







 本文介绍了概率论在机器学习中的基础概念,包括概率、联合概率、条件概率、贝叶斯定理,以及连续概率分布和正态分布。概率用于度量事件发生的可能性,贝叶斯定理在信息获取后更新概率的计算,而正态分布是自然界中常见的一种分布,常用于数据建模。在机器学习中,这些概念用于理解和处理随机变量,例如在分类任务中使用逻辑回归进行预测。
本文介绍了概率论在机器学习中的基础概念,包括概率、联合概率、条件概率、贝叶斯定理,以及连续概率分布和正态分布。概率用于度量事件发生的可能性,贝叶斯定理在信息获取后更新概率的计算,而正态分布是自然界中常见的一种分布,常用于数据建模。在机器学习中,这些概念用于理解和处理随机变量,例如在分类任务中使用逻辑回归进行预测。
(由于平台稿件格式问题,公式格式不能正确写上;如若读写困难可後台私信我要完整电子版)
5.1 概率入门
概率是一门古老的学科,如果溯源,一般认为其来源于赌博,但是随后其发展出了一套体系理论并拓展到科学和工程的方方面面。特别是在机器学习领域中,概率和统计学可以说奠定了一整套理论基础。概率和统计学本身涉及的知识面非常之广,本书仅围绕机器学习方面的知识展开讨论。
概率是用来度量事情发生的可能性的,通常用 P 表示。概率是续型变量,值域一般定义为 [0,1]。如果一个事情必然发生,那么该事件被称为必然事件。例如,“太阳从东方升起”就是必然事件,我们把它记为 y1,那么对应的概率为 P(y1)=1。如果一个事件绝对不可能发生,那么该事件被称为不可能事件。例如,事件“太阳从西方升起”就是不可能事件,我们把它记为 y2,那么对应的概率为 P(y2)=0。一个事件的发生与否,如果具有一定的不确定性,那么该事件被称为随机事件,对应的概率介于0和1。例如,我们把“明天下雨”记为 y3,如果对应的概率为 P(y3)=0.9,就表示明天下雨的可能性较大,但不代表一定会下雨。
假设我们扔一枚硬币,y=1 表示结果为正面,y=0 表示结果为反面。如果硬币是均质的,那么 P(y=1)=0.5,P(y=0)=0.5,即表示一次投掷两种结果的占比。
概率是怎么算出来的呢?概率和频率的关系也比较密切,除了理论上的推导,最直接的方法就是统计已发生事情的频率。例如,一共投掷硬币100次,其中正面朝上51,反面朝上49次,我们使用频率作为概率的估计,即
P(y=1)=51/100
P(y=0)=49/100
使用频率估计概率是一个相对粗糙但有效的方法,其实就是对已有经验进行总结,前提是实验次数一定要足够多,这样估计的结果才准确。这其实也是机器学习中训练数据要足够大的原因——原则上多多益善。举个反例,如果只投1次硬币,那么必然出现一个面朝上的概率为1,另一个面朝上的概率为0的情况,而这显然是不准确的。
再举个例子。我们掷骰子,投掷结果 y 就是一个典型的随机事件,并且结果是多中选一的。骰子的每一面出现的概率都相等,即
P(y=1)=P(y=2)=P(y=3)=P(y=4)=P(y=5)=P(y=6)
且结果必然是6个面中间的一个,因此,所有面出现的概率相加必然为1,即
P(y=1)+P(y=2)+P(y=3)+P(y=4)+P(y=5)+P(y=6)=1
因此,很容易得到
P(y=1)=P(y=2)=P(y=3)=P(y=4)=P(y=5)=P(y=6)=1/6
需要注意的是,y=1,⋯,6 只表示状态,代表结果 y 为点数,骰子各个面并无大小之分。
通过上面的分析可以知道,虽然不同的随机事件具有不同的特点和使用场景,但是它们有一定的共性,具体如下。
值域固定,即 P(y)∈[0,1]。
有限可加性。如果 n 个事件 y1,y2,y3,⋯,yn 中的任意两个都互斥,即不可能同时发生(例如,每次掷骰子时6个面只会有一个朝上),那么 P(y1∪⋯∪yn)=P(y1)+⋯+P(yn)。y1∪⋯∪yn 表示事件 y1~yn 中至少有一个发生。
概率之和为1。如果对于事件 y,穷举它所可能发生的事件 y1,y2,y3,⋯,yn,并且任意两个事件都不可能同时发生,那么有 P(y1)+⋯+P(yn)=1。
事件的包含性。例如,事件A为掷骰子结果为偶数,事件B为掷骰子结果为2,那么只要事件B发生,事件A就一定发生。对这种情况,我们称事件A包含事件B,此时有 P(事件B)<P(事件A)。
对于任意两个事件 A 和 B,P(A∪B)=P(A)+P(B)-P(A∩B),A∪B 表示 A 和 B 至少发生一个,A∩B 表示 A 和 B 同时发生。例如,A 表示掷骰子结果为偶数,对应的投掷结果为 {2,4,6},P(A)=1/2,B 表示掷骰子结果大于(不包括)3,对应的投掷结果为 {4,5,6},P(B)=1/2,那么 A∪B 表示投掷结果为 {2,4,5,6} 中的任意一个,因此,P(A∪B)=4/6。A∩B 表示投掷结果同时满足两个事件,即 {4,6},因此 P(A∩B)=2/6。我们可以发现,P(A) 和 P(B) 都考虑了结果 {4,6},直接计算 P(A)+P(B) 会重复计算 {4,6} 一次,因此,还需减去重复的部分 P(A∩B)。验算一下,易得
P(A∪B)=4/6
P(A)+P(B)-P(A∩B)=3/6+3/6-2/6=4/6
特别的,当 A∩B=∅,即 A 和 B 为互斥事件,不可能同时发生时,P(A∩B)=0,可以得到
P(A∪B)=P(A)+P(B)
此为有限可加性。
5.2 联合概率和条件概率
我们生活在这个世界上,每天都会发生形形色色的事件,这些事件往往不是孤立存在的,它们之间往往具有联系和相关性,它们之间的发生和结果往往互相影响。
小明是个小学生,每天有下面两组随机事件发生在他身上。
y1={█(1,妈妈批评小明@ 0,妈妈没有批评小明)┤
y2={█( 1,小明考试不及格@ 0,小明考试及格) ┤
