




 本文深入探讨了Java中内置锁与显示锁的概念区别,详细解释了HashMap与ConcurrentHashMap的数据结构及工作原理,并对比了两者之间的主要差异。此外,还介绍了Java8中ConcurrentHashMap的改进之处。
本文深入探讨了Java中内置锁与显示锁的概念区别,详细解释了HashMap与ConcurrentHashMap的数据结构及工作原理,并对比了两者之间的主要差异。此外,还介绍了Java8中ConcurrentHashMap的改进之处。
引言:
首先需要了解的是内置锁和显示锁
内置锁也叫对象锁,关键字为 synchronized
显示锁就是Lock及其子类
线程不安全的HashMap
数据结构
由哈希表实现,数据结构构成为数组+链表+红黑树,解决哈希冲突的方案为拉链法
寻址方式
通过Integer.highestOneBit算出比指定整数小的最大的2^N值,其实现方法如下。
public static int highestOneBit(int i) {
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16);
return i - (i >>> 1);
}
Java8 hashcode计算方式:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
Java 7基于分段锁的ConcurrentHashMap
ConcurrentHashMap最外层是一个Segment的数组。每个Segment包含一个与HashMap数据结构差不多的链表数组。
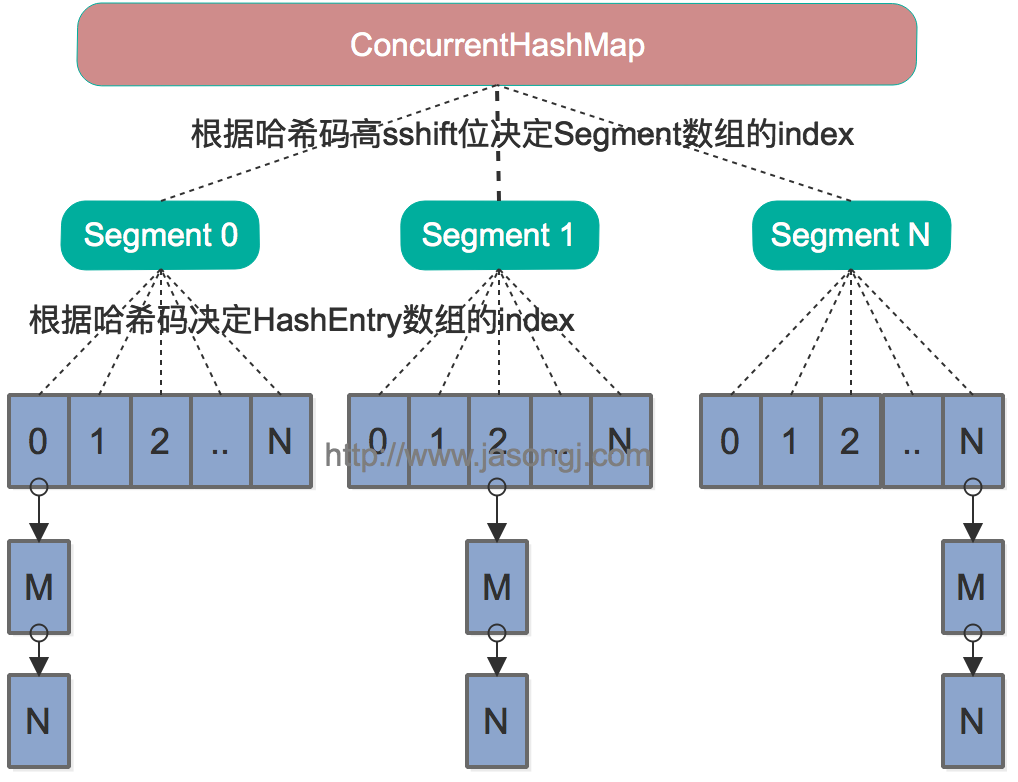
同步方式
Segment继承自ReentrantLock,所以我们可以很方便的对每一个Segment上锁。
ReentrantLock内部实现:
CAS状态:通过是否修改成功来判断是否拿到锁
等待队列:
等待队列中的线程都要做park操作
它使用了自旋锁,如果tryLock获取锁失败,说明锁被其它线程占用,此时通过循环再次以tryLock的方式申请锁。如果在循环过程中该Key所对应的链表头被修改,则重置retry次数。如果retry次数超过一定值,则使用lock方法申请锁。
这里使用自旋锁是因为自旋锁的效率比较高,但是它消耗CPU资源比较多,因此在自旋次数超过阈值时切换为互斥锁。
ConcurrentHashMap与HashMap相比,有以下不同点
ConcurrentHashMap线程安全,而HashMap非线程安全
HashMap允许Key和Value为null,而ConcurrentHashMap不允许
HashMap不允许通过Iterator遍历的同时通过HashMap修改,而ConcurrentHashMap允许该行为,并且该更新对后续的遍历可见
Java 8基于CAS的ConcurrentHashMap
1、摒弃了分段锁的方案,而是直接使用数组元素作为锁。
2、Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(long(N)))
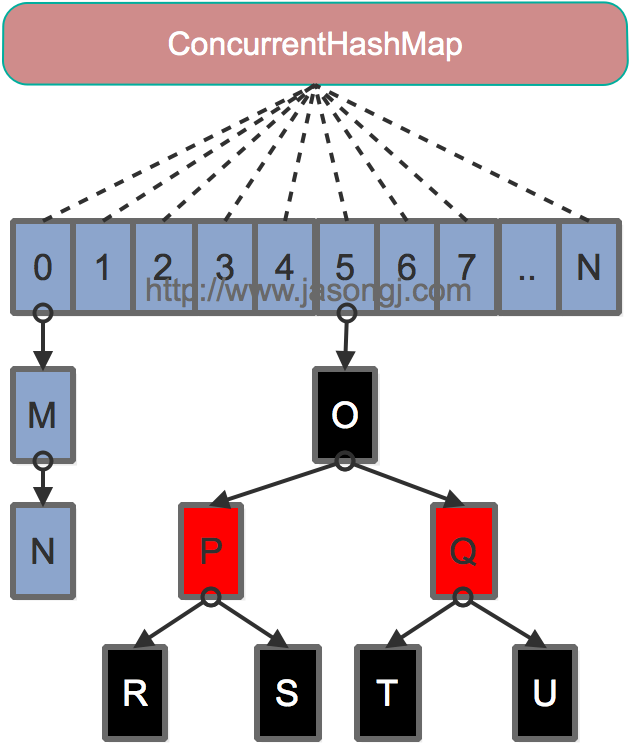
寻址方式:
将数组强制初始化为2的幂次,用hash&(length-1)取模,提升了运算速度
同步方式:
直接使用桶元素作为锁(此处为内置锁)

















 3573
3573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









