



近年来,生成式人工智能(AIGC)热潮席卷全球,从文生文、图生图到代码生成、智能对话,AI大模型成为技术革新的核心引擎。然而,随着国内外模型数量爆炸式增长,选型难题也摆在了开发者、创作者、企业面前:到底该选哪个模型?不同模型之间的差异又体现在哪些方面?本文将从实际应用出发,探讨“大模型选型”这一关键问题,并介绍一种高效的模型对比方式,帮助你做出更理性选择。
一、模型数量激增,选型困惑加剧
从OpenAI的GPT-4到Anthropic的Claude,再到国内的文心一言、通义千问、月之暗等,各家厂商的AI大模型层出不穷。单从命名上就已让人眼花缭乱,更遑论版本、参数规模、调用方式、训练方法等专业维度。尤其对初次接触AI模型的用户而言,“怎么选”已成一道门槛。
二、常见对比维度有哪些?别掉进误区
在进行AI模型选择时,以下几个核心维度往往是必须考虑的:

很多用户容易陷入“只看模型火不火”或“别人说好就选它”的误区,忽视了自身使用场景和具体需求的匹配度。
三、一站式对比工具:如何用AIbase模型广场提升选型效率?
面对纷繁复杂的模型信息,一个高效、系统的对比平台就显得尤为重要。[AIbase模型广场](https://model.aibase.com/zh/compare) 提供了一个涵盖中英文主流大模型的选型平台,聚合模型的核心参数、调用方式、价格、更新频率、训练方法、能力标签等信息,支持多模型横向对比,极大降低了“信息搜索成本”。
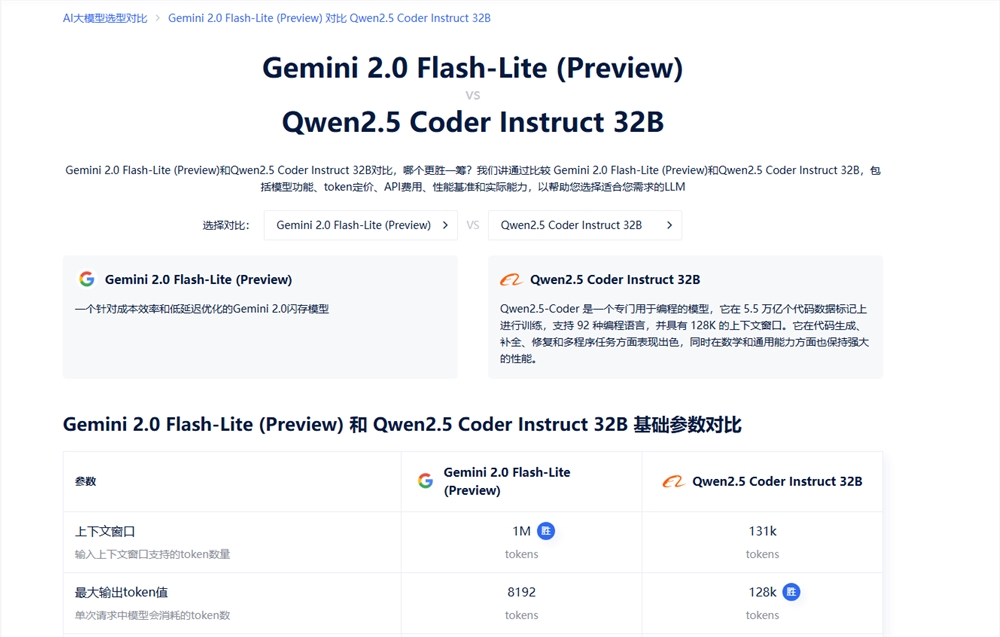
✅ 你可以在平台上完成这些操作:
- 按模型能力(如代码能力、多模态能力)筛选候选模型;
- 比较最多5个模型的详细参数与差异;
- 获取模型是否适合“写作”、“问答”、“图像生成”等不同场景;
- 快速跳转至模型官网或调用接口。
这让原本需要查阅多篇文档、多轮测试的工作,在几分钟内完成初步决策。
四、举个例子:如何选一个适合中文写作的模型?
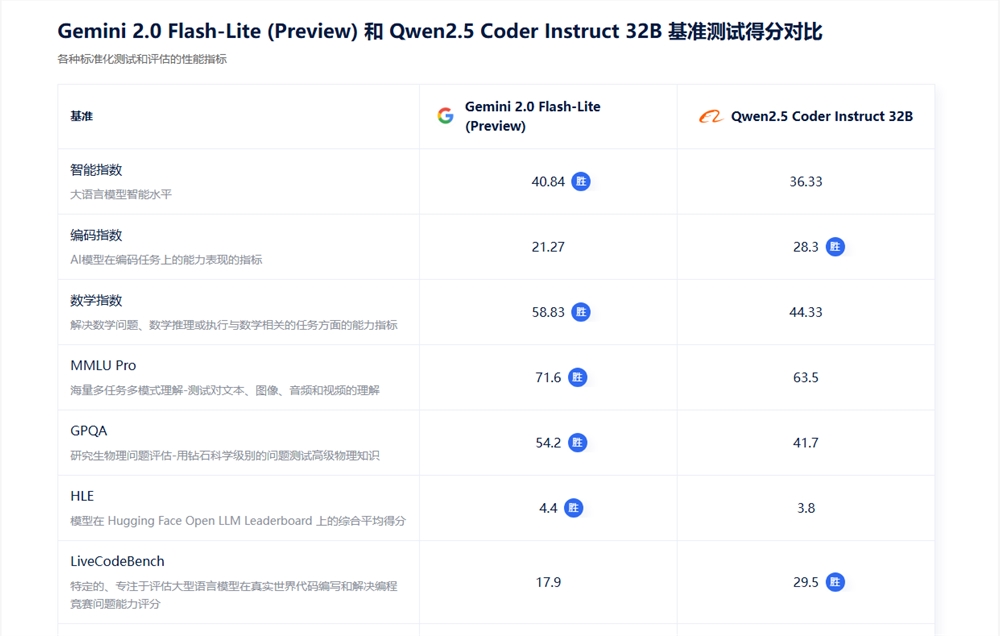
假设你是一位内容创作者,主要需求是生成高质量的中文长文,对模型的语言能力、生成连贯度和响应速度有较高要求。那么在AIbase模型广场的对比过程中,你可能会筛选出以下模型进行对比:

在经过上述对比后,结合你的成本预算和是否需要多模态支持,可以更清晰地定位适合自己的模型。
五、总结:模型选择不是越强越好,而是合适最重要
每个大模型都有其技术侧重点和设计目的,没有绝对最优,只有相对更适合。合理选型需要从自身需求出发,结合**AI大模型对比**维度,理解模型差异,避免走弯路。
如你正面临“大模型选哪个”的难题,不妨借助像 AIbase 模型广场这样的平台,在纷繁信息中建立理性的认知体系,让AI真正服务于你的目标。
> - [AIbase 模型对比入口](https://model.aibase.com/zh/compare)

















 901
901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