我们统计小明最近100天的表现情况,如表5-1所示。表5-1
| y2=1 | y2=0 | |
| y1=1 | 27 | 13 |
| y1=0 | 3 | 57 |
表5-1
可以发现,在这100天中,小明一共有27+13=40天被妈妈批评,剩下60天没有被妈妈批评。我们用频率来估计概率,可以得到
P(y1=1)=40/100=0.4
同理,P(y2=1)=0.3,P(y2=0)=0.7。
上面的概率都是对单个事件进行描述。有时候,我们需要对两个事件的组合概率进行描述。例如,小明考试不及格(y2=1)且没有被妈妈批评(y1=0)的概率,根据统计可得
P(y1=0,y2=1)=3/100
假设小明考试不及格,即 y2=1 已经发生,我们想知道小明会被妈妈批评的概率,又该如何计算呢?用 P(y1|y2) 表示 y2 发生后 y1 会发生的概率,称为条件概率。例如,在 N 天中,小明一共有 n 次考试不及格,考试不及格时被妈妈批评了 m 次,可以通过统计计算条件概率,即
P(y1=1│y2=1)=m/n=(m/N)/(n/N)=(P(y1=1,y2=1))/(P(y2=1))
上式反映了条件概率和联合概率之间的联系。更一般的写法为
P(y1│y2)=(P(y1,y2))/(P(y2))
根据表5-1,我们可以得到
P(y1=1,y2=1)=27/100
P(y2=1)=30/100
因此
P(y1=1│y2=1)=(P(y1=1,y2=1))/(P(y2=1))=(27/100)/(30/100)=0.9
同理,如果小明考试及格,那么他被妈妈批评的概率为
P(y1=1│y2=0)=(P(y1=1,y2=0))/(P(y2=0))=(13/100)/(70/100)=0.19
如果我们不知道考试结果,那么小明被妈妈批评的概率为 P(y1=1)=0.4。可以发现,如果小明考试不及格,即 y2=1,那么他被妈妈批评的概率将显著提升至 0.9。如果小明考试考试及格,即 y2=0,那么他被妈妈批评的概率就会下降至 0.19。因此,考试结果 y2 给我们提供了额外的信息,提升了判断的准确性。在机器学习中,也把条件概率中的条件称为知识。
我们也可以把单个概率写成条件概率之和的形式。例如,y2 只有两种取值情况 y2=0 和 y2=1,那么有
P(y1=1)=P(y2=0)P(y1=1│y2=0)+P(y2=1)P(y1=1│y2=1)
即各个条件概率加权求和,权重为 P(y2=0) 和 P(y2=1)。写得更通用些:
P(y1)=∑_(y2∈Y2)▒〖P(y2)P(y1│y2) 〗
Y2 为 y2 所有可能取值的集合。
特别的,如果 y1 和 y2 相互独立,即这两个随机变量风马牛不相及,那么满足
P(y1,y2)=P(x1)P(x2)
例如,我们投掷两个独立的骰子,第一个骰子为3点、第二个骰子为5点的概率是多少呢?显然,两个独立事件同时发生的概率为两个事件单独发生的概率相乘,即
P(y1=3,y2=5)=P(y1=3)P(y2=5)=1/6×1/6=1/36
再如,y1 和 y2 分别表示一个人的身高和体重,那么
P(y1=175cm,y2=60kg)≠P(y1=175cm)P(y2=60kg)
这是因为一个人的身高和体重具有很强的相关性,当知道一个人的身高后,体重也八九不离十,此时 y1 和 y2 称作不独立。
显然,在上述小明的例子中,妈妈批评小明和小明考试不及格之间存在相互影响,因此 P(y1,y2)≠P(y1)P(y2)。
如果从一个分布中独立抽取 n 个样本,那么这 n 个样本是相互独立的,即
P(y1,y2,⋯,yn)=P(y1)P(y2)⋯P(yn)
例如,随机扔硬币 n 次,虽然扔的是同一个硬币,但是前后结果互相不影响,所以这 n 个结果相互独立。再如,从一个班的学生中“有回放”地随机抽取 n 个人,他们的身高就是随机变量,并且相互独立。所谓“有回放”就是指抽取第一个人后,将他放回班级,下次抽取的时候仍然有同样概率抽取到他。
如果做无回放抽取,即抽取完第一个人后,不把他再放回班级,第二次抽取的时候班级的人数就会由 N 人变成 N-1 人,第二次抽取的概率分布被第一次抽取的结果影响,发生了变化,因此,两次抽取出来的身高就不再是独立的,即
P(y1,y2)≠P(y1)P(y2)
如果要求每次抽取的人性别和上一次不相同,那么前后两次抽取出来的身高也不再是独立事件。
当两个随机变量 y1 和 y2 相互独立时,条件概率有如下结论。
P(y1│y2)=(P(y1,y2))/(P(y2))=(P(y1)P(y2))/(P(y2))=P(y1)
y2 对 y1 发生的概率不会造成任何影响,即 y2 无法为 y1 提供知识。这也相当于投掷两枚独立硬币,第一枚硬币的投掷结果不会对第二枚硬币的投掷结果造成任何影响。
5.3 贝叶斯定理
隔壁邻居听到小明被妈妈批评(y1=1 已经发生),心想小明是不是考试又不及格了(y1=1 已经发生,y2 的概率),那么此时邻居需要计算的条件概率就是
P(y2=1│y1=1)
根据5.2节的公式,我们可以进行如下推导。
P(y2│y1)=(P(y1,y2))/(P(y1))=(P(y1,y2)P(y2))/(P(y1)P(y2))=P(y2)(P(y1│y2))/(P(y1))
上述公式称作贝叶斯定理,它贯穿了机器学习。贝叶斯定理有时也写成如下形式。
P(y2│y1)=(P(y2)P(y1│y2))/(∑_(y2∈Y2)▒〖P(y2)P(y1│y2) 〗)
使用贝叶斯定理,我们可以得到
P(y2=1│y1=1)=P(y2=1) (P(y1=1│y2=1))/P(y1=1) =0.3×0.9/0.4=0.675
我们如何理解贝叶斯定理 P(y2│y1)=P(y2)(P(y1│y2))/(P(y1)) 呢?
