




 本文深入解析Java Buffer的工作原理,重点比较allocate和allocateDirect的区别,探讨直接缓冲区在性能提升中的作用,并剖析MappedByteBuffer在堆外内存操作中的优势。
本文深入解析Java Buffer的工作原理,重点比较allocate和allocateDirect的区别,探讨直接缓冲区在性能提升中的作用,并剖析MappedByteBuffer在堆外内存操作中的优势。
Buffer
Buffer(缓存区),在本质上Buffer我们可以称为内存块,线程read()和write()都需要经过Buffer,java中提供了一些方法可以让开发者更便捷的使用Buffer
Buffer源码:
public abstract class Buffer {
static final int SPLITERATOR_CHARACTERISTICS =
Spliterator.SIZED | Spliterator.SUBSIZED | Spliterator.ORDERED;
// Invariants: mark <= position <= limit <= capacity
//标记
private int mark = -1;
//读写位置,下一个读或写的索引,每次读写缓冲区都会改变此值,为下一次读写准备
private int position = 0;
//极限值,不能对limit值之外的区域进行读写操作,limit可修改
private int limit;
//缓冲区所能容纳的最大数据量,不可修改,定义缓冲区时已存在
private int capacity;
Buffer(int mark, int pos, int lim, int cap) { // package-private
if (cap < 0)
throw new IllegalArgumentException("Negative capacity: " + cap);
this.capacity = cap;
limit(lim);
position(pos);
if (mark >= 0) {
if (mark > pos)
throw new IllegalArgumentException("mark > position: ("
+ mark + " > " + pos + ")");
this.mark = mark;
}
}
//JDK1.4提供的API
//返回缓冲区的容量
public final int capacity() {
return capacity;
}
//返回缓冲区的位置
public final int position() {
return position;
}
//设置缓冲区的位置
public final Buffer position(int newPosition) {
if ((newPosition > limit) || (newPosition < 0))
throw new IllegalArgumentException();
position = newPosition;
if (mark > position) mark = -1;
return this;
}
//返回缓冲区限制
public final int limit() {
return limit;
}
//设置缓冲区限制
public final Buffer limit(int newLimit) {
if ((newLimit > capacity) || (newLimit < 0))
throw new IllegalArgumentException();
limit = newLimit;
if (position > limit) position = limit;
if (mark > limit) mark = -1;
return this;
}
//在此缓冲区的位置设置标记
public final Buffer mark() {
mark = position;
return this;
}
//将此缓冲区的位置重置为以前标记的位置
public final Buffer reset() {
int m = mark;
if (m < 0)
throw new InvalidMarkException();
position = m;
return this;
}
//清除此缓冲区,将各个标记恢复到初始状态,但是数据并没有真正擦除
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
//反转此缓冲区,也就是读写转换
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
//重绕此缓冲区
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}
//返回当前位置与限制位置存在的元素数
public final int remaining() {
return limit - position;
}
//判断当前位置和限制位置是否有元素数
public final boolean hasRemaining() {
return position < limit;
}
//判断是否为只读缓冲区
public abstract boolean isReadOnly();
//JDK1.6后提供的API
//返回此缓冲区是否具有可访问的底层数组
public abstract boolean hasArray();
//返回缓冲区的底层数组
public abstract Object array();
//返回缓冲区底层实现数组中第一个缓冲区元素偏移量
public abstract int arrayOffset();
//判断缓冲区是否为直接缓冲区
public abstract boolean isDirect();
}
因为源码太多了,我就删减了一些,然后将方法的具体作用都标在了方法上方
看到上方的源码,我们知道了Buffer为一个抽象类,它不能被实例化,所以基本数据类型(除开boolean)都有了自己的实现类,最常用的就是一个叫ByteBuffer的类
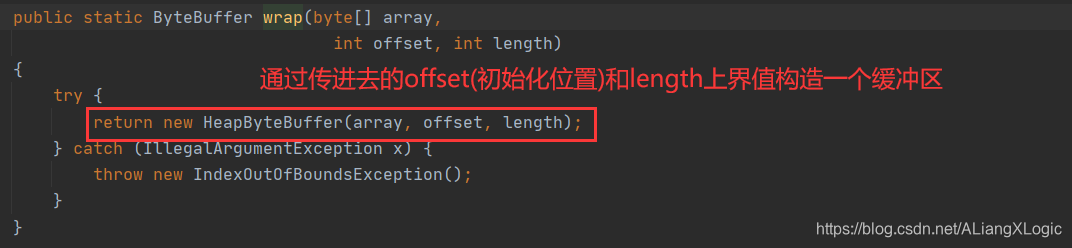
我们来看看ByteBuffer的源码,因为方法太多了,在这里我就选比较重要的贴出来给大家看看
关于创建缓冲区的API:


