







一、文章概况
文章题目:
《Tips and Tricks for Visual Question Answering:Learnings from the 2017 Challenge》
文章下载地址:
https://openaccess.thecvf.com/content_cvpr_2018/papers/Teney_Tips_and_Tricks_CVPR_2018_paper.pdf
二、文献导读
摘要部分
Deep Learning has had a transformative impact on Computer Vision, but for all of the success there is also a significant cost. This is that the models and procedures used are so complex and intertwined that it is often impossible to distinguish the impact of the individual design and engineering choices each model embodies. This ambiguity diverts progress in the field, and leads to a situation where developing a state-of-the-art model is as much an art as a science. As a step towards addressing this problem we present a massive exploration of the effects of the myriad architectural and hyperparameter choices that must be made in generating a state-of-the-art model. The model is of particular interest because it won the 2017 Visual Question Answering Challenge. We provide a detailed analysis of the impact of each choice on model performance, in the hope that it will inform others in developing models, but also that it might set a precedent that will accelerate scientific progress in the field.
深度学习对计算机视觉产生了变革型的影像,但模型和程序的复杂性对于所取得的成功也产生了巨大的成本,对于开发一门先进的模型既是一门科学,也是一门艺术,本文通过大量的探索提出了一些改善模型的技巧和方法,如模型的结构超和参数的选择本文,赢得了2017年视觉问答挑战赛。
三、文章详细介绍
1.Introduction
视觉问答(VQA)的任务涉及图片和相关的文本问题,计算机必须根据相关的问题做出正确的回答。本文为VQA提出了一个相对简单的模型实现最先进的结果。它是基于联合嵌入的神经网络实现的。所提出的模型基于输入问题和图像的联合嵌入原理,随后是对一组候选答案的多标签分类器。

文章中最关键的地方,总结如下:
– Using a sigmoid output that allows multiple correct answers per question, instead of a common single-label softmax.(使用sigmoid代替softmax,这样可以保证每个问题都有多个正确的答案输出)
