




Web服务器
Web服务器是互联网时代最为重要的TCP服务器。Web服务器不仅为站点提供基本的Web访问功能,还是Web service、微服务架构的基础设施。
Web服务器使用应用层协议是HTTP。HTTP是最重要的应用层协议,而且诸如SOAP和REST都是基于HTTP。
这一部分,我们要编写一个Web服务器,通过这一例子去理解应用层协议到底是什么,以及如何编写多进程服务器(稍后会学习多线程和I/O复用)。
HTTP入门
对于一个不熟悉HTTP的初学者,如何去从头着手呢?首先,我们有标准的HTTP服务器,本机有httpd(Apache Web Server)、所有的网站也都是标准的HTTP服务器;其次,我们也有标准的HTTP客户端,Web浏览器;最后,我们有标准的TCP客户端telnet,以及上一章我们自己编写的TCP server。这样我们就可以分别观察标准HTTP Server和Client的行为了。
首先,我们用telnet访问某一个网站。这里以访问东北大学为例。我们发现connect之后没有任何反应,所以显然,这时服务器端在read,客户端需要write,但不知道该说些什么。随便发送一些字符试一试。
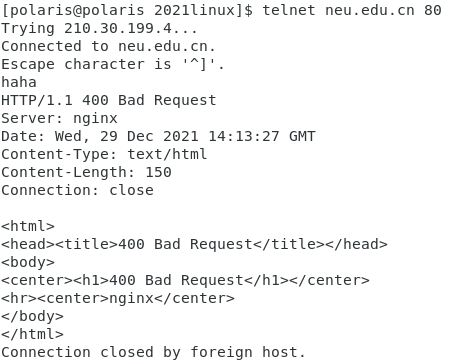
我们发送“haha”给了服务器,“haha”下面的全是服务器写给我们的内容,即HTTP响应报文,响应报文分为三部分:
- 响应行:响应行主要包括响应协议,比如HTTP/1.1;状态码,这里是400;状态码的描述:Bad Request。
常见状态码:
100~199:表示成功接收请求,要求客户端继续提交下一次请求才能完成整个处理过程。
200~299:表示成功接收请求并已完成整个处理过程。常用200。
300~399:为完成请求,客户需进一步细化请求。
400~499:客户端的请求有错误,常用404(在web服务器中没有该文件)、403(权限不够)
500~599:服务器端出现错误,常用500。
响应头:响应头就是一些常见的响应名对应的响应值。比如返回内容的MIME类型,这里是Content-Type: text/html,说明响应体是一个text纯文本文件,而且是html纯文本。
响应体:响应头后面用“\r\n\r\n”与响应体隔开。因为C语言里字符和字节是同样的东西:8bit整数,因此响应体除了是纯文本,还可以是图片——也是当作char附在“\r\n\r\n”即可。
很显然,我们上面的例子客户端给服务器发送了不能处理的请求“haha”。所以现在我们要试一试标准的HTTP客户端——Web浏览器。
我们把上一章第一个server稍微改了一下,把客户端发送的内容直接在server的终端打印出来。
#include <sys/socket.h>
#include <netinet/in.h>
#include <netinet/ip.h>
#include <stdlib.h>
#include <arpa/inet.h>
#include <stdlib.h>
#include <unistd.h>
main(int ac, char *av[]){
int tcp_socket;
struct sockaddr_in addr;
int fd;
char buf[512];
int n;
tcp_socket = socket(AF_INET, SOCK_STREAM, 0);
addr.sin_family = AF_INET;
addr.sin_port = htons(atoi(av[1]));
addr.sin_addr.s_addr = INADDR_ANY;
if(bind(tcp_socket, (const struct sockaddr *)&addr, sizeof(struct sockaddr_in))==-1){
perror("cannot bind");
exit(1);
}
listen(tcp_socket, 1);
fd=accept(tcp_socket, NULL, NULL);
n=read(fd, buf, sizeof(buf));
write(1, buf, n);
close(fd);
}
首先运行上面的server程序。
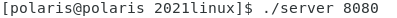
通过Web浏览器访问我们的server。

这时Server在终端输出了Web浏览器的请求报文。
