






一、自然语言处理中的前馈网络
1.1 简介
自然语言处理(Natural Language Processing,NLP)是人工智能的一个分支,旨在使计算机能够理解、解释和生成人类语言。在这一领域中,前馈网络(Feedforward Networks)是一种常用的神经网络结构,它能够处理序列数据,如文本、语音等,并用于各种NLP任务,如文本分类、情感分析、机器翻译等。
前馈网络的特点包括:
1. 结构简单:前馈网络的结构相对简单,易于理解和实现。
2. 计算效率高:前馈网络的计算过程可以并行处理,提高了计算效率。
3. 易于扩展:前馈网络可以很容易地添加更多的隐藏层或神经元,以提高模型的复杂度和表达能力。
4. 易于优化:前馈网络的参数数量较少,易于使用梯度下降等优化算法进行训练。
在前馈网络中,激活函数的引入使得模型能够学习更复杂的非线性关系。常用的激活函数包括ReLU、Sigmoid、Tanh等。
在前馈网络的基础上,研究人员还提出了多种改进和变体,如卷积神经网络(CNN)、循环神经网络(RNN)和变换器(Transformer)等,以提高模型在NLP任务中的性能。
总之,前馈网络是自然语言处理中的重要组成部分,它为各种NLP任务提供了强大的建模能力。通过不断的研究和优化,前馈网络在NLP领域的应用将越来越广泛。
1.2 应用场景
自然语言处理(NLP)中的前馈网络,也称为全连接神经网络(FCNN)或多层感知机(MLP),广泛应用于多种NLP任务和场景。以下是一些主要应用场景:
1. 文本分类:
- 情感分析:判断文本内容是正面、负面还是中性。
- 主题分类:将文本归类到预定义的主题类别中。
- 文档分类:将文档分为不同的类别,如垃圾邮件检测、新闻分类等。
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, Conv1D, GlobalMaxPooling1D, Dense
tokenizer = Tokenizer(num_words=vocab_size)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
padded_sequences = pad_sequences(sequences, maxlen=max_sequence_length)
model = Sequential([
Embedding(input_dim=vocab_size, output_dim=embedding_dim),
Conv1D(filters=num_filters, kernel_size=filter_size, activation='relu'),
GlobalMaxPooling1D(),
Dense(units=num_classes, activation='softmax')
])2. 命名实体识别:
- 识别文本中的特定实体,如人名、地点、组织、时间等。
from transformers import pipeline
nlp = pipeline("ner")
results = nlp("Apple is a tech company based in California.")
for entity in results:
print(f"Entity: {entity['word']}, Type: {entity['entity']}")3. 关系提取:
- 从文本中提取实体之间的关系,如“学生”和“学习”之间的关系。
4. 机器翻译:
- 尽管现代机器翻译系统更倾向于使用序列到序列(seq2seq)模型,但早期的机器翻译系统使用了基于前馈网络的模型。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
model = Sequential([
Embedding(input_dim=vocab_size, output_dim=embedding_dim),
LSTM(units=hidden_units),
Dense(output_dim=vocab_size, activation='softmax')
])5. 文本生成:
- 生成新闻摘要、诗歌、对话等。
import tensorflow as tf
from tensorflow.keras.layers import Embedding, LSTM, Dense
model = tf.keras.Sequential([
Embedding(input_dim=vocab_size, output_dim=embedding_dim),
LSTM(units=hidden_units, return_sequences=True),
Dense(output_dim=vocab_size, activation='softmax')
])6. 文本相似度计算:
- 计算两个文本之间的相似度,用于文本推荐、问答系统等。
7. 文本摘要:
- 自动生成文本的摘要,提取关键信息。
8. 问答系统:
- 基于前馈网络的模型可以用于理解用户的问题并从文本中提取答案。
9. 语音识别:
- 虽然语音识别更倾向于使用循环神经网络(RNN)或变换器(Transformer),但前馈网络也可以用于语音信号的特征提取。
前馈网络在NLP中的应用不限于上述场景,随着技术的进步,新的应用场景和模型不断出现。例如,结合注意力机制的前馈网络在机器翻译和文本摘要任务中取得了显著的成果。
1.3 核心概念
自然语言处理(NLP)中的前馈网络,也称为全连接神经网络(FCNN)或多层感知机(MLP),是一种深度学习模型,它通过多个神经元层对输入数据进行非线性变换,以学习数据的复杂特征。以下是前馈网络的核心概念:
1. 层次结构:
- 输入层:接收原始数据,如文本中的词汇。
- 隐藏层:包含多个神经元,每个神经元对输入数据进行非线性变换,可以捕捉数据的更高层次特征。
- 输出层:根据隐藏层的输出生成最终结果,如分类标签或概率分布。
2. 非线性变换:
- 通过激活函数(如ReLU、Sigmoid、Tanh等)对隐藏层的输出进行非线性变换,使网络能够学习数据的复杂关系。
3. 权重和偏置:
- 每个神经元都有一组权重和偏置,用于计算输入数据的加权和,然后通过激活函数得到输出。
- 这些权重和偏置是模型学习过程中的参数,通过反向传播算法进行调整。
4. 前向传播和反向传播:
- 前向传播:从输入层开始,逐层计算每个神经元的输出。
- 反向传播:在训练过程中,计算损失函数对权重和偏置的梯度,然后更新这些参数。
5. 正则化和优化:
- 使用正则化技术(如L1正则化和L2正则化)来防止过拟合。
- 使用优化算法(如梯度下降、Adam等)来调整模型参数。
6. 多层结构:
- 前馈网络可以包含多个隐藏层,每个隐藏层都学习数据的更高层次特征。
- 层与层之间的连接是全连接的,即每个隐藏层的神经元都接收上一层的所有输出。
7. 模型容量:
- 隐藏层的神经元数量决定了模型的容量,即模型能够学习的特征数量。
- 增加隐藏层的神经元数量可以提高模型的表达能力,但也可能导致过拟合。
8. 多分类和回归:
- 对于多分类问题,输出层通常包含多个神经元,每个神经元对应一个类别。
- 对于回归问题,输出层通常只有一个神经元,生成连续的预测值。
前馈网络的核心概念在于通过多层神经元对输入数据进行逐层非线性变换,从而学习数据的复杂特征。这种结构使得前馈网络能够处理各种NLP任务,并取得了显著的成果。
二、多层感知机(MLP)
2.1 MLP的基本结构
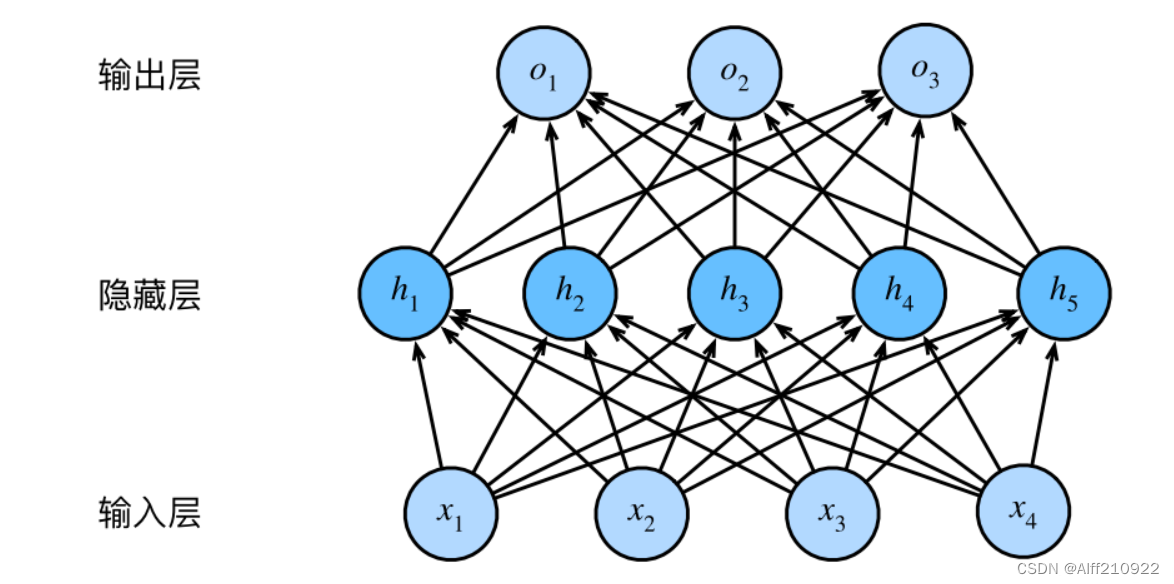
多层感知机(Multilayer Perceptron,MLP)是一种前馈神经网络,由多个处理层组成,每个处理层由多个神经元组成。MLP的基本结构可以分为以下几个部分:
1. 输入层:
- 输入层是MLP的入口,它接收外部输入数据。在NLP任务中,输入层通常接收文本的向量表示,如单词的one-hot编码、词嵌入等。
2. 隐藏层:
- 隐藏层是MLP的中间层,包含多个神经元。这些神经元可以学习输入数据的复杂特征和模式。隐藏层可以有多个,每增加一层,网络的复杂度和表达能力都会增强。
3. 输出层:
- 输出层是MLP的出口,它生成最终的预测结果。在NLP任务中,输出层通常包含一个或多个神经元,用于生成分类标签或概率分布。
import torch.nn as nn
import torch.nn.functional as F
class MultilayerPerceptron(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
"""
初始化多层感知机模型。
Args:
input_dim (int): 输入向量的尺寸。
