




 本文介绍了一种基于大数据的招聘数据可视化系统,涉及项目背景、数据处理方法(包括数据采集、清洗、存储)、网络爬虫技术的应用以及使用ECharts进行数据可视化展示的过程。还提到了Hive在数据处理中的作用,展示了如何通过这些技术来支持招聘行业决策和求职者快速获取信息。
本文介绍了一种基于大数据的招聘数据可视化系统,涉及项目背景、数据处理方法(包括数据采集、清洗、存储)、网络爬虫技术的应用以及使用ECharts进行数据可视化展示的过程。还提到了Hive在数据处理中的作用,展示了如何通过这些技术来支持招聘行业决策和求职者快速获取信息。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长大数据毕设专题,本次分享的课题是
🎯基于大数据的招聘数据可视化系统
项目背景
随着大数据时代的来临,招聘行业的数据量也在急剧增长。这些数据中蕴含着丰富的信息,对于了解市场趋势、人才需求、企业竞争状况等具有重要意义。因此,建立一个基于大数据的招聘数据可视化系统,旨在通过数据挖掘和分析技术,为招聘行业提供决策支持。这一课题将有助于提升招聘行业的效率和精准度,为企业和求职者提供更好的服务,同时为相关领域的发展提供有力支持。
设计思路
数据处理
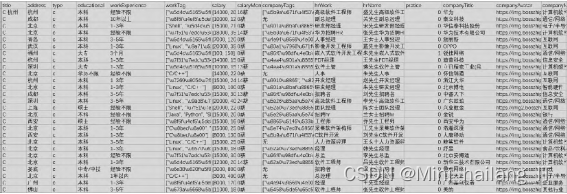
由于现有的招聘数据集无法满足本课题的需求,我决定自制一个全新的数据集。首先,从各大招聘网站、社交媒体平台和相关机构收集招聘数据,确保数据的全面性和准确性。然后,对收集到的数据进行清洗和预处理,包括去重、异常值处理、数据格式统一等操作。接着,将数据按照特定的结构存储在数据库中,以便后续的数据分析和可视化展示。为了提高数据的质量和多样性,我还从多个不同的招聘平台和行业收集数据,以获得更广泛的数据样本。
我们使用requests库发送HTTP请求获取招聘网站的数据,并假设数据以JSON格式返回。然后,我们将数据转换为DataFrame格式,以便进行数据清洗和预处理操作。在清洗和预处理阶段,我们可以根据实际需求进行一系列操作,如去重、异常值处理、数据格式统一等。最后,我们将清洗后的数据保存为CSV文件供后续分析和使用。
import requests
import pandas as pd
url = 'https://www.example.com/job_listings'
response = requests.get(url)
job_data = response.json()
job_df = pd.DataFrame(job_data)
job_df = job_df.drop_duplicates()
job_df.to_csv('job_data.csv', index=False) 系统实验
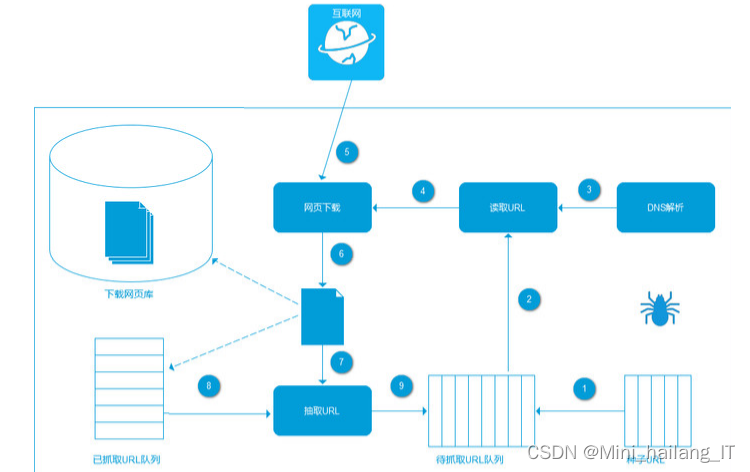
网络爬虫技术是一种通过编写计算机程序,按照一定的规则,自动化地爬取目标网页的数据信息的技术。通过网络爬虫,我们可以收集有价值的数据,并对其进行过滤和清洗,从而获得充足的数据资源,用于进行各种相关项目的研究和分析。
在爬取目标网站的招聘信息时,我们首先需要构建一个爬虫程序,该程序可以模拟浏览器行为,向目标网站的URL发出请求,并获取URL的返回结果。然后,我们对返回结果进行分析,提取出所需的招聘信息,例如职位名称、公司名称、工作地点、薪资待遇等。
import requests
from bs4 import BeautifulSoup
url = 'https://www.example.com/job_listings'
response = requests.get(url)
html_content = response.content
soup = BeautifulSoup(html_content, 'html.parser')
job_listings = []
job_elements = soup.find_all('div', class_='job')
for job_element in job_elements:
job_title = job_element.find('h2').text.strip()
company_name = job_element.find('span', class_='company').text.strip()
location = job_element.find('span', class_='location').text.strip()
job_data = {
'job_title': job_title,
'company_name': company_name,
'location': location
}
job_listings.append(job_data)
for job in job_listings:
print('Job Title:', job['job_title'])
print('Company Name:', job['company_name'])
print('Location:', job['location'])
print('---')数据可视化是从数据中抽象出信息,并以清晰且简单明了的方式展现出来的过程。它是一种高效的信息沟通手段,通过图形图像处理、计算机视觉和用户界面等技术方法,将经过预处理的原始数据以清晰可视的方式展示出来。数据可视化的主要目的是通过简单的图形图像传达和沟通所获取的数据信息。 使用EChart作为可视化库来实现图表展示部分。EChart拥有强大的功能和强大的兼容性,通过散点图、饼图、折线图和不同频次的词云图等可视化方式,为求职人员清晰地展示招聘信息,使求职过程更加快速高效。
Hive是基于Hadoop的数据仓库基础设施,具有强大的数据处理能力和高可扩展性。它使用类似于SQL的查询语言,方便数据分析和查询操作,并通过优化查询执行计划提高性能。Hive支持复杂的数据分析操作,与Hadoop生态系统紧密集成,同时提供可视化工具支持。综合而言,使用Hive进行统计和分析能够处理大规模数据集,提供灵活的查询语言和优化执行计划,支持复杂数据分析,并与其他工具整合,为数据分析提供强大而便捷的解决方案。
import requests
import pandas as pd
import matplotlib.pyplot as plt
def scrape_job_data():
url = "https://example.com/jobs"
response = requests.get(url)
return job_data
def clean_data(job_data):
return cleaned_data
def plot_salary_distribution(job_data):
salaries = job_data['salary']
plt.hist(salaries, bins=10)
plt.xlabel('Salary')
plt.ylabel('Count')
plt.title('Salary Distribution')
plt.show()
def plot_industry_count(job_data):
industry_counts = job_data['industry'].value_counts()
industry_counts.plot(kind='bar')
plt.xlabel('Industry')
plt.ylabel('Count')
plt.title('Industry Count')
plt.show()
def main():
job_data = scrape_job_data()
cleaned_data = clean_data(job_data)
plot_salary_distribution(cleaned_data)
plot_industry_count(cleaned_data)
if __name__ == "__main__":
main()
















 2074
2074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