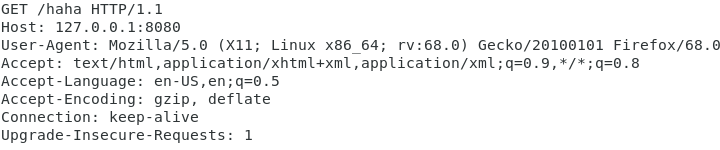
为了更好的研究HTTP服务器,我们还是要用到我们本机的Web server,httpd(Apache Web Server)。首先要确保自己的系统是否安装的httpd,然后切换到超级用户,使用systemctl启动httpd。
使用超级用户在/var/www/html/下创建一个html文件。
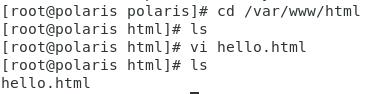
先用浏览器看看能否访问。

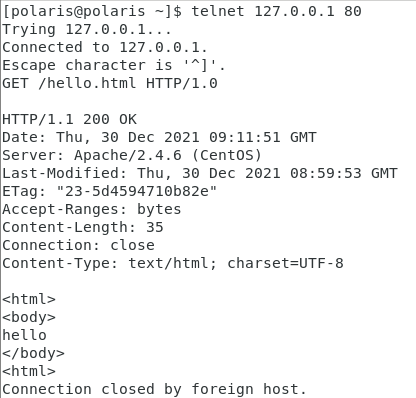
再用telnet访问一下。当连接到httpd之后,输入GET /hello.html HTTP/1.0,之后敲两个回车(即\r\n\r\n )。
再看一个例子。URL中的目录结构与Web Server的主目录/var/www/html下的目录结构完全是对应的。有一个特例是/这个目录,即直接在浏览器输入网址/IP地址,会返回一个默认页码(取决于Web服务器的设置)。
下面我们再研究一下有图片的页面。
随便去一个网站,保存一个html页面。
将其放到/var/www/html下
用浏览器访问本机httpd提供的这个网页。
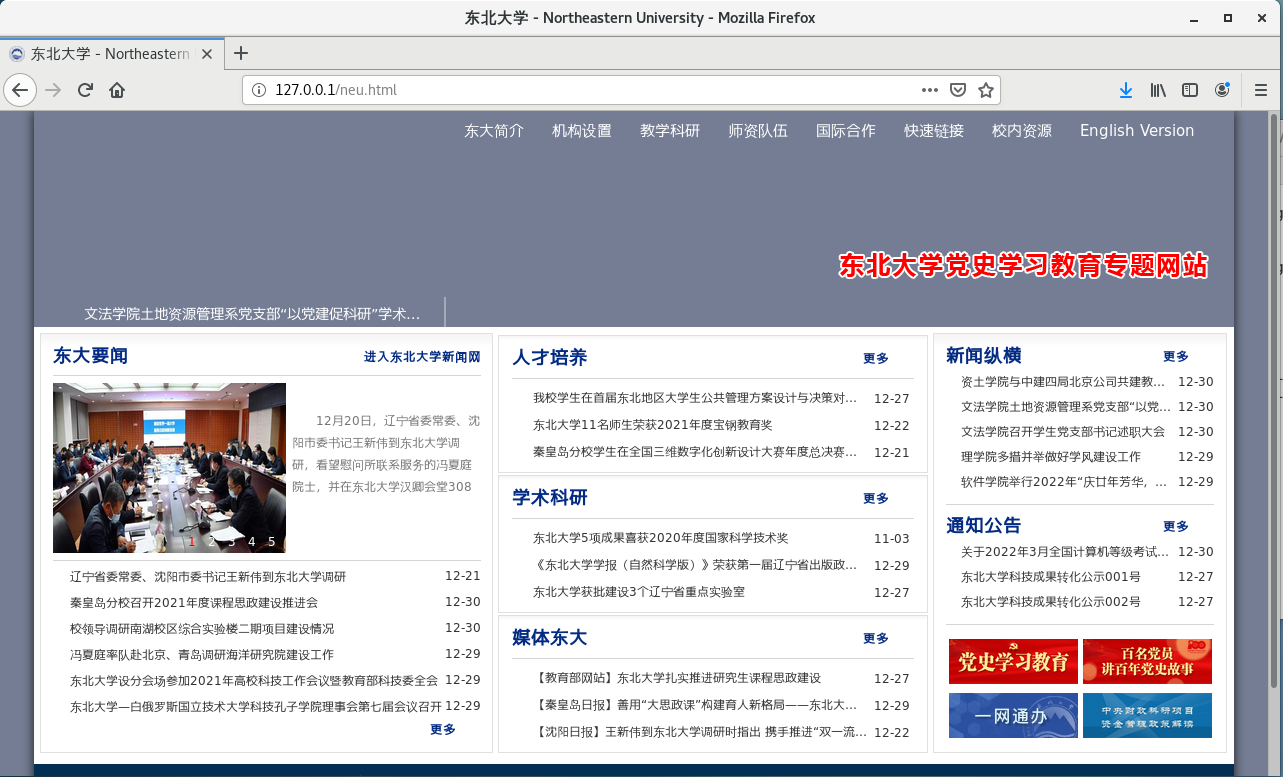
事实上,“neu.html”是一个纯文本文件。之所以上面能显示图片,是因为html中写明了在指定位置存在图片,并给出了其位置。通过neu.html,我们知道在这有一张jpg图片,并且给出了位置。
实际上,neu.html这个页面是通过GET多次来获得页面上所有的文件的,如果通过一次TCP连接GET所有文件,则是HTTP/1。对于HTTP/1.0,页面上每个文件都需要建立一次TCP连接GET得到。
我们也可以用telnet直接GET一张图片。除了MIME类型变成了image/png,响应体由于是图片,所以用字符显示出来几乎是乱码之外,与一个纯文本的HTML页面没有本质不同。
HTTP的GET命令就是用来传输文件的——即使在集群内部,我们也经常使用HTTP传输文件,它比NFS之类的网络文件系统更为可靠。
Web服务器编写
通过上面一节,我们已经基本掌握了HTTP协议中的GET命令,我们下面就实现一个只支持GET命令的Web服务器——但是它已经可以实现对静态页面的访问——这也是网站最重要的功能。
版本1
无论客户端GET什么文件,都只返回其一个固定的HTML页面——该页面写死在服务器程序里。
另外,服务器是一个死循环,不停地accept,提供服务,close…… 大部分服务器都是这种死循环。
#include <sys/socket.h>
#include <netinet/in.h>
#include <netinet/ip.h>
#include <stdlib.h>
#include <arpa/inet.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
#include <string.h>
main(int ac, char *av[]){
int tcp_socket;
struct sockaddr_in addr;
int fd;
char buf[1024];
char message[1024]="HTTP/1.1 200 OK\r\n\r\n<html> <body> Hello world! Haha </body> </html>";
int n;
tcp_socket = socket(AF_INET, SOCK_STREAM, 0);
addr.sin_family = AF_INET;
addr.sin_port = htons(atoi(av[1]));
addr.sin_addr.s_addr = INADDR_ANY;
if(bind(tcp_socket, (const struct sockaddr *)&addr, sizeof(struct sockaddr_in))==-1){
perror("cannot bind");
exit(1);
}
listen(tcp_socket, 1);
while(1){
fd=accept(tcp_socket, NULL, NULL);
n=read(fd, buf, sizeof(buf));
write(fd, message, strlen(message));