我们需要计算的 P(y2│y1) 被称作后验概率,即 y1 发生后 y2 的概率。y1 被称作知识,P(y2) 被称作先验概率,表示在没有任何知识的帮助下 y2 发生的概率。P(y1│y2) 被称作似然函数,它其实表示了 y2 对 y1 的影响。P(y1) 被称作证据因子,如果 y1 本身是低概率事件,那么 y1 一旦发生,对 y2 的影响就会非常大,反之亦然。
在机器学习中,其实就是使用模型判断特征 x 对应的类别 y,即让模型拟合
P(y│x)
机器学习中,通常使用高维特征,因此 x 也被称为特征向量。机器学习的训练就是指利用训练数据 〖{x_((i)),y_((i))}〗_(i=1)^N,使用模型来直接估计 P(y│x)。这种机器学习的方法称为“判别模型”。另一种机器学习方法,模型学习的是 P(x,y),这种方法称为“生成模型”。判别模型和生成模型是机器学习的主要两个流派,考虑到落地难度和最终效果,判别模型的使用相对较多,生成模型也有适用的地方。下面通过一个例子说明二者的异同。
例如,x=175 为人的身高,y=0 表示女性,y=1 表示男性。已知身高,我们想根据身高预测性别,判别模型和生成模型分别是如何计算的?
判别模型可以得到此人为男性的概率 P(y=1|x=175)=0.9,那么,此人为女性的概率就是 P(y=0|x=175)=1-P(y=1|x=175)=0.1。因为 P(y=1│x=175)>P(y=0|x=175),所以模型结论是此人为男性。
在生成模型中,首先计算 P(y=1,x=175)=0.01,表示男性且身高为175cm的人占总人口比例的1%,接着计算 P(y=0,x=175)=0.001,表示女性且身高175cm的人占总人口的比例为0.1%。因为 P(y=1,x=175)>P(y=0,x=175),所以模型判断此人为男性。这里需要注意的是,P(y=1,x=175)+P(y=0,x=175)≠1,原因在于还有很多其他的身高和性别组合并没有被考虑进去,这正是判别模型和生成模型的差别。
判别模型和生成模型各有何优缺点呢?
使用模型估计 P(x,y) 比估计 P(y│x) 更加复杂,模型需要更多的参数及训练样本,因此,常见的模型,例如逻辑回归、神经网络,本质都是判别模型。但是,我们可以通过生成模型生成(采样)一系列符合真实情况的数据,例如男性180cm、女性160cm等,而判别模型只能根据身高来判断性别,缺乏生成数据的能力。
另外,例如 x=300 表示一个人的身高为300cm,这其实是个异常数据,该人为男性或者女性的概率都会很低。如果使用判别模型,因为有 P(y=1|x=300)+P(y=0|x=300)=1 的约束,所以 P(y=1|x=300) 或 P(y=0|x=300) 至少有一个不会太小,不存在二者都趋近于0的情况(这与真实情况矛盾),而判别模型必须二选一,因此会给出错误的结论。但在使用生成模型时,P(y=0,x=175)=10^(-9) 和 P(y=1,x=175)=〖2×10〗^(-9) 是可以存在的,符合真实情况。当在两类概率都超低的情况下,生成模型可以给出数据异常的结论。
5.4 连续概率分布
我们在扔骰子时,最终的结果 X 是一个离散变量,也就是说,X 是可以进行穷举的。例如,掷一个六面骰子,有 P(X=1)=1/6,P(X=2)=1/6 等。但是,在很多情况下,X 是不可穷举的,例如人的身高就是不可穷举的随机变量,无法数完所有情况,这类随机变量称作连续型随机变量。
因为 X 的状态是不可穷举的,所以 P(X) 是无法枚举的,我们需要换一种方式来定义概率。我们用一个非负可积的函数 f(x) 表示 X 的概率密度,它和概率成正比(类似于密度和重量之间的关系),f(x) 称作概率分布密度函数,简称概率密度。f(x) 表示在随机变量 X 在 x 附近的可能性,“可能性”不会为负值,因此 f(x)≥0。另外,因为 X 在 (-∞,+∞) 上所有的可能性相加必为1,所以可得
∫_(-∞)^(+∞)▒f(x)dx=1
例如,男性身高就是一个典型的正态分布,对应的概率密度函数为 f(x)=1/(15√2π) exp(-(x-160)^2/450)。
使用概率分布计算概率时,计算的是区间的概率,而不是某一个点的概率。这就好比我们称重量,一定要有体积的支撑才谈得上重量。例如,水这种物质只有密度,并不存在重量,我们所说的水重量,都是有一桶、一甁这种体积概念作为支撑的。再如,我们要判断一个人身高在区间 (170,175] 的概率,可以把170~175上的所有可能性相加,即
P(170<X≤175)=∫_170^175▒f(x)dx=∫_(-∞)^175▒f(x)dx-∫_(-∞)^170▒f(x)dx=F(175)-F(170)
这里我们把 F(a) 称作累计分布函数,F(a) 即表示 P(x<a)。
概率密度函数 f(x) 有一点“反常理”,在这里详细讲解一下,以便读者深入理解。
首先介绍一下均匀分布。均匀分布也叫矩形分布,是一个常见的连续概率分布,它在相同长度间隔的分布概率是相等的,定义如下。
