




 强化学习是机器通过与环境交互学习目标的方法,涉及状态、动作、状态转移、奖励和策略等概念。状态和动作空间定义了智能体的行动范围,状态转移和奖励构成学习的基础。策略指导智能体在特定状态下应采取的行动,而奖励则反馈行为的效果。MDP是强化学习的核心模型,包含状态、动作、奖励和状态转移概率等要素。
强化学习是机器通过与环境交互学习目标的方法,涉及状态、动作、状态转移、奖励和策略等概念。状态和动作空间定义了智能体的行动范围,状态转移和奖励构成学习的基础。策略指导智能体在特定状态下应采取的行动,而奖励则反馈行为的效果。MDP是强化学习的核心模型,包含状态、动作、奖励和状态转移概率等要素。
初识强化学习
强化学习是机器通过与环境交互来实现目标的一种计算方法。机器与环境的一轮交互是指,机器在环境的一个状态下做一个动作决策,把这个动作作用到环境当中,这个环境发生相应的改变并且将相应的奖励反馈和下一轮状态传回机器。这种交互是迭代进行的,机器的目标是最大化在多轮交互过程中获得的累积奖励的期望。
一个网络世界的示例:
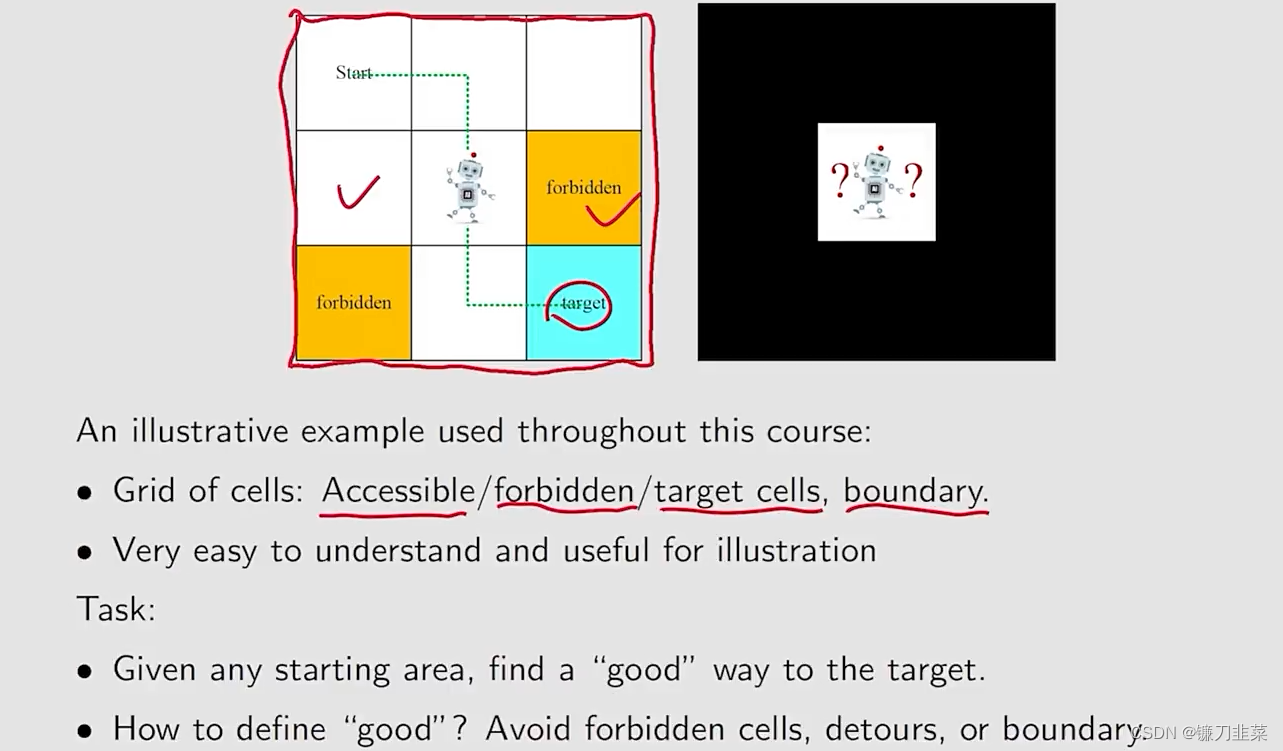
强化学习用智能体(agent)来表示决策的机器,它不但可以感知周围的环境信息,还可以通过做决策来直接改变这个环境。
智能体有3种关键要素:感知、决策和奖励
- 感知。agent在某种程度上感知环境的状态,从而指导自己所处的现状。
- 决策:agent根据当前的状态计算出达到目标需要采取的动作的过程叫做决策。
