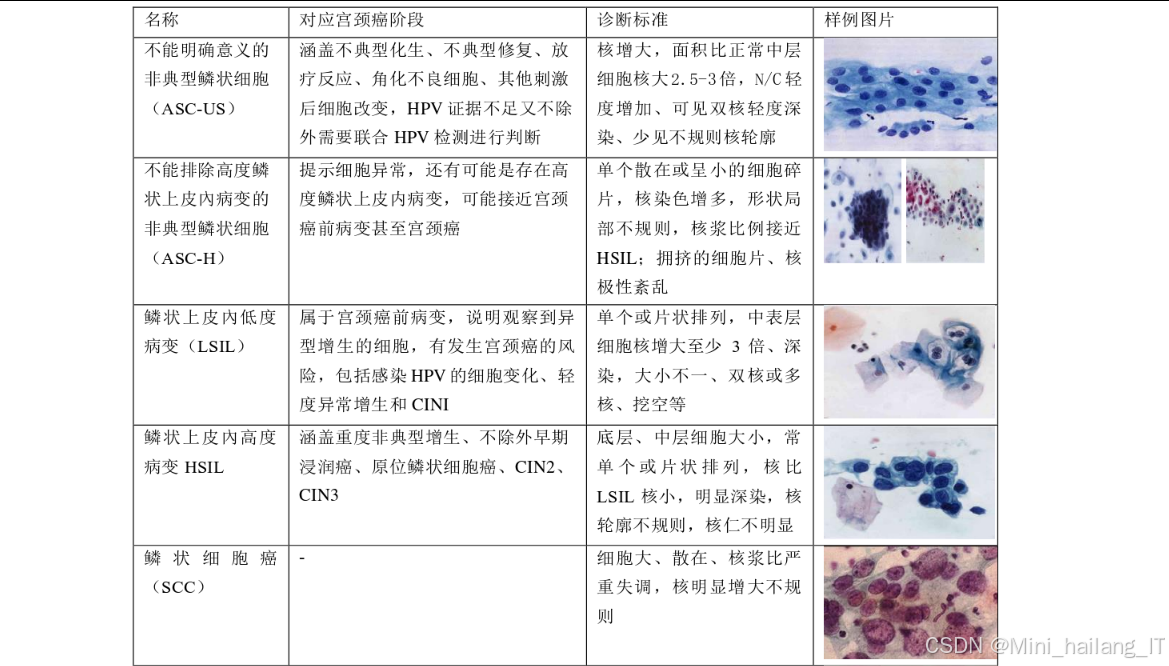
标注格式采用PASCAL VOC 2007标准,每张图像对应一个XML标注文件,记录了异常细胞的位置信息(边界框坐标)和类别信息。数据集中共定义了5类异常细胞,分别对应TBS(The Bethesda System)分类系统中的不同病变等级,具体类别编号与病变类型的对应关系如下:1代表非典型鳞状细胞(ASC-US),2代表低级别鳞状上皮内病变(LSIL),3代表高级别鳞状上皮内病变(HSIL),5代表鳞状细胞癌(SCC),9代表腺癌(AC)。
数据分割策略
为了确保模型评估的公平性和可靠性,研究团队采用了7:3的比例将数据集随机划分为训练集和测试集。其中,训练集包含1738张子图像,测试集包含745张子图像。数据分割过程中,特别注意了各类别样本的均衡分布,确保训练集和测试集中各类别异常细胞的比例大致相同,避免模型训练过程中的类别不平衡问题。
数据预处理
针对数据集中存在的问题,研究团队实施了一系列数据预处理和增强措施,以提高数据质量和模型的泛化能力:
-
图像标准化:对所有图像进行尺寸调整,统一为512×512像素,并进行灰度归一化处理,将像素值缩放到[0,1]区间,消除不同图像间亮度差异的影响。
-
颜色标准化:采用颜色标准化算法(如Macenko标准化)对图像进行处理,减少染色差异带来的影响,使同一类型的细胞在不同图像中具有相似的颜色特征。
-
传统数据增强:包括几何变换(旋转、翻转、缩放)、图像扰动(亮度调整、对比度调整、饱和度调整)和滤波变换(高斯模糊、锐化)等,以增加训练数据的多样性。
-
高级数据增强:采用Mixup、Mosaic、Copy_paste等混合变换方法,生成新的训练样本,这些方法可以有效地扩大训练数据集,提高模型对小目标和遮挡目标的检测能力。
-
对抗样本处理:在训练过程中引入对抗样本生成方法(如PGD训练),增强模型对对抗攻击的防御能力,提高模型的鲁棒性和安全性。
-
标注修正:通过半自动化的方式对数据集中的标签错误进行修正,使用预训练模型对标注结果进行初步验证,对明显错误的标注进行人工审核和修正。
-
HSV色彩空间转换:针对宫颈细胞图像的特点,将RGB格式的图像转换为HSV色彩空间,以便更好地分离亮度信息和颜色信息,减少光照和染色差异的影响。在自监督学习部分,研究团队特别利用HSV色彩空间的特性构建正例样本对,以提高对比学习的效果。
通过以上数据预处理和增强措施,研究团队成功构建了一个高质量、多样化的宫颈癌细胞数据集,为后续的模型训练和评估提供了可靠的数据基础。同时,这些预处理方法也为解决医学图像数据集中常见的质量差异、染色差异等问题提供了可行的解决方案。
功能模块
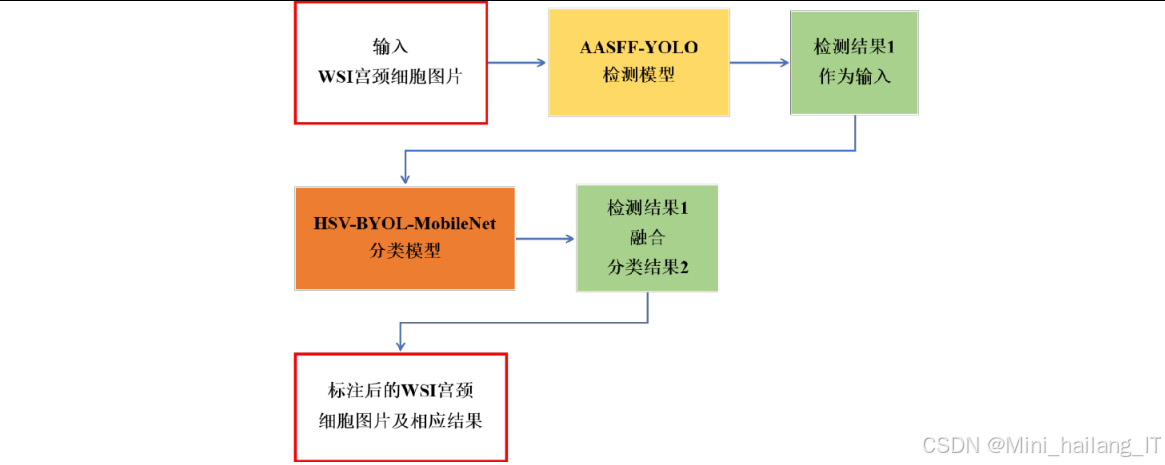
AASFF-YOLO宫颈癌细胞检测模块
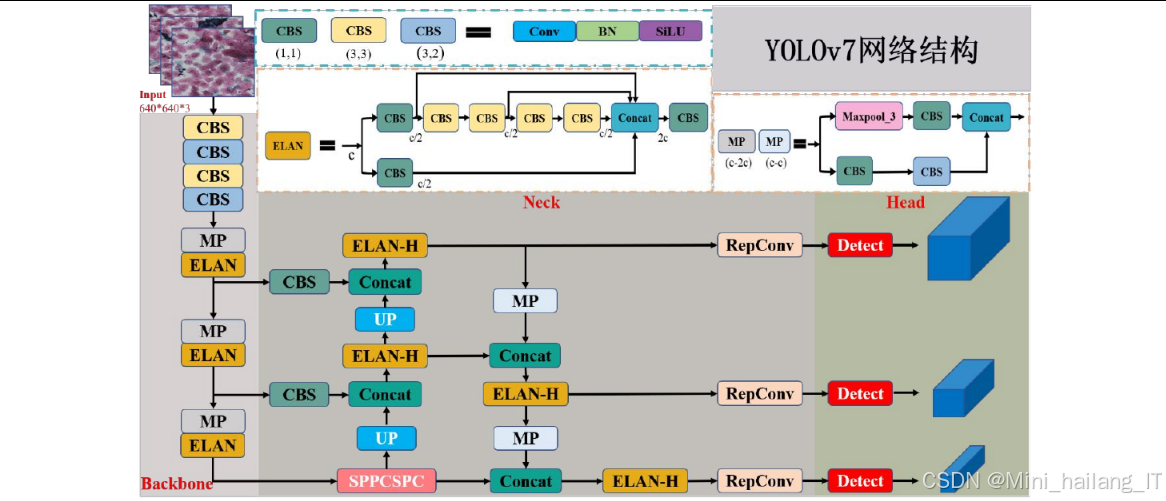
AASFF-YOLO检测模块是本研究的核心模块之一,主要负责对输入的宫颈细胞图像进行处理,定位并初步识别图像中的异常细胞。该模块基于YOLOv7进行改进,融合了注意力机制和自适应空间特征融合策略,专门针对宫颈癌细胞小目标、背景复杂等特点进行了优化。
技术思路与流程:
-
输入处理:将512×512像素的宫颈细胞图像作为输入,首先进行数据增强(如Mosaic、Mixup等),然后将图像调整为模型所需的输入尺寸,并进行标准化处理。
-
特征提取网络:采用改进的YOLOv7骨干网络,在每个ELAN模块后添加CBAM注意力机制,形成A-ELAN结构。CBAM注意力机制通过通道注意力和空间注意力两个子模块,自适应地调整特征图中不同通道和位置的权重,帮助模型聚焦于图像中的关键区域,提高对小目标的特征提取能力。
-
特征融合网络(Neck):采用FPN和PAN结构进行多尺度特征融合,将来自不同层级的特征图进行充分融合,以保留丰富的语义信息和空间细节信息。
-
检测头(Head):在检测头部分引入ASFF自适应空间特征融合策略,通过可学习的参数对来自不同层级的特征图进行加权融合,使检测头能够根据目标的大小和位置自适应地选择最适合的特征表示。
-
输出处理:检测头输出的特征图经过预测层生成边界框坐标、置信度和类别概率,然后通过非极大值抑制(NMS)算法过滤冗余的边界框,最终得到检测结果。
实现过程:
-
模型构建:基于PyTorch框架构建AASFF-YOLO模型,包括骨干网络、特征融合网络和检测头三个部分。在实现过程中,特别注意了模型各组件之间的接口设计,确保数据流转的顺畅性。
-
注意力机制集成:在ELAN模块后添加CBAM注意力机制,通过实验比较了三种不同的注意力模块添加方式,最终确定在每个ELAN模块后直接添加CBAM的方式效果最佳。
-
ASFF模块实现:实现ASFF自适应空间特征融合模块,通过可学习的参数对来自不同层级的特征图进行加权融合。ASFF模块的核心是一个轻量级的卷积网络,用于生成融合权重,然后根据这些权重对多尺度特征进行加权求和。