f(x)={█(1/(b-a),a<x<b@0,其他 )┤
均匀分布通常缩写为 U(a,b),a 和 b 是均匀分布的两个参数。如果 b-a<1,那么 f(x)=1/(b-a)>1。因此,概率密度和概率不能混为一谈,概率不能大于1,而概率密度可以大于1。
另一个“反常理”的现象是,在连续概率分布中,任意一点 x0 发生的概率 P(x=x0) 为
P(x=x0)=∫_x0^x0▒f(x)dx=0
但是,从概率密度 f(x) 上采样,每次采样的结果必然是定义域中的某一个点。因此,可以说明一个事情发生的概率即使为0也未必是不可能事件。
同理,可以得到 P(x≠x0)=1-P(x=x0)=1-0=1,但事件 x=x0 完全有可能发生,即 x≠x0 没有发生。因此,概率为1的事件不一定是必然事件。
多个连续型随机变量也可以组成联合分布。例如,连续型随机变量 X 和 Y 组成的联合分布为 f(x,y),f(x,y)=1/√2π exp(-1/2 x^2-1/2 y^2) 且满足
∫_(-∞)^(+∞)▒∫_(-∞)^(+∞)▒f(x,y)dxdy=1
我们也可以从联合概率分布 f(x,y) 中得到单变量 x 对应的概率密度 f(x),其实就是把另一个变量 y 所有可能性对应的概率密度求和,这叫作边缘分布。例如,边缘分布 f(x) 为
f(x)=∫_(-∞)^(+∞)▒f(x,y)dy
即将 y 的取值都考虑在内。
同理,有
f(y)=∫_(-∞)^(+∞)▒f(x,y)dx
下面我们讨论连续型随机变量的一些性质。这些性质基本和离散型概率类似,只是大部分都是以概率密度替代概率。连续型随机变量 X 和 Y 之间的条件概率有如下关系。
f(x|y)=(f(x,y))/(f(y))
类似的,单变量概率也可以通过条件概率来进行表示,即
f(x)=∫_(-∞)^(+∞)▒〖f(y)f(x|y)dy〗
如果连续型随机变量 X 和 Y 相互独立,那么它们之间的概率密度满足
f(x,y)=f(x)f(y)
连续概率分布之间可以组成联合概率分布,连续概率分布和离散分布也可以组成联合概率分布。这些组合对应的贝叶斯定理如表5-2所示。

表5-2
可以发现,对于连续型随机变量,统一都用概率密度代替概率。
5.5 均值和方差
如果你是一个家长,在给孩子挑选学校时,可能会看重学校的平均考试成绩,它代表了学校的整体教学水平。如果这个数据没有公开,你有什么办法去了解呢?你可以站在校门口,随机挑选 N 个走出校门的学生,询问他们的考试成绩。
假设被询问的学生的考试分数分别为 x_1~x_N,那么平均分就是
X ̅=1/N ∑_(i=1)^N▒x_i
平均数也称为均值。
但是,均值 X ̅ 和我们的采样有关,如果我们刚好全部采样到低分同学,那么 X ̅ 就会整体偏小,反之亦然。因此,X ̅ 本身也是一个随机变量。
假设我们站在“上帝视角”,掌握了学校所有学生的考试分数,考试分数是 0~750 的整数。考试分数为离散随机变量 X,X 的取值就是 0~750 的整数,P(0),⋯,P(750) 为对应的概率,P(x) 表示一个学生分数为 x 的概率,也可以理解成分数为 x 的人数占学校学生数的比例。因为校长掌握了全部信息,并不存在随机抽取,所以校长计算出来的均值就是一个确定的值,我们称之为“期望”,记为 E(X)。
E(X)=∑_(score=0)^750▒〖score×P(x=score)〗
这里的期望 E(X) 是一个确定性的数,不再是随机变量。有时为了简便也用 μ 表示期望。
如果家长站在校门口的时间足够长,询问的学生人数足够多,那么他掌握的资料就很接近“真相”,因此 X ̅ 就越接近 E(X)。
但是,仅仅知道均值有时候不能完全反映真实的情况。例如,一个学校的学生考试分数有可能差距极大,也可能差距不大,在这两种情况下,它们的期望(均值)也有可能相等。因此,期望(均值)也不一定能完全反映一个群体的真实情况。
如果学生的考试分数都远离均值,那么该校学生考试分数的差异较大;如果学生的考试分数都接近均值,那么该校学生考试分数的差异较小。作为家长,随机问询 N 个学生的成绩,使用“样本标准差”s 度量一个学校学生的整体差异
s=√(1/(N-1) ∑_(i=1)^N▒(x_i-X ̅ )^2 )
因为 s 和随机询问的 x_i 有关,所以 s 也是一个随机变量。这里需要注意,分母是 N-1 而不是 N,这主要是为了消除采样时的系统性偏差。
但是,校长掌握所有学生的情况,因此他得到的标准差记为
σ=√(∑_(score=0)^750▒〖P(x=score)〖(score-E(X))〗^2 〗)
一般来说,σ^2 叫作方差,记为 D(X)。标准差和方差是一个确定性事件。
同一个统计量有对应样本和总体两个版本,如表5-3所示。

表5-3
上面都是在随机变量 X 为离散分布时进行分析的。但如果随机变量 X 是连续型随机变量,概率密度为 f(x),计算方式又该如何呢?