close(fd);
}
}
编译运行,绑定在9000端口。运行结果如下:


无论客户端GET什么页面,都返回同样内容。
版本2
根据用户GET的文件名,将文件内容写给Web浏览器。在这里,我们仅写给Web浏览器相应行和响应体,并没有写响应头——由于现代浏览器健壮性很好,因此不写也不会影响其结果。
在这里我们用了一个大小为1024的buffer来一次性读取客户端的请求报文。注意这个缓存要足够大才能一次read存得下请求报文,比如设置为512肯定就无法工作。一般可以使用stdio.h中的BUFSIZ作为缓存的大小,它的值是8192。实际上,HTTP GET方法提交的数据大小长度并没有限制(但浏览器对URL长度会有限制,不同的浏览器限制不同,如Firefox浏览器URL的长度限制为65536个字符)。因此即使缓存设置为BUFSIZ,本程序还是有出现bug的可能性。
#include <sys/socket.h>
#include <netinet/in.h>
#include <netinet/ip.h>
#include <stdlib.h>
#include <arpa/inet.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
#include <fcntl.h>
void handle_get(int fd, char path[]){
char buf[1024];
int n;
int filefd;
if((filefd=open(path+1, O_RDONLY))==-1){
write(fd, "HTTP/1.0 404 Not Found\r\n\r\n", 26);
return;
}
write(fd, "HTTP/1.0 200 OK\r\n\r\n", 19);
while((n=read(filefd, buf, sizeof(buf)))>0){
write(fd, buf, n);
}
close(filefd);
}
main(int ac, char *av[]){
int tcp_socket;
struct sockaddr_in addr;
int fd;
char buf[1024];
int n;
char cmd[512];
char path[512];
tcp_socket = socket(AF_INET, SOCK_STREAM, 0);
addr.sin_family = AF_INET;
addr.sin_port = htons(atoi(av[1]));
addr.sin_addr.s_addr = INADDR_ANY;
if(bind(tcp_socket, (const struct sockaddr *)&addr, sizeof(struct sockaddr_in))==-1){
perror("cannot bind");
exit(1);
}
listen(tcp_socket, 1);
while(1){
fd=accept(tcp_socket, NULL, NULL);
n=read(fd, buf, sizeof(buf));
sscanf(buf, "%s%s", cmd, path);
if(strcmp(cmd, "GET")==0){
handle_get(fd, path);
}
close(fd);
}
}
当然,这个Web服务器的主目录是它所在的目录,因此,我们要确保当前目录有html文件——可以把刚才/var/www/html/下的文件复制过来。编译运行,绑定在8080端口。运行结果如下,即使是有图片的网页也完全没问题。
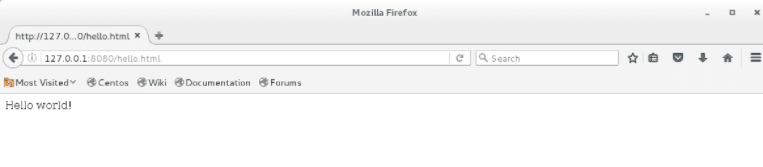
当然,这个服务器还有大量问题。其中最大的问题,如果一个客户端的速度很慢(传输一个文件需要很久),或者是恶意地不响应(比如客户端发送一字节数据——不是换行符后进入休眠)——这就是DOS(Denial of Service)攻击。它就无法响应其他客户端的请求了。我们可以认为制造这种情况。
我们用telnet连接至我们编写的Web服务器,但是不发送请求。
我们发现我们的服务器没有响应了。
直到我们终止telnet。
这时才能正常响应。
因此,我们需要解决某个客户端太慢的问题——解决方案很多,多进程是最简单的解决方案。
多进程的Web服务器
