




〔探索AI的无限可能,关注“AIGCmagic”星球,让AIGC科技点亮生活〕
论文标题:
Treat Visual Tokens as Text? But Your MLLM Only Needs Fewer Efforts to See
论文地址:
https://arxiv.org/abs/2410.06169
代码地址:
https://github.com/ZhangAIPI/YOPO_MLLM_Pruning
本文以LLaVA模型为实验对象,通过一系列剪枝策略,将计算量压缩至12%,同时保持了与原始模型同等的性能,并进一步在Qwen2-VL和InternVL2.0上验证了此种剪枝策略的普适性。
一. 研究背景
研究问题:这篇文章要解决的问题是如何在多模态大型语言模型(MLLMs)中有效处理视觉令牌的计算冗余,以提高模型的效率。具体来说,随着视觉令牌数量的增加,LLMs的计算复杂度呈二次增长,这成为制约其可扩展性的关键瓶颈。
研究难点:该问题的研究难点包括:视觉令牌数量庞大,导致计算开销显著增加;确定不同样本中的重要视觉令牌也是一个计算开销大的问题。
相关工作:该问题的研究相关工作包括设计更小的视觉编码器、将密集的LLMs转换为专家混合模型(MoE)、采用紧凑的语言模型以及实现视觉令牌剪枝等方法。这些方法在一定程度上缓解了计算负载,但通常会以牺牲模型质量为代价。
二. 研究动机
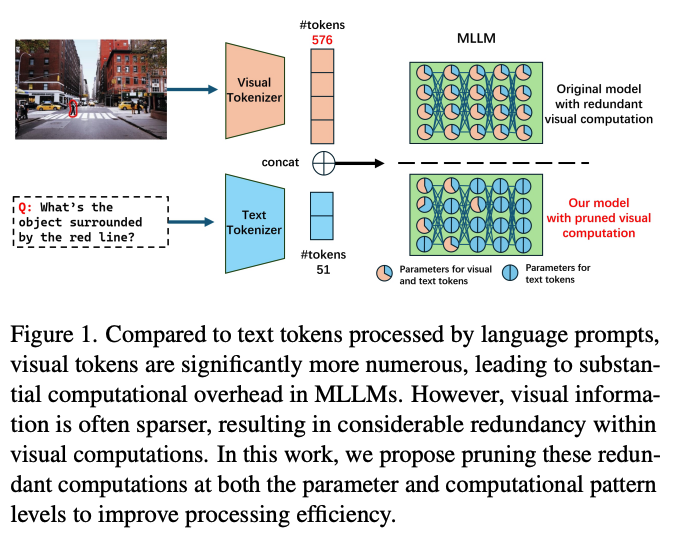
多模态大模型近年来在跨模态任务(如视觉问答、文本生成和科学推理)中表现出了强大的能力。然而,与文本 token 相比,视觉 token 的数量往往更为庞大。例如,在 LLaVA 模型中,处理一张图像涉及超过 500 个视觉 token,而对应的文本 token 只有数十个。这种极大的不平衡带来了如下问题:
计算效率低下: LLMs 的注意力机制复杂度随着输入 token 数量呈二次增长。这种计算成本的急剧增加对硬件资源提出了极高的要求,限制了多模态大模型的实际应用。
冗余性被忽视: 尽管视觉数据包含丰富的信息,但其固有的空间稀疏性导致许多计算是冗余的。例如,大部分视觉 token 之间的交互权重很低,仅有邻近 token 之间的交互是关键。此外,在深层模型中,视觉 token 对文本生成的影响逐渐减弱,但现有计算模式并未有效利用这一特性。
现有方法的局限性: 已有的优化策略,如减少视觉 token 数量或使用轻量化的语言模型,通常以牺牲模型性能为代价。如何在保持性能的同时显著降低计算复杂度,仍是一个急需解决的问题。
基于上述问题,本文提出了新的优化方向:通过深入挖掘视觉参数和计算模式的冗余性,对模型计算做剪枝,而不是简单地减少 token 数量。这种方法不仅能降低计算开销,还能最大程度地保留模型性能。
三. 研究方法