如果在采样样本上计算均值和标准差,虽然 X 为连续型随机变量,但是采样后都是一个个具体的数值,因此,仍然使用上述方法计算均值和样本标准差。对于期望和标准差的计算方法如下。
E(X)=∫_(-∞)^(-∞)▒〖xf(x)〗 dx
D(X)=∫_(-∞)^(-∞)▒〖〖(x-E(X))〗^2 f(x)〗 dx
其实很简单,就是把 ∑ 替换成了 ∫,把概率 P 替换成了概率密度函数 f(x)。
期望有一些常见的数学性质,列举如下。
E(C)=C,即常数的期望仍然为它本身。
E(aX)=aE(X),a 为常数。
E(aX+bY)=aE(X)+bE(Y)。
若 X 和 Y 相互独立,则 E(XY)=E(X)E(Y)。
方差的一些常见数学性质,列举如下。
D(X)≥0,若 C 是常数,则 D(C)=0。
D(aX)=a^2 D(X)。
D(aX+bY)=a^2 D(X)+b^2 D(Y)+2abE{(X-E(X))E(Y-E(Y))}。
如果 X 和 Y 相互独立,则 D(aX+bY)=a^2 D(X)+b^2 D(Y)。
D(X+b)=D(X),其中 b 是常数。
D(X)=E(X^2)-E^2 (X)。
期望和方差的这些数学性质都可以从定义中推导出来,这里不再赘述。
均值 X ̅ 本身也是随机变量,它对应的均值和方差又是多少呢?如果 X 对应的期望为 μ,方差为 σ^2,x_1,⋯,x_N 都是独立采样的,它们之间相互独立,那么均值 X ̅ 对应的期望和方差分别为
E(X ̅ )=E(1/N ∑_(i=1)^N▒x_i )=1/N E(∑_(i=1)^N▒x_i )=1/N ∑_(i=1)^N▒〖〖E(x〗_i)=1/N ∑_(i=1)^N▒〖μ=μ〗〗
可以发现,X ̅ 是 μ 的无偏估计,即估计量在统计学上没有偏差。
另外,因为 x_i 之间相互独立,所以 D(∑_(i=1)^N▒x_i )=∑_(i=1)^N▒〖〖D(x〗_i)〗。利用这个性质,可以推出
D(X ̅ )=D(1/N ∑_(i=1)^N▒x_i )=1/N^2 D(∑_(i=1)^N▒x_i )=1/N^2 ∑_(i=1)^N▒〖〖D(x〗_i)=1/N^2 ∑_(i=1)^N▒〖σ^2=σ^2/N〗〗
这说明:尽管 X ̅ 是 μ 的无偏估计,但是每次采样出来的 X ̅ 是在 μ 周围左右摇摆的,只是摇摆的中心为 μ 而已。D(X ̅ ) 表示摇摆力度,这就好比荡秋千,虽然中心不变,但是震荡幅度
是不同的。D(X ̅ )=σ^2/N 也说明,N 越大,D(X ̅ ) 越小,也就是每次采样出来的 X ̅ 偏离 μ 的幅度越小。
在神经网络的训练过程中,训练集一共有 M 个样本,w 为待更新的参数,每个样本对
应的梯度为 g_((i))=(∂Loss_((i)))/∂w。考虑所有训练样本,平均梯度为 ∂Loss/∂w=1/M ∑_(i=1)^M▒(∂Loss_((i)))/∂w=1/M ∑_(i=1)^M▒g_((i)) ,梯度下降法通过如下公式进行参数更新。
w=w-μ ∂Loss/∂w
但是,在实际工程中,M 往往非常大,计算 ∂Loss/∂w 非常耗时。因此,我们可以从 M 个训练样本中随机采样 N 个样本进行梯度计算,这称为SGD算法,公式如下。
g ̅=1/N ∑_(i=1)^N▒g_((i))
通过上面的结论,我们可以知道 g ̅ 为期望 ∂Loss/∂w 的无偏估计。但是,N 越小,g ̅ 在 ∂Loss/∂w 的摆动就越严重——时大时小,不利于训练。不过,g ̅ 适当摆动有利于在学习时逃离鞍点,如图5-1所示。
图5-1
当 w 落在鞍点的时候,∂Loss/∂w=0,w 将不再更新,学习结束。但是,使用SGD算法计算出 g ̅ 为 ∂Loss/∂w 的无偏估计,是一个随机值,因此会有轻微的变化,使 g ̅≠0,从而使 w 得到更新,进而逃离鞍点。
5.6 相关性
在真实世界中,随机变量之间有可能并不独立,它们之间往往相互影响。例如,从人群中随机抽一个人,那么它的身高就是随机变量 X,体重对应的就是随机变量 Y,尽管 X 和 Y 都是随机变量,但是他们之间却是有关系的。例如,知道一个人的身高是180cm,那么他的体重尽管是随机的,但也大概能有个范围,此时就称 X 和 Y 不独立。再如,明天北京的天气是随机变量 X,而我的考试成绩是随机变量 Y,北京的天气和我的考试成绩没有任何关系,因此,随机变量 X 和 Y 相互独立。但是,因为蝴蝶效应的存在,其实很难找出真正独立的事情,例如上海的天气可能会影响北京的天气,而北京的天气会进一步影响我的心情,从而影响我的考试成绩,所以,判断两个事件独立是非常难的。