-
损失函数设计:采用CIoU损失函数计算边界框回归损失,二元交叉熵损失函数计算置信度损失和类别分类损失,综合考虑了目标的重叠度、中心点距离和宽高比等因素。
-
对抗训练集成:在训练过程中引入PGD(Projected Gradient Descent)对抗训练方法,通过生成对抗样本并将其纳入训练集,增强模型对对抗攻击的防御能力。
实验结果表明,AASFF-YOLO检测模块在宫颈癌细胞数据集上表现出色,mAP@0.5达到64.02%,相比原始YOLOv7模型提升了4.22%,同时在各类别异常细胞的检测性能上也有显著提升。
HSV-BYOL自监督分类模块
HSV-BYOL自监督分类模块主要负责对检测模块输出的候选区域进行精确分类,以提高异常细胞识别的准确性。该模块基于BYOL对比自监督学习框架,结合HSV色彩空间转换策略,旨在充分利用大量未标注数据进行预训练,降低对标注数据的依赖。
技术思路与流程:
-
输入处理:从检测模块获取的候选区域(裁剪后的单细胞图像)作为输入,首先将其调整为224×224像素的标准尺寸,然后进行数据增强(如随机裁剪、翻转、颜色抖动等),并将其转换为HSV色彩空间。
-
自监督预训练:采用BYOL自监督学习框架进行预训练,BYOL由在线网络和目标网络两个结构相同但参数不同的网络组成。在线网络的参数通过梯度下降直接更新,而目标网络的参数则通过在线网络参数的指数移动平均进行更新。
-
正例构建策略:针对宫颈细胞图像的特点,提出了基于HSV色彩空间的正例构建策略。具体来说,将原始图像通过基础数据增强得到的两个视图作为正例对,其中一个视图保持RGB格式,另一个视图转换为HSV格式。这种策略可以更好地捕捉宫颈细胞的颜色特征,减少染色和光照差异的影响。
-
特征提取与映射:使用MobileNet-v3-small作为骨干网络提取图像特征,然后通过投影头将特征映射到低维空间,再通过预测头生成最终的特征表示。
-
监督微调:使用少量标注数据对预训练模型进行微调,以适应特定的分类任务。微调过程中,固定骨干网络和投影头的参数,只更新预测头的参数,以保留预训练阶段学习到的通用特征表示。
两阶段检测分类融合模块
两阶段检测分类融合模块是本研究的集成模块,负责将AASFF-YOLO检测模块和HSV-BYOL分类模块的输出结果进行融合,形成最终的检测分类结果。该模块通过正常细胞采样算法和检测分类融合算法,有效地平衡了查全率和查准率,提高了系统的整体性能。
技术思路与流程:
-
候选区域生成:将输入图像首先送入AASFF-YOLO检测模块,生成初步的检测结果,包括边界框坐标、置信度和类别预测。
-
候选区域过滤:对检测模块输出的候选区域进行初步过滤,去除置信度低于阈值的边界框,减少后续处理的计算量。
-
候选区域分类:将过滤后的候选区域裁剪出来,调整为标准尺寸,然后送入HSV-BYOL分类模块进行精确分类,得到每个候选区域的类别预测和分类置信度。
-
正常细胞采样:设计正常细胞采样算法,通过计算检测边界框与标注边界框之间的IoU(Intersection over Union)值,过滤与异常细胞重叠的预测框,确保采样到的正常细胞的纯净性。
-
检测分类融合:根据分类模块的输出结果对检测模块的结果进行修正,删除分类为正常细胞的检测框,同时修正异常细胞的类别,最终得到融合后的检测分类结果。
实现过程:
-
正常细胞采样算法实现:设计基于IoU阈值的正常细胞采样算法,通过设置0.3和0.5两个IoU阈值,过滤与异常细胞重叠的预测框。具体来说,对于检测到的每个边界框,如果其与任何一个标注的异常细胞边界框的IoU值大于0.3但小于0.5,则认为该边界框可能包含异常细胞的部分区域,需要被过滤;如果IoU值大于0.5,则直接认为该边界框包含异常细胞。
-
检测分类融合算法实现:实现检测分类融合算法,根据分类模块的输出结果对检测模块的结果进行修正。对于每个检测边界框,如果分类模块预测其为正常细胞,则直接删除该边界框;如果分类模块预测其为异常细胞,则用分类结果修正检测结果中的类别信息,并重新计算置信度。
-
置信度重计算:在融合过程中,重新计算每个保留的边界框的置信度,结合检测模块的原始置信度和分类模块的分类置信度,得到最终的综合置信度。
-
非极大值抑制(NMS)优化:对融合后的边界框再次应用NMS算法,去除冗余的边界框,确保每个细胞只被检测一次。
-
性能评估:设计评估指标,包括mAP、准确率、召回率、F1值等,对两阶段检测分类融合模块的性能进行全面评估。
算法理论
目标检测算法基础
目标检测是计算机视觉领域的核心任务之一,旨在从图像中定位并识别出感兴趣的目标。近年来,基于深度学习的目标检测算法取得了突破性进展,主要分为两阶段检测算法和单阶段检测算法两大类。
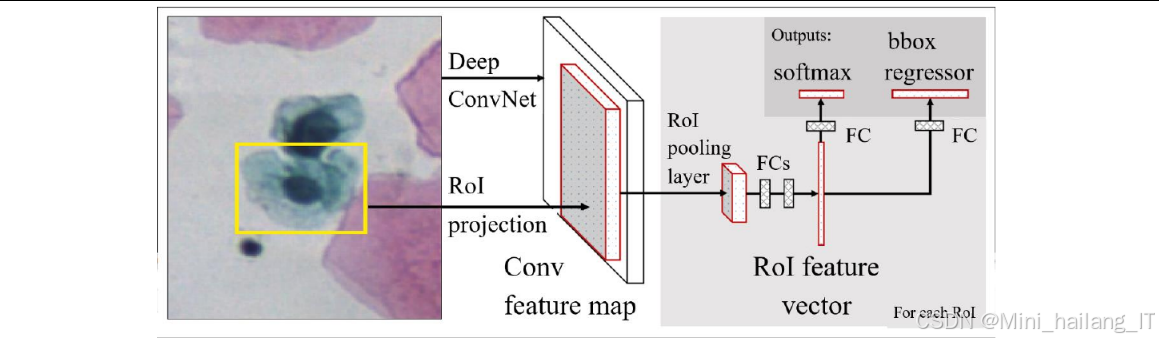
