




 本文介绍了如何利用深度学习中的RNN和GRU构建一个英汉翻译系统,包括项目背景、设计思路,重点描述了数据集的创建和模型实验过程,展示了如何通过BP算法训练神经网络以提高翻译质量和效率。
本文介绍了如何利用深度学习中的RNN和GRU构建一个英汉翻译系统,包括项目背景、设计思路,重点描述了数据集的创建和模型实验过程,展示了如何通过BP算法训练神经网络以提高翻译质量和效率。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于深度学习的英汉翻译系统
项目背景
随着全球化的不断发展,跨语言交流变得越来越重要。英汉翻译作为其中的一种重要形式,对于促进跨文化交流、推动国际合作具有重要意义。然而,英汉翻译的准确性和流畅度一直是一个挑战,尤其是在语义和语境的理解方面。基于深度学习的英汉翻译系统能够利用大数据和神经网络模型,从海量的双语语料库中学习,提高翻译的质量和效率。
设计思路
循环神经网络(RNN)是深度学习领域中的一种特殊类型的神经网络,其核心特点在于其隐藏层的输出不仅作为当前时间步的输出,还作为下一个时间步的输入,从而实现了对序列数据的处理。这种结构使得RNN能够捕捉输入序列中的时间依赖性,特别适用于处理如文本、语音、时间序列等连续数据。RNN的学习算法采用的是BPTT,即时间反向传播算法,通过反向传播梯度来更新网络权重。RNN的设计初衷是为了解决源语言之间相互关联的问题,并在处理长距离依赖关系上展现出强大的能力。
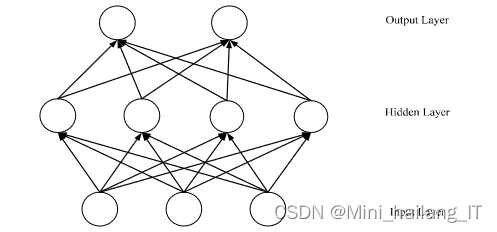
在传统的前馈神经网络(FNN)中,各层之间的神经元是完全连接的,但在同一层内的神经元之间则没有连接。这种连接方式在处理某些任务时存在局限性,特别是在需要利用序列数据中时间依赖性的情况下。例如,当使用FNN预测下一个输出时,它必须依赖于前面的部分信息,这增加了预测的复杂性,可能导致速率下降和依赖性增强。为了解决这个问题,循环神经网络(RNN)被引入。RNN通过其特殊的隐藏层结构,能够在不同时间步之间传递信息,从而更有效地处理序列数据中的时间依赖性,降低了预测复杂度,提高了处理速度,并更好地捕捉了数据间的长期依赖关系。
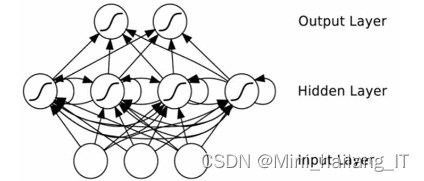
神经网络模拟人脑组织,体现处理过程及参数变化,具备分布式处理、多进程并行和自主学习等优势。随着发展,已在计算机视觉、图像识别、语音识别等领域取得显著效果。常用网络结构包括深度神经网络、卷积神经网络、循环递归神经网络和生成对抗网络等。神经网络可视为函数组合,能表示更复杂的函数,未来发展潜力巨大。
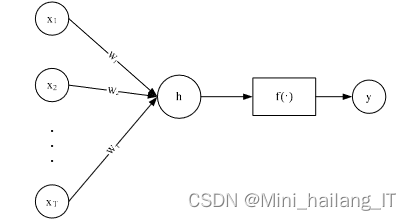
BP算法是神经网络训练中的核心算法之一,它通过误差的反向传播来更新网络中的权重,从而减小网络输出与实际目标值之间的误差。BP算法允许多层神经网络学习并逼近复杂的非线性函数,这在很多实际问题中是非常有用的。在BP神经网络中,输入层负责接收原始数据,并将其传递给隐藏层。隐藏层可以有一层或多层,它们对数据进行非线性变换,提取输入数据的特征。这些特征随后被传递到输出层,输出层根据隐藏层提供的特征产生最终的网络输出。
训练过程中,网络首先根据当前权重和偏置生成一个输出,然后计算这个输出与真实目标值之间的误差。这个误差随后被反向传播到网络中,用于更新每一层的权重和偏置,以减小未来的误差。这个过程反复进行,直到网络的输出与真实目标值之间的误差达到一个可接受的水平。
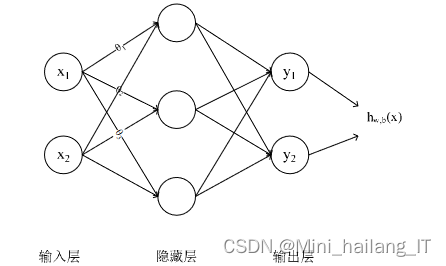
BP神经网络的结构使其能够处理各种复杂的任务,如图像识别、语音识别、自然语言处理等。其强大的表示能力来自于其能够学习并逼近复杂的非线性函数,这是单层感知机所无法做到的。然而,BP算法也存在一些问题,如容易陷入局部最小值、训练时间长等,这些问题在后续的研究中得到了不断的改进和优化。
GRU(Gated Recurrent Unit)神经网络是一种改进的循环神经网络(RNN)架构,它通过引入门控机制来更有效地捕捉序列数据中的长期依赖关系。GRU使用更新门和重置门来控制信息的流动,从而避免了RNN中常见的梯度消失或爆炸问题。这种结构使得GRU在处理如自然语言处理、语音识别、时间序列预测等需要处理长期依赖关系的任务时表现出色。
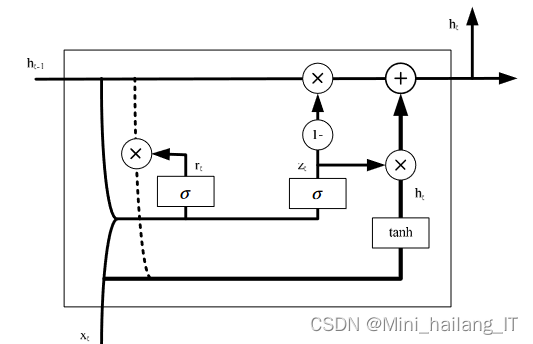
数据集
由于网络上缺乏现有的合适数据集,我决定自己收集数据并制作一个全新的数据集来支持基于深度学习的英汉翻译系统的研究。我搜集了大量的英文和中文文本,包括新闻、文章、小说等不同类型的语料。为了获取更准确的翻译结果,我还手动对一部分语料进行了校对和标注。通过这个自制的数据集,我能够提供更具代表性的训练样本,以及用于评估和测试的数据集。我相信这个自制的数据集将为基于深度学习的英汉翻译系统的研究提供有力的支持,并对该领域的发展做出积极贡献。

