



在深入了解AI编译器之前,我们首先需要了解编译器的基本概念。编译器是一种软件,它将高级编程语言(如Python、C++等)编写的源代码转换成低级语言(如机器码)的目标代码。这个过程通常包括几个阶段,如词法分析、语法分析、语义分析、中间代码生成、优化和代码生成等,而我们习惯把这几个阶段分为前端和后端,如下图所示:
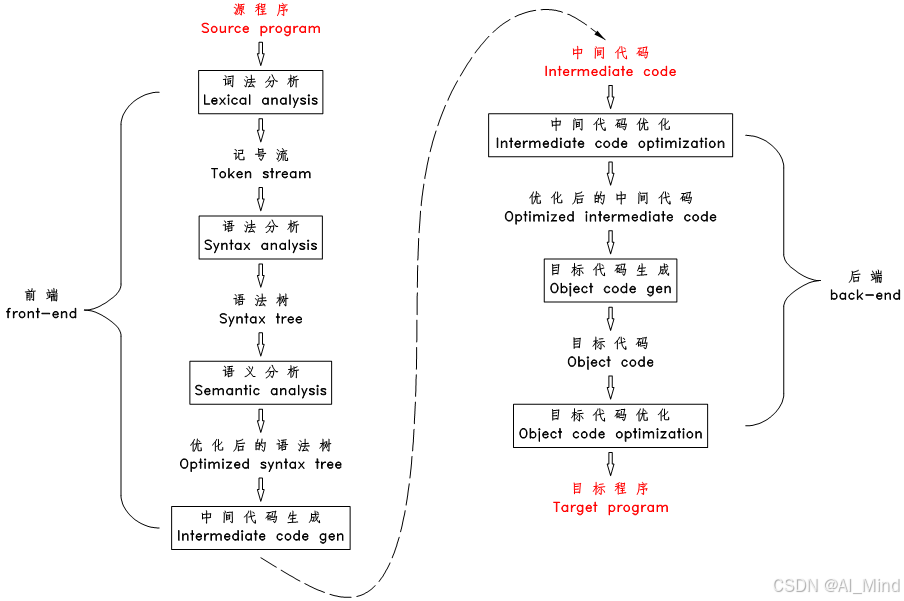
在上图中我们可以看到 “中间代码”这个东西,通常我们也叫“中间表示(Intermediate Representation)”,即 IR。在一些主流的传统编译器(LLVM)中,LLVM前端将高级语言转化为IR,后端将IR转换成目标硬件上的机器指令,IR作为桥梁在前后端之间进行基于IR的各种优化。这样无论是新增硬件的支持,还是新增前端的支持,都可以尽可能地复用IR相关的部分。IR可以是单层的,也可以是多层的, LLVM IR是典型的单层IR,其前后端优化都基于相同的LLVM IR进行。
AI编译器就是基于这种思想,采用了多层级IR的设计,比如下图展示了基于TensorFlow的多层IR表示:

第一层是图IR,也就是基于TensorFlow编写的代码生成的图表示,然后通过第二层的一些加速优化类型的IR,如XLA(Accelerated Linear Algebra)等,再转化为第三层基于硬件层面的IR,如LLVM IR,TPU IR等,最后根据相应的IR转化到对应的硬件上面运行。
为什么要设计成多层IR的表示呢? 主要的原因是因为目前主流的一些框架和加速器厂商非常多,比如在机器学习框架上就有PyTorch、TensorFlow、MindSpore等等,加速器除了英伟达的GPU还有Google自己的TPU,华为的昇腾芯片、海光的DCU等等。这导致各家厂商都会对自己的芯片进行专项优化,而在这个过程中,有许多IR是重复优化的,为了减少这种冗余的开发,多层IR的产生是很有必要的。虽然多层IR在表达上更加灵活,并且在不同的层级上可以进行不同的PASS优化,但其也存在一些劣势,首先就是IR转换之间的问题 ,不同的IR之间想要做到完全兼容是非常困难的,不仅工作量非常大,而且还可能带来一定的信息损失;还有不同的IR在顺序上也存在着依赖,这导致优化起来有更强的约束。在解决这个问题上,出现了MLIR这个东西,由于不是本篇幅重点,不予介绍。想要了解的话可以阅读MLIR的官方文档,网址如下(MLIR)。
说了这么多可能还是没明白什么是AI编译器,我们看下AI编译器的架构图:
根据上图,不管前面的多层IR设计,我们直接考虑AI编译器究竟做了些什么东西。首先呢,就是根据机器学习框架编写的代码,转换为计算图,然后计算图输入到编译器前端,在前端经过静态分析,自动微分,中间表示的前端优化(比如类型推导,表达式简化等),其中这中间表示优化的过程有可能会反复多次,然后前端优化后的代码输入到编译器后端,后端对传入的计算图进行一些硬件相关的优化(比如硬件指令优化,数据排布优化等),然后通过算子的选择,最后再进行内存分配,然后通过硬件的驱动层,最后传入到不同的硬件设备上面运行。
以上就是AI编译器干的事情了,由于篇幅限制,具体详细的部分就不展开了,有机会可以详细展开说说AI编译器的前后端运行的具体细节是如何的。

















 1812
1812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