两阶段检测算法:以R-CNN系列算法为代表,包括R-CNN、Fast R-CNN和Faster R-CNN等。这类算法首先生成目标候选区域(Region Proposal),然后对每个候选区域进行分类和边界框回归。R-CNN使用选择性搜索(Selective Search)生成候选区域,然后通过CNN提取特征,最后使用SVM进行分类;Fast R-CNN改进了R-CNN的架构,共享卷积特征,提高了检测速度;Faster R-CNN则引入了区域提议网络(RPN),实现了端到端的训练,进一步提高了检测性能和速度。
单阶段检测算法:以YOLO系列和SSD等为代表,直接在特征图上进行目标检测,不需要生成候选区域。YOLO(You Only Look Once)将目标检测问题转化为回归问题,通过单次前向传播即可得到目标的位置和类别;SSD(Single Shot MultiBox Detector)结合了FPN的多尺度特征融合思想,在不同尺度的特征图上进行检测,提高了对小目标的检测能力;RetinaNet则提出了焦点损失(Focal Loss),解决了类别不平衡问题,进一步提高了检测性能。
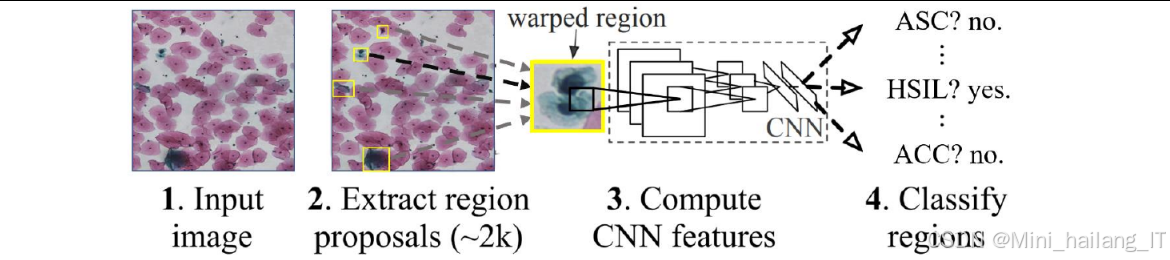
YOLO系列算法在近年来不断发展,从YOLOv1到YOLOv8,性能和速度都有显著提升。YOLOv7作为YOLO系列的重要成员,通过引入ELAN结构、可训练的bag-of-freebies等技术,在保持较高检测速度的同时,显著提高了检测精度,特别适合实时目标检测任务。
注意力机制原理
注意力机制是模仿人类视觉注意力机制的一种技术,能够帮助模型自适应地关注图像中的重要区域,提高特征提取的效率和有效性。根据不同的分类标准,注意力机制可以分为以下几类:

-
全局注意力与局部注意力:全局注意力关注整个特征图,而局部注意力只关注特征图的部分区域。
-
硬性注意力与软性注意力:硬性注意力通过采样或门控机制选择特定区域,输出为0-1的二值分布;软性注意力则为每个位置分配一个权重,输出为连续的概率分布。
-
自我注意力与非自我注意力:自我注意力通过计算特征图内部元素之间的关系来生成注意力权重,非自我注意力则通过外部信息(如查询向量)来指导注意力分配。
-
单头注意力与多头注意力:单头注意力只有一个注意力计算模块,多头注意力则有多个并行的注意力计算模块,可以捕捉不同类型的依赖关系。
-
绝对位置编码与相对位置编码:绝对位置编码直接将位置信息添加到特征中,相对位置编码则编码元素之间的相对位置关系。
在本研究中,我们主要使用了CBAM(Convolutional Block Attention Module)注意力机制,它是一种结合通道注意力和空间注意力的高效注意力模块。CBAM的工作原理如下:
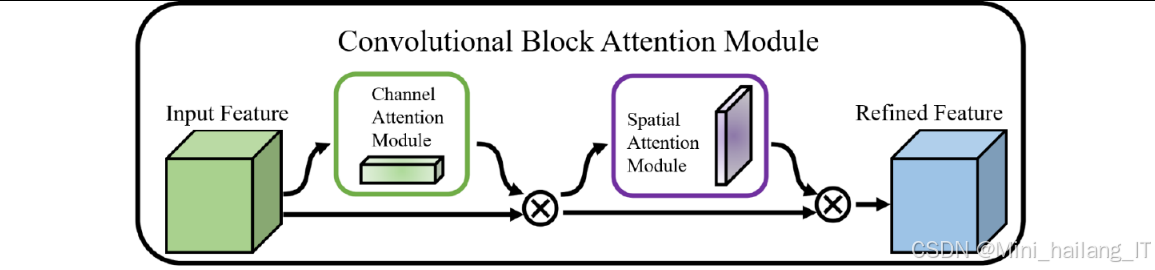
-
通道注意力模块:首先通过全局平均池化和全局最大池化将特征图压缩为一维特征向量,然后通过共享的多层感知机(MLP)对这两个向量进行处理,最后通过Sigmoid函数生成通道注意力权重。
-
空间注意力模块:首先沿通道维度进行最大池化和平均池化,得到两个二维特征图,然后将它们拼接起来,通过卷积层和Sigmoid函数生成空间注意力权重。
-
注意力融合:先将通道注意力权重与输入特征图相乘,然后将得到的特征图与空间注意力权重相乘,最终得到增强后的特征图。
CBAM注意力机制的优点在于结构简单、计算开销小,可以很容易地集成到现有的卷积神经网络中,提高模型的特征提取能力。
自适应空间特征融合理论
自适应空间特征融合是一种用于多尺度特征融合的先进技术,能够根据目标的大小和位置自适应地选择最适合的特征表示。ASFF的核心思想是通过可学习的参数对来自不同层级的特征图进行加权融合,而不是简单地相加或拼接。
ASFF的工作原理如下:
-
特征图调整:首先将来自不同层级的特征图调整到相同的空间尺寸(通常通过上采样或下采样实现)。
-
融合权重生成:通过轻量级的卷积网络对调整后的特征图进行处理,生成融合权重。融合权重的生成考虑了空间位置信息,使得不同位置可以有不同的融合权重。
-
加权融合:根据生成的融合权重,对调整后的特征图进行加权求和,得到最终的融合特征图。
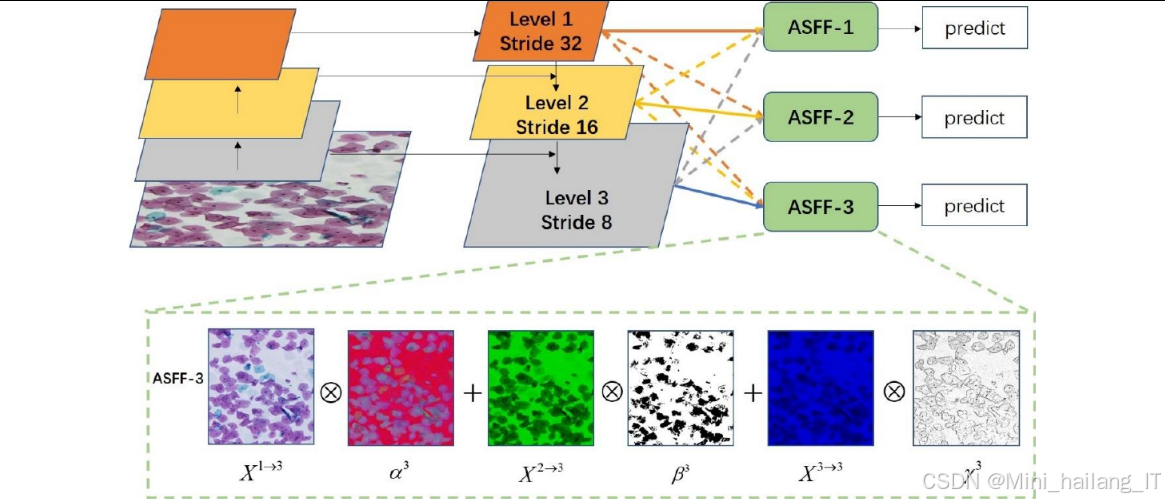
ASFF的数学表示如下:
对于输入的三个不同尺度的特征图F1, F2, F3(分别来自高层、中层和低层),首先将它们调整到相同的尺度,然后通过卷积网络生成三个融合权重W1, W2, W3,满足W1 + W2 + W3 = 1。最终的融合特征图F融合可以表示为:
F融合 = W1 * F1 + W2 * F2 + W3 * F3
其中,融合权重W1, W2, W3是位置相关的,即不同空间位置的权重可能不同。这种设计使得ASFF能够根据目标的大小和位置自适应地选择最适合的特征表示,提高模型对多尺度目标的检测能力。
对比自监督学习原理
对比自监督学习是自监督学习的一种重要方法,通过构建正例和负例样本对,学习数据的语义表示。对比自监督学习的核心思想是让相似的样本在特征空间中距离更近,不同的样本在特征空间中距离更远。