我们想要编写多进程的Web服务器,动机有两个。第一,就是上文所说的为了改善某个客户太慢或恶意无响应这种情况——当然DOS很难解决,尤其是DDOS(分布式的拒绝攻击)。第二,多进程能充分利用硬件资源,提升Web服务器处理并发请求的能力。如果回到我们之前说的,TCP服务器就是接线员。一般来说,一个接线员某一时刻只能服务一个TCP客户端。如果我们想同时服务更多的客户,则多雇佣一些接线员就可以了。
版本1
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
#include <fcntl.h>
#include <signal.h>
void handle_get(int fd, char path[]){
char buf[1024];
int n;
int filefd;
if((filefd=open(path+1, O_RDONLY))==-1){
write(fd, "HTTP/1.0 404 Not Found\r\n\r\n", 26);
return;
}
write(fd, "HTTP/1.0 200 OK\r\n\r\n", 19);
while((n=read(filefd, buf, sizeof(buf)))>0){
write(fd, buf, n);
}
close(filefd);
}
main(int ac, char *av[]){
int tcp_socket;
struct sockaddr_in addr;
int fd;
char buf[1024];
int n;
char cmd[512];
char path[512];
int rv_fork;
signal(SIGCHLD, SIG_IGN);
tcp_socket = socket(AF_INET, SOCK_STREAM, 0);
addr.sin_family = AF_INET;
addr.sin_port = htons(atoi(av[1]));
addr.sin_addr.s_addr = INADDR_ANY;
if(bind(tcp_socket, (const struct sockaddr *)&addr, sizeof(struct sockaddr_in))==-1){
perror("cannot bind");
exit(1);
}
listen(tcp_socket, 1);
while(1){
fd=accept(tcp_socket, NULL, NULL);
n=read(fd, buf, sizeof(buf));
sscanf(buf, "%s%s", cmd, path);
if(strcmp(cmd, "GET")==0){
rv_fork=fork();
if(0==rv_fork){
handle_get(fd, path);
close(fd);
exit(0);
}else{
close(fd);
}
}
}
}
这个版本的Web Server,当客户端希望请求一个文件时,主进程才fork出一个进程去处理文件传输,自己则close socket连接,以便继续accept下一次的客户端连接请求。注意,在这里尽管父进程close了socket连接,但是却不会影响子进程与客户端的连接。这是因为在Linux中每个文件(包括socket)都有一个引用计数:fork之后,计数增加一,close一次,计数减一,直到引用计数为0才会清理和释放资源(真正同客户端断开)。这里对文件描述符的理解如有问题亦可再参考一下文件重定向和管道一章。
另外,本程序也用signal(SIGCHLD, SIG_IGN)处理了僵尸进程的问题。
当然,如果我们仍使用上面用过的“攻击”方法,这个服务器还是无法提供服务了。
版本2
只要对上面的程序略微修改一下,就可以避免上面那种“攻击”了。
#include <sys/socket.h>
#include <netinet/in.h>
#include <netinet/ip.h>
#include <stdlib.h>
#include <arpa/inet.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
#include <fcntl.h>
#include <signal.h>
void handle_get(int fd, char path[]){
char buf[1024];
int n;
int filefd;