- 奖励:环境根据状态和agent采取的动作,产生一个标量信号作为奖励反馈。
强化学习中智能体学习的优化目标定义为价值(value)。
另外,从数据层面看,强化学习中,数据是在智能体与环境交互的过程中得到的,如果agent不采取某个决策动作,那么该动作对应的数据就永远无法被观测到,所以当前智能体的训练数据来自之前智能体的决策结果。而对于有监督学习任务,则是建立在给定的数据分布中采样得到的训练数据集上,通过优化在训练数据集中设定的目标函数(如最小化预测误差)找到模型的最优参数。这里的训练数据集背后的数据分布是完全不变的。
具体而言,强化学习中有一个关于数据分布的概念,称为占用度量(occupancy measure)。归一化的占用度量用于衡量在一个智能体决策与一个动态环境的交互过程,采样得到一个具体的状态动作对(state-action pair)的概率分布。
占用度量的一个重要性质:给定两个策略及其与一个动态环境交互得到的两个占用度量,那么当且仅当这两个占用度量相同时,这两个策略相同。也就是说,如果一个智能体的策略有所改变,那么它和环境交互得到的占用度量也会相应改变。
基本概念
State(状态)和State Space(状态空间)

Action(动作)与Action Space(动作空间)
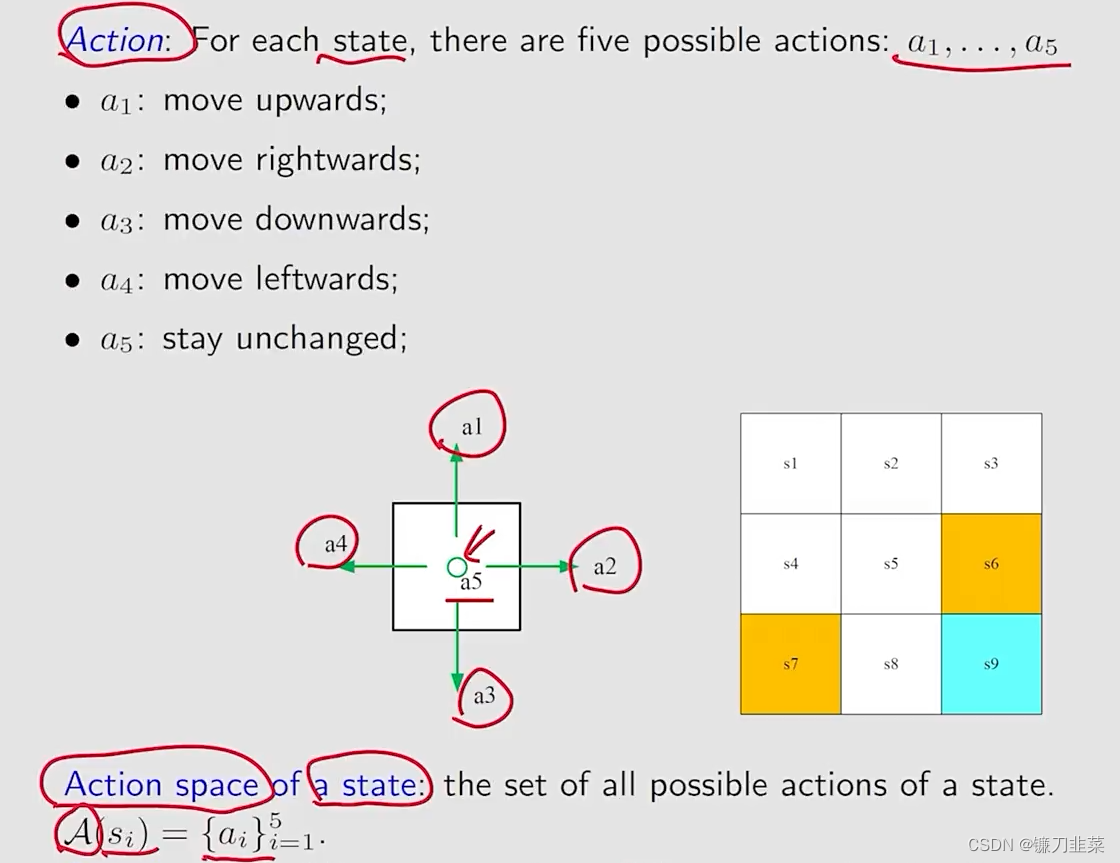
State transition(状态转移)

Forbidden area
在状态s5, 如果我们选择动作a2,也就是向右走,那么下一个状态是什么?
