




 本文介绍了一种基于深度学习的海面目标检测系统,重点讨论了ShuffleNetv2Block和BiFPN在算法理论中的应用,以及如何通过优化这些结构来提高检测速度、精度和效率。作者还分享了实验过程和结果,展示了模型压缩和性能提升策略。
本文介绍了一种基于深度学习的海面目标检测系统,重点讨论了ShuffleNetv2Block和BiFPN在算法理论中的应用,以及如何通过优化这些结构来提高检测速度、精度和效率。作者还分享了实验过程和结果,展示了模型压缩和性能提升策略。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的海面目标检测算法系统
设计思路
一、课题背景与意义
基于深度学习的目标检测方法在船舶类目标检测领域具有重大研究意义。随着我国进出口贸易的繁荣发展,船舶数量和种类不断增加,对海上重要敏感区域的实时目标识别能力提出了更高的要求。通过利用深度学习技术,可以从海上图像或视频中自动识别和定位船舶目标,从而辅助海上执法工作。随着网络智能化的发展,深度学习在船舶目标检测领域的应用将继续受到重视并取得更多的研究成果。
二、算法理论原理
2.1 ShuffleNetv2 Block
YOLOv5是一种一阶段目标检测算法,通过在YOLOv4的基础上进行改进,提高了检测速度和精度。YOLOv5s是最小的模型,具有最小的计算量和参数量,因此被选择为改进的基线模型。YOLOv5s的模型结构包括输入端、骨干部分、颈部部分和预测部分。输入端包括输入图像和图像预处理,用于准备输入数据。骨干部分主要利用CSP(Cross Stage Partial)结构对输入图像进行特征提取。颈部部分使用FPN和PAN结构进行图像特征融合。预测部分使用损失函数和非极大值抑制(NMS)对图像进行目标预测和筛选。损失函数用于计算预测框与真实框之间的差异,并进行优化训练。
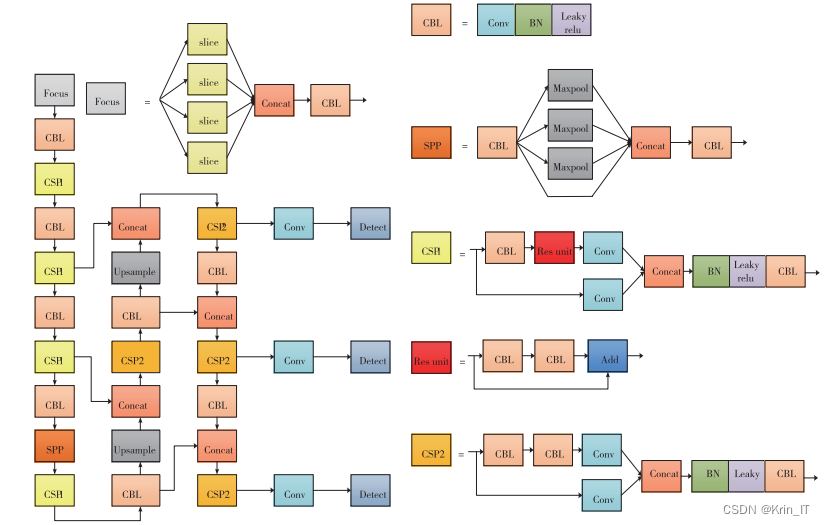
YOLOv5是一种一阶段目标检测算法,通过在YOLOv4的基础上进行改进,提高了检测速度和精度。其骨干部分由Focus、CBL、CSP和SPP组成,通过Focus操作进行特征点隔点采样并堆叠,在CBL中进行卷积、批归一化和激活函数处理,而CSP结构嵌入了残差结构来减少计算量并增加网络深度,同时SPP结构增强感受野。颈部部分采用FPN+PAN结构进行特征融合,而ShuffleNet和ShuffleNetv2是轻量级特征提取网络,平衡了速度和准确度。这些改进使得YOLOv5在目标检测任务中具有更高的性能和效率。
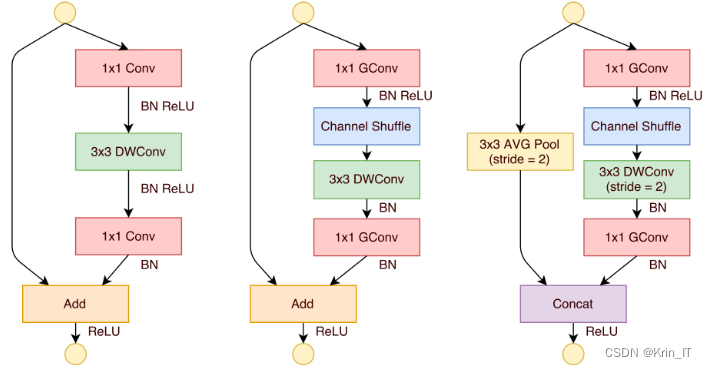
ShuffleNetv2引入了通道分割(Channel Split)操作,将输入特征图在通道维度上分为两部分,每部分的通道数相同。左边分支不进行任何操作,右边分支经过一系列卷积操作后输出,保持通道数不变。然后将左右两个分支的输出结果进行拼接(Concat)。接下来对拼接后的结果进行通道洗牌(Channel Shuffle),促进左右分支之间的信息交流。对于步长为2的ShuffleNetv2模块,不再使用通道分割,而是每个分支直接复制一份输入,每个分支都进行stride=2的下采样操作,最后再进行拼接,从而完成下采样操作。
2.2 Bi FPN
分组卷积会导致特征图的分组信息不流通,影响特征提取效果。为解决这问题,引入了Channel Shuffle来重新组合通道,实现特征信息的混合与流通。此外,加权双向特征金字塔网络(Bi FPN)改进了传统特征融合方法,删除对网络贡献较小的节点,通过添加连接线促进网络融合。Bi FPN采用带权重的特征融合方式,根据特征的重要度和分辨率进行分区处理,更充分地融合特征。综上所述,通过Channel Shuffle和Bi FPN,解决了分组卷积导致的信息流通问题,并实现了更有效的特征提取和融合。