if((filefd=open(path+1, O_RDONLY))==-1){
write(fd, "HTTP/1.0 404 Not Found\r\n\r\n", 26);
return;
}
write(fd, "HTTP/1.0 200 OK\r\n\r\n", 19);
while((n=read(filefd, buf, sizeof(buf)))>0){
write(fd, buf, n);
}
close(filefd);
}
main(int ac, char *av[]){
int tcp_socket;
struct sockaddr_in addr;
int fd;
char buf[1024];
int n;
char cmd[512];
char path[512];
int rv_fork;
signal(SIGCHLD, SIG_IGN);
tcp_socket = socket(AF_INET, SOCK_STREAM, 0);
addr.sin_family = AF_INET;
addr.sin_port = htons(atoi(av[1]));
addr.sin_addr.s_addr = INADDR_ANY;
if(bind(tcp_socket, (const struct sockaddr *)&addr, sizeof(struct sockaddr_in))==-1){
perror("cannot bind");
exit(1);
}
listen(tcp_socket, 1);
while(1){
fd=accept(tcp_socket, NULL, NULL);
rv_fork=fork();
if(0==rv_fork){
n=read(fd, buf, sizeof(buf));
sscanf(buf, "%s%s", cmd, path);
if(strcmp(cmd, "GET")==0){
handle_get(fd, path);
close(fd);
exit(0);
}
}else{
close(fd);
}
}
}
prefork
上面的多进程Web服务器都是等客户请求到达时,才fork出子进程处理用户请求,处理完又销毁了这个子进程(子进程自己退出)。进程的创建和销毁都是耗时的。其实我们可以有另一个思路,就是预先fork一堆进程,让这些进程同时去试图accept客户端的请求,结果是谁accept上谁处理,其他进程接着等待下一次的请求。
这种方式就是prefork。这种方式能减少频繁创建和销毁进程的开销。每个子进程在一个时间点内,只能处理一个请求。该方法成熟稳定,不需要担心线程安全问题,而且Linux的进程是轻量级的进程,父进程和子进程通过COW(copy on write)共享大部分资源。但是相对I/O复用(如epoll)来说进程还是更占用资源,因此prefork不擅长极其高并发的场景。
prefork也是Apache三种的工作模式的第一种。
版本3:prefork的Web服务器
#include <sys/socket.h>
#include <netinet/in.h>
#include <netinet/ip.h>
#include <stdlib.h>
#include <arpa/inet.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
#include <fcntl.h>
#include <signal.h>
void handle_get(int fd, char path[]){
char buf[1024];
int n;
int filefd;
if((filefd=open(path+1, O_RDONLY))==-1){
write(fd, "HTTP/1.0 404 Not Found\r\n\r\n", 26);
return;
}
write(fd, "HTTP/1.0 200 OK\r\n\r\n", 19);
while((n=read(filefd, buf, sizeof(buf)))>0){
write(fd, buf, n);
}
close(filefd);
}
main(int ac, char *av[]){
int tcp_socket;
struct sockaddr_in addr;
int fd;
char buf[1024];
int n;