对比自监督学习的主要组成部分包括:
-
数据增强:通过不同的数据增强策略对原始数据进行处理,生成多个视图。通常,同一个样本的不同视图被视为正例对,不同样本的视图被视为负例对。
-
特征提取网络:用于从数据中提取特征表示,通常是一个深度卷积神经网络。
-
投影头:用于将提取的特征映射到低维空间,便于计算相似度。
-
对比损失函数:用于衡量样本对之间的相似性,常见的对比损失函数包括Triplet Loss、Contrastive Loss、NT-Xent Loss和InfoNCE Loss等。
BYOL(Bootstrap Your Own Latent)是一种创新的对比自监督学习方法,它不依赖于负例样本,而是通过构建在线网络和目标网络两个结构相同但参数不同的网络来学习特征表示。BYOL的工作原理如下:
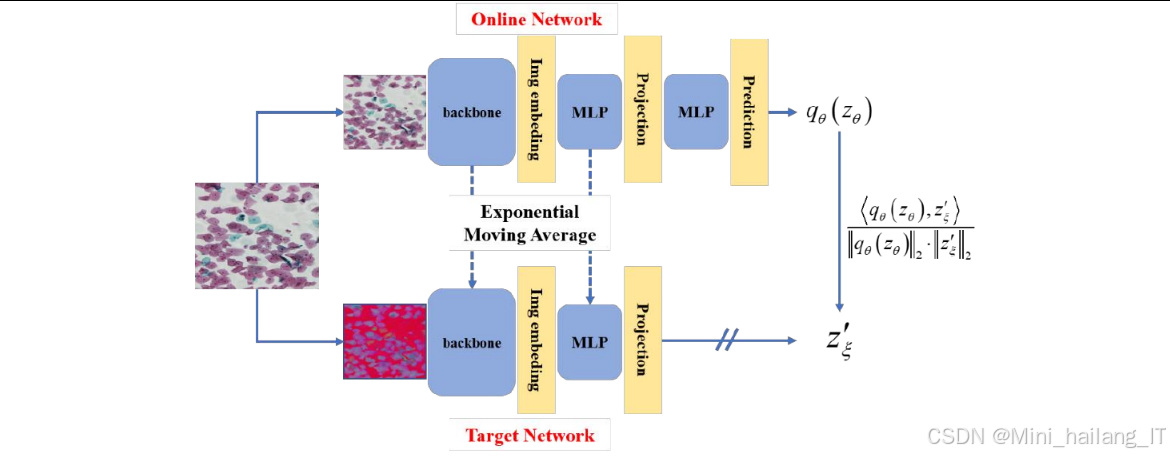
-
双网络结构:BYOL包含在线网络和目标网络两个结构相同的网络。在线网络的参数通过梯度下降直接更新,目标网络的参数则通过在线网络参数的指数移动平均进行更新。
-
数据增强:对每个样本生成两个不同的增强视图,分别输入到在线网络和目标网络中。
-
特征提取与投影:两个网络分别对输入视图进行特征提取和投影,生成特征表示。
-
预测头:在线网络还包含一个预测头,用于预测目标网络的特征表示。
-
损失函数:通过最小化在线网络的预测结果和目标网络的特征表示之间的距离来训练模型。
BYOL的优点在于不依赖于负例样本,避免了负例采样带来的问题,同时通过在线网络和目标网络的设计,有效地避免了模型坍塌到恒等映射的问题。
色彩空间转换理论
色彩空间是描述颜色的数学模型,不同的色彩空间有不同的特点和应用场景。在图像处理中,常用的色彩空间包括RGB、HSV、HSL等。
RGB色彩空间是最常用的色彩空间之一,它使用红(Red)、绿(Green)、蓝(Blue)三个通道来表示颜色。RGB色彩空间的优点是直观、计算简单,但它的三个通道之间存在较高的相关性,不便于独立调整亮度和颜色信息。
HSV色彩空间则将颜色分为色相(Hue)、饱和度(Saturation)和明度(Value)三个通道,具有以下优点:
-
亮度与颜色分离:HSV色彩空间将亮度信息(V通道)与颜色信息(H和S通道)分离,便于独立调整亮度和颜色。
-
更符合人类视觉感知:HSV色彩空间的三个通道更符合人类对颜色的感知方式,色相表示颜色的种类,饱和度表示颜色的纯度,明度表示颜色的亮度。
-
更准确的颜色距离计算:在HSV色彩空间中,颜色之间的距离更符合人类对颜色差异的感知,可以更准确地进行颜色比较和分析。
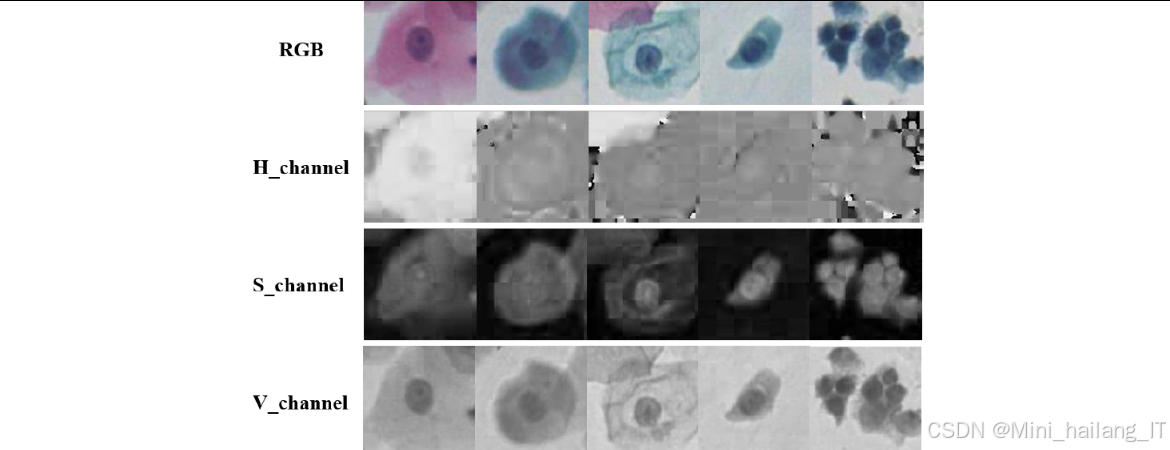
在本研究中,我们将RGB色彩空间转换为HSV色彩空间,主要基于以下考虑:
-
减少光照和染色差异的影响:通过分离亮度信息和颜色信息,可以更好地处理由于光照和染色剂不同导致的图像差异。
-
提高颜色特征的鲁棒性:HSV色彩空间中的颜色特征更加稳定,不易受到光照变化的影响,有利于提高模型的鲁棒性。
-
增强对比学习效果:在对比自监督学习中,使用HSV色彩空间可以构建更有效的正例样本对,帮助模型学习到更有区分力的特征表示。
核心代码介绍
A-ELAN注意力特征提取模块
A-ELAN模块的核心结构,包括主分支、三个卷积分支、CBAM注意力机制和残差连接。A-ELAN模块的工作流程如下:首先通过1×1卷积将输入特征图的通道数调整为c2;然后将特征图分为四个分支,其中第一个分支直接进行1×1卷积,后三个分支通过3×3卷积逐步提取特征;接着将四个分支的特征图在通道维度上拼接,并通过1×1卷积将通道数压缩回c1;然后通过CBAM注意力机制对特征图进行增强,重点关注重要的通道和空间位置;最后通过残差连接和SiLU激活函数输出最终的特征图。
A-ELAN模块是在YOLOv7的ELAN结构基础上添加CBAM注意力机制形成的,它能够有效地提高模型对小目标的特征提取能力。以下是A-ELAN模块的核心代码实现:
class A_ELAN(nn.Module):
def __init__(self, c1, c2, c3, c4, e=0.5):
super().__init__()
# 输入通道数
self.c1 = c1
# 输出通道数
self.c2 = c2
self.c3 = c3
self.c4 = c4
# 扩展系数
self.e = e
# 主分支卷积层
self.cv1 = Conv(c1, c2, 1, 1)
# 三个分支的卷积层
self.cv2 = Conv(c2, c2, 1, 1)
self.cv3 = Conv(c2, c2, 3, 1)
self.cv4 = Conv(c2, c2, 3, 1)
# 连接后的卷积层
self.cv5 = Conv(c2 * 4, c1, 1, 1)
# 添加CBAM注意力机制
self.cbam = CBAM(c1)