hidden_dim (int): 第一个线性层的输出尺寸。
output_dim (int): 第二个线性层的输出尺寸。
"""
super(MultilayerPerceptron, self).__init__()
# 定义第一个线性层,输入尺寸为input_dim,输出尺寸为hidden_dim
self.fc1 = nn.Linear(input_dim, hidden_dim)
# 定义第二个线性层,输入尺寸为hidden_dim,输出尺寸为output_dim
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x_in, apply_softmax=False):
"""
前向传播过程。
Args:
x_in (torch.Tensor): 输入数据张量。
x_in.shape 应该为 (batch, input_dim)
apply_softmax (bool): 一个标志位,用于决定是否应用softmax激活。
如果使用交叉熵损失,则不应该应用softmax。
Returns:
张量,形状为 (batch, output_dim)
"""
# 通过第一个线性层,并应用ReLU激活函数
intermediate = F.relu(self.fc1(x_in))
# 通过第二个线性层
output = self.fc2(intermediate)
# 如果需要,应用softmax激活函数
if apply_softmax:
output = F.softmax(output, dim=1)
return output
MLP的基本结构简单明了,易于理解和实现。通过增加隐藏层的数量和神经元数量,MLP可以学习更复杂的特征和模式,提高模型的表达能力。然而,MLP的缺点是计算效率较低,且容易过拟合,因此,在实际应用中,研究人员通常会采用其他更高效的神经网络结构,如卷积神经网(CNN)和循环神经网络(RNN)。
4,激活函数
激活函数(activation function)通过计算加权和并加上偏置来确定神经元是否应该被激活,它们将输⼊信号 转换为输出的可微运算。⼤多数激活函数都是非线性的。
1.ReLU函数
在自然语言处理(NLP)中,ReLU(Rectified Linear Unit)函数是一种常用的激活函数,它被用于在神经网络的隐藏层中引入非线性。ReLU函数的数学表达式非常简单:
这意味着如果输入x大于0,ReLU函数的输出就是x本身;如果x小于或等于0,输出就是0。换句话说,ReLU函数对负值输入产生0输出,对正值输入则保持其原值。
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.relu(x)
d2l.plot(x.detach(), y.detach(), 'x', 'relu(x)', figsize=(5, 2.5)) 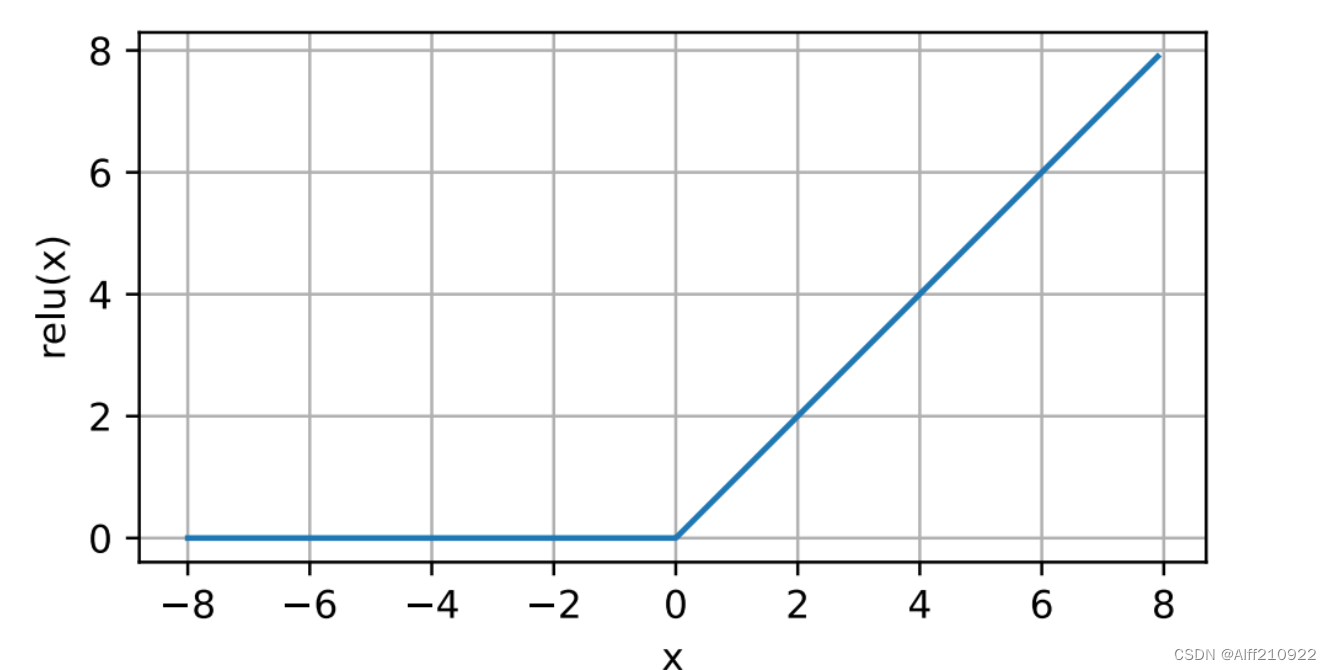
2.sigmoid函数
在自然语言处理(NLP)中,Sigmoid函数是一种常用的激活函数,它被用于在神经网络的隐藏层或输出层中引入非线性。Sigmoid函数的数学表达式如下:
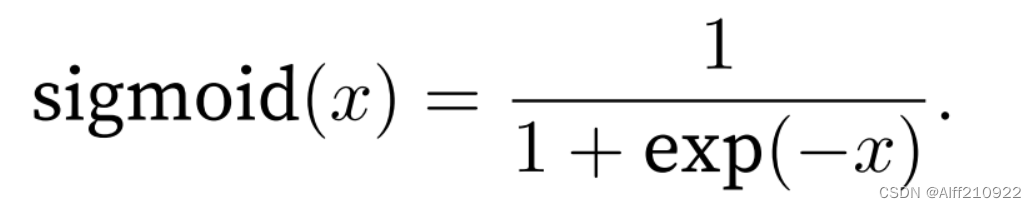
这个函数的输出范围在(0, 1)之间,这意味着对于任何输入x,Sigmoid函数的输出都是一个正数,且随着x的增加,输出逐渐接近1,但永远不会达到1。当x是一个非常大的负数时,输出接近0,但永远不会为0。
y = torch.sigmoid(x)
d2l.plot(x.detach(), y.detach(), 'x', 'sigmoid(x)', figsize=(5, 2.5))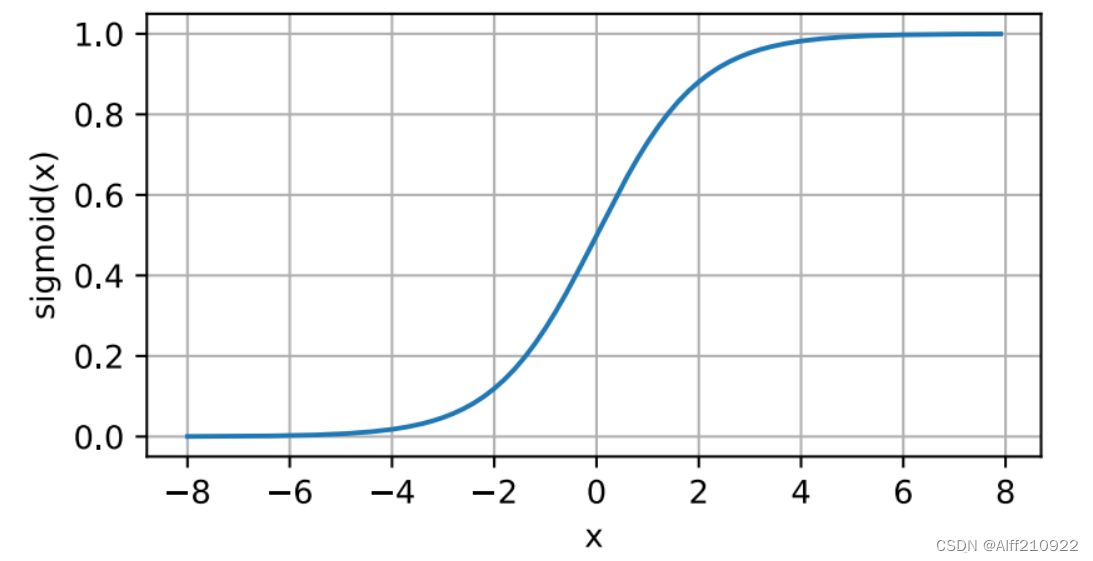
3.tanh函数
与sigmoid函数类似,tanh(双曲正切)函数也能将其输⼊压缩转换到区间(-1, 1)上。tanh函数的公式如下:
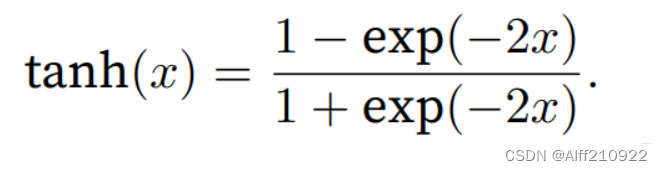
当输⼊在0附近时,tanh函数接近线性变换。函数的形状类似于sigmoid函数, 不同的是tanh函数关于坐标系原点中⼼对称。
y = torch.tanh(x)
d2l.plot(x.detach(), y.detach(), 'x', 'tanh(x)', figsize=(5, 2.5))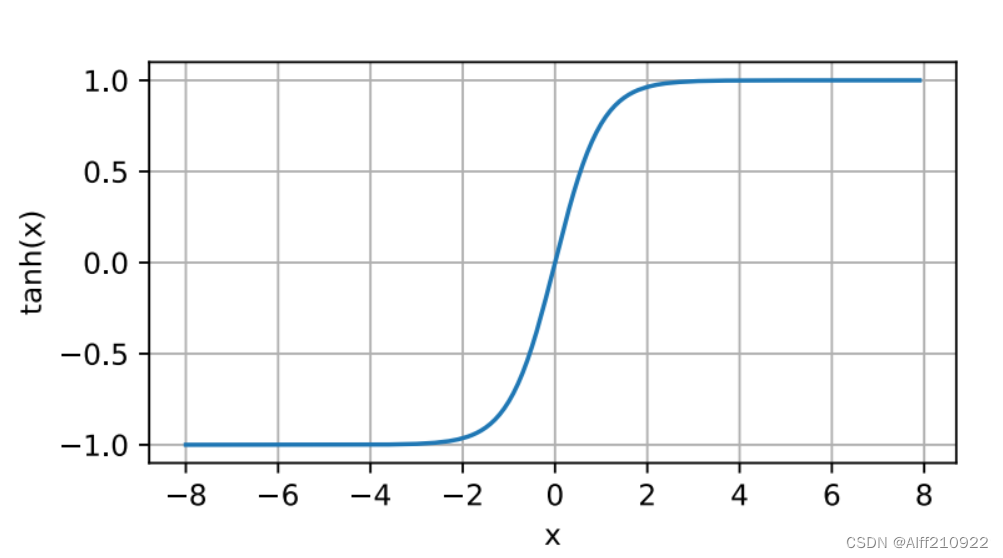
2.2 XOR问题的简单示例
参考b站视频
https://www.bilibili.com/video/BV13h4y1g7Rb/?p=109 https://www.bilibili.com/video/BV13h4y1g7Rb/?p=109
https://www.bilibili.com/video/BV13h4y1g7Rb/?p=109
XOR(异或)问题是一个经典的机器学习问题,用于演示线性模型在处理非线性数据时的局限性。在XOR问题中,我们有一个二元分类任务,其中每个输入由两个二元值(0或1)组成,目标是从这些输入中预测异或(XOR)的结果。异或运算的定义是:当两个输入不同(一个为0,一个为1)时输出1,否则输出0。XOR问题的真值表如下:
| 输入 (x1) | 输入 (x2) | 输出 (y) |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
在二维平面上表示,这四个点构成了两个不同的类别,无法通过一条直线来完美划分。具体来说,这四个点分别位于坐标(0,0)、(0,1)、(1,0)和(1,1),其中(0,0)和(1,1)属于同一类别,(0,1)和(1,0)属于另一类别。
在这里插入图片描述
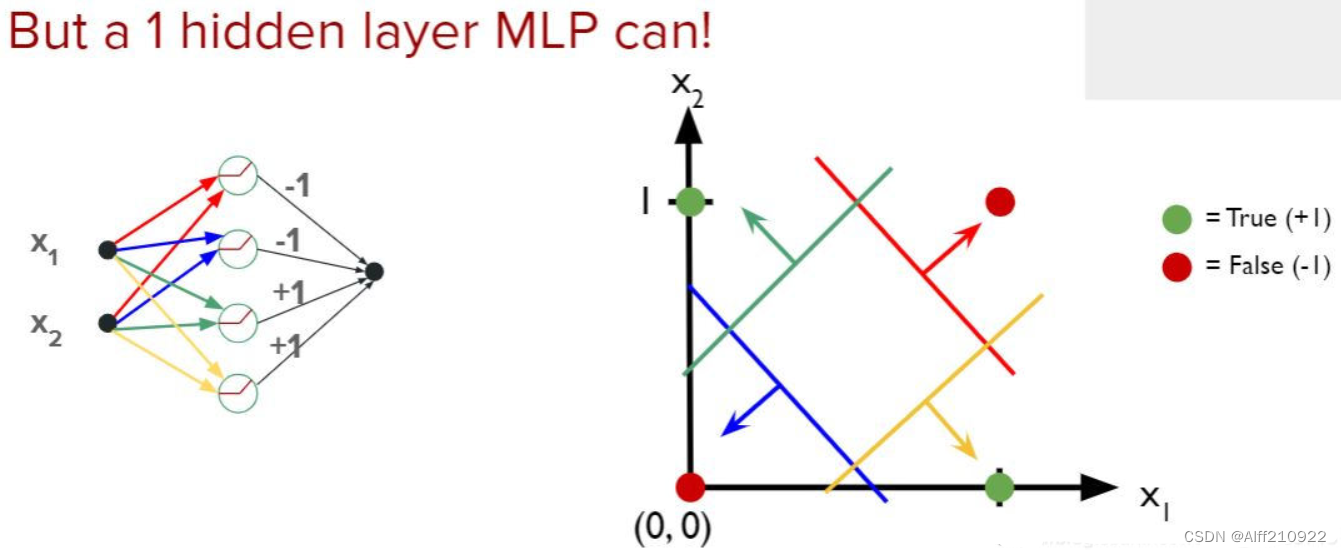
2.3 在PyTorch中实现多层感知器
2.3.2 多层感知器的实例化
设置了一个简单的MLP模型,它有一个输入层、一个隐藏层和一个输出层。这个模型可以用于各 种监督学习任务,如分类或回归问题,其中输入数据是三维向量,输出是一个四维向量。
batch_size = 2 # number of samples input at once
input_dim = 3
hidden_dim = 100
output_dim = 4
# Initialize model
mlp = MultilayerPerceptron(input_dim, hidden_dim, output_dim)
print(mlp)
2.3.3 使用随机输入测试多层感知器
这段代码使用了PyTorch库来生成一个随机输入张量x_input,并使用一个自定义的`describe`函数来描述这个张量的类型、形状和值。
import torch # 导入PyTorch库
def describe(x):
"""
描述张量的类型、形状和值。
Args:
x (torch.Tensor): 要描述的张量。
"""
print("Type: {}".format(x.type())) # 打印张量的数据类型
print("Shape/size: {}".format(x.shape)) # 打印张量的形状或大小
print("Values: \n{}".format(x)) # 打印张量的具体数值
# 生成随机输入张量x_input,具有给定的batch_size和input_dim
x_input = torch.rand(batch_size, input_dim)
# 调用describe函数来描述x_input张量
describe(x_input)
在神经网络的训练过程中,通常需要生成大量的随机输入数据来测试模型的性能。这段代码提供了一个简单的例子,展示了如何生成随机输入并打印其描述信息。

2.3.4 带有apply_softmax的多层感知器
softmax函数能够将一个数值向量转换为一个概率分布,其中每个元素都是其原始值经过指数变换后的归一化结果。这样做的好处是,模型输出的值可以直接被解释为概率,从而方便地进行后续的决策过程。
在PyTorch中,通过设置一个额外的参数(比如apply_softmax=True)来应用softmax函数。这样,模型在处理每个输入数据点时,会先计算一个数值向量,然后将其转换为概率分布。
之后,我们使用describe函数来打印出转换后的概率分布张量y_output的详细信息,包括它的类型、形状和值。通过这种方式,我们可以清楚地看到模型的输出已经被转换为一个概率分布,其中每个元素都表示模型对于给定输入数据点的预测概率。
y_output = mlp(x_input, apply_softmax=True)