在实际应用中,我们往往会降低要求,一般只判断两个事件是否线性相关,即两个事件的变化方向是否有规律可循。线性相关又分为两种情况。
正相关:两个变量朝同一方向变化。
负相关:两个变量朝相反方向变化。
如果两个事件的变化方向没有明显的关系,那么称为线性无关。例如,一个人的身高和他的考试成绩没有任何关联。
需要注意的是,线性相关的两个事件一定不独立,但独立的两个事件一定线性无关,即独立性比不相关更加严格。
如上所述,线性相关性是用来描述两个变量的变化方向是否一致的。对相关性进行如下定义。
Cov(X,Y)=E((X-E(X))(Y-E(Y)))
如果变量 X 比均值 E(X) 高(低),Y 也高(低)于均值 E(Y),那么此时认为 X 和 Y 正相关,即 X 和 Y 的变化方向相同。当 X 和 Y 同方向变化时,X-E(X) 和 Y-E(Y) 要么同为正,要么同为负,但相乘结果都为正,因此 Cov(X,Y)>0,表明 X 和 Y 正相关。当 X 和 Y 反方向变化时,那么 Cov(X,Y)<0。
如果 X 和 Y 毫无关系,那么此时 Cov(X,Y)=0,称 X 和 Y 线性无关。如果 X 和 Y 相互独立,根据均值的性质,可以知道
E(XY)=E(X)E(Y)
所以有
Cov(X,Y)=E((X-E(X))(Y-E(Y)))=E(XY-XE(Y)-YE(X)+E(X)E(Y))
=E(XY)-2E(X)E(Y)+E(X)E(Y)=0
即独立一定线性无关。但是,反过来不成立,不相关的两个事件,有可能并不独立,它们之间有更为隐蔽的联系,这也说明独立性比不相关要求更高。
上述是站在“上帝视角”定义的协方差。我们采集到一系列样本对 〖{X_i,Y_i}〗_(i=1)^N,例如一共有 N 个人,X_i 和 Y_i 分别是第 i 个人的身高和体重,协方差的计算方法如下。
Cov(X,Y)=(∑_(i=1)^N▒〖(X_i-X ̅)(Y_i-Y ̅)〗)/(N-1)
X ̅=1/N ∑_(i=1)^N▒X_i
Y ̅=1/N ∑_(i=1)^N▒Y_i
尽管 Cov(X,Y) 可以衡量 X 和 Y 的相关性,但是并没有进行归一化,这会带来数值上的困扰,不方便不同关系之间的比较。例如,同样是计算体重 X 和身高 Y 的相关性,我们把体重的单位从千克换成克,那么对应的 X-E(X) 在数值上被放大1000倍,Cov(X,Y) 也被放大1000倍。我们需要对 Cov(X,Y) 进行归一化,避免被量纲单位所影响,因此提出了相关系数的概念,具体如下。
ρ_XY=(Cov(X,Y))/(D(X)D(Y))
可以发现
ρ_XY∈[-1,1]
因为分母方差的存在,随机变量的量纲上下抵消,ρ_XY 不再受选取量纲的影响,更能反映客观的相关性,以及不同事件相关性的比较。
另外,相关性和我们之前讲解过的距离也有对应关系。例如,x 和 y 都是 n 维向量,即 x=[■(x_1@⋮@x_n )] 和 y=[■(y_1@⋮@y_n )]。为了方便计算,一般采取去中心化的技术对象进行处理,用 x ̅ 表示向量 x 各个维度的均值。去中心化就是
x^'=[■(x_1-x ̅@⋮@x_n-x ̅ )]
完成去中心化,x 各个维度的均值就为0。同理,可以得到 y^'=[■(y_1-y ̅@⋮@y_n-y ̅ )]。
如果我们把 x 和 y 中的每个元素都当成同一个事件,例如 x_i 和 y_i 表示两个人对第 i 部电影的喜爱程度,那么 x ̅ 和 y ̅ 就代表两个人对电影的总体偏好,有些人喜欢看电影,那么整体打分就偏高,反之亦然。接着,我们计算向量 x 和 y 的协方差,它表明两个人对电影品味的相关性,具体如下。
Cov(x,y)=(∑_(i=1)^n▒〖(x_i-x ̅)(y_i-y ̅)〗)/(n-1)=(〖(x^')〗^T y^')/(n-1)
同时,我们可以发现,向量 x 的标准差为
S_x=√((∑_(i=1)^n▒〖(x_i-x ̅)〗^2 )/(n-1))=‖x^' ‖/√(n-1)
同理
S_y=‖y^' ‖/√(n-1)
因此,我们可以得到向量 x 和 y 的相关系数:
ρ_xy=(Cov(x,y))/(S_x S_y )=(〖(x^')〗^T y^')/‖x^' ‖‖y^' ‖ =cosine(x^',y^')
综上所示,向量之间的相关系数就是向量去中心化后的余弦距离,用来表示向量之间的相关性。
5.7 正态分布
5.7.1 正态分布的基本概念和性质
正态分布,也叫高斯分布,它是一个连续型随机变量分布。正态分布不仅在机器学习中应用广泛,在各类工程领域、经济学中都有广泛应用。若随机变量 X 符合正态分布,那么它对应的均值和方差分别为 μ 和 σ^2。概率密度函数
f(x)=1/(√2π σ) exp(-(x-μ)^2/(2σ^2 ))