# 激活函数
self.silu = nn.SiLU()
def forward(self, x):
# 主分支处理
y = self.cv1(x)
# 分支1
y1 = self.cv2(y)
# 分支2
y2 = self.cv3(y)
# 分支3
y3 = self.cv4(y2)
# 分支4
y4 = self.cv4(y3)
# 连接所有分支
y = torch.cat([y1, y2, y3, y4], dim=1)
# 卷积压缩通道数
y = self.cv5(y)
# 添加CBAM注意力机制
y = self.cbam(y)
# 残差连接
y = self.silu(y + x)
return y
CBAM注意力机制的添加是A-ELAN模块的关键创新点,它能够自适应地调整特征图中不同通道和空间位置的权重,帮助模型聚焦于图像中的关键区域,特别是小目标区域。
ASFF自适应空间特征融合模块
ASFF模块的核心逻辑,包括特征图尺寸调整、融合权重生成和特征加权融合等功能。ASFF模块的工作流程如下:首先根据当前层级,通过上采样或下采样将来自不同层级的特征图调整到相同的空间尺寸;然后通过1×1卷积将各层特征图的通道数调整为相同,并生成权重特征图;接着将三个权重特征图在通道维度上拼接,通过1×1卷积和softmax函数生成最终的融合权重;最后根据融合权重对调整后的特征图进行加权求和,得到融合后的特征图。ASFF模块是本研究中用于特征融合的核心组件,它通过可学习的参数对来自不同层级的特征图进行加权融合,提高了检测头对多尺度特征的利用效率。以下是ASFF模块的核心代码实现:
class ASFF(nn.Module):
def __init__(self, level, c1, c2, c3):
super().__init__()
# 特征层级
self.level = level
# 输入通道数
self.c1 = c1
self.c2 = c2
self.c3 = c3
# 输出通道数
self.inter_dim = c3
# 卷积层用于调整通道数和生成融合权重
self.upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.downsample = nn.MaxPool2d(kernel_size=2)
# 权重生成卷积层
self.weight_level_1 = Conv(c1, self.inter_dim, 1, 1)
self.weight_level_2 = Conv(c2, self.inter_dim, 1, 1)
self.weight_level_3 = Conv(c3, self.inter_dim, 1, 1)
# 权重融合卷积层
self.weight_levels = Conv(self.inter_dim * 3, 3, 1, 1)
# 特征融合卷积层
self.conv = Conv(self.inter_dim, c3, 3, 1, 1)
# 激活函数
self.relu = nn.ReLU()
def forward(self, x):
# x是一个包含三个不同尺度特征图的列表
x_level_1, x_level_2, x_level_3 = x
# 根据层级调整特征图尺寸
if self.level == 0:
x_level_2 = self.downsample(x_level_2)
x_level_3 = self.downsample(self.downsample(x_level_3))
elif self.level == 1:
x_level_1 = self.upsample(x_level_1)
x_level_3 = self.downsample(x_level_3)
elif self.level == 2:
x_level_1 = self.upsample(self.upsample(x_level_1))
x_level_2 = self.upsample(x_level_2)
# 生成各层特征的权重
level_1_weight_v = self.weight_level_1(x_level_1)
level_2_weight_v = self.weight_level_2(x_level_2)
level_3_weight_v = self.weight_level_3(x_level_3)
# 拼接权重特征图
levels_weight_v = torch.cat([level_1_weight_v, level_2_weight_v, level_3_weight_v], dim=1)
# 生成最终的融合权重
levels_weight = self.weight_levels(levels_weight_v)
levels_weight = F.softmax(levels_weight, dim=1)
# 调整输入特征图的通道数
if self.c1 != self.inter_dim:
x_level_1 = self.weight_level_1(x_level_1)
if self.c2 != self.inter_dim:
x_level_2 = self.weight_level_2(x_level_2)
if self.c3 != self.inter_dim:
x_level_3 = self.weight_level_3(x_level_3)
# 加权融合特征图
fused_out_reduce = x_level_1 * levels_weight[:, 0:1, :, :] + \
x_level_2 * levels_weight[:, 1:2, :, :] + \
x_level_3 * levels_weight[:, 2:3, :, :]
# 卷积调整输出特征
out = self.conv(fused_out_reduce)
return out
ASFF模块的关键创新点在于其自适应的特征融合方式,它通过可学习的参数自动确定不同层级特征的重要性,使得检测头能够根据目标的大小和位置选择最适合的特征表示。实验结果表明,ASFF模块的使用使模型的mAP@0.5提升了0.34%,进一步提高了对宫颈癌细胞的检测性能。
HSV-BYOL自监督学习框架
HSV-BYOL自监督学习框架的核心逻辑,包括在线网络、目标网络、投影头、预测头以及损失函数的设计。HSV-BYOL框架的工作流程如下:首先创建结构相同的在线网络和目标网络,在线网络的参数通过梯度下降直接更新,目标网络的参数则通过在线网络参数的指数移动平均进行更新;然后对每个样本生成两个RGB格式的视图和一个HSV格式的视图,分别输入到在线网络和目标网络中;接着通过投影头和预测头生成特征表示;最后计算不同视图组合之间的损失,包括RGB视图之间的损失和RGB-HSV视图之间的损失。HSV-BYOL自监督学习框架是本研究中用于分类模型预训练的核心组件,它结合了BYOL自监督学习和HSV色彩空间转换,能够有效地利用未标注数据进行预训练。以下是HSV-BYOL框架的核心代码实现:
class HSV_BYOL(nn.Module):
def __init__(self, base_encoder, dim=256, pred_dim=4096):
super().__init__()
# 创建在线网络和目标网络
self.online_encoder = base_encoder()
self.target_encoder = base_encoder()
# 获取编码器的输出维度
dim_mlp = self.online_encoder.fc.weight.shape[1]
# 替换编码器的全连接层
self.online_encoder.fc = nn.Identity()
self.target_encoder.fc = nn.Identity()
# 在线网络的投影头
self.online_projector = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp),
nn.BatchNorm1d(dim_mlp),
nn.ReLU(inplace=True),
nn.Linear(dim_mlp, dim),
nn.BatchNorm1d(dim)
)
# 在线网络的预测头
self.online_predictor = nn.Sequential(
nn.Linear(dim, pred_dim),
nn.BatchNorm1d(pred_dim),
nn.ReLU(inplace=True),
nn.Linear(pred_dim, dim)
)
# 目标网络的投影头(不更新参数)
self.target_projector = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp),
nn.BatchNorm1d(dim_mlp),
nn.ReLU(inplace=True),
nn.Linear(dim_mlp, dim),
nn.BatchNorm1d(dim)
)
# 初始化目标网络参数
self._initialize_weights()
self._momentum_update_target_network(0)
def _initialize_weights(self):
# 初始化权重
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight, std=0.01)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm1d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
@torch.no_grad()
def _momentum_update_target_network(self, m):