describe(y_output)
三、实验步骤
3.1 姓氏分类的多层感知器示例
3.1.1 姓氏数据集
我们使用的姓氏数据集包含了来自18个不同国家的10,000个姓氏,这些姓氏是从互联网上不同的姓名来源收集的。数据集在实验的几个示例中重用,并具有一些有趣的属性。首先是它相当不平衡,前三类占数据集的60%以上。其次是国籍和姓氏正字法之间存在有效和直观的关系。
为了创建最终的数据集,我们通过选择标记为俄语的姓氏的随机子集来减少俄语的过度代表性。然后,我们将数据集分为三个部分:70%用于训练,15%用于验证,最后15%用于测试,以确保跨这些部分的类标签分布具有可比性。
3.1.1.1 实现SurnameDataset.__getitem__()
# 定义一个SurnameDataset类,它继承自Dataset类
class SurnameDataset(Dataset):
# Implementation is nearly identical to Section 3.5
def __getitem__(self, index):
# 根据索引获取数据帧中的一行
row = self._target_df.iloc[index]
# 使用_vectorizer来矢量化surname列
surname_vector = \
self._vectorizer.vectorize(row.surname)
# 使用_vectorizer的nationality_vocab来查找nationality列的索引
nationality_index = \
self._vectorizer.nationality_vocab.lookup_token(row.nationality)
# 返回一个包含矢量化姓氏和民族索引的字典
return {'x_surname': surname_vector,
'y_nationality': nationality_index}3.1.2 词汇、向量化器和数据加载器
3.1.2.1 实现SurnameVectorizer:
它负责将姓氏转换成向量形式。它使用了两个Vocabulary实例来处理字符和国籍的映射。
__init__方法初始化了SurnameVectorizer,接收两个Vocabulary实例作为参数,分别用于字符和国籍的映射。vectorize方法将一个姓氏字符串转换成一个one-hot编码的向量,其中每个字符对应的位置被设置为1。from_dataframe类方法从一个数据框中创建SurnameVectorizer实例,通过遍历数据框中的每个姓氏和国籍来构建字符和国籍的映射。class SurnameVectorizer(object): """The Vectorizer which coordinates the Vocabularies and puts them to use""" def __init__(self, surname_vocab, nationality_vocab): """ Args: surname_vocab (Vocabulary): maps characters to integers nationality_vocab (Vocabulary): maps nationalities to integers """ # 初始化字符到整数的映射器 self.surname_vocab = surname_vocab # 初始化国籍到整数的映射器 self.nationality_vocab = nationality_vocab def vectorize(self, surname): """Vectorize the provided surname Args: surname (str): the surname Returns: one_hot (np.ndarray): a collapsed one-hot encoding """ # 获取字符映射器 vocab = self.surname_vocab # 初始化一个与字符映射器大小相同的零向量,用于存储one-hot编码 one_hot = np.zeros(len(vocab), dtype=np.float32) # 遍历姓氏中的每个字符 for token in surname: # 在对应字符的索引位置设置1,实现one-hot编码 one_hot[vocab.lookup_token(token)] = 1 # 返回压缩的one-hot编码向量 return one_hot @classmethod def from_dataframe(cls, surname_df): """Instantiate the vectorizer from the dataset dataframe Args: surname_df (pandas.DataFrame): the surnames dataset Returns: an instance of the SurnameVectorizer """ # 使用未知字符符号初始化字符映射器 surname_vocab = Vocabulary(unk_token="@") # 初始化国籍映射器,不添加未知标记 nationality_vocab = Vocabulary(add_unk=False) # 遍历数据集中的每一行 for index, row in surname_df.iterrows(): # 将姓氏中的每个字符添加到字符映射器 for letter in row.surname: surname_vocab.add_token(letter) # 将国籍添加到国籍映射器 nationality_vocab.add_token(row.nationality) # 使用字符和国籍映射器实例化SurnameVectorizer return cls(surname_vocab, nationality_vocab)这个类和相关的功能模块为后续的机器学习任务提供了数据预处理和转换的接口。
3.1.3 姓氏分类器模型
3.1.3.1 作为多层感知器的SurnameClassifier
这段代码定义了一个名为SurnameClassifier的类,它是一个简单的两层多层感知器(MLP),用于对姓氏进行分类。
-
__init__方法:- 初始化模型的超类
nn.Module。 - 定义两个全连接层(
fc1和fc2),其中fc1的输入维度是input_dim,输出维度是hidden_dim;fc2的输入维度是hidden_dim,输出维度是output_dim。
- 初始化模型的超类
-
forward方法:- 接受一个输入数据张量
x_in和一个布尔值apply_softmax。 - 通过第一个全连接层
fc1,并应用ReLU激活函数。 - 通过第二个全连接层
fc2。 - 如果
apply_softmax为True,则应用softmax激活函数,否则返回未经过softmax处理的张量。 - 返回预测张量。
- 接受一个输入数据张量
import torch.nn as nn
import torch.nn.functional as F
class SurnameClassifier(nn.Module):
"""A 2-layer Multilayer Perceptron for classifying surnames"""
def __init__(self, input_dim, hidden_dim, output_dim):
"""
Args:
input_dim (int): the size of the input vectors
hidden_dim (int): the output size of the first Linear layer
output_dim (int): the output size of the second Linear layer
"""
# 调用nn.Module的初始化方法
super(SurnameClassifier, self).__init__()
# 定义第一个全连接层,输入维度为input_dim,输出维度为hidden_dim
self.fc1 = nn.Linear(input_dim, hidden_dim)
# 定义第二个全连接层,输入维度为hidden_dim,输出维度为output_dim
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x_in, apply_softmax=False):
"""The forward pass of the classifier
Args:
x_in (torch.Tensor): an input data tensor.
