



8月21日,DeepSeek在官方公众号宣布DeepSeek-V3.1正式发布,上下文长度拓展到128k,拥有685B参数,同时支持思考模式与非思考模式。该模型一经推出,即在Hugging Face上火速走红,其编码能力也在全球范围内得到诸多专业测评团队认可。
来自Hugging Face的纵向对比显示,与此前R1版本与V3版本相比,DeepSeek V3.1 在代码生成和代码代理任务上全面制胜,其思考模式(Thinking)在代码生成类任务中优势明显(比如 LiveCodeBench 和 Aider),达到业界最高水平;非思考模式 (NonThinking)在代码代理类任务(SWE、Terminal-bench)中表现最好,分数远超过旧版本V3和R1。
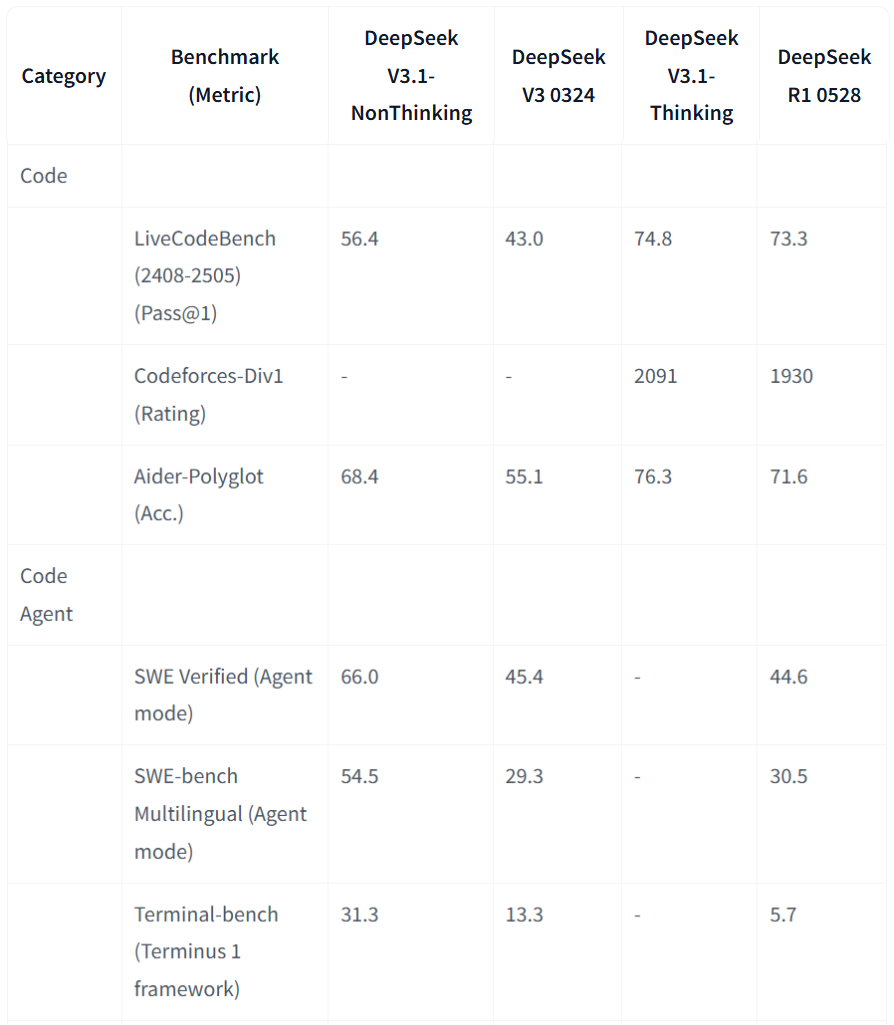
(来源:Hugging Face)
值得一提的是,V3.1在Aider 编程测试中表现优异,获得 71.6% Pass率(Pass@1),略高于 Claude Opus 4,领先约1%。
来自实际使用者和社区反馈显示,多数开发者认为 DeepSeek V3.1的编程“流畅性优于 GPT-5”,生成准确率高,适合片段式和复杂逻辑任务。同时,V3.1每完成一次完整编程测试的成本约为 $1.01,相比 Claude Opus 的约 $68,节省约 68 倍成本,性价比极高,非常适合在企业级、大规模应用场景中使用。
聪明的你也许已经开始期待在Costrict中体验这款模型了,悄悄透露,我们已经在内部测评了DeepSeek V3.1的编码能力了,一起期待一下!


















 1808
1808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









