







 本文介绍了BP神经网络的基本原理,包括特征变换、多分类任务、梯度下降法等内容,并探讨了度量学习及其应用场景。
本文介绍了BP神经网络的基本原理,包括特征变换、多分类任务、梯度下降法等内容,并探讨了度量学习及其应用场景。
8.1 BP神经网络的基本原理
逻辑回归因其简单、高效、具有可解释性,在工业界得到了广泛的应用并大放异彩。但是,随着业务越来越复杂,分类任务的难度越来越高,逻辑回归渐渐力不从心。分类任务的难度主要体现在数据的线性不可分上——不同类别的数据犬牙交错,很难用一条简单的直线将数据点分开,如图8-1左图所示。为了降低数据分布的复杂性,一般会对特征进行变换和组合,使低维空间中的数据在高维空间中变成线性可分的,如图8-1右图所示。
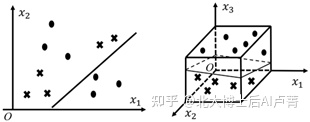
图8-1
根据上面的思路,逻辑回归有了诸多改良。
人工组合高维特征:将特征升维至高维空间(如果不怕麻烦,可以进行任意维度和阶次的交叉),从而将低维空间中的线性不可分问题转换成高维空间中的线性可分问题。不过,这种方法会耗费较多的人力,并且需要我们对业务特征有很深的理解。在一些重要的场景中,当算法能力达到瓶颈时,人工组合高维特征往往能够出奇制胜。
自动交叉二阶特征:例如,FM(Factorization Machine)算法可自动进行所有二阶特征的交叉。不过,FM算法只能进行二阶交叉,如果需要进行更高阶的交叉(例如“女性”“年轻”“双十一”的交叉),FM算法就无能为力了。
SVM+核方法:可以将特征投影到超高维空间。由于可选的核函数种类有限,SVM升维的“花样”不多,并且伴随着巨大的运算量。
在本质上,上述经典方法都是对“原始输入特征”做文章,通过对特征的变换和组合,将线性不可分问题转换为线性可分问题。不过,上述方法都是针对特定场景精心设计的,一旦实际场景中的特征组合在设计之外,模型就无能为力了。
是否有一种方法,可以根据实际分类任务自动进行特征组合变换呢?答案是肯定的。例如,在二分类场景中,可使用线性变换对特征 x=[x_1,⋯,x_m ]^T 进行变换,形成新特征,如图8-2所示。
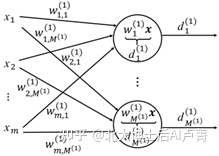
图8-2
在图8-2中,w_j^((1))=[w_(1,j)^((1)),⋯,w_(m,j)^((1)) ]^T,转换后的每一维特征都对原始特征 x 进行了不同
角度的线性变换,公式如下。
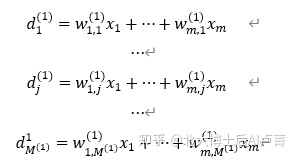
x_i 为输入特征的第 i 维。d_j^((1)) 表示经过第一次特征变换后第 j 维的特征。M^((1)) 表示第一次特
征变换后的特征维度,可以大于或小于原始特征维度 m(并无特定要求)。w_(i,j)^((1)) 表示进行第
一次特征变换时,第 i 维输入特征连接至第 j 维输出特征的连接权重。
特征变换通常可以简洁地写成矩阵相乘的形式,公式如下。

一般来说,可以对经过线性变换的特征 d 进行非线性转换,公式如下。
a^((1))=f(d^((1))+〖w0〗^((1)) )=[■(〖f(d〗_1^((1))+〖w0〗_1^((1)))@⋮@〖f(d〗_(M^((1)))^((1))+〖w0〗_(M^((1)))^((1))))]
其中,〖w0〗^((1))=[〖w0〗_1^((1)),⋯,〖w0〗_(M^((1)))^((1)) ]^T 称为偏置项,其作用和逻辑回归中的 w_0 类似,也是待学
习参数,用于提升模型的表达能力。非线性变换函数 f 一般称为激活函数,其中最常见的是
Sigmoid,即 f_Sigmoid (d)=1/(1+e^(-d) )。
把经过非线性变换的特征 a^((1)) 输入逻辑回归模型并进行分类,有
d^((2) )=W^((2) ) a^((1) )
y^'=f_Sigmoid (d^((2))+〖w0〗^((2)) )
整个流程图如图8-3所示(略去偏置项)。在进行二分类时,最后一层的节点的默认激活函数为Sigmoid(为了使输出具有概率意义)。需要注意的是,中间层 f(d^((1))+〖w0〗^((1))) 的激活函数 f 的作用是进行非线性变换,Sigmoid函数只是候选函数之一。如果我们要解决的不是分类问题,而是回归问题,则只需要去掉最后一层的激活函数(中间层仍然需要使用激活函数)。
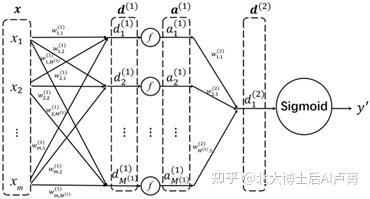
图8-3
图8-2展示了转换方法(线性组合),具体的转换结果需要由参数 W^((1))、〖w0〗^((1))、W^((2))、〖w0〗^((2)) 决定。它们都是待学习参数,一般是通过训练得到的。当我们以分类为目标学习这些参数时,它们会以分类正确为目标自行调整(相当于用分类任务驱动特征组合)。在画图时,一般会将网络中的参数、激活函数等细节省略。这就是经典的BP(Back Propagation)网络,也称
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