x_in.shape should be (batch, input_dim)
apply_softmax (bool): a flag for the softmax activation
should be false if used with the Cross Entropy losses
Returns:
the resulting tensor. tensor.shape should be (batch, output_dim)
"""
# 通过第一个全连接层,并应用ReLU激活函数
intermediate_vector = F.relu(self.fc1(x_in))
# 通过第二个全连接层
prediction_vector = self.fc2(intermediate_vector)
# 如果需要,则应用softmax激活函数
if apply_softmax:
prediction_vector = F.softmax(prediction_vector, dim=1)
# 返回预测向量
return prediction_vector
3.1.4 训练过程
3.1.4.1 为多层感知器分类姓氏的参数
这段代码定义了一个Namespace对象,用于存储命令行参数。Namespace是argparse模块中的一个类,它提供了一种组织参数的方式,使得参数可以像字典一样被访问,并且可以包含嵌套的参数结构。
surname_csv:指定包含姓氏数据及其分割的CSV文件路径。vectorizer_file:指定向量化器的序列化文件路径,用于保存和加载向量化器的状态。model_state_file:指定保存模型状态的文件路径,通常包含模型的权重和参数。save_dir:指定模型状态保存的目录路径,确保目录存在或者在运行时创建。hidden_dim:指定隐藏层的维度大小,这是一个超参数,需要根据具体的任务和数据集进行调整。seed:指定随机种子,用于保证实验的可重复性,即每次运行时使用相同的随机数种子。num_epochs:指定训练的epoch数,即整个训练过程重复的次数。early_stopping_criteria:指定提前停止训练的准则,即连续多少次验证集损失不下降时停止训练。learning_rate:指定学习率,这是一个超参数,影响模型的收敛速度和最终性能。batch_size:指定每次迭代训练的数据批次大小,这是超参数,会影响模型的收敛速度和内存使用。
from argparse import Namespace
# 创建一个命名空间对象,用于存储命令行参数
args = Namespace(
# Data and path information
surname_csv="data/surnames/surnames_with_splits.csv", # 包含姓氏数据及其分割的CSV文件路径
vectorizer_file="vectorizer.json", # 向量化器的序列化文件路径
model_state_file="model.pth", # 保存模型状态的文件路径
save_dir="model_storage/ch4/surname_mlp", # 模型状态保存的目录路径
# Model hyper parameters
hidden_dim=300, # 隐藏层的维度大小
# Training hyper parameters
seed=1337, # 随机种子,用于保证实验的可重复性
num_epochs=100, # 训练的epoch数
early_stopping_criteria=5, # 提前停止训练的准则,即连续多少次验证集损失不下降时停止训练
learning_rate=0.001, # 学习率
batch_size=64, # 每次迭代训练的数据批次大小
# Runtime options omitted for space
)
这些参数可以作为命令行参数传递给程序,或者作为程序的默认参数。
3.1.4.2 实例化数据集、模型、损失函数和优化器
加载数据集并创建一个向量化器,然后使用这个向量化器创建一个SurnameClassifier实例。之后,它将模型转移到指定的设备上,定义损失函数,并根据数据集的类权重进行调整,最后创建优化器。
dataset = SurnameDataset.load_dataset_and_make_vectorizer(args.surname_csv)
vectorizer = dataset.get_vectorizer()
# 创建一个SurnameClassifier实例,其中输入维度等于向量化器中字符的数量,
# 隐藏维度是模型参数args.hidden_dim,输出维度等于向量化器中国籍的数量。
classifier = SurnameClassifier(input_dim=len(vectorizer.surname_vocab),
hidden_dim=args.hidden_dim,
output_dim=len(vectorizer.nationality_vocab))
# 将模型转移到指定的设备上,这里假设args.device是一个有效的设备名称,如'cpu'或'cuda:0'
classifier = classifier.to(args.device)
# 定义损失函数,使用交叉熵损失,并根据数据集的类权重进行调整
loss_func = nn.CrossEntropyLoss(dataset.class_weights)
# 创建优化器,使用Adam算法,学习率为args.learning_rate
optimizer = optim.Adam(classifier.parameters(), lr=args.learning_rate)
3.1.4.3 训练循环
# 训练循环的5个步骤:
# --------------------------------------
# step 1. zero the gradients
optimizer.zero_grad()
# step 2. compute the output
# 计算模型的输出
y_pred = classifier(batch_dict['x_surname'])
# step 3. compute the loss
# 计算损失函数的值
loss = loss_func(y_pred, batch_dict['y_nationality'])
# 将损失转换为CPU上的浮点数,并计算当前批次损失
loss_batch = loss.to("cpu").item()
# 更新运行损失值
running_loss += (loss_batch - running_loss) / (batch_index + 1)
# step 4. use loss to produce gradients
# 反向传播损失函数,计算梯度
loss.backward()
# step 5. use optimizer to take gradient step
# 使用优化器根据梯度更新模型参数
optimizer.step()
3.1.5 模型评估和预测
3.1.5.2 对新姓氏进行分类
使用vectorizer将输入的名字转化为向量形式,然后使用分类器对向量进行预测,得到每个国籍的概率分布。接着,它获取概率分布中的最大值及其对应的索引,并根据索引从vectorizer的国籍词汇表中获取预测的国籍。最后,它返回预测结果,包括国籍和概率值。
# 定义一个函数,根据输入的名字预测其国籍
def predict_nationality(name, classifier, vectorizer):
# 使用vectorizer将输入的名字转化为向量形式
vectorized_name = vectorizer.vectorize(name)
# 将向量转化为tensor,并调整其形状以适配分类器的输入要求
vectorized_name = torch.tensor(vectorized_name).view(1, -1)
# 使用分类器对向量进行预测,得到每个国籍的概率分布
result = classifier(vectorized_name, apply_softmax=True)
# 获取概率分布中的最大值及其对应的索引
probability_values, indices = result.max(dim=1)
# 将索引从tensor转化为整数形式
index = indices.item()
# 根据索引从vectorizer的国籍词汇表中获取预测的国籍
predicted_nationality = vectorizer.nationality_vocab.lookup_index(index)
# 获取预测为该国籍的概率值
probability_value = probability_values.item()
# 返回预测结果,包括国籍和概率值
return {'nationality': predicted_nationality,
'probability': probability_value}
3.1.5.3 获取新姓氏的前k个预测
首先使用vectorizer将输入的名字转化为向量形式,然后使用分类器对向量进行预测,得到每个国籍的概率分布。接着,它获取概率分布中最大的k个值及其对应的索引,并将这些值和索引转换为国籍和概率的字典。最后,它返回预测结果,包括前k个最可能的国籍及其概率。
# 定义一个函数,根据输入的名字预测其国籍,并返回概率最高的k个国籍
def predict_topk_nationality(name, classifier, vectorizer, k=5):
# 使用vectorizer将输入的名字转化为向量形式
vectorized_name = vectorizer.vectorize(name)
# 将向量转化为tensor,并调整其形状以适配分类器的输入要求
vectorized_name = torch.tensor(vectorized_name).view(1, -1)
# 使用分类器对向量进行预测,得到每个国籍的概率分布
prediction_vector = classifier(vectorized_name, apply_softmax=True)
# 获取概率分布中最大的k个值及其对应的索引
probability_values, indices = torch.topk(prediction_vector, k=k)
# 从tensor中提取概率值和索引,并转换为numpy数组
# 因为返回的尺寸是1,k,所以我们需要取出第一个元素
probability_values = probability_values.detach().numpy()[0]
indices = indices.detach().numpy()[0]
# 初始化一个列表来存储结果
results = []
# 遍历概率值和索引,将它们转换为国籍和概率的字典
for prob_value, index in zip(probability_values, indices):
# 根据索引从vectorizer的国籍词汇表中获取预测的国籍
nationality = vectorizer.nationality_vocab.lookup_index(index)
# 将国籍和概率添加到结果列表中
results.append({'nationality': nationality,
'probability': prob_value})
# 返回预测结果,包括前k个最可能的国籍及其概率
return results
3.1.6 正则化多层感知器:权重正则化和结构正则化(或Dropout)
3.1.6.1 Dropout
Dropout 是一种在神经网络中常用的正则化技术,用于减少过拟合。其原理是在网络的训练过程中,随机地将部分神经元的输出置为零(即失活),从而使得网络在每次迭代时都在不同的子网络上训练,以减少神经元之间的复杂依赖关系,从而增强模型的泛化能力。
工作原理:
- 随机失活神经元:在每次训练迭代时,Dropout 方法会以一定的概率(通常为 0.5)随机地将某些神经元的输出置为零,即使得这些神经元在此次迭代中不参与前向传播和反向传播。这样可以阻止网络过度依赖于某些特定的神经元,增强模型的泛化能力。
- 训练时与测试时的区别:在训练时,通过随机失活神经元来减少过拟合;而在测试时,所有的神经元都保持活跃,但是输出值需要按照训练时的概率进行缩放,以保持期望输出的一致性。
- Dropout的随机性:Dropout 是通过在每次迭代中随机选择要失活的神经元来实现的。这种随机性会导致网络在每次迭代时都训练在不同的子网络上,从而相当于训练了多个不同的模型,最终取平均或者加权平均作为最终的预测结果。
Dropout的优点:
- 减少过拟合:通过随机失活部分神经元,阻止网络过度拟合训练数据,从而提高了模型的泛化能力。
- 简单易用:Dropout 是一种简单而有效的正则化技术,可以直接应用于现有的神经网络模型中,而无需对网络结构进行修改。
