




 本文深入介绍了PageRank算法的工作原理及应用,包括基本的PageRank计算公式、阻尼因素的引入及其影响,同时还探讨了PageRank算法的一种改进形式——TrustRank算法,以及另一种重要的排序算法HITS算法。
本文深入介绍了PageRank算法的工作原理及应用,包括基本的PageRank计算公式、阻尼因素的引入及其影响,同时还探讨了PageRank算法的一种改进形式——TrustRank算法,以及另一种重要的排序算法HITS算法。
PageRank Description
PageRank是对搜索引擎搜索结果的排序算法,根据谷歌的描述:
PageRank works by counting the number and quality of links to a page to determine a rough estimate of how important the website is. The underlying assumption is that more important websites are likely to receive more links from other websites.
PageRank算法
出边迭代(Link value iteration)
谷歌在从网络上爬取一次网页数据就会重新计算PageRankPageRank和网页索引。
假设有四个web网页A, B, C和D组成的网络,忽略网页的自环边。将一个网页指向另一个网页的多条出边看作单独的一个link链接。所有网页的初始PageRank值相等,为了更好地展现概率,所有网页的初始PageRank和为1。这里有
PR(A)=PR(B)=PR(C)=PR(D)PR(A)=PR(B)=PR(C)=PR(D)
example 1:
如果图中只有B,C,D指向A的三条边,那么在第一次迭代后,网络中的三个节点都会向A传递0.25PageRank0.25PageRank,因此有
PR(A)=PR(B)+PR(C)+PR(D)PR(A)=PR(B)+PR(C)+PR(D),A的PageRankPageRank值因此变为0.75。example 2:
假设B link to C和A,C link to A, D link to all three。因此B会向A传递1/2的PageRankPageRank,C向A传递1/1的PageRankPageRank值,D向A传递1/3的PageRankPageRank值,由此可得
PR(A)=PR(B)2+PR(C)1+PR(D)3PR(A)=PR(B)2+PR(C)1+PR(D)3
因此,在所有情况下可得出page u的PageRankPageRank值
PR(u)=∑v∈BuPR(v)L(v)PR(u)=∑v∈BuPR(v)L(v)
其中每个页面u的PageRankPageRank值与每个和它邻接的页面vv有关。邻接页面集为, L(v)L(v)为该顶点的出边数。
阻尼因素
PageRank算法基于一个理想的情况,一个随机点击网页链接的用户终将停止他的随机点击行为。在整个随机点击的过程中,该用户在任何中间步骤中继续的概率称为阻尼因素dd。则为用户停止点击的概率。
根据阻尼因素改进后的PageRank
PR(A)=1−d+d(PR(B)L(B)+PR(C)L(C)+PR(D)L(D))(1)(1)PR(A)=1−d+d(PR(B)L(B)+PR(C)L(C)+PR(D)L(D))
PR(A)=1−dN+d(PR(B)L(B)+PR(C)L(C)+PR(D)L(D))(2)(2)PR(A)=1−dN+d(PR(B)L(B)+PR(C)L(C)+PR(D)L(D))
在第一个公式中PageRankPageRank值之和为N,在第二个公式中PageRankPageRank值之和为1。
其中dd为阻尼因素,为用户在任何中间步骤停止的浏览的概率
终止条件
如果存在一个网页与网络中其他所有网页没有链接,则网页浏览行为终止。
计算过程
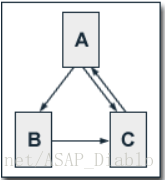
设置damping factor为0.5,利用公式(1)(1)来对网络中节点的PageRankPageRank进行计算。
PR(A)=0.5+0.5PR(C)PR(A)=0.5+0.5PR(C)
PR(B)=0.5+0.5(PR(A)2)PR(B)=0.5+0.5(PR(A)2)
PR(C)=0.5+0.5(PR(A)2+PR(B))PR(C)=0.5+0.5(PR(A)2+PR(B))
解得P
PR(A)=14/13=1.07692308PR(A)=14/13=1.07692308
PR(B)=10/13=0.76923077PR(B)=10/13=0.76923077
PR(C)=15/13=1.15384615PR(C)=15/13=1.15384615
迭代计算
| Iteration | PR(A) | PR(B) | PR(C) |
|---|---|---|---|
| 0 | 1 | 1 | 1 |
| 1 | 1 | 0.75 | 1.125 |
| 2 | 1.0625 | 0.7656 | 1.1484 |
| … | … | … | .. |
| 12 | 1.0769 | 0.7692 | 1.1538 |
在迭代式计算后,所有页面的PageRankPageRank值仍然和为N,每个网页的平均PageRankPageRank值为1
改进的PageRank–TrustRank
目的
Spam pages垃圾网页与good pages优质网页区别开来,可以防止垃圾网页操纵google搜索排名结果、提升搜索结果质量。
前提假设:
- 优质页面一般不链接垃圾页面,而垃圾页面总是试图连接到好页面以提高其声望
- 种子页面的候选者是专业网站,它们只基于优点而链接其它页面,如政府网站、非谋利性网站和严格管理的网站(DMOZ、Yahoo目录、Search Engine Watch等),它们不会链接垃圾页面的。
- 最权威和可信的网页就是”种子”页面本身。
算法步骤:
- 首先挑选出“spam status”待定的种子网站
- 人工检验这些种子网站,告诉算法这些种子网站是spam或者是good pages,其中good pages的TrustRankTrustRank高
- 算法通过检测剩余网站与第2步中筛选出来的good pages的关联性来决定这些网站是否是good pages
挑选种子网站有两种方式
一种是选择导出链接最多的网站,因为TrustRank算法就是计算指数随着导出链接的衰减,导出链接多的网站,在某种意义上可以理解为“逆向PR值”比较高。
另一种挑选种子网站的方法是选PR值高的网站,因为PR值越高,在搜索结果页面出现的概率就越大,这些网站才正是TrustRank算法最关注的、需要调整排名的网站,那些PR值很低的页面,在没有TrustRank算法时排名也很靠后,计算TrustRank意义就不大了。
HITS Algorithm
- 通过基于文本的查找算法来找出与查询集关联度最高的RootSet
- Expanding Root set:链接到Rootset中的网页和Rootset链接到的网页组成Base Set
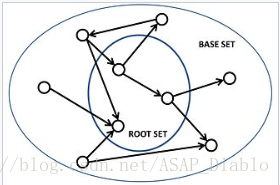
- Base Set中的所有网页和链接组成一个focused subgraph
- authority and hub values are defined in terms of each other in a mutual recursion. A node contains authority and hub value.
- Authority update:如果一个节点被认证的hubs所链接,那么这个节点将被赋予高Authority值. A(i)=∑H(i)(3)(3)A(i)=∑H(i)
- Hub update:如果一个节点链接了一些网络中的authorities,那么这个节点将被赋予高hub值. H(i)=∑A(i)(4)(4)H(i)=∑A(i)
- 计算节点的Hub and Authority score:
- 每个节点初始hub 和 authority值为1
- 运行Authority update (3)(3)
- 运行Hub update (4)(4)
- 将每个节点的Authority值和Hub值单位化 A(i)=A(i)|A(i)|A(i)=A(i)|A(i)|

















 2225
2225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