# 动量更新目标网络参数
for param_q, param_k in zip(self.online_encoder.parameters(), self.target_encoder.parameters()):
param_k.data = param_k.data * m + param_q.data * (1. - m)
for param_q, param_k in zip(self.online_projector.parameters(), self.target_projector.parameters()):
param_k.data = param_k.data * m + param_q.data * (1. - m)
def forward(self, x1, x2, x1_hsv):
# x1: RGB格式视图1
# x2: RGB格式视图2
# x1_hsv: HSV格式视图1
# 在线网络处理RGB视图1
z1 = self.online_projector(self.online_encoder(x1))
p1 = self.online_predictor(z1)
# 在线网络处理RGB视图2
z2 = self.online_projector(self.online_encoder(x2))
p2 = self.online_predictor(z2)
# 在线网络处理HSV视图1
z1_hsv = self.online_projector(self.online_encoder(x1_hsv))
p1_hsv = self.online_predictor(z1_hsv)
# 目标网络处理(不计算梯度)
with torch.no_grad():
# 更新目标网络参数
self._momentum_update_target_network(0.996)
# 目标网络处理RGB视图1
z1_target = self.target_projector(self.target_encoder(x1))
# 目标网络处理RGB视图2
z2_target = self.target_projector(self.target_encoder(x2))
# 目标网络处理HSV视图1
z1_hsv_target = self.target_projector(self.target_encoder(x1_hsv))
# 计算损失
# RGB视图1与RGB视图2的损失
loss1 = F.mse_loss(p1, z2_target.detach())
loss2 = F.mse_loss(p2, z1_target.detach())
# RGB视图1与HSV视图1的损失
loss3 = F.mse_loss(p1, z1_hsv_target.detach())
loss4 = F.mse_loss(p1_hsv, z1_target.detach())
# 总损失
loss = loss1 + loss2 + loss3 + loss4
return loss
HSV-BYOL框架的关键创新点在于引入了HSV色彩空间转换,构建了RGB-HSV的正例样本对,这种设计能够更好地捕捉宫颈细胞的颜色特征,减少染色和光照差异的影响。
重难点和创新点
难点
本研究在实施过程中面临以下几个主要难点:
-
宫颈癌细胞小目标检测:宫颈癌细胞在图像中通常表现为小目标,且背景复杂,传统目标检测算法在这种场景下检测性能不佳。如何提高模型对小目标的检测能力是本研究的首要难点。
-
标注数据获取困难:高质量的医学图像标注需要专业医师的参与,成本高昂且耗时。如何利用有限的标注数据训练高性能的模型是本研究的另一个重要难点。
-
数据质量差异:由于样本采集、制片和染色过程的差异,宫颈细胞图像存在较大的质量差异,包括清晰度、对比度和色彩分布等方面的差异,这些差异增加了模型训练的难度。
-
模型鲁棒性:医学图像分析对模型的鲁棒性要求较高,模型需要能够应对各种干扰因素,如噪声、光照变化和染色差异等。如何提高模型的鲁棒性是本研究的技术难点之一。
-
实时性能要求:宫颈癌筛查需要处理大量的图像数据,对模型的推理速度有较高要求。如何在保证检测精度的同时满足实时性能要求是本研究的工程难点。
创新点
针对上述难点,本研究提出了以下技术创新点:
-
AASFF-YOLO检测模型:提出了融合注意力机制和自适应空间特征融合的AASFF-YOLO检测模型。通过在YOLOv7的ELAN模块后添加CBAM注意力机制 ,提高了模型对小目标的特征提取能力;通过在检测头部分添加ASFF自适应空间特征融合策略,提高了模型对多尺度特征的利用效率。
-
HSV-BYOL自监督分类算法:提出了基于HSV色彩空间的BYOL自监督分类算法。通过将宫颈细胞图像转换为HSV色彩空间,并将其作为BYOL自监督框架的正例输入,更好地捕捉了宫颈细胞的颜色特征,减少了染色和光照差异的影响
-