dropout不会向模型中添加额外的参数,但是需要一个超参数——“drop probability”。drop probability,它是单位之间的连接drop的概率。通常将下降概率设置为0.5。以下给出了一个带dropout的MLP的重新实现。
import torch.nn as nn
import torch.nn.functional as F
# 定义一个多层感知机(MLP)类
class MultilayerPerceptron(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
"""
Args:
input_dim (int): 输入向量的尺寸
hidden_dim (int): 第一个线性层输出的尺寸
output_dim (int): 第二个线性层输出的尺寸
"""
super(MultilayerPerceptron, self).__init__()
# 定义第一个全连接层,输入尺寸为input_dim,输出尺寸为hidden_dim
self.fc1 = nn.Linear(input_dim, hidden_dim)
# 定义第二个全连接层,输入尺寸为hidden_dim,输出尺寸为output_dim
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x_in, apply_softmax=False):
"""多层感知机的前向传播
Args:
x_in (torch.Tensor): 输入数据张量。
x_in.shape 应该是 (batch, input_dim)
apply_softmax (bool): 是否应用softmax激活的标志
如果与交叉熵损失一起使用,应该设置为false
Returns:
结果张量。tensor.shape 应该是 (batch, output_dim)
"""
# 通过第一个全连接层,并应用ReLU激活函数
intermediate = F.relu(self.fc1(x_in))
# 对中间层的输出应用dropout,以减少过拟合的风险
intermediate = F.dropout(intermediate, p=0.5)
# 通过第二个全连接层得到输出
output = self.fc2(intermediate)
# 如果指定了apply_softmax,则对输出应用softmax激活函数
if apply_softmax:
output = F.softmax(output, dim=1)
# 返回最终的输出张量
return output
四、卷积神经网络(CNN)
4.1 历史背景
当处理图像或其他具有空间结构的数据时,卷积神经网络(CNN)是一种常用的深度学习模型。
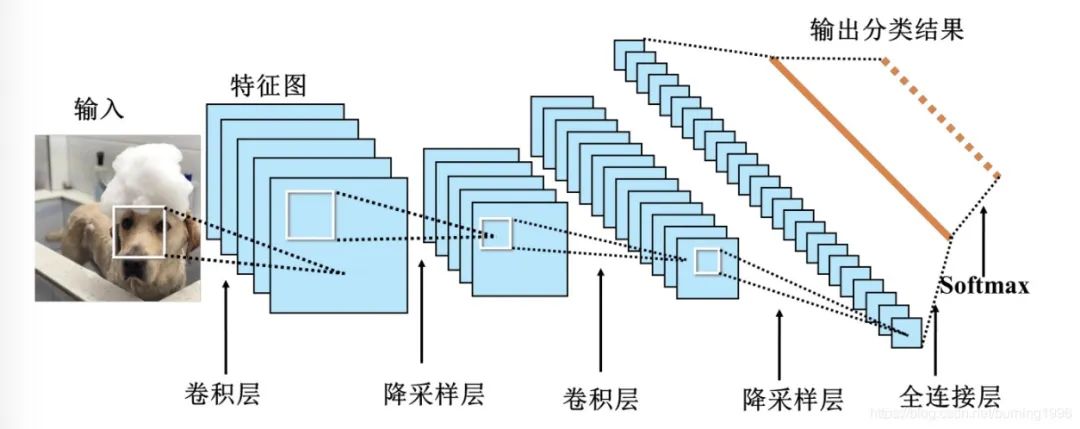
CNN的设计灵感源自人脑的视觉处理方式。与传统的全连接神经网络不同,CNN通过在输入数据上应用卷积操作来提取局部特征,并通过训练过程自动学习这些卷积操作的参数。下面逐步解释CNN中的关键概念:
卷积层(Convolutional Layer):卷积层是CNN的核心组件之一。它包含了多个可学习的滤波器(也称为卷积核),这些滤波器在输入数据上滑动,进行卷积操作并生成特征图。每个滤波器专注于检测输入数据的不同特征,如边缘、纹理等。通过堆叠多个卷积层,网络能够学习到更加复杂和抽象的特征。
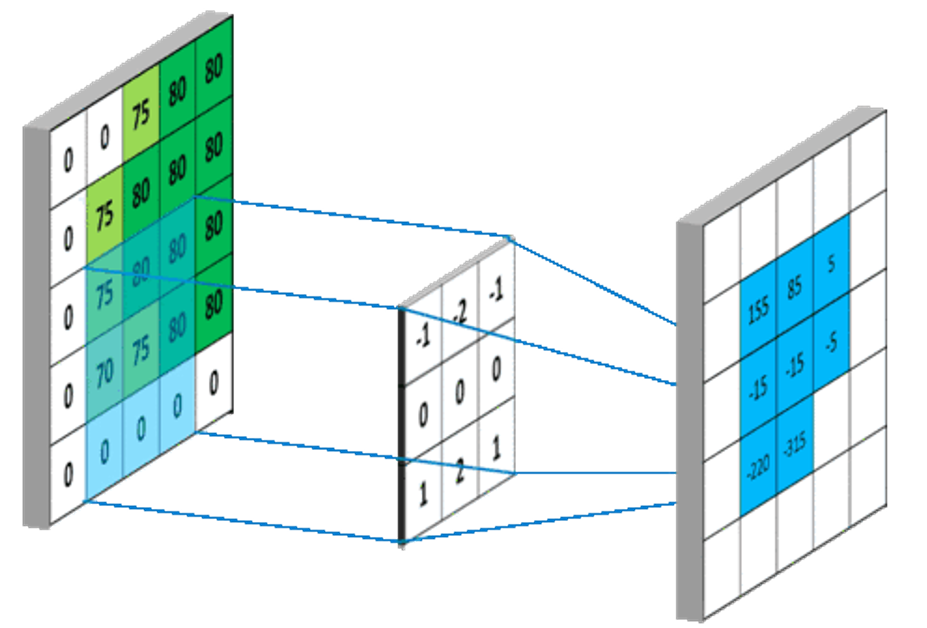
池化层(Pooling Layer):池化层用于减小特征图的空间维度,从而减少模型的参数量和计算复杂度,并且可以增强模型的鲁棒性。最常用的池化操作是最大池化(Max Pooling),它在每个区域内保留最大的特征值。池化操作通过保持主要特征并减少冗余信息来提取出更加重要的特征。
全连接层(Fully Connected Layer):全连接层将卷积层和池化层提取到的特征连接起来,并输出最终的分类或回归结果。它采用传统神经网络中常见的全连接结构,每个神经元都与上一层的所有神经元相连。全连接层的作用是对特征进行组合和整合,以便进行最终的预测。
总结起来,CNN通过卷积层逐步提取局部特征,使用池化层减小数据维度,而后在全连接层中对特征进行组合和分类。这种架构使得CNN能够有效地处理具有空间结构的输入数据,例如图像。通过反向传播算法来优化网络参数,CNN能够自动地学习到适合特定任务的特征表示,从而实现较好的性能。在图像识别、目标检测、人脸识别等计算机视觉任务。
在TensorFlow中,可以使用tf.keras.layers.Conv2D来定义卷积层。这个函数有很多参数,例如filters表示卷积核的数量,kernel_size表示卷积核的大小,strides表示步长,padding表示填充方式等。下面进行详细介绍。
4.2 CNN的超参数
4.2.1 卷积操作的维度
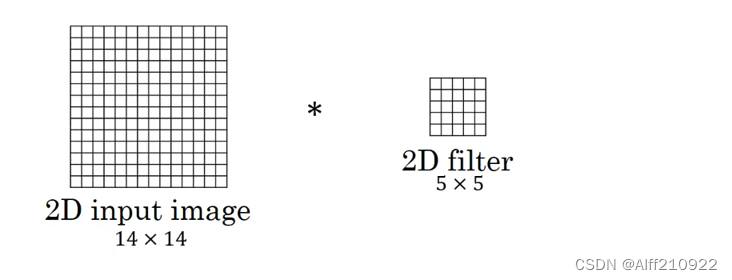
二维卷积是将一个特征图在width和height两个方向进行滑动窗口操作,对应位置进行相乘求和;
import tensorflow as tf
x = tf.get_variable(name="x", shape=[1, 3, 3, 5], initializer=tf.zeros_initializer)
x = tf.layers.conv2d(
x,
filters=1, # 结果的第三个通道是1
kernel_size=[1, 1],
strides=[1, 1],
padding='same',
data_format='channels_last',
use_bias=True,
bias_initializer=tf.zeros_initializer())
print(x) # shape=(1, 3, 3, 1)而一维卷积则只是在width或者height方向上进行滑动窗口并相乘求和。
import tensorflow as tf
x = tf.get_variable(name="x", shape=[32, 512, 1024], initializer=tf.zeros_initializer)
x = tf.layers.conv1d(
x,
filters=1, # 输出的第三个通道是1
kernel_size=512,
strides=1,
padding='same',
data_format='channels_last',
dilation_rate=1,
use_bias=True,
bias_initializer=tf.zeros_initializer())
print(x) # Tensor("conv1d/BiasAdd:0", shape=(32, 512, 1), dtype=float32)4.2.2 通道
通道就是从不同“角度”看待你的输入,在图像里面,RGB格式的图像就有3个通道(红,绿,蓝)。同样的,NLP中也有不同的通道,例如可以把通道分为不同的词嵌入方法(word2vec,GloVe等),不同语种的表达,或者同一个意思不同方式的表达。
4.2.3 核尺寸
卷积核的大小决定了网络提取特征的空间范围。对于小尺寸的图像特征,可以选择小的卷积核;对于大尺寸图像特征,可以选择更大的卷积核。常见的卷积核大小为3x3和5x5,但也可以尝试其他尺寸。
4.2.4 步幅
http://cs231n.github.io/convolutional-networks/
步长决定了卷积操作每次在输入上移动的距离。较大的步长可以减少输出的尺寸,同时可能会损失一些细节信息。较小的步长可以更细致地探索输入,但会增加计算负担。根据问题和数据的复杂性,选择适当的步长。
4.2.5 填充
处理特征图边界的方式,一般有两种,一种是“valid”,对边界外完全不填充,只对输入像素执行卷积操作,这样会使输出特征图像尺寸变得更小,且边缘信息容易丢失;另一种是还是“same”,对边界外进行填充(一般填充为0),再执行卷积操作,这样可使输出特征图的尺寸与输入特征图的尺寸一致,边缘信息也可以多次计算。
4.2.6 膨胀
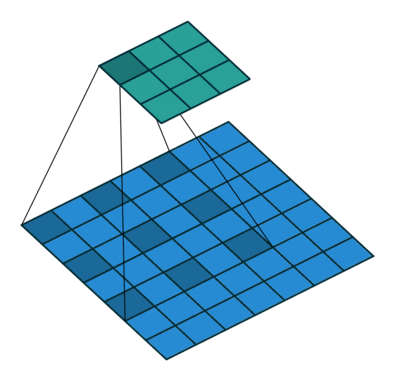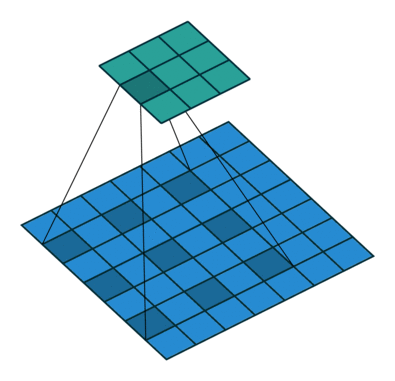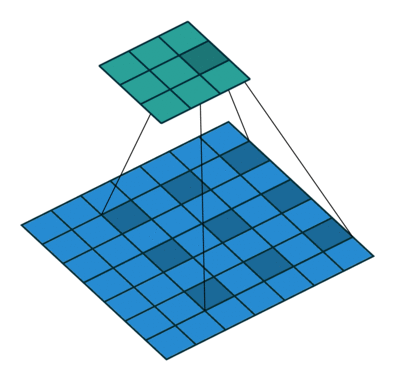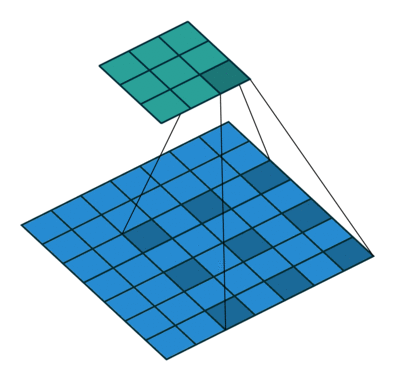
如上图,膨胀卷积的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。在图像需要全局信息或者自然语言处理中需要较长的sequence信息依赖的问题中,都能很好的应用。
4.3 在PyTorch中实现CNN
4.3.1 人工数据和使用Conv1d类
构造特征向量的第一步是将PyTorch的Conv1d类的一个实例应用到三维数据张量。通过检查输出的大小,你可以知道张量减少了多少。
# 定义超参数
batch_size = 2 # 批量大小,表示每次处理的数据样本数量
one_hot_size = 10 # one-hot编码的大小,表示每个时间步的特征维度
sequence_width = 7 # 序列宽度,表示时间序列中的时间步数量
# 生成随机数据作为输入,形状为(batch_size, one_hot_size, sequence_width)
# 这里的数据可以看作是两个样本,每个样本是一个长度为7的时间序列,每个时间步的特征维度为10
data = torch.randn(batch_size, one_hot_size, sequence_width)
# 定义一维卷积层,输入通道数为one_hot_size,输出通道数为16,卷积核大小为3
conv1 = Conv1d(in_channels=one_hot_size, out_channels=16, kernel_size=3)
# 应用卷积层到数据上,得到中间输出
intermediate1 = conv1(data)
# 打印输入数据的形状
print(data.size()) # 输出形状为(batch_size, one_hot_size, sequence_width)
# 打印卷积后的中间输出形状
# 卷积操作会改变序列宽度,新的序列宽度取决于输入序列宽度、卷积核大小和填充情况
print(intermediate1.size()) # 输出形状为(batch_size, out_channels, new_sequence_width)

4.3.2 卷积在数据上的迭代应用
# 定义第二个一维卷积层,输入通道数为16,输出通道数为32,卷积核大小为3
conv2 = nn.Conv1d(in_channels=16, out_channels=32, kernel_size=3)
# 定义第三个一维卷积层,输入通道数为32,输出通道数为64,卷积核大小为3
conv3 = nn.Conv1d(in_channels=32, out_channels=64, kernel_size=3)
# 将第一个卷积层的输出通过第二个卷积层,得到第二个中间结果
intermediate2 = conv2(intermediate1)
# 将第二个卷积层的输出通过第三个卷积层,得到第三个中间结果
intermediate3 = conv3(intermediate2)
# 打印第二个卷积层输出数据的形状
print(intermediate2.size())
# 打印第三个卷积层输出数据的形状
print(intermediate3.size())

延申
在深度学习中,将张量简化为每个数据点的一个特征向量通常涉及到对张量进行某种形式的池化(pooling)或全局平均池化(global average pooling),以及可能的扁平化(flattening)操作。以下是一些常用的方法:
-
全局平均池化 (Global Average Pooling): 全局平均池化会沿着张量的空间维度(例如,图像的高度和宽度)计算平均值,从而为每个通道(feature map)生成一个单一的值。这个操作通常用于卷积神经网络的末端,作为全连接层的一种替代,以减少参数数量和过拟合的风险。
-
最大池化 (Max Pooling): 最大池化会沿着张量的空间维度选取最大值,为每个通道生成一个单一的值。虽然它不会减少通道数,但它可以减少空间维度的大小。
-
扁平化 (Flattening): 扁平化是将张量转换为向量的一种方法,它将张量的所有维度的值连成一个长向量。这通常在卷积层之后和全连接层之前使用。
-
全连接层 (Fully Connected Layer): 全连接层对输入张量的每个元素进行加权,并输出一个特征向量。这是传统的深度神经网络中常用的方法。
-
注意力机制 (Attention Mechanism): 注意力机制可以通过为输入张量的不同部分分配不同的权重来生成一个特征向量,这种方法在自然语言处理和某些视觉任务中非常流行。
-
自适应平均池化 (Adaptive Average Pooling): 自适应平均池化可以输入任何尺寸的张量,并输出指定尺寸的张量。当目标尺寸为1x1时,它将张量简化为单个特征向量。
