



 本文详细介绍了Java中的IO流,包括流的分类(字符流、字节流、输入流、输出流)、节点流与处理流的区别、以及常见的流类如InputStream、OutputStream、Reader、Writer等。此外,还探讨了序列化与反序列化的过程和注意事项,强调了在处理纯文本数据时优先使用字符流的原则。
本文详细介绍了Java中的IO流,包括流的分类(字符流、字节流、输入流、输出流)、节点流与处理流的区别、以及常见的流类如InputStream、OutputStream、Reader、Writer等。此外,还探讨了序列化与反序列化的过程和注意事项,强调了在处理纯文本数据时优先使用字符流的原则。
IO流结构图
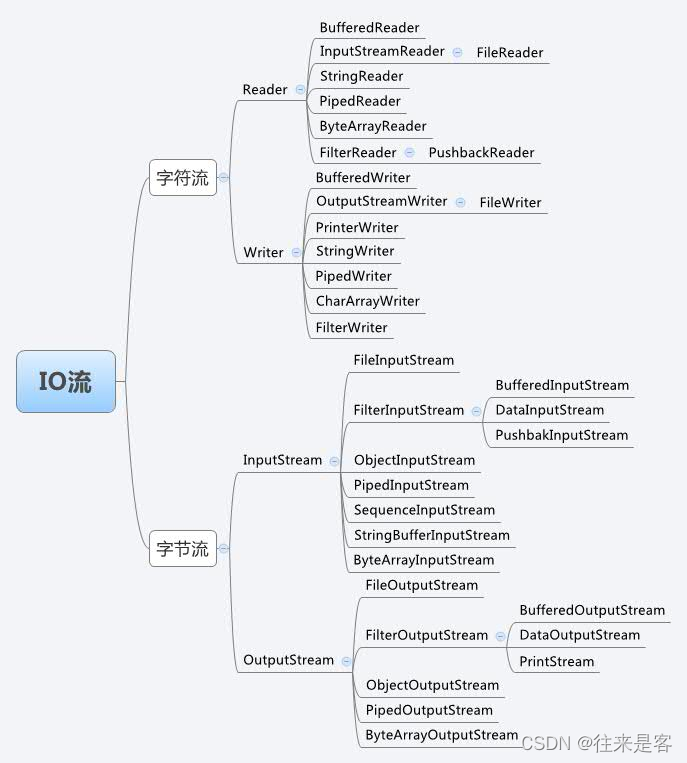
流的概念和作用
流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象。即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作。
IO流的分类
-
根据处理数据类型的不同分为:字符流和字节流
-
根据数据流向不同分为:输入流和输出流
按照流的角色划分为节点流和处理流。
-
节点流:从或向一个特定的地方(节点)读写数据。如FileInputStream。
-
处理流(包装流):是对一个已存在的流的连接和封装,通过所封装的流的功能调用实现数据读写。如BufferedReader。处理流的构造方法总是要带一个其他的流对象做参数。一个流对象经过其他流的多次包装,称为流的链接。
注意:一个IO流可以既是输入流又是字节流又或是以其他方式分类的流类型,是不冲突的。比如FileInputStream,它既是输入流又是字节流还是文件节点流。
Java IO 流有4个抽象基类:
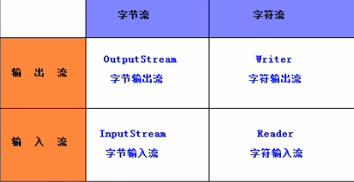
字符流和字节流
字符流的由来: 因为数据编码的不同,而有了对字符进行高效操作的流对象。本质其实就是基于字节流读取时,去查了指定的码表。 字节流和字符流的区别:
-
读写单位不同:字节流以字节(8bit)为单位,字符流以字符为单位,根据码表映射字符,一次可能读多个字节。
-
处理对象不同:字节流能处理所有类型的数据(如图片、avi等),而字符流只能处理字符类型的数据。
-
字节流:一次读入或读出是8位二进制。当传输的资源文件有中文时,就会出现乱码。
-
字符流:一次读入或读出是16位二进制。有中文时,使用该流就可以正确传输显示中文。
设备上的数据无论是图片或者视频,文字,它们都以二进制存储的。二进制的最终都是以一个8位为数据单元进行体现,所以计算机中的最小数据单元就是字节。意味着,字节流可以处理设备上的所有数据,所以字节流一样可以处理字符数据。
结论:只要是处理纯文本数据,就优先考虑使用字符流。 除此之外都使用字节流。
输入流和输出流
输入流只能进行读操作,输出流只能进行写操作,程序中需要根据待传输数据的不同特性而使用不同的流。
输出:把程序(内存)中的内容输出到磁盘、光盘等存储设备中。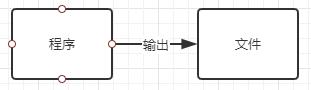
输入:读取外部数据(磁盘、光盘等存储设备的数据)到程序(内存)中。
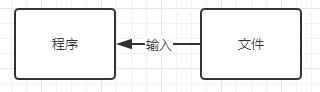
字节输入流 InputStream
java.io 包下所有的字节输入流都继承自 InputStream,并且实现了其中的方法。InputStream 中提供的主要数据操作方法如下:
int read():从输入流中读取一个字节的二进制数据。
int read(byte[] b):将多个字节读到数组中,填满整个数组。
int read(byte[] b, int off, int len):从输入流中读取长度为 len 的数据,从数组 b 中下标为 off 的位置开始放置读入的数据,读完返回读取的字节数。