– Using soft scores as ground truth targets that cast the task as a regression of scores for candidate answers, instead of a traditional classification.(ground truth用软得分,将任务转化为候选答案分数的回归,而不是传统的分类)
– Using gated tanh activations in all non-linear layers.(用gated tanh激活函数)
– Using image features from bottom-up attention that provide region-specific features, instead of traditional grid-like feature maps from a CNN.(bottom-up attention用自下而上注意力图像特征)
– Using pretrained representations of candidate answers to initialize the weights of the output layer.(候选答案的预训练表达)
– Using large mini-batches and smart shuffling of training data during stochastic gradient descent(大的mini-batches和智能打乱)
2. Background
QVA的普遍方法由三部分组成
(1)将问答作为分类问题,问答是对一组候选答案的分类,正确答案集中在一小组单词和短语中。
(2)实现联合嵌入的深度神经网络来解决,大多数VQA模型都是通过深度神经网络实现问题和图像的联合嵌入的,这两个输入分别用卷积和递归神经网络映射成固定大小的向量表示。这些表示形式的进一步非线性映射通常被解释为联合“语义”的空间投影,然后可以在输入上述分类器之前,可以通过逐元素乘法的连接来组合它们。
(3)在示例问题/答案的监督下进行端到端训练,由于深度学习在监督问题上的成功应用,整个神经网络从问题、图像及其基本真实答案进行端到端训练。
VQA的最新研究中,大多数都是基于基本的联合嵌入的方法,研究表明,如果仔细实施或者严格挑选超参数,非常简单的模型也可以获得很好的性能。本文中大量实验表明,一些关键的选择(如门控激活,回归输出,智能打乱等)能够明显提高简单模型的性能。
3. Proposed Model
本章介绍了基于深度神经网络的建议模型,选择了特定的超参数和数值使模型效果达到最佳。
完整的模型总结图如下:
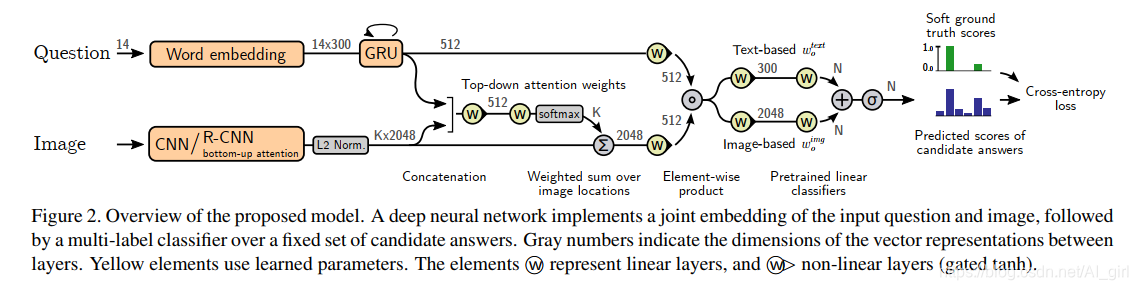
3.1文本特征提取
无论是在训练期还是测试期,输入的实例都是一个文本问题和图像。输入的问题会被标记,首先使用空格和标点符号将输入的问题拆为单词(问题中出现的数字也被归为单词),为了提高其效率,每个问题至多有14的单词,多余的单词会被丢弃。数据集中大约只有0.25%的问题超过14个单词。每个单词转化成一个带有查找表的向量表示,查找表的条目是在训练期间沿着其他参数学习的300维向量。少于14个单词的用零向量填充结束,得到的单词嵌入序列的大小为14×300,然后通过循环神经网络RGU,使其成为512维的递归单元内部状态。实验发现,运行相同次数的循环单元效果更好。
3.2图像特征提取
输入的图像经过卷积神经网络(CNN),得到大小为K×2048维的向量表示,其中K为图像中位置的向量,即每一个位置由2048个向量表示,该向量对该区域中的图像外观进行编码。
对比试验,从两种主要的选择对网络的影响,一个性能较低,一个性能较好。性能较低的是构建了一个200层的ResNet,在Image net上进行预处理,将14×14大小的特征图,平均池化成7×7大小,K取49。第二个性能较高的是采用自上而下注意力提取特征图,该方法是基于Faster R-CNN框架内的ResNet CNN。实验评估了固定K=36或自适应K,自适应K对图像中检测到的元素使用了固定阈值,从而允许区域K的值随每个图像的复杂度而变化,最大为100。VQA v2数据集中使用的图像平均大约为K=60.