4.3.3 两种额外的特征向量缩减方法例子
# 压缩第三个卷积层的输出,去除维度为1的维度
y_output = intermediate3.squeeze()
# 打印压缩后的输出数据的形状
print(y_output.size())
![]()
这种设计一系列卷积的方法是基于经验的:从数据的预期大小开始,处理一系列卷积,最终得到适合特征向量。
4.4 使用CNN进行姓氏分类的示例
为了评估卷积神经网络(CNN)在姓氏分类任务中的性能,我们构建了一个基础的CNN模型。与之前的多层感知机(MLP)模型不同,CNN的输入是扩展的one-hot矩阵,而不是压缩的one-hot向量。这种设计优化了CNN对字符序列的识别能力,使其能够捕捉到MLP模型可能忽略的序列信息。
4.4.1 SurnameDataset的修改
调整SurnameDataset 我们对SurnameDataset类中的__getitem__方法进行了调整,以满足CNN对输入数据的特定要求。与MLP示例中的数据集相比,主要的变化在于数据集的组成。它现在由one-hot矩阵构成,而非单一的one-hot向量。为了支持这种变化,数据集类必须跟踪数据集中最长的姓氏,以便为矢量化器提供矩阵的行数。每个one-hot向量对应矩阵的一列,其大小与词汇表的大小相匹配。这样的设计确保了每个批次中的姓氏矩阵可以被组合成一个统一的三维张量,以便CNN能够有效地处理。
class SurnameDataset(Dataset):
# ... existing implementation from Section 4.2
def __getitem__(self, index):
row = self._target_df.iloc[index]
surname_matrix = \
self._vectorizer.vectorize(row.surname, self._max_seq_length)
nationality_index = \
self._vectorizer.nationality_vocab.lookup_token(row.nationality)
return {'x_surname': surname_matrix,
'y_nationality': nationality_index}4.4.2 词汇、向量化器和数据加载器
词汇表、矢量化器和DataLoader 尽管词汇表和DataLoader的实现与MLP示例中的相同,但SurnameVectorizer的vectorize方法进行了修改,以适应CNN的需求。该方法现在将字符映射为整数,并基于这些整数构建由one-hot向量组成的矩阵。这种修改的必要性在于,CNN使用的Conv1d层要求输入张量的第0维表示批次大小,第1维表示通道数,第2维表示特征数。
除了更改输入为one-hot矩阵外,我们还修改了矢量化器,以计算姓氏的最大长度,并将其保存为max_surname_length。这个长度用于确定one-hot矩阵的大小,确保所有输入矩阵的大小一致,这对于CNN的训练至关重要。
class SurnameVectorizer(object):
""" 负责协调词汇表并使用它们进行向量化的类 """
def vectorize(self, surname):
"""
将姓氏字符串向量化为one-hot矩阵
Args:
surname (str): 需要向量化处理的姓氏
Returns:
one_hot_matrix (np.ndarray): 姓氏对应的one-hot矩阵
"""
# 创建一个零矩阵,其大小为字符词汇表的长度乘以最大姓氏长度
one_hot_matrix_size = (len(self.character_vocab), self.max_surname_length)
one_hot_matrix = np.zeros(one_hot_matrix_size, dtype=np.float32)
# 遍历姓氏中的每个字符
for position_index, character in enumerate(surname):
# 获取字符在字符词汇表中的索引
character_index = self.character_vocab.lookup_token(character)
# 在one-hot矩阵中对应的位置标记为1
one_hot_matrix[character_index][position_index] = 1
return one_hot_matrix
@classmethod
def from_dataframe(cls, surname_df):
""" 从数据集的数据框实例化向量器
Args:
surname_df (pandas.DataFrame): 姓氏数据集
Returns:
SurnameVectorizer的一个实例
"""
# 初始化字符词汇表,添加未知字符的标记
character_vocab = Vocabulary(unk_token="@")
# 初始化国籍词汇表,不添加未知字符的标记
nationality_vocab = Vocabulary(add_unk=False)
# 初始化最大姓氏长度为0
max_surname_length = 0
# 遍历数据框中的每一行
for index, row in surname_df.iterrows():
# 更新最大姓氏长度
max_surname_length = max(max_surname_length, len(row.surname))
# 将姓氏中的每个字符添加到字符词汇表中
for letter in row.surname:
character_vocab.add_token(letter)
# 将国籍添加到国籍词汇表中
nationality_vocab.add_token(row.nationality)
# 返回SurnameVectorizer的实例
return cls(character_vocab, nationality_vocab, max_surname_length)
4.4.3 使用卷积网络重新实现SurnameClassifier
一个基于卷积神经网络(CNN)的字符级分类器。这个类继承自nn.Module,是PyTorch中所有神经网络模块的基类。
这种网络结构适用于处理序列数据,如姓氏,因为它能够捕捉到序列中的局部特征(通过卷积层)并将这些特征汇总起来(通过全连接层)进行分类。卷积层使用的3x1卷积核和步幅为2的下采样有助于减少数据的空间维度,同时保持重要的特征信息。ELU激活函数则提供了非线性特性,有助于网络学习复杂的特征。
import torch.nn as nn
import torch.nn.functional as F
class SurnameClassifier(nn.Module):
def __init__(self, initial_num_channels, num_classes, num_channels):
"""
Args:
initial_num_channels (int): 输入特征向量的尺寸
num_classes (int): 输出预测向量的尺寸
num_channels (int): 网络中各个卷积层使用的通道数
"""
super(SurnameClassifier, self).__init__()
# 定义卷积神经网络结构
self.convnet = nn.Sequential(
# 第一层卷积,使用3x1的卷积核
nn.Conv1d(in_channels=initial_num_channels,
out_channels=num_channels, kernel_size=3),
# 激活函数 ELU
nn.ELU(),
# 第二层卷积,使用3x1的卷积核,步幅为2
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
# 激活函数 ELU
nn.ELU(),
# 第三层卷积,使用3x1的卷积核,步幅为2
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
# 激活函数 ELU
nn.ELU(),
# 第四层卷积,使用3x1的卷积核
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3),
# 激活函数 ELU
nn.ELU()
)
# 定义全连接层,将卷积层的输出映射到类别数
self.fc = nn.Linear(num_channels, num_classes)
def forward(self, x_surname, apply_softmax=False):
"""分类器的前向传播过程
Args:
x_surname (torch.Tensor): 输入数据张量。
x_surname.shape 应该是 (batch, initial_num_channels, max_surname_length)
apply_softmax (bool): 是否应用softmax激活函数的标志
如果与交叉熵损失一起使用,应该设置为false
Returns:
结果张量。tensor.shape 应该是 (batch, num_classes)
"""
# 通过卷积网络提取特征,并压缩掉序列长度维度
features = self.convnet(x_surname).squeeze(dim=2)
# 通过全连接层得到预测向量
prediction_vector = self.fc(features)
# 如果指定,则对预测向量应用softmax激活函数
if apply_softmax:
prediction_vector = F.softmax(prediction_vector, dim=1)
return prediction_vector
4.4.4 训练过程
训练程序包括以下序列:实例化数据集,实例化模型,实例化损失函数,实例化优化器,遍历数据集的训练分区和更新模型参数,遍历数据集的验证分区和测量性能,然后重复数据集迭代一定次数。
# 定义命令行参数
args = Namespace(
# 数据和路径信息
surname_csv="surnames_with_splits.csv", # 姓氏数据的CSV文件路径
vectorizer_file="vectorizer.json", # 矢量化器的JSON文件路径
model_state_file="model.pth", # 模型状态的PyTorch文件路径
save_dir="model_storage/surname_mlp", # 保存模型的目录路径
# 模型超参数
hidden_dim=300, # 隐藏层的维度
# 训练超参数
seed=1337, # 随机种子,用于结果复现
num_epochs=100, # 训练轮数
early_stopping_criteria=5, # 提前停止训练的准则
learning_rate=0.001, # 学习率
batch_size=64, # 批量大小
# 运行时选项
cuda=False, # 是否使用CUDA加速
reload_from_files=False, # 是否从文件加载模型和矢量化器
expand_filepaths_to_save_dir=True, # 是否将文件路径扩展到保存目录
)
# 如果需要将文件路径扩展到保存目录
if args.expand_filepaths_to_save_dir:
args.vectorizer_file = os.path.join(args.save_dir,
args.vectorizer_file)
args.model_state_file = os.path.join(args.save_dir,
args.model_state_file)
print("Expanded filepaths: ")
print("\t{}".format(args.vectorizer_file))
print("\t{}".format(args.model_state_file))
# 检查CUDA是否可用
if not torch.cuda.is_available():
args.cuda = False
# 设置设备,使用CUDA或CPU
args.device = torch.device("cuda" if args.cuda else "cpu")
print("Using CUDA: {}".format(args.cuda))
# 设置随机种子,以保证结果的可复现性
set_seed_everywhere(args.seed, args.cuda)
# 处理目录,确保保存目录存在
handle_dirs(args.save_dir)
if args.reload_from_files:
# 如果args.reload_from_files设置为True,则尝试从检查点加载数据集和向量器
print("Reloading!")