可以记做 X~N(μ,σ^2),不同的正态分布差异主要在于 μ 和 σ。
正态分布的概率密度函数的图像是一个倒钟型,如图5-2所示。
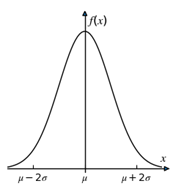
图5-2
特别的,当 μ=0 和 σ=1 时,我们称之为 N(0,1) 为标准正态分布。
正态分布以 μ 为对称轴左右对称,概率密度 f(x) 在 x=μ 时最大,并且 μ 为分布的均值、中位数、众数。σ 越大,数据越分散,图形铺得越开,如图5-3所示。
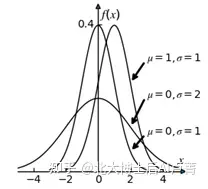
图5-3
在正态分布中有一个著名的sigma原则,具体如下,如图5-4所示。
sigma原则:数值分布在 (μ-σ,μ+σ) 中的概率为0.68。
2sigma原则:数值分布在 (μ-2σ,μ+2σ) 中的概率为0.95。
3sigma原则:数值分布在 (μ-3σ,μ+3σ) 中的概率为0.997。
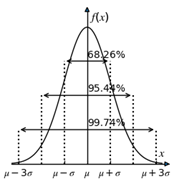
图5-4
通过这个原则,我们可以快速判断数据是否为低概率事件。在实际应用中,一般把区间 (μ-3σ,μ+3σ) 看作随机变量 X 实际可能的取值区间,这称为正态分布的 3σ 原则。如果 X 落在 (μ-3σ,μ+3σ) 以外的概率小于3‰(1-0.9974=0.0026),在实际应用中常认为相应的事件不会发生。
正态分布有一些非常好的数学性质,正是这些性质使得使用它来分析问题非常方便,具体如下。
性质1:如果 X~N(μ,σ^2),a 和 b 是实数,那么 aX+b~N(aμ+b,〖(aσ)〗^2)
这条性质告诉我们,如果随机变量 X 为正态分布,那么它的线性变换也是正态分布。使用这条性质,我们可以很容易地将任意的正态分布 X~N(μ,σ^2) 转换成标准正态分布 N(0,1),即 a=1/σ,b=-μ/σ。
在机器学习中,多维特征有不同的含义,它们在数值上差异非常大。如果特征都属于正态分布,仅是 μ 和 σ 不同,我们可以把各个维度的特征都转换成标准正态分布,从而归一化量纲。例如,有 N 个训练样本 〖{x_((i) ),y_((i) )}〗_(i=1)^N,特征 x_((i) )=〖[x_((i),1),x_((i),2)]〗^T,分别计算各个维度的均值和样本方差,公式如下。
μ_1=1/N ∑_(i=1)^N▒x_((i),1)
μ_2=1/N ∑_(i=1)^N▒x_((i),2)
σ_1=√(1/(N-1) ∑_(i=1)^N▒〖(x_((i),1)-μ_1)〗^2 )
σ_2=√(1/(N-1) ∑_(i=1)^N▒〖(x_((i),2)-μ_2)〗^2 )
对于特征,可以进行如下转换。
(x_((i),1)-μ_1)/σ_1 →x_((i),1)
(x_((i),2)-μ_2)/σ_2 →x_((i),2)
转换后,特征在各个维度的分布都符合标准正态分布 N(0,1),并且数值都在一个数量级。
在深度学习中,为了增强网络的稳定性和提高学习速度,经常采用批标准化(Batch Normalization,BN)的方法对数据进行正规化。
BN一般对激活函数之前的输入 d^((l)) 进行操作。例如,在使用SGD进行训练时,每次都选取 N 个样本计算梯度。神经网络某层(输入层和各个中间层)的输入为 n 维向量,记为 〖{x_((i))}〗_(i=1)^N,x_((i),j) 表示第 i 个样本的第 j 维。计算这批数据各个维度的均值和方差,方法如下。
μ_j=1/N ∑_(i=1)^N▒x_((i),j)
σ_j=√(1/N ∑_(i=1)^N▒〖(x_((i),j)-μ_j)〗^2 )
j=1,⋯,n
然后,将各个样本进行如下变换。
x ̅_((i),j)=γ_j (x_((i),j)-μ_j)/σ_j +β_j,i=1,⋯,N,j=1,⋯,n
这个变换可以分解为两步:第一步,计算 (x_((i),j)-μ_j)/σ_j ,作用是将数据分布规范化至标准正态分布 Ν(0,1);第二步,通过 γ_j 和 β_j 将标准正态分布调整至 Ν(β_j,γ_j^2),其中 γ_j 和 β_j 为待学习参数。
性质2:如果 X~N(μ_x,σ_x^2),Y~N(μ_y,σ_y^2),那么它们的“和”“差”都满足正态分布
公式如下。
X+Y~N(μ_x+μ_y,σ_x^2+σ_y^2)
X-Y~N(μ_x-μ_y,σ_x^2+σ_y^2)
这个性质非常有意思,它极大地扩展了正态分布的使用范围。例如,在线性回归中,有
y^'=w_0+w_1 x_1+⋯+w_n x_n
