




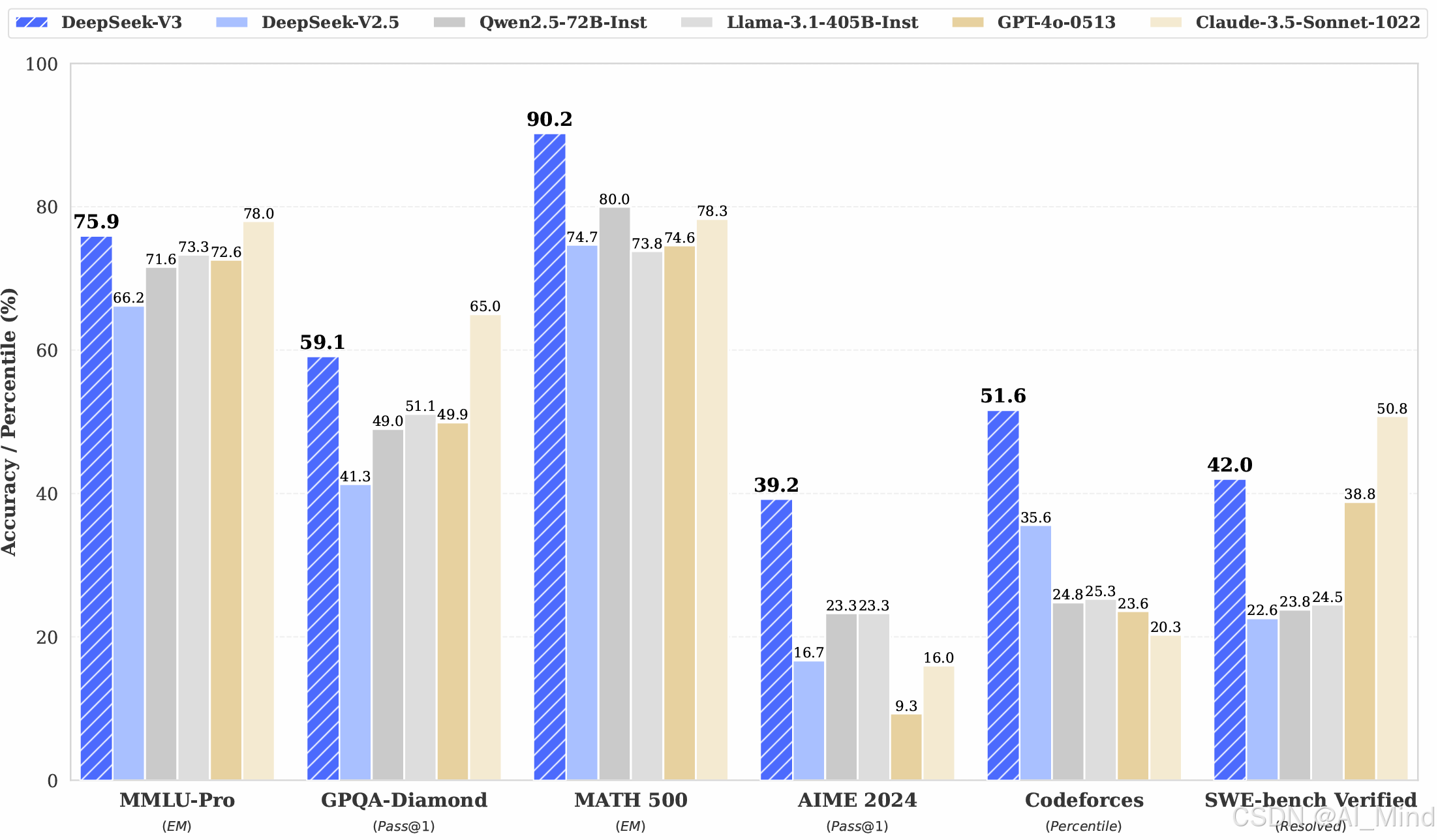
2024年12月DeepSeek发布了全新的模型DeepSeek-V3,并且已经上线和开源。DeepSeek-V3是一款强大的混合专家模型(MoE),总参数量为6710亿,其中每个token激活37亿参数。DeepSeek-V3在多项指标上超越了Qwen2.5-72B 和 Llama-3.1-405B 等开源模型,并且性能比肩 GPT-4o 和 Claude-3.5-Sonnet等模型。
1. 架构
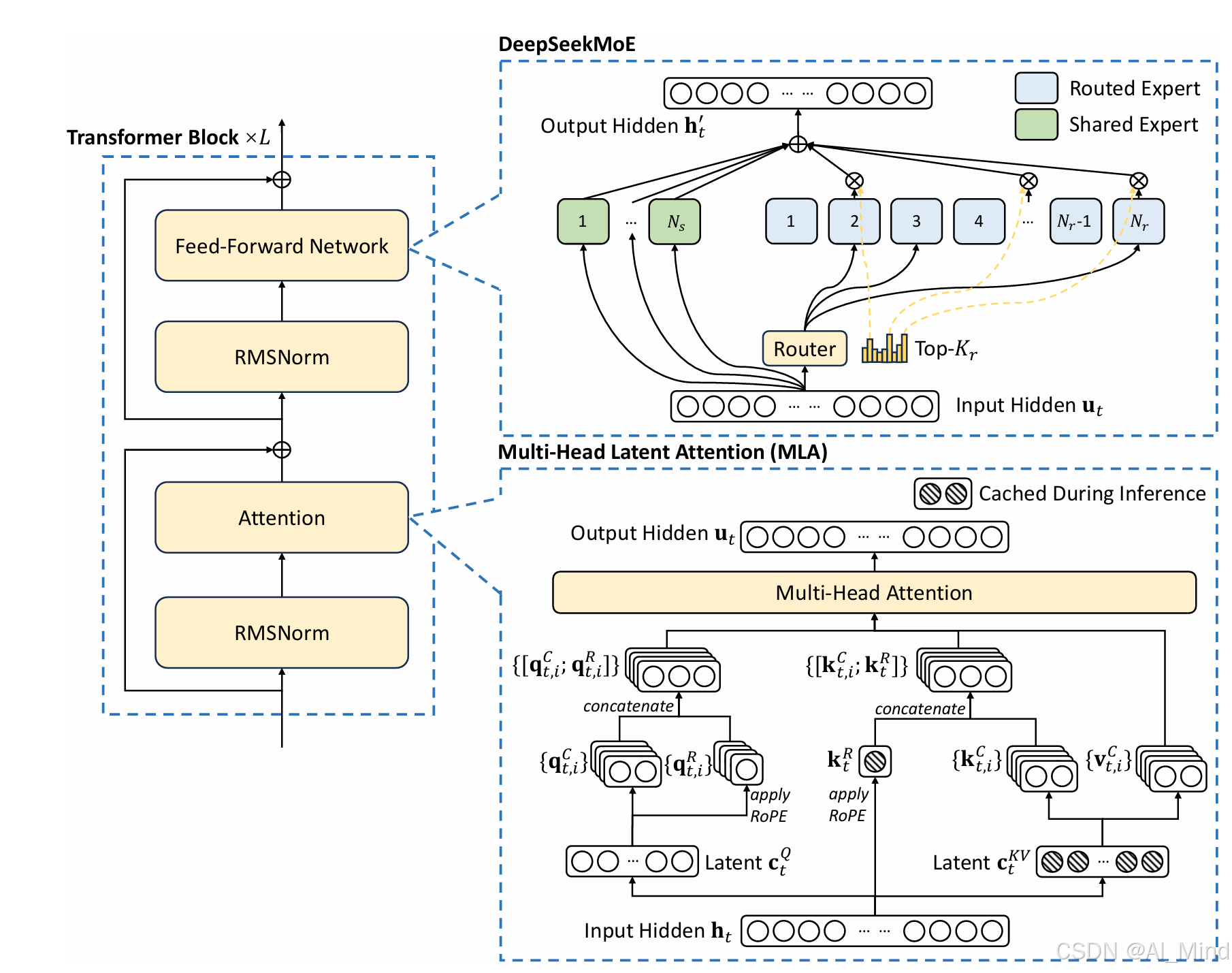
DeepSeek-V3 的基本架构仍然基于 Transformer 框架,采用了多头潜在注意力(MLA )和 DeepSeekMoE 架构。MLA 通过低秩联合压缩注意力键和值,减少了推理过程中的键值缓存,从而提高了推理效率。DeepSeekMoE 则通过细粒度的专家和共享专家的隔离,实现了经济高效的训练。在 DeepSeek-V2 高效架构的基础上,DeepSeek-V3 还引入了无辅助损失的负载平衡策略,并通过动态调整专家偏置项,确保训练过程中的负载平衡,从而避免了传统辅助损失对模型性能的负面影响。 DeepSeek-V3 研究了一种多标记预测(MTP)目标,并证明其对模型性能有益。该目标还可以用于推测解码,从而加速推理过程。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3684
3684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