# 使用SurnameDataset类的静态方法load_dataset_and_load_vectorizer来加载数据集和向量器
# 这需要一个CSV文件路径和一个已经存在的向量器文件路径
dataset = SurnameDataset.load_dataset_and_load_vectorizer(args.surname_csv,
args.vectorizer_file)
else:
# 如果args.reload_from_files设置为False,则创建新的数据集和向量器
print("Creating fresh!")
# 使用SurnameDataset类的静态方法load_dataset_and_make_vectorizer来加载数据集并创建新的向量器
# 这需要一个CSV文件路径
dataset = SurnameDataset.load_dataset_and_make_vectorizer(args.surname_csv)
# 保存新创建的向量器到指定的文件路径,以便后续使用
dataset.save_vectorizer(args.vectorizer_file)
# 从数据集中获取向量器
vectorizer = dataset.get_vectorizer()
# 创建一个SurnameClassifier对象,它将用于处理人名数据
classifier = SurnameClassifier(input_dim=len(vectorizer.surname_vocab),
hidden_dim=args.hidden_dim,
output_dim=len(vectorizer.nationality_vocab))
# 将分类器模型转移到指定的设备上(CUDA或CPU)
classifier = classifier.to(args.device)
# 将数据集的类权重转移到指定的设备上(CUDA或CPU)
dataset.class_weights = dataset.class_weights.to(args.device)
# 定义损失函数,使用交叉熵损失函数,并考虑数据集的类权重
loss_func = nn.CrossEntropyLoss(dataset.class_weights)
# 创建优化器,使用Adam算法,并指定学习率
optimizer = optim.Adam(classifier.parameters(), lr=args.learning_rate)
# 创建学习率调度器,当验证损失不再下降时,将学习率减少一半
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer,
mode='min', factor=0.5,
patience=1)
# 创建训练状态对象,包含所有必要的参数和状态信息
train_state = make_train_state(args)
# 创建一个进度条,用于显示训练过程,描述为'training routine',总步数为训练轮数
epoch_bar = tqdm_notebook(desc='training routine',
total=args.num_epochs,
position=0)
# 设置数据集的划分方式为'train'
dataset.set_split('train')
# 创建一个进度条,用于显示'train'划分下的批次,总步数为数据集划分为'train'时的批次数
train_bar = tqdm_notebook(desc='split=train',
total=dataset.get_num_batches(args.batch_size),
position=1,
leave=True)
# 设置数据集的划分方式为'val'
dataset.set_split('val')
# 创建一个进度条,用于显示'val'划分下的批次,总步数为数据集划分为'val'时的批次数
val_bar = tqdm_notebook(desc='split=val',
total=dataset.get_num_batches(args.batch_size),
position=1,
leave=True)
try:
# 进入循环,遍历所有训练轮次
for epoch_index in range(args.num_epochs):
# 更新训练状态中的epoch索引
train_state['epoch_index'] = epoch_index
# 迭代训练数据集
# 设置:批生成器,设置损失和准确率初始化为0,设置模型为训练模式
# 设置数据集的划分方式为'train'
dataset.set_split('train')
# 创建一个批生成器,用于生成训练批次,指定批量大小和设备
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
# 初始化运行中的损失和准确率
running_loss = 0.0
running_acc = 0.0
# 将分类器设置为训练模式
classifier.train()
# 遍历批生成器生成的每个批次
for batch_index, batch_dict in enumerate(batch_generator):
# 训练循环的五个步骤:
# --------------------------------------
# 步骤1:清空梯度
optimizer.zero_grad()
# 步骤2:计算输出
y_pred = classifier(batch_dict['x_surname'])
# 步骤3:计算损失
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# 步骤4:使用损失产生梯度
loss.backward()
# 步骤5:使用优化器进行梯度更新
optimizer.step()
# -----------------------------------------
# 计算准确率
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
# 更新进度条
train_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
train_bar.update()
# 更新训练状态中的训练损失和训练准确率
train_state['train_loss'].append(running_loss)
train_state['train_acc'].append(running_acc)
# 迭代验证数据集
# 设置:批生成器,设置损失和准确率初始化为0;设置模型为评估模式
dataset.set_split('val')
# 创建一个批生成器,用于生成验证批次,指定批量大小和设备
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
# 初始化运行中的损失和准确率
running_loss = 0.
running_acc = 0.
# 将分类器设置为评估模式
classifier.eval()
# 遍历批生成器生成的每个批次
for batch_index, batch_dict in enumerate(batch_generator):
# 计算输出
y_pred = classifier(batch_dict['x_surname'])
# 步骤3:计算损失
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.to("cpu").item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# 计算准确率
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
# 更新进度条
val_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
val_bar.update()
# 更新训练状态中的验证损失和验证准确率
train_state['val_loss'].append(running_loss)
train_state['val_acc'].append(running_acc)
# 更新训练状态
train_state = update_train_state(args=args, model=classifier,
train_state=train_state)
# 学习率调度器根据最新的验证损失进行调整
scheduler.step(train_state['val_loss'][-1])
# 如果训练状态中停止提前的标志为True,则退出循环
if train_state['stop_early']:
break
# 重置进度条计数
train_bar.n = 0
val_bar.n = 0
# 更新训练进度条
epoch_bar.update()
except KeyboardInterrupt:
print("Exiting loop")
# 在测试集上使用最佳可用的模型计算损失和准确率
# 加载模型的状态字典
classifier.load_state_dict(torch.load(train_state['model_filename']))
# 将模型转移到指定的设备上(CUDA或CPU)
classifier = classifier.to(args.device)
# 将数据集的类权重转移到指定的设备上(CUDA或CPU)
dataset.class_weights = dataset.class_weights.to(args.device)
# 定义损失函数,使用交叉熵损失函数,并考虑数据集的类权重
loss_func = nn.CrossEntropyLoss(dataset.class_weights)
# 设置数据集的划分方式为'test'
dataset.set_split('test')
# 创建一个批生成器,用于生成测试批次,指定批量大小和设备
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
# 初始化运行中的损失和准确率
running_loss = 0.
running_acc = 0.
# 将分类器设置为评估模式
classifier.eval()
# 遍历批生成器生成的每个批次
for batch_index, batch_dict in enumerate(batch_generator):
# 计算输出
y_pred = classifier(batch_dict['x_surname'])
# 计算损失
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# 计算准确率
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
# 更新训练状态中的测试损失和测试准确率
train_state['test_loss'] = running_loss
train_state['test_acc'] = running_acc

4.4.5 模型评估和预测
4.4.5.1 对新姓氏进行分类或检索前k个预测
def predict_nationality(surname, classifier, vectorizer):
"""根据新姓氏预测国籍
参数:
surname (str): 需要分类的姓氏
classifier (SurnameClassifier): 分类器的实例
vectorizer (SurnameVectorizer): 对应的向量化器
返回:
一个字典,包含最可能的国籍及其概率
"""
# 使用向量化器将姓氏转换为数值格式
vectorized_surname = vectorizer.vectorize(surname)
# 将向量化后的姓氏转换为PyTorch张量,并调整形状以适配分类器的输入要求
vectorized_surname = torch.tensor(vectorized_surname).view(1, -1)
# 使用分类器对向量化后的姓氏进行预测,输出每个可能国籍的概率
# apply_softmax=True表示分类器会对输出应用softmax函数,确保概率总和为1
result = classifier(vectorized_surname, apply_softmax=True)
# 从结果张量中提取最大概率及其对应的索引
# 最大概率对应的索引即为预测的国籍
probability_values, indices = result.max(dim=1)
index = indices.item()