两阶段检测分类融合框架:构建了两阶段的宫颈癌自动检测分类框架,将检测模块和分类模块的优势相结合。通过正常细胞采样算法和检测分类融合算法,有效地平衡了查全率和查准率,提高了系统的整体性能。
-
对抗训练策略:在AASFF-YOLO模型训练过程中引入了PGD对抗训练策略,通过生成对抗样本并将其纳入训练集,增强了模型对对抗攻击的防御能力,提高了模型的鲁棒性和安全性。
-
HSV色彩空间数据增强:针对宫颈细胞图像的特点,提出了基于HSV色彩空间的数据增强策略,通过分离亮度信息和颜色信息,更好地处理了由于光照和染色剂不同导致的图像差异,提高了模型的泛化能力。
本研究在应用方面也有以下创新点:
-
临床实用性:研发的宫颈癌自动检测分类系统在保证检测精度的同时,保持了较高的推理速度,能够满足临床应用的实时性要求。系统的查全率和查准率分别达到85.8%和82.3%,可以作为辅助医师诊断的可靠工具。
-
可扩展性:系统的模块化设计使其具有良好的可扩展性,可以方便地集成新的算法和功能。同时,系统的核心技术可以推广到其他类型的医学图像分析任务中,如乳腺癌筛查、肺癌CT影像分析等。
-
低成本实现:通过自监督学习和数据增强技术,系统降低了对高质量标注数据的依赖,减少了数据获取的成本。同时,系统的模型结构经过优化,计算效率较高,可以在普通GPU设备上运行,降低了部署成本。
总结
本研究聚焦于宫颈癌细胞图像识别领域,针对现有技术在小目标检测、标注数据依赖、查全率和查准率平衡等方面的不足,提出了一系列创新方法,并构建了一套完整的宫颈癌自动检测分类系统。主要工作总结如下:
-
改进的目标检测算法:基于YOLOv7提出了AASFF-YOLO检测模型,通过融合CBAM注意力机制和ASFF自适应空间特征融合策略,显著提高了对宫颈癌细胞小目标的检测能力。
-
自监督分类算法:提出了基于HSV色彩空间的BYOL自监督分类算法,有效利用大量未标注数据进行预训练,降低了对标注数据的依赖。
-
两阶段检测分类框架:构建了两阶段的宫颈癌自动检测分类框架,将检测模块和分类模块的优势相结合,通过正常细胞采样算法和检测分类融合算法,有效平衡了查全率和查准率。
参考文献
[1] Bochkovskiy A, Wang C Y, Liao H Y M. YOLOv4: Optimal speed and accuracy of object detection[J]. arXiv preprint arXiv:2004.10934, 2020.
[2] Wang C Y, Bochkovskiy A, Liao H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 7464-7475.
[3] Woo S, Park J, Lee J Y, et al. CBAM: Convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 3-19.
[4] Liu S, Huang D, Wang Y. Learning spatial fusion for single-shot object detection[J]. arXiv preprint arXiv:1911.09516, 2019.
[5] Grill J B, Strub F, Altché F, et al. Bootstrap your own latent-a new approach to self-supervised learning[J]. Advances in neural information processing systems, 2020, 33: 21271-21284.
[6] Azizi S, Mustafa B, Ryan F, et al. Big self-supervised models advance medical image classification[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 3478-3488.
[7] Madry A, Makelov A, Schmidt L, et al. Towards deep learning models resistant to adversarial attacks[J]. arXiv preprint arXiv:1706.06083, 2017.
[8] Zhang L, Lu L, Nogues I, et al. DeepPap: deep convolutional networks for cervical cell classification[J]. IEEE journal of biomedical and health informatics, 2017, 21(6): 1633-1643.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