void close():关闭数据流。
int available():返回目前可以从数据流中读取的字节数(但实际的读操作所读得的字节数可能大于该返回值)。
long skip(long l):跳过数据流中指定数量的字节不读取,返回值表示实际跳过的字节数。
对数据流中字节的读取通常是按从头到尾顺序进行的,如果需要以反方向读取,则需要使用回推(Push Back)操作。在支持回推操作的数据流中经常用到如下几个方法:
boolean markSupported():用于测试数据流是否支持回推操作,当一个数据流支持 mark() 和 reset() 方法时,返回 true,否则返回 false。
void mark(int readlimit):用于标记数据流的当前位置,并划出一个缓冲区,其大小至少为指定参数的大小。
void reset():将输入流重新定位到对此流最后调用 mark() 方法时的位置。
字节输入流 InputStream 有很多子类,日常开发中,经常使用的一些类见下图:
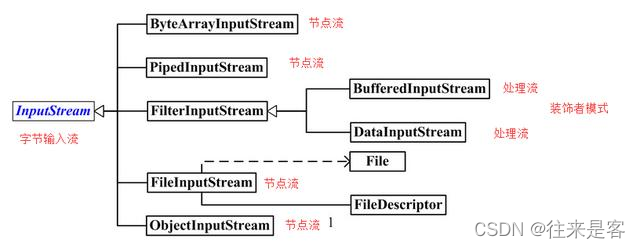
- ByteArrayInputStream:字节数组输入流,该类的功能就是从字节数组 byte[] 中进行以字节为单位的读取,也就是将资源文件都以字节形式存入到该类中的字节数组中去,我们拿数据也是从这个字节数组中拿。
- PipedInputStream:管道字节输入流,它和 PipedOutputStream 一起使用,能实现多线程间的管道通信。
- FilterInputStream:装饰者模式中充当装饰者的角色,具体的装饰者都要继承它,所以在该类的子类下都是用来装饰别的流的,也就是处理类。过滤
- BufferedInputStream:缓冲流,对处理流进行装饰、增强,内部会有一个缓冲区,用来存放字节,每次都是将缓冲区存满然后发送,而不是一个字节或两个字节这样发送,效率更高。
- DataInputStream:数据输入流,用来装饰其他输入流,它允许通过数据流来读写Java基本类型。
- FileInputStream:文件输入流,通常用于对文件进行读取操作。
- File:对指定目录的文件进行操作。
- ObjectInputStream:对象输入流,用来提供对“基本数据或对象”的持久存储。通俗点讲,就是能直接传输Java对象(序列化、反序列化用)。
字节输出流 OutputStream
与字节输入流类似,java.io 包下所有字节输出流大多是从抽象类 OutputStream 继承而来的。OutputStream 提供的主要数据操作方法:
void write(int i):将字节 i 写入到数据流中,它只输出所读入参数的最低 8
位,该方法是抽象方法,需要在其输出流子类中加以实现,然后才能使用。 void write(byte[] b):将数组 b 中的全部
b.length 个字节写入数据流。 void write(byte[] b, int off, int len):将数组 b 中从下标
off 开始的 len 个字节写入数据流。元素 b[off] 是此操作写入的第一个字节,b[off + len - 1]
是此操作写入的最后一个字节。 void close():关闭输出流。 void flush():刷新此输出流并强制写出所有缓冲的输出字节。
为了加快数据传输速度,提高数据输出效率,又是输出数据流会在提交数据之前把所要输出的数据先暂时保存在内存缓冲区中,然后成批进行输出,每次传输过程都以某特定数据长度为单位进行传输,在这种方式下,数据的末尾一般都会有一部分数据由于数量不够一个批次,而存留在缓冲区里,调用 flush() 方法可以将这部分数据强制提交。
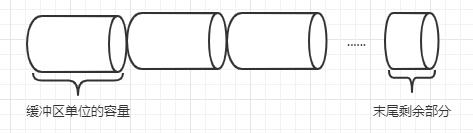