# 使用向量化器的国籍词汇表将索引转换回可读的国籍名称
predicted_nationality = vectorizer.nationality_vocab.lookup_index(index)
# 提取预测国籍的概率值
probability_value = probability_values.item()
# 返回包含预测国籍和概率的字典
return {'nationality': predicted_nationality, 'probability': probability_value}
4.4.5.2 使用训练好的模型进行预测
# 用户输入一个姓氏以进行分类
new_surname = input("Enter a surname to classify: ")
# 将分类器从GPU移动到CPU,如果之前在GPU上训练的话
classifier = classifier.to("cpu")
# 使用predict_nationality函数预测输入姓氏的国籍
prediction = predict_nationality(new_surname, classifier, vectorizer)
# 打印预测结果,包括输入的姓氏、预测的国籍和概率
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))
Top-K Inference
实现了一个简单的用户交互界面,用于输入一个姓氏,然后预测这个姓氏最可能的国籍,并显示前k个预测结果。
vectorizer.nationality_vocab.lookup_index(8)
def predict_topk_nationality(name, classifier, vectorizer, k=5):
# 使用向量化器将姓名转换为数值格式
vectorized_name = vectorizer.vectorize(name)
# 将向量化后的姓名转换为PyTorch张量,并调整形状以适配分类器的输入要求
vectorized_name = torch.tensor(vectorized_name).view(1, -1)
# 使用分类器对向量化后的姓名进行预测,输出每个可能国籍的概率
# apply_softmax=True表示分类器会对输出应用softmax函数,确保概率总和为1
prediction_vector = classifier(vectorized_name, apply_softmax=True)
# 获取概率最高的前k个预测结果及其索引
probability_values, indices = torch.topk(prediction_vector, k=k)
# 从张量中提取概率值和索引,并转换为numpy数组
# returned size is 1,k
probability_values = probability_values.detach().numpy()[0]
indices = indices.detach().numpy()[0]
# 初始化一个空列表来存储结果
results = []
# 遍历概率值和索引,将索引转换为国籍名称,并添加到结果列表中
for prob_value, index in zip(probability_values, indices):
nationality = vectorizer.nationality_vocab.lookup_index(index)
results.append({'nationality': nationality,
'probability': prob_value})
# 返回包含前k个预测结果的列表
return results
# 用户输入一个姓氏以进行分类
new_surname = input("Enter a surname to classify: ")
# 将分类器从GPU移动到CPU,如果之前在GPU上训练的话
classifier = classifier.to("cpu")
# 用户输入想要查看的顶部预测数量
k = int(input("How many of the top predictions to see? "))
# 如果用户请求的预测数量超过国籍词汇表的大小,则默认显示最大数量
if k > len(vectorizer.nationality_vocab):
print("Sorry! That's more than the # of nationalities we have.. defaulting you to max size :)")
k = len(vectorizer.nationality_vocab)
# 使用predict_topk_nationality函数预测输入姓氏的前k个国籍
predictions = predict_topk_nationality(new_surname, classifier, vectorizer, k=k)
# 打印顶部预测结果
print("Top {} predictions:".format(k))
print("===================")
# 遍历预测结果并打印每个预测的国籍和概率
for prediction in predictions:
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))

4.5 CNN中的其他主题
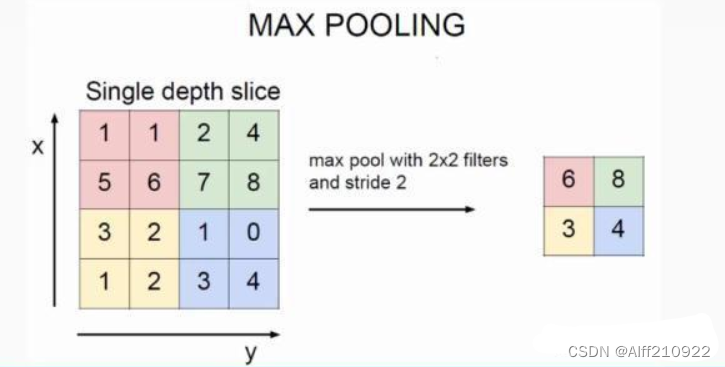
4.5.1 池化操作
池化过程在一般卷积过程后。池化(pooling) 的本质,其实就是采样。Pooling 对于输入的 Feature Map,选择某种方式对其进行降维压缩,以加快运算速度。
采用较多的一种池化过程叫最大池化(Max Pooling),其具体操作过程如下:
还有一种叫平均池化(Average Pooling),就是从以上取某个区域的最大值改为求这个区域的平均值,例子如下:
import torch
import torch.nn.functional as F
input = torch.Tensor(4,3,16,16)
output = F.avg_pool2d(input, kernel_size=2, stride=2)
output.shape
torch.Size([4, 3, 8, 8])
4.5.2 批量归一化(BatchNorm)
批量归一化(Batch Normalization)是一种在神经网络中常用的正则化和加速训练的技术。它通过在神经网络的每一层之后引入一个归一化层,从而帮助网络更快地学习。批量归一化的工作原理如下:
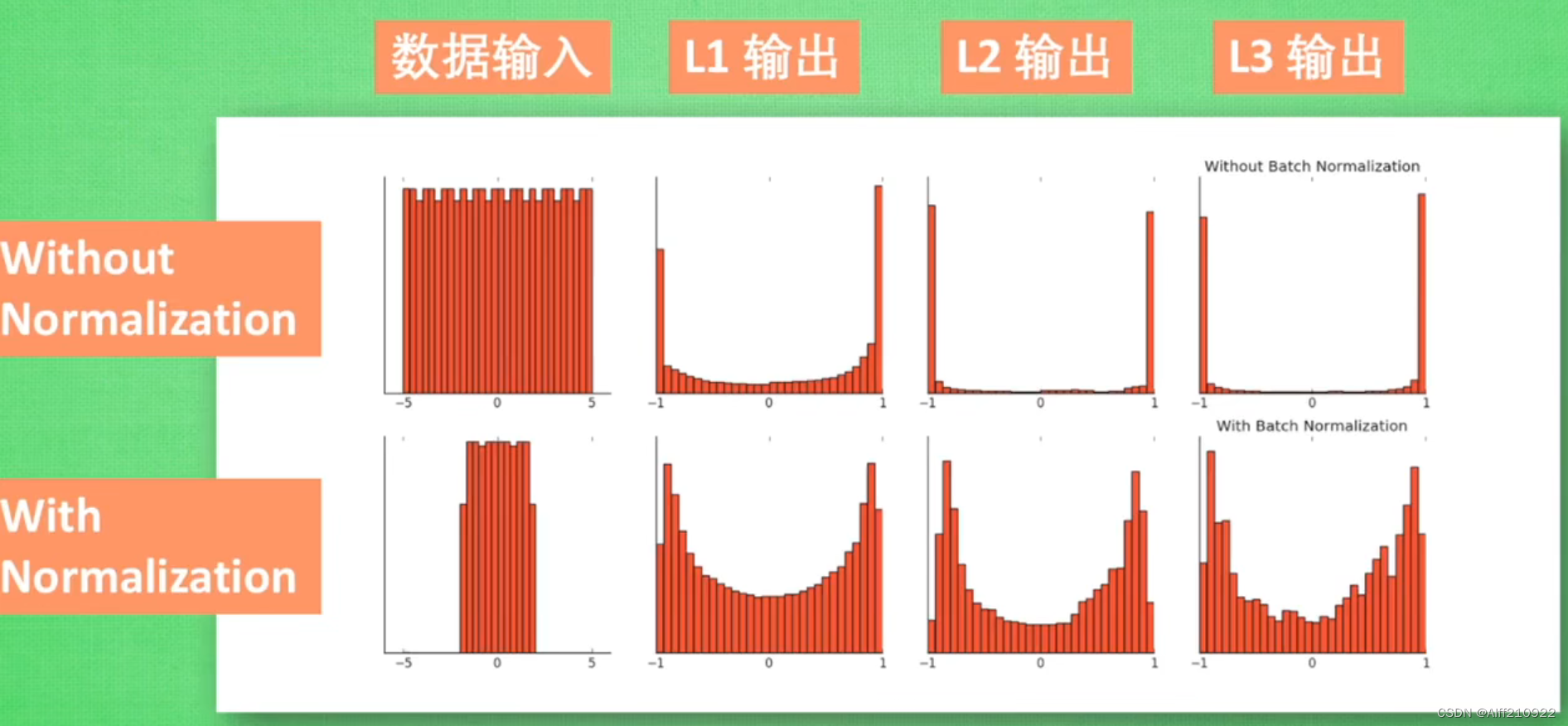
-
收集数据: 批量归一化需要收集当前批次(batch)的所有输入数据。对于每个输入数据,批量归一化都会计算数据的均值(mean)和方差(variance)。
-
标准化: 标准化是将数据从原始分布(通常是均值为0、方差为1的正态分布)转换为标准化的分布。对于每个输入数据,批量归一化会将其减去均值,然后除以方差的平方根,最后乘以一个可学习的参数(称为“缩放”或“γ”)和一个可学习的参数(称为“偏移”或“β”)。这个过程可以表示为:
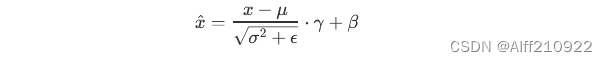
-
增加可学习的参数: 批量归一化中增加了两个可学习的参数(γγ 和 ββ),它们是批量归一化层的一部分。这些参数可以帮助网络更快地学习,并可以调整数据的分布,使其更适合网络的训练。
-
应用激活函数: 在批量归一化之后,通常会应用一个激活函数,如ReLU或Sigmoid。激活函数可以帮助网络学习更复杂的非线性关系。
批量归一化的优点包括:
-
加速训练:批量归一化可以加速神经网络的训练过程,因为它可以减少梯度消失和梯度爆炸的问题,从而使网络更容易训练。
-
减少过拟合:批量归一化可以帮助网络更好地泛化到新的数据,从而减少过拟合的问题。
-
提高性能:批量归一化可以提高神经网络的性能,因为它可以提高网络的准确性和稳定性。
批量归一化是一种非常强大的技术,它在许多不同的神经网络架构中都有应用,包括卷积神经网络(CNN)、循环神经网络(RNN)和长短期记忆网络(LSTM)等。
4.5.3 残差连接/残差块
在卷积神经网络(CNN)中,残差连接(Residual Connection)或残差块(Residual Block)是一种结构,它允许网络学习输入数据的直接映射,而不是试图从零开始学习每个层的输出。这种结构最早由He等人在2016年的论文《Deep Residual Learning for Image Recognition》中提出,并在VGGNet、ResNet等网络架构中得到了广泛应用。
(1)残差连接
残差连接的基本思想是在网络的某些层之间添加一个短路,即直接将输入数据与输出数据相加。这种连接的目的是为了保留输入数据的一些原始信息,从而避免在训练过程中梯度消失或梯度爆炸的问题。残差连接通常在网络的瓶颈层或深层结构中使用,以提高网络的训练效率和性能。
(2)残差块
残差块是包含残差连接的CNN结构,它由两个或多个卷积层组成,每个卷积层后面都跟着一个非线性激活函数。在残差块中,输入数据首先通过第一个卷积层,然后通过第二个卷积层,最后通过一个残差连接。残差连接的目的是为了保留输入数据的原始信息,从而帮助网络更好地学习输入数据的特征。
残差块的公式可以表示为:
y=H(x)+F(x)
其中,x 是输入数据,H(x) 是通过第一个卷积层后的输出,F(x) 是通过第二个卷积层后的输出,y 是残差块的输出。
(3)应用
残差连接和残差块在CNN中得到了广泛应用,特别是在深度网络中。它们可以帮助网络更好地学习输入数据的特征,从而提高网络的性能和泛化能力。例如,在ResNet网络中,残差连接和残差块被广泛应用于网络的各个层次,从而实现了非常深的网络结构。
总之,残差连接和残差块是CNN中非常重要的结构,它们可以帮助网络更好地学习输入数据的特征,从而提高网络的性能和泛化能力。
五、总结
5.1 多层感知器和卷积神经网络在前馈神经网络中的位置
多层感知器(MLP)和卷积神经网络(CNN)都是前馈神经网络(Feedforward Neural Network)的变体。在前馈神经网络中,信息仅在神经元之间单向传递,不涉及循环。MLP和CNN在前馈神经网络中的位置如下:
-
多层感知器(MLP):MLP是一种全连接的神经网络,其中每个神经元都与其前一层的所有神经元相连。MLP可以用于处理多种类型的数据,包括文本、图像等。MLP在多层感知机中,通常包含一个或多个隐藏层,以及一个输出层。
-
卷积神经网络(CNN):CNN是一种专门用于处理图像和序列数据的神经网络。CNN包含多个卷积层、池化层和全连接层。卷积层用于提取输入数据的特征,池化层用于减小特征图的大小,全连接层用于进行分类或回归任务。
5.2 理解数据张量的大小和形状对神经网络模型的重要性
在神经网络中,数据张量的大小和形状对于模型的训练和预测至关重要。数据张量的大小和形状决定了网络输入数据的维度和特征。以下是一些关于数据张量大小和形状的重要性的关键点:
-
维度:数据张量的大小决定了输入数据的特征数量和空间维度。例如,对于图像数据,张量的大小通常包括高度、宽度和颜色通道的数量。
-
形状:数据张量的大小和形状决定了网络输入数据的布局和结构。网络需要知道输入数据的形状,以便正确地处理和解释数据。
-
特征提取:在神经网络中,卷积层和池化层用于提取输入数据的特征。这些层需要知道数据张量的大小和形状,以便正确地应用卷积和池化操作。
-
网络结构:神经网络的结构和层数决定了数据张量的大小和形状的变化。网络的每一层都会对数据张量的大小和形状进行变换,因此需要了解每一层的输出形状。
-
损失函数和优化器:在神经网络的训练过程中,损失函数和优化器需要知道输入数据的形状,以便计算损失和更新权重。
因此,了解数据张量的大小和形状对于设计和训练神经网络至关重要。通过正确处理和理解数据张量的大小和形状,可以提高神经网络的性能和准确性
六、参考文献
CNN学习(5):残差网络ResNet和卷积神经网络CNN中的常见操作_卷积神经网络和残差网络-优快云博客
https://blog.youkuaiyun.com/qq_46703208/article/details/129785264
https://blog.youkuaiyun.com/qq_62573714/article/details/137243838
https://blog.youkuaiyun.com/weixin_72943020/article/details/134892324


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









