









实例描述
假设肿瘤医院想要用神经网络对已有的病例数据进行分类,数据的样本特征包括病人的年龄和肿瘤的大小,对应的标签应该是良性肿瘤还是恶性肿瘤
1.生成样本集
利用python生成一个二维数组“病人的年纪,肿瘤的大小”样本集,下面代码中generate为生成样本的函数,意思是按照指定的均值和方差生成固定数量的样本。
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
def generate(sample_size, mean, cov, diff, regresssion):
samples_per_class = int(sample_size/2)
X0 = np.random.multivariate_normal(mean, cov, samples_per_class)
Y0 = np.zeros(samples_per_class)
for ci, d in enumerate(diff):
X1 = np.random.multivariate_normal(mean+d, cov, samples_per_class)
Y1 = (ci+1)*np.ones(samples_per_class)
X0 = np.concatenate((X0,X1))
Y0 = np.concatenate((Y0,Y1))
return X0, Y0
np.random.seed(10)
num_classes = 2
mean = np.random.randn(num_classes)
cov = np.eye(num_classes)
X, Y = generate(1000, mean, cov, [3.0], True)
# print(X)
colors = ['r' if l == 0 else 'b' for l in Y[:]]
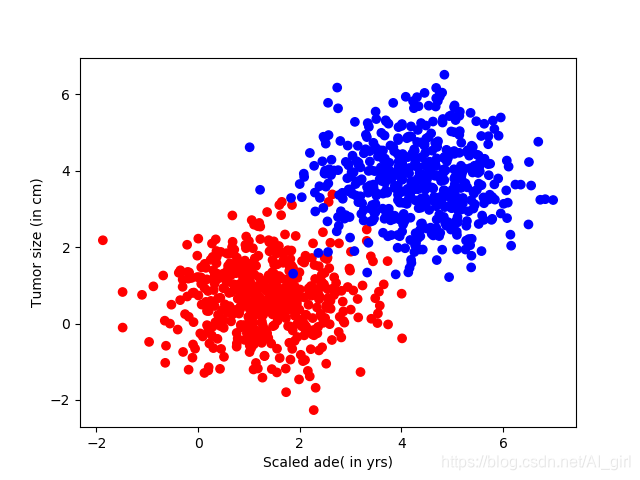
plt.scatter(X[:, 0], X[: ,1], c = colors)
plt.xlabel("Scaled ade( in yrs)")
plt.ylabel("Tumor size (in cm)")
plt.show()
运行以上代码,得到如下结果:
2.构建网络结构
开始构建网络模型。
--I激活函数使用的是Sigomoid。
--损失函数使用的是loss交交叉熵,里面又加了一个平方差函数用来评估模型的错误率。
--优化器使用AdamOpimizer。
lab_dim = 1
input_dim = 2
input_features = tf.placeholder(tf.float32,[None, input_dim])
input_lables = tf.placeholder(tf.float32,[None, lab_dim])
#定义学习
W = tf.Variable(tf.random_normal([input_dim, lab_dim]), name = "weight")
b = tf.Variable(tf.zeros([lab_dim]), name = "bias")
output =tf.nn.sigmoid(tf.matmul(input_features, W) + b)
cross_entropy = -(input_lables * tf.log(output) + (1 - input_lables) * tf.log(1 - output))
ser = tf.square(input_lables - output)
loss = tf.reduce_mean(cross_entropy)
err = tf.reduce_mean(ser)
optimizer = tf.train.AdamOptimizer(0.04)
#尽量用这个,因其收敛快,会动态调节梯度
train = optimizer.minimize(loss)
3.设置参数进行训练
令整个数据迭代50次,每次的minibatchsize取25条。
maxEpochs = 50
minibatchSize = 25
#启动session
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
#向模型输入数据
for epoch in range(maxEpochs):
sumerr = 0
for i in range(np.int32(len(Y)/minibatchSize)):
x1 = X[i*minibatchSize:(i+1)*minibatchSize,:]
y1 = np.reshape(Y[i*minibatchSize:(i+1)*minibatchSize],[-1, 1])
tf.reshape(y1,[-1, 1])
_,lossval, outputval, errval = sess.run([train, loss, output, err], feed_dict={input_features:x1, input_lables:y1})
sumerr = sumerr+errval
print("Epoch:", '%04d' %(epoch+1), "cost=","{:.9f}".format(lossval), "err=",sumerr/minibatchSize)
每一次计算都会见err错误值累加起来,数据集迭代完一次会将err的错误率进行一次平均,平均值再输出来。运行以上代码,生成一下信息:
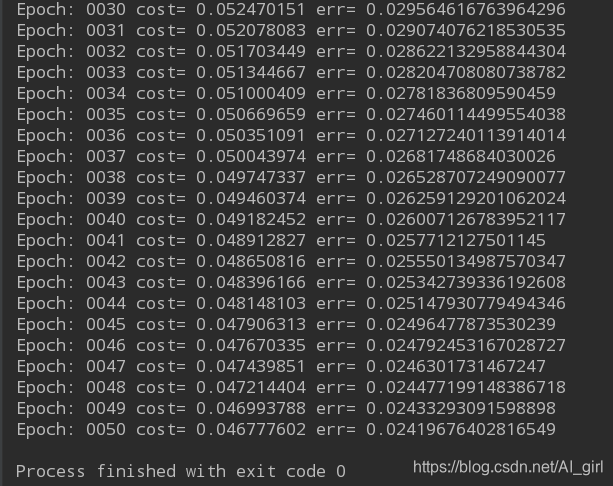
经过50次迭代,得到了错误率为0.024的模型。
4.数据可视化
下面可以直观的将模型结果和样本以可视化的方式显示出来,前一部分是先去100个测试点,在图上显示出来,接着将模型以一条直线 的方式显示出来。
train_X, train_Y = generate(100, mean, cov, [3.0], True)
colors = ['r' if l==0 else 'b' for l in train_Y[:]]
plt.scatter(train_X[:,0], train_X[:, 1], c=colors)
x = np.linspace(-1,8,200)
y = -x*(sess.run(W)[0]/sess.run(W)[1])-sess.run(b)/sess.run(W)[1]
plt.plot(x, y, label = 'Fitted line')
plt.legend()
plt.show()
运行代码,会生成如下结果: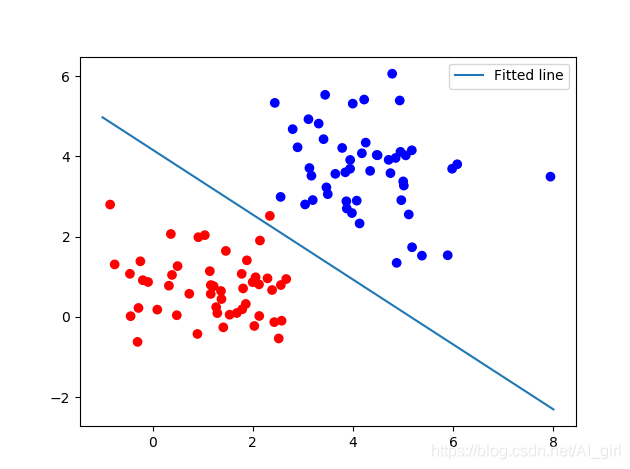


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