- 情况1:这个黄色区域(Forbidden area)是可达区域,但是会有惩罚;
- 情况2:这个forbidden area是不可达区域,也就是说这个区域是被封闭的;
Tabular representation(表格化表示)
用一个表格描述状态转移的情况。如下所示
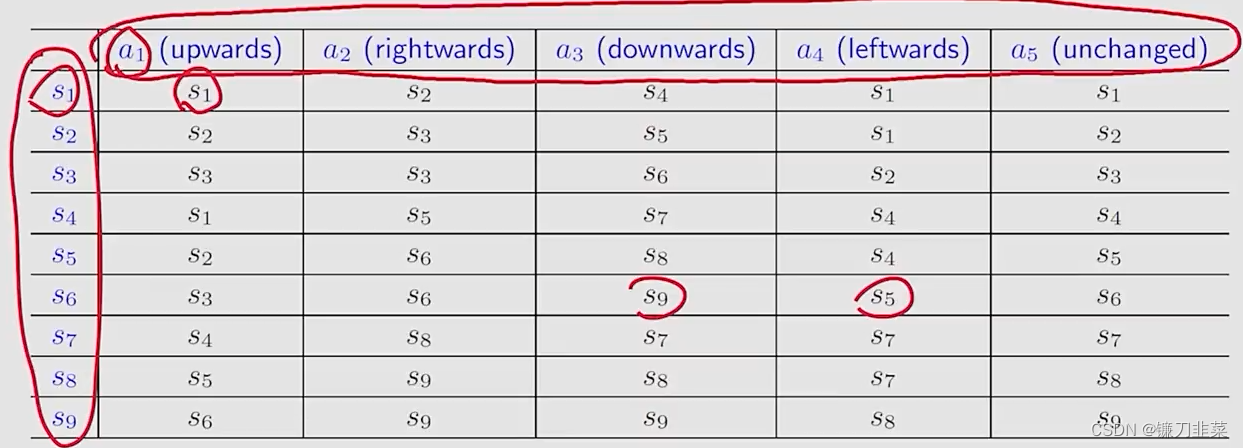
第一行表示动作,第一列表示当前位置,表格中的元素表示在当前位置选择动作执行后的状态。但是这种表格只能表示确定性的情况。
State transition probability(状态转移概率)
使用概率表述状态转移。

这种方式尽管也是确定性的情况,但是也可以描述随机性(stochastic)的情况。
Policy(策略)
告诉agent在某个state应该采取什么action。
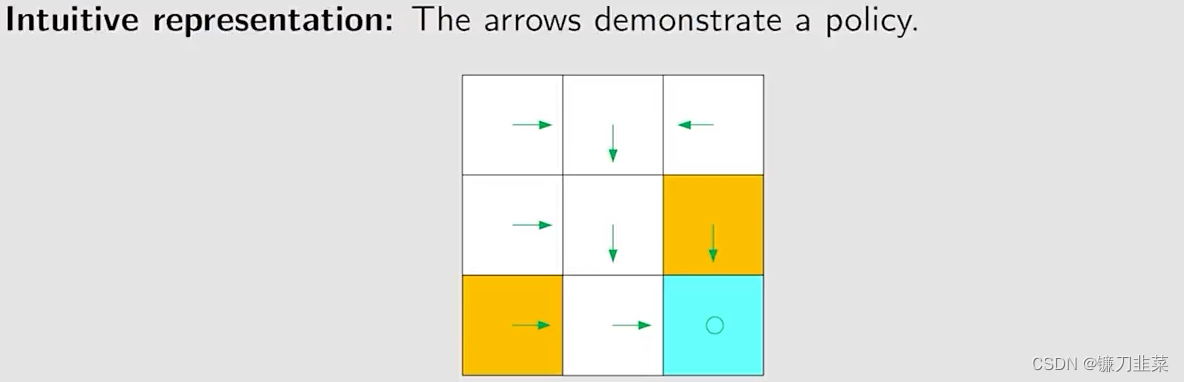
基于上面的策略,可以得到在不同起始点的路径:
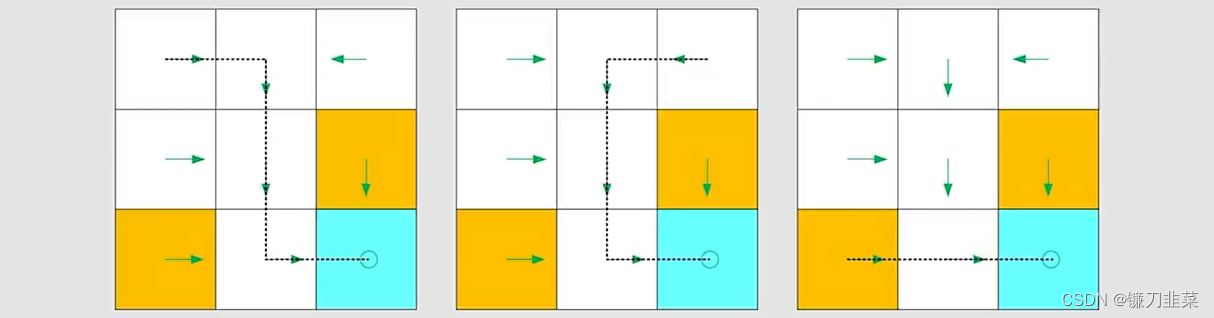
数学方式表示(Methematical representation):使用条件概率,如下,对于状态s1,有:
π ( a 1 ∣ s 1 ) = 0 \pi (a_1|s_1)=0 π(a1∣s1)=0
π ( a 2 ∣ s 1 ) = 1 \pi (a_2|s_1)=1 π(a2∣s1)=1
π ( a 3 ∣ s 1 ) = 0 \pi (a_3|s_1)=0 π(a3∣s1)=0
π ( a 4 ∣ s 1 ) = 0 \pi (a_4|s_1)=0 π(a
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 321
321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