char cmd[512];
char path[512];
int rv_fork;
int i;
signal(SIGCHLD, SIG_IGN);
tcp_socket = socket(AF_INET, SOCK_STREAM, 0);
addr.sin_family = AF_INET;
addr.sin_port = htons(atoi(av[1]));
addr.sin_addr.s_addr = INADDR_ANY;
if(bind(tcp_socket, (const struct sockaddr *)&addr, sizeof(struct sockaddr_in))==-1){
perror("cannot bind");
exit(1);
}
listen(tcp_socket, 1);
/*prefork serveral child*/
for(i=0;i<32;i++){
rv_fork=fork();
if(0==rv_fork)
break;
}
while(1){
fd=accept(tcp_socket, NULL, NULL);
n=read(fd, buf, sizeof(buf));
sscanf(buf, "%s%s", cmd, path);
printf("%d accept: %s %s\n", getpid(), cmd, path);
if(strcmp(cmd, "GET")==0){
handle_get(fd, path);
}
close(fd);
}
}
很显然,这种方式也不会收到刚才那种“攻击”的影响。
进程不宜“活得”太久
死亡对于自然界中的生命是必要且有意义的,这一点对进程也是一样。
首先,进程在堆中分配的空间(比如C中用malloc申请的空间,或C++中创建的对象),使用后如果忘了释放(C要用free,C++的对象要析构),就会使得这部分内存无法回收利用。而服务器一般都是长时间运行的死循环,这样系统中可用内存就会越来越少,相漏掉了一样,我们称之为内存泄漏(Memory Leak)。程序员试图避免内存泄漏,也有很多工具用来检测内存泄漏,但真的在实际中很难避免——这也是为什么诸如Java中的垃圾回收机制保证了菜鸟写的程序也是可用的。其实,有一个方法可以很好的避免内存泄漏——就是让进程的寿命不要太长,当一个进程服务一定次数或时间后,它就要退出。当一个进程退出后,它的内存全部的内存都得以释放。
其次,尽管父进程和子进程是COW(copy on write),但子进程创建后,随着时间越来越久,父子进程就会越来越不一样,那样它们共享的内存就越来越少,占据的总内存就会越来越大。最好的方法是子进程按时(或按提供服务次数)退出,重新fork一个子进程,这样共享的部分是最多的。
Apache的基本配置之一,就是设置一个进程的寿命。当进程响应了指定次数后,令其退出,重新fork一个新进程。Apache如果采用prefork,需要根据内存的大小(而且要考虑COW:进程会共享大量内存),设定prefork进程的数量。
free,C++的对象要析构),就会使得这部分内存无法回收利用。而服务器一般都是长时间运行的死循环,这样系统中可用内存就会越来越少,相漏掉了一样,我们称之为内存泄漏(Memory Leak)。程序员试图避免内存泄漏,也有很多工具用来检测内存泄漏,但真的在实际中很难避免——这也是为什么诸如Java中的垃圾回收机制保证了菜鸟写的程序也是可用的。其实,有一个方法可以很好的避免内存泄漏——就是让进程的寿命不要太长,当一个进程服务一定次数或时间后,它就要退出。当一个进程退出后,它的内存全部的内存都得以释放。
其次,尽管父进程和子进程是COW(copy on write),但子进程创建后,随着时间越来越久,父子进程就会越来越不一样,那样它们共享的内存就越来越少,占据的总内存就会越来越大。最好的方法是子进程按时(或按提供服务次数)退出,重新fork一个子进程,这样共享的部分是最多的。
Apache的基本配置之一,就是设置一个进程的寿命。当进程响应了指定次数后,令其退出,重新fork一个新进程。Apache如果采用prefork,需要根据内存的大小(而且要考虑COW:进程会共享大量内存),设定prefork进程的数量。

















 1261
1261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