注意力机制是一种模仿人脑工作方式的方法,常用于深度学习网络中以提高模型性能。SE Attention是目前广泛应用的注意力机制之一,通过全局池化计算通道注意力来促进通道间信息交互。然而,SE Attention忽略了位置信息的重要性,而坐标注意力机制则综合考虑了通道和位置信息。坐标注意力通过池化编码捕捉通道和位置信息,并通过卷积和加权处理得到既关注通道又涵盖位置的特征。综上所述,注意力机制可以让模型更关注重要内容,而坐标注意力机制则更全面地考虑通道和位置信息,对于提升目标检测模型具有重要意义。
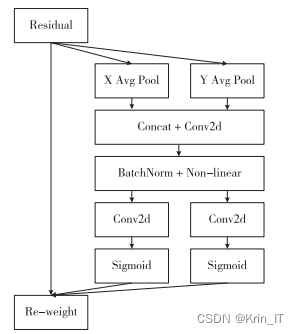
相关代码:
import torch
import torch.nn as nn
class FeatureFusion(nn.Module):
def __init__(self, in_channels, weights):
super(FeatureFusion, self).__init__()
self.weights = weights
# 定义特征融合层
self.fusion_layer = nn.Conv2d(in_channels, 1, kernel_size=1)
self.sigmoid = nn.Sigmoid()
def forward(self, features):
weighted_features = []
# 对每个特征进行加权处理
for i, feature in enumerate(features):
weighted_feature = feature * self.weights[i]
weighted_features.append(weighted_feature)
# 将加权特征进行特征分区处理
fused_feature = torch.cat(weighted_features, dim=1)
fused_feature = self.fusion_layer(fused_feature)
fused_feature = self.sigmoid(fused_feature)
return fused_feature三、检测的实现
3.1 数据集
由于网络上没有现有的合适数据集,我决定自己进行现场拍摄,创建了一个全新的海面目标检测数据集。海面目标分为八类,包括轮渡、浮标、大船、快艇、小船、皮艇、帆船和其他。数据集中的视频每隔15帧提取一张图片,共截取了1240张不同的海面目标图片。根据7:3的比例,将数据集划分为训练集和测试集,其中训练集包含868张图片,测试集包含372张图片。通过在岸上拍摄,我能够捕捉到真实的海面环境和多样的目标情况,这将为我的研究提供更准确、可靠的数据。

数据集使用MAKE SENSE在线标注软件进行标注,标注格式为TXT,适用于YOLOv5模型训练。每张图片标注完成后,生成一个.txt文本文件,其中存储了每个标签的信息。文本文件中的内容以空格分隔,第一列为目标类型,后续四列为坐标信息,依次表示标注物的中点x坐标、中点y坐标、宽度和高度。
def parse_annotation(txt_file):
with open(txt_file, 'r') as file:
lines = file.readlines()
annotations = []
for line in lines:
values = line.strip().split()
label = values[0]
x = float(values[1])
y = float(values[2])
width = float(values[3])
height = float(values[4])
annotation = {
'label': label,
'x': x,
'y': y,
'width': width,
'height': height
}
annotations.append(annotation)
return annotations3.2 实验环境搭建
在实验中,设置输入图片和验证图片的大小均为640×640。训练轮数被设置为200轮,批处理大小为32。动量被设置为0.937,初始学习率为0.01,权值衰减系数为0.0005。为了丰富数据集并提高网络的训练速度,采用了Mosaic数据增强技术。