3.3图像注意力
Our model implements a classical question-guided attention mechanism common to most modern VQA models . We refer to this stage as the top-down attention, as opposed to the model of that provides image features from bottom-up attention.
该模型实现了大多数VQA模型所共有的经典问题引导注意力机制,将此阶段称为自上而下注意力,与自下而上注意力提供特征图像的模型相反。
对于图像中的每个位置 i=1,2,......k,特征向量Vi和问题嵌入q连接,它们都通过非线性层和线性层,获取与注意力相关的权重标量。用softmax函数对所有位置的注意力权重进行归一化处理,然后对所有位置的图像特征进行归一化加权并求和,将图表示成一个大小为2048的向量表示。
3.4多模态融合
问题q和图像的表示经过非线性层,然后进行简单的Hadamard乘积(即逐元素乘法)相结合,得到的向量称为问题和图像的联合嵌入,然后送到输出分类器进行分类。
3.5输出分类器
输出词汇是从训练集中出现8次以上所有正确答案中预先选定的,相当于N=3129个答案。将VQA视为多标签分类任务。得到的多标签分类器将联合嵌入h通过非线性层fo,然后经过线性映射wo来预测N个候选者的得分sˆ
![]()
其中σ是sigmoid激活函数,wo是初始化学习权重矩阵,sigmoid将最后的分数归一化为(0.1),尽管使用的是目标软的分,但其后的损失类似于是二元交叉熵。最后这个阶段可以看作是逻辑回归,可以预测每个答案的正确性。主要方程为:
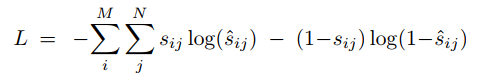
其中索引i和j分别为M个训练问题和N个候选答案,实验证明上述方程比其他VQA模型中常用的softmax分类器有效得多。该方程有两个优点,首先,sigmoid函数允许对每个问题的正确答案进行优化;其次,使用软分数作为目标比提供了二进制目标更为有效的训练信号。
3.6预处理分类器
候选答案j的分数实际上是由联合图像问题表示形式fo(h)和第j行的wo的点积确定。当答案无法与预训练的嵌入匹配时,通过检查、删除连字符或保留多单词表达式中的单个术语后使用最接近的匹配,相应的向量放在矩阵中。
3.7非线性层
非线性层的实现方式一个常见的仿射变换,后跟一个ReLU函数,在实际中,每个非线性层使用门控双曲正切激活。
3.8训练
使用随机梯度下降来训练网络,选择AdaDelta算法,该算法不需要固定的学习率,并且对参数的初始化非常不敏感,但该模型容易过拟合。
4. Ablative Experiments
每个网络重复训练三次,用不同的随机种子训练同一网络。
4.1训练数据
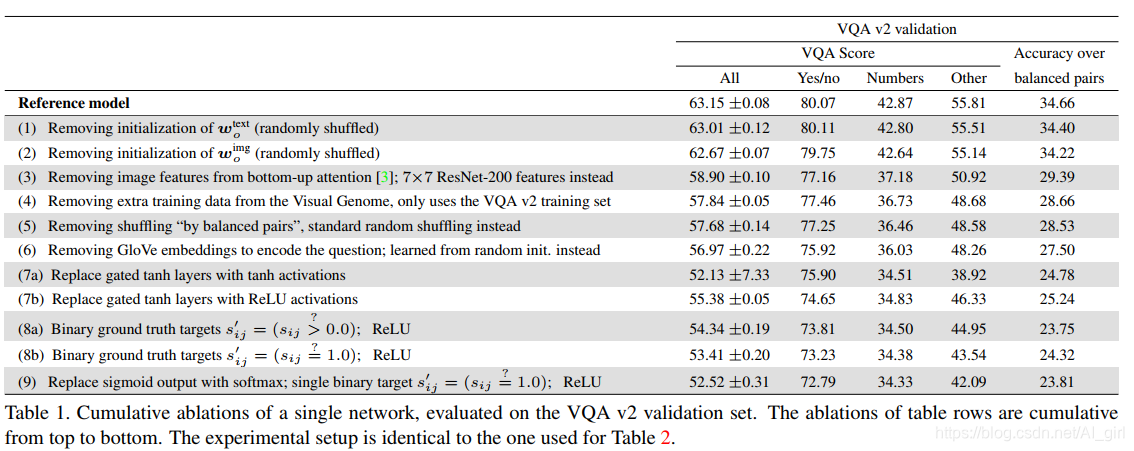
通过提出的改组可以提高成对的准确性
4.2问题嵌入
4.3图像特征
最佳模型使用了自下而上的图像特征,这些是通过一个Faster RCNN框架和专注于特定图像区域的101层ResNet获得的。该方法在物体检测上使用固定的阈值,因此特征的数量K适应于图像的内容,K的上限为100,并且得出的平均值约为K = 60。 我们尝试使用固定数字的特征K = 36, 性能稍微下降了。考虑到较低的实现和计算成本,该选项可能是一个合理的选择。
建议的模型最初是使用标准ResNet功能开发的,并未针对功能进行专门优化。 相反,我们发现最佳选择对于各种图像特征都是稳定的。在所有情况下,我们还观察到图像特征的L2归一化对于获得良好性能至关重要,至少对于我们选择的体系结构和优化器而言。
5.Discussion and Conclusions


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