如果各个特征 x_i 都服从正态分布 N(μ_i,σ_i^2),那么预测结果 y^' 也符合正态分布。
正态分布是一个非常重要的分布,自然界常见的事物,例如人的身高、体重及学生的考试成绩等,都符合正态分布。正态分布为什么会很常见呢?原因在于中心极限定理:多个独立统计量的和的均值,符合正态分布。简单地说,如果一个事物受到多种因素的影响,那么,不管每个因素本身是什么分布,它们加总后,结果的均值就是正态分布。例如,男性身高受遗传因素、饮食因素、体育锻炼等多方面影响,这些因素本身都是随机变量,并且属于不同的分布,但是只要样本量足够,男性身高就会符合正态分布。
这也是我们在做机器学习任务的时候,无论是样本空间分布,还是噪声分布,都会使用正态分布建模的原因——正态分布最接近客观事实。
5.7.2 正态分布和逻辑回归
我们可以通过身高 x 和贝叶斯定理来预测性别 y,y=1 表示男性,y=0 表示女性,男性和女性的身高分布都满足正态分布。
男性的身高分布的概率密度为
f(x|y=1)=1/(√2π σ) e^(-〖(x-μ_1)〗^2/(2σ^2 ))
女性的身高分布的概率密度为
f(x|y=0)=1/(√2π σ) e^(-〖(x-μ_2)〗^2/(2σ^2 ))
其中,男性身高的均值为 μ_1,女性身高的均值为 μ_2,方差都为 σ。我们知道一个人的身高 x,想通过身高预测其性别,这就是一个典型的二分类问题——在判别模型中,其实就是比较 P(y=1│x) 和 P(y=0│x) 的大小。需要注意的是,P(y=1│x)+P(y=0│x)=1。
假设男性和女性的比例为 (P(y=1))/(P(y=0))=α,因为 P(y=1)+P(y=0)=1,所以 P(y=1)=α/(1+α) 和 P(y=0)=1/(1+α)。
根据贝叶斯公式,当一个人的身高为 x 时,其为男性的概率为
P(y=1│x)=(P(y=1)f(x|y=1))/(∑_(y∈Y)▒P(y) f(x|y))=α/(1+α) (f(x|y=1))/(∑_(y∈Y)▒P(y) f(x|y))
同理,当一个人的身高为 x 时,其为女性的概率为
P(y=0│x)=(P(y=0)f(x|y=0))/(∑_(y∈Y)▒P(y) f(x|y))=1/(1+α) (f(x|y=0))/(∑_(y∈Y)▒P(y) f(x|y))
将二者相除,有
(P(y=1│x))/(P(y=0│x) )=α (f(x|y=1))/(f(x|y=0))
根据身高的概率密度函数分布,可知
f(x|y=1)=1/(√2π σ) e^(-〖(x-μ_1)〗^2/(2σ^2 ))
f(x|y=0)=1/(√2π σ) e^(-〖(x-μ_2)〗^2/(2σ^2 ))
那么有
(P(y=1│x))/(P(y=0│x) )=αe^(-〖(x-μ_1 )^2-(x-μ_2 )〗^2/(2σ^2 ))=e^lnα e^(-((2μ_2-2μ_1 )x+(μ_1^2-μ_2^2 ))/(2σ^2 ))=e^(-((2μ_2-2μ_1 )x+(μ_1^2-μ_2^2 ))/(2σ^2 )+lnα)
结合 P(y=1│x)+P(y=0│x)=1,可以得出
P(y=1│x)=1/(1+e^(-(((2μ_1-2μ_2 )x+(μ_2^2-μ_1^2 ))/(2σ^2 )+lnα) ) )
令 w=(μ_1-μ_2)/σ^2 ,w_0=(μ_2^2-μ_1^2)/(2σ^2 )+lnα,则
P(y=1│x)=1/(1+e^(-(wx+w_0)) )
其实,这就是逻辑回归。
逻辑回归是典型的判别式模型,并没有去学习正态分布对应的参数 μ_1、μ_2、σ,而是直
接学习对分类有用参数,即 (μ_1-μ_2)/σ^2 和 (μ_2^2-μ_1^2)/(2σ^2 )+ln (P(y=1))/(P(y=0))。这也是判别模型比生成模简单的原因——判别模型仅学习对分类有帮助的信息,而不是类别本身。
不过,在这里需要注意:将逻辑回归作为分类函数,相当于默认偏置条件“数据满足正态分布”。经统计学方法验证,当数据量足够大时,根据中心极限定义,概率分布都会趋近于正态分布。这也说明,在训练模型时,数据量越大,数据分布越接近正态分布,越符合模型的假设,效果自然越好。
对机器学习感兴趣的读者可以去主页关注我;本人著有《速通深度学习》以及《速通机器学习数学基础》二书,想要完整版电子档可以后台私信我;实体版已出版在JD上有售,有兴趣的同学可以自行搜索了解
想一起学习机器学习的话也可以後台私信,本人所做机器学习0基础教程已有60余章还未公开;想了解的话也是後台私信或者评论区留言。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