3.3 实验及结果分析
在评价模型性能时,常用的指标包括Precision(查准率)、Recall(召回率)、PR曲线、AP(平均精度)、mAP(平均精度均值)、计算量和参数量。Precision是预测为正样本中预测正确的比率,Recall是所有正样本中预测正确的比率。PR曲线由Recall作为横坐标、Precision作为纵坐标组成,AP是PR曲线下的面积,mAP是各类别AP的平均值,用于衡量模型在所有类别上的性能好坏。计算量和参数量反映了模型的大小和复杂度。因此,选择Precision、Recall、mAP、计算量和参数量作为模型的评价指标,用于综合衡量模型的性能和效率。

通过将轻量级网络ShuffleNetv2 Block替换YOLOv5的骨干网络,成功压缩了模型的参数量和计算量,分别达到了56.8%和56.3%的压缩比。尽管模型的P(查准率)、R(召回率)和mAP(平均精度)相比原网络略有降低,但在颈部部分使用BiFPN结构提高了网络的特征融合能力,并仅增加了少量参数,将模型的准确率、召回率和平均精度提高至原YOLOv5水平。
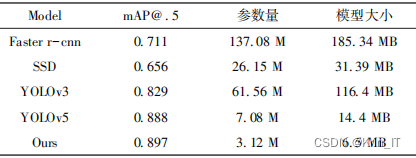
通过重新设计网络的骨干部分,使用ShuffleNetv2 Block替代特征提取部分,大大压缩了模型的计算量和参数量。在颈部部分采用加权双向特征金字塔网络,有效融合特征提取结果,提升了检测性能。引入坐标注意力机制,同时考虑通道信息和位置信息。改进后的模型相较于YOLOv5在平均精度、准确率、召回率方面有明显提升,同时在计算量和参数量上有显著降低。
相关代码如下:
import torch
from torchvision.models import yolov5
# 加载预训练的YOLOv5模型
model = yolov5s(pretrained=True)
# 设置模型为评估模式
model.eval()
# 定义类别标签
class_labels = ['ship', 'buoy', 'sea']
# 加载测试图像
image = torch.randn(1, 3, 416, 416) # 示例输入图像,尺寸为(1, 3, 416, 416)
# 运行图像通过模型进行推理
with torch.no_grad():
outputs = model(image)
# 解析预测结果
pred_boxes = outputs.pred[0][:, :4] # 预测框坐标
pred_scores = outputs.pred[0][:, 4] # 预测置信度
pred_class_indices = outputs.pred[0][:, 5].long() # 预测类别索引
# 根据置信度阈值过滤预测结果
threshold = 0.5 # 置信度阈值
filtered_indices = pred_scores >= threshold
filtered_boxes = pred_boxes[filtered_indices]
filtered_scores = pred_scores[filtered_indices]
filtered_class_indices = pred_class_indices[filtered_indices]
# 打印过滤后的预测结果
for box, score, class_index in zip(filtered_boxes, filtered_scores, filtered_class_indices):
class_label = class_labels[class_index]
print(f"Class: {class_label}, Score: {score}, Box: {box}")实现效果图样例

创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 8869
8869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