有的人就有疑惑了,这上面这两种创建缓冲区的方式有什么区别呢?我在这里给大家稍微扩展一下
allocateDirect():使用该方法创建的缓冲区称为直接缓冲区,分配缓冲区的内存不是由jvm来管理的,那它是如何释放内存的呢?虽然内存不是jvm进行管理,但是指向该内存的对象是jvm管理的,所以当对象消亡,内存也就清理掉了
allocate():使用该方法创建的缓冲区所分配的内存为jvm管理,就为正常的缓冲区,一般我们使用这种方式比较多
为什么java要提供这两种内存的分配方式呢?当然是为了有效的利用计算机上的资源,废话!!主要还是java的跨平台性,java的内存并不是本机上面的内存,而是jvm的内存,这就有一个问题了,当通过网络传输过来了一段数据,首先他是要经过系统的内存复制到java的内存中的,那当我们使用了allocateDirect()创建出来的直接缓冲区分配的内存是系统的内存,也就不用经历一次复制,大大提高了系统的性能
但是jvm请求系统的内存本身就是一个很耗时的操作,建议对于一些比较小的文件我们尽量不要用allocateDirect()来创建缓冲区
接着回到我们的ByteBuffer类中,介绍其它的方法

有关读取/写入的API





在这里给大家扩展一下一个类,也就是MappedByteBuffer,它里面的方法可以直接在堆外内存对文件进行修改,减少了一次数据数据拷贝,具体的细节我用代码给大家展示
package com.hecl.NIO.Buffer;
import java.io.RandomAccessFile;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
public class test_MappedByteBuffer {
public static void main(String[] args) {
try{
//通过这段语句我们就可以不用将数据加载进缓冲区,而是在堆外调用方法去修改文件的信息了
MappedByteBuffer mappedByteBuffer = new RandomAccessFile("E:\\ALiangX.txt","rw")
.getChannel().map(FileChannel.MapMode.READ_WRITE,0,11);
mappedByteBuffer.put(9, (byte) 'h');
mappedByteBuffer.put(10, (byte) 'i');
}catch (Exception e){
e.printStackTrace();
}
}
}

我们来分析一下上面的代码,最主要的还是下面这段
MappedByteBuffer mappedByteBuffer = new RandomAccessFile("E:\\ALiangX.txt","rw")
.getChannel().map(FileChannel.MapMode.READ_WRITE,0,11);
看过前面的都应该知道我们是怎么获取到文件、新建通道的了,我们主要是来分析一下这个map方法

参数一:MapMode 为MappedByteBuffer的一个静态内部类,主要有三种模式
MapMode.READ_ONLY:只读模式,选择此模式后,继续修改文件中的内容则会抛出异常
MapMode.READ_WRITE:可读可写模式,但是对映射同一文件的其他程序未必可见
MapMode.PRIVATE:私有模式,只在虚拟内容中,不保存到具体文件
参数二:position:文件映射的起始位置
参数三:size:映射文件的长度
在这里主要把原理和优缺点说一下,剩下的如果你们还想看给我留言我再去肝出来
1.MappedByteBuffer主要是将内存上的数据映射到虚拟内存中,对虚拟内存做修改,这样也解释了为什么只能对position之后,size之前的数据进行更改了
2.处理大文件用MappedByteBuffer效率较高,但是相对的垃圾回收时间不确定,内存占用率高
下期我们主要讲Channel(通道)
完成:2021/3/27 16:57 ALiangX
转载请标注原作者,谢谢你们的支持,能给个小心心吗?



















 1741
1741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