模型实验
实验步骤从处理数据开始,首先将输入和目标语句在网络层中索引并建立字典,包括“SOS”和“EOS”标志。接下来,将Unicode数据转换为ASCII格式,统一为小写并修剪标点。然后,将数据拆分为汉语和英语对照对,选取长度小于30的句子作为训练集。
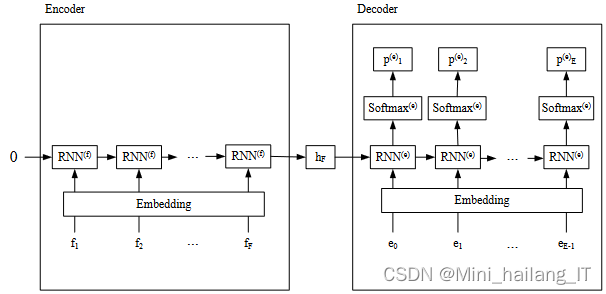
模型训练阶段,首先定义一个空序列用于逐步填入编码器的输出。编码器接收源语句序列,而解码器以开始符号<SOS>为起点,并利用编码器的最后一个隐藏层作为初始隐藏状态。通过迭代公式,解码器生成目标语句序列。在解码过程中,每次迭代都将当前输入和隐藏状态传入解码器,并结合编码器的输出进行计算。若解码过程中遇到结束符,则当前句子结束并终止循环。
相关代码示例:
# 训练过程
criterion = nn.NLLLoss()
optimizer = torch.optim.Adam(list(encoder.parameters()) + list(decoder.parameters()))
for epoch in range(num_epochs):
for i, (src_seq, tgt_seq) in enumerate(zip(src_sentences, tgt_sentences)):
# 将词序列转换为词嵌入张量
src_tensor = ... # 转换为源语句的词嵌入张量
tgt_tensor = ... # 转换为目标语句的词嵌入张量,包括<SOS>开始符号
# 编码过程
encoder_hidden, encoder_cell = encoder(src_tensor)
# 初始化解码器隐藏状态和细胞状态
decoder_hidden = encoder_hidden.detach()
decoder_cell = encoder_cell.detach()
# 解码过程
decoder_input = tgt_tensor[0] # 开始符号<SOS>
decoded_words = []
teacher_forcing_ratio = 0.5 # 教师强制比例,用于平衡使用真实目标和模型预测
for t in range(1, tgt_tensor.shape[0]):
decoder_output, decoder_hidden, decoder_cell = decoder(decoder_input, decoder_hidden, decoder_cell)
_, predicted = decoder_output.max(1)
# 以一定的概率使用真实目标,否则使用模型预测
decoder_input = tgt_tensor[t] if random.random() < teacher_forcing_ratio else predicted
decoded_words.append(predicted.item())
# 如果遇到结束符,则跳出循环
if predicted.item() == END_OF_SENTENCE_TOKEN:
break
# 计算损失
loss = criterion(decoder_output.view(-1, output_size), tgt_tensor[1:].view(-1))
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step() 
















 644
644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