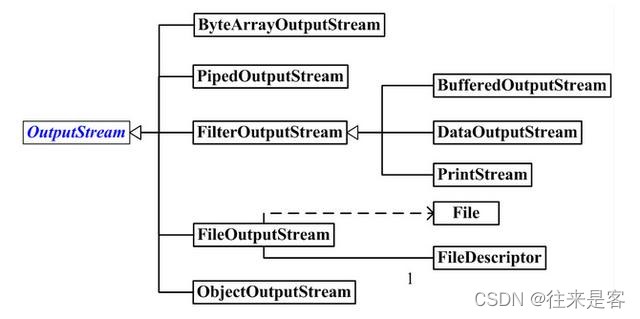
以上子类的作用可以看回到上面的字节输入流子类,这里不再多说
字符流
从JDK1.1开始,java.io 包中加入了专门用于字符流处理的类,它们是以Reader和Writer为基础派生的一系列类。
同其他程序设计语言使用ASCII字符集不同,Java使用Unicode字符集来表示字符串和字符。ASCII字符集以一个字节(8bit)表示一个字符,可以认为一个字符就是一个字节(byte)。但Java使用的Unicode是一种大字符集,用两个字节(16bit)来表示一个字符,这时字节与字符就不再相同。为了实现与其他程序语言及不同平台的交互,Java提供一种新的数据流处理方案,称作读者(Reader)和写者(Writer)。
字符输入流 Reader
Reader是所有的输入字符流的父类,它是一个抽象类。
下图是Reader及其一些常用子类的继承图:
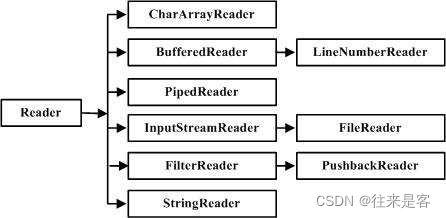
- CharReader和SringReader是两种基本的介质流,它们分别将Char数组、String中读取数据。
- PipedReader 是从与其它线程共用的管道中读取数据。
- BufferedReader很明显是一个装饰器,它和其他子类负责装饰其他Reader对象。
- FilterReader是所有自定义具体装饰流的父类,其子类PushBackReader对Reader对象进行装饰,会增加一个行号。
- InputStreamReader是其中最重要的一个,用来在字节输入流和字符输入流之间作为中介,可以将字节输入流转换为字符输入流。FileReader 可以说是一个达到此功能、常用的工具类,在其源代码中明显使用了将FileInputStream 转变为Reader 的方法。
Reader 中各个类的用途和使用方法基本和InputStream 中的类使用一致。
字符输出流 Writer
Writer是所有的输出字符流的父类,它是一个抽象类。
下图是Writer及其一些常用子类的继承图:
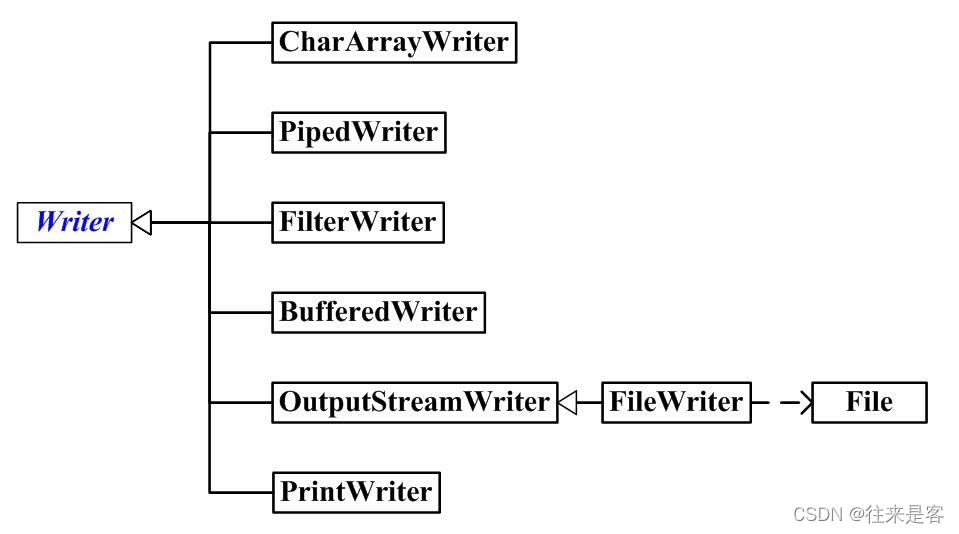
- CharWriter、StringWriter 是两种基本的介质流,它们分别向Char 数组、String 中写入数据。
- PipedWriter 是向与其它线程共用的管道中写入数据。
- BufferedWriter 是一个装饰器为Writer 提供缓冲功能。
- PrintWriter 和PrintStream 极其类似,功能和使用也非常相似。
- OutputStreamWriter是其中最重要的一个,用来在字节输出流和字符输出流之间作为中介,可以将字节输出流转换为字符输出流。FileWriter 可以说是一个达到此功能、常用的工具类,在其源代码中明显使用了将OutputStream转变为Writer 的方法。
Writer 中各个类的用途和使用方法基本和OutputStream 中的类使用一致。
序列化
把Java对象转换为字节序列的过程称为对象的序列化,也就是将对象写入到IO流中。序列化是为了解决在对对象流进行读写操作时所引发的问题。序列化机制允许将实现序列化的Java对象转换位字节序列,这些字节序列可以保存在磁盘上,或通过网络传输,以达到以后恢复成原来的对象。序列化机制使得对象可以脱离程序的运行而独立存在。
要对一个对象序列化,这个对象就需要实现Serializable接口,如果这个对象中有一个变量是另一个对象的引用,则引用的对象也要实现Serializable接口,这个过程是递归的。Serializable接口中没有定义任何方法,只是作为一个标记来指示实现该接口的类可以进行序列化。
要实现序列化,只需两步即可:
- 步骤一:创建一个ObjectOutputStream输出流;
- 步骤二:调用ObjectOutputStream对象的 writeObject 方法输出可序列化对象。
序列化只能保存对象的非静态成员变量,而不能保存任何成员方法和静态成员变量,并且保存的只是变量的值,变量的修饰符对序列化没有影响。
有一些对象类不具有可持久化性,因为其数据的特性决定了它会经常变化,其状态只是瞬时的,这样的对象是无法保存去状态的,如Thread对象或流对象。对于这样的成员变量,必须用 transient 关键字标明,否则编译器将报错。任何用 transient 关键字标明的成员变量,都不会被保存。
另外,序列化可能涉及将对象存放到磁盘上或在网络上发送数据,这时会产生安全问题。对于一些需要保密的数据(如用户密码等),不应保存在永久介质中,为了保证安全,应在这些变量前加上 transient 关键字。
反序列化
反序列化就是从 IO 流中恢复对象。
反序列化也只需两步即可完成:
- 步骤一:创建 ObjectInputStream 输入流
- 步骤二:调用ObjectInputStream对象的readObject()得到序列化的对象。
序列化版本号serialVersionUID
我们知道,反序列化必须拥有 class 文件,但随着项目的升级,class文件也会升级,序列化怎么保证升级前后的兼容性呢?
java序列化提供了一个private static final long serialVersionUID 的序列化版本号,只有版本号相同,即使更改了序列化属性,对象也可以正确被反序列化回来。
如果反序列化使用的class的版本号与序列化时使用的不一致,反序列化会报InvalidClassException异常:
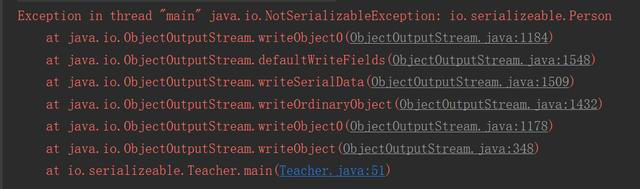
序列化版本号可自由指定,如果不指定,JVM会根据类信息自己计算一个版本号,这样随着class的升级,就无法正确反序列化;不指定版本号另一个明显隐患是,不利于jvm间的移植,可能class文件没有更改,但不同jvm可能计算的规则不一样,这样也会导致无法反序列化。
什么情况下需要修改serialVersionUID呢?分三种情况。
- 如果只是修改了方法,反序列化不容影响,则无需修改版本号;
- 如果只是修改了静态变量,瞬态变量(transient修饰的变量),反序列化不受影响,无需修改版本号;
- 如果修改了非瞬态变量,则可能导致反序列化失败。如果新类中实例变量的类型与序列化时类的类型不一致,则会反序列化失败,这时候需要更改serialVersionUID。如果只是新增了实例变量,则反序列化回来新增的是默认值;如果减少了实例变量,反序列化时会忽略掉减少的实例变量。
序列化使用场景
- 所有需要网络传输的对象都需要实现序列化接口,通过建议所有的javaBean都实现Serializable接口。
- 对象的类名、实例变量(包括基本类型,数组,对其他对象的引用)都会被序列化;方法、类变量、transient实例变量都不会被序列化。
- 如果想让某个变量不被序列化,使用transient修饰。
- 序列化对象的引用类型成员变量,也必须是可序列化的,否则,会报错。
- 反序列化时必须有序列化对象的class文件。
- 当通过文件、网络来读取序列化后的对象时,必须按照实际写入的顺序读取。
- 单例类序列化,需要重写readResolve()方法;否则会破坏单例原则。
- 同一对象序列化多次,只有第一次序列化为二进制流,以后都只是保存序列化编号,不会重复序列化。
- 建议所有可序列化的类加上serialVersionUID 版本号,方便项目升级。

















 235
235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