本文提出了四种核心策略,分别从注意力机制、前馈网络和层剪枝等多个角度优化视觉计算:
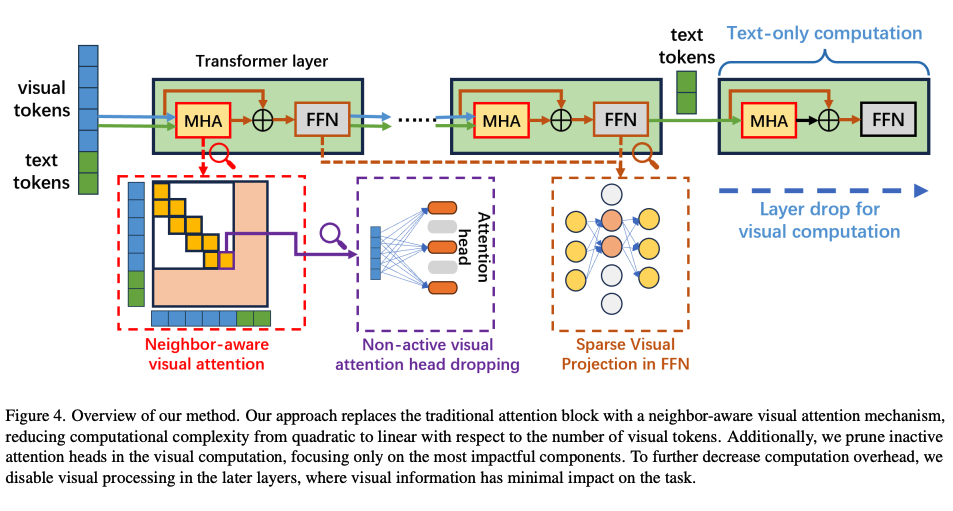
3.1 邻域感知的视觉注意力
论文分析了视觉注意力计算中的冗余,发现大多数注意力权重集中在相邻的视觉令牌上。为了减少计算负担,提出了一种修改后的注意力机制,使得只有相邻的视觉令牌之间才会发生注意力计算,而文本令牌仍然可以跨越视觉和文本令牌进行注意力计算。修改后的注意力计算公式如下:
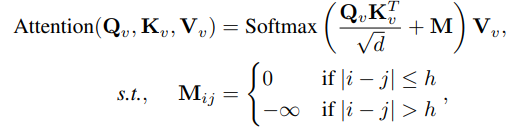
这里 h 表示视觉令牌的邻域大小。
3.2 非活跃注意头剪枝
研究团队以 LLaVA-1.5 作为研究对象,随机选取了 100 个视觉问答样本,可视化了视觉 token 的不同注意力头的权重,实验发现大约有一半数量的注意力头都没有被激活。由此可见这部分注意力头的相关计算同样存在大量冗余并可以被剪枝。实验表明,即使剪掉大量注意力头,模型仅有极小的性能下降。
3.3 稀疏投影的前馈网络
通过剪枝大部分视觉注意力计算,模型的视觉表达变得高度稀疏。为了有效利用这种稀疏性,研究团队提出在每个 transformer 模块内的前馈网络隐藏层中随机丢弃 p% 的神经元。
3.4 选择性层丢弃
研究团队通过可视化 LLaVA-1.5 不同层的视觉 token 跨模态注意力权重发现,大权重集中在前 20 层,在第 20 层到 40 层之间权重接近于 0。
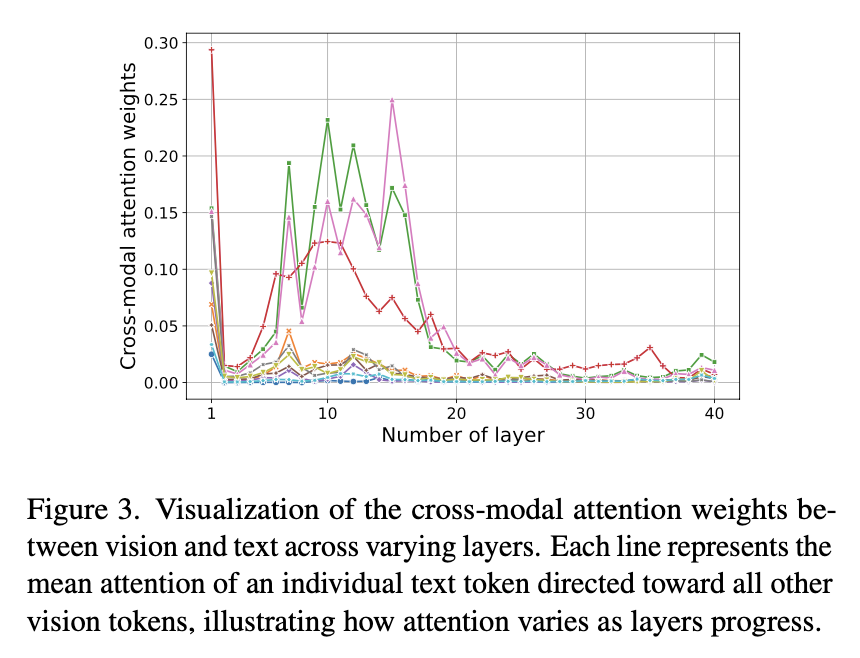
这项结果表明靠后的 20 层的视觉计算存在大量冗余。这一观察启发了研究团队在靠后的层中直接跳过所有与视觉相关的计算,从而减少计算开销。使得注意力计算可以简化如下:
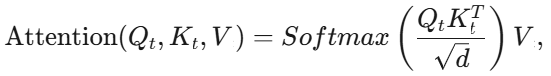
四. 实验设计
研究模型:主要研究了LLaVA-1.5-7B和LLaVA-1.5-13B模型的视觉计算剪枝。隐藏维度分别为4096和5120,中间FFN尺寸分别为11008和13824。LLaVA-1.5-7B模型有32层,每层32个注意力头;LLaVA-1.5-13B模型有40层,每层40个注意力头。
基准模型:选择了四种基线方法,包括PruMerge+、PyramidDrop、SparseVLM和FastV。其中,PruMerge+和PyramidDrop需要微调以适应视觉令牌减少,而SparseVLM和FastV是无需训练的方法。
评估基准:在视觉问答、科学推理和多模态理解等多个基准上进行评估。包括VQAv2、ScienceQA、TextVQA、GQA、POPE、MME和MM-Bench等。
实现方式:在训练集和训练无关的设置下应用不同的剪枝策略。训练集使用与LLaVA-1.5相同的训练数据和协议,训练无关的设置则直接对研究模型应用不同的剪枝策略。
五. 实验结果
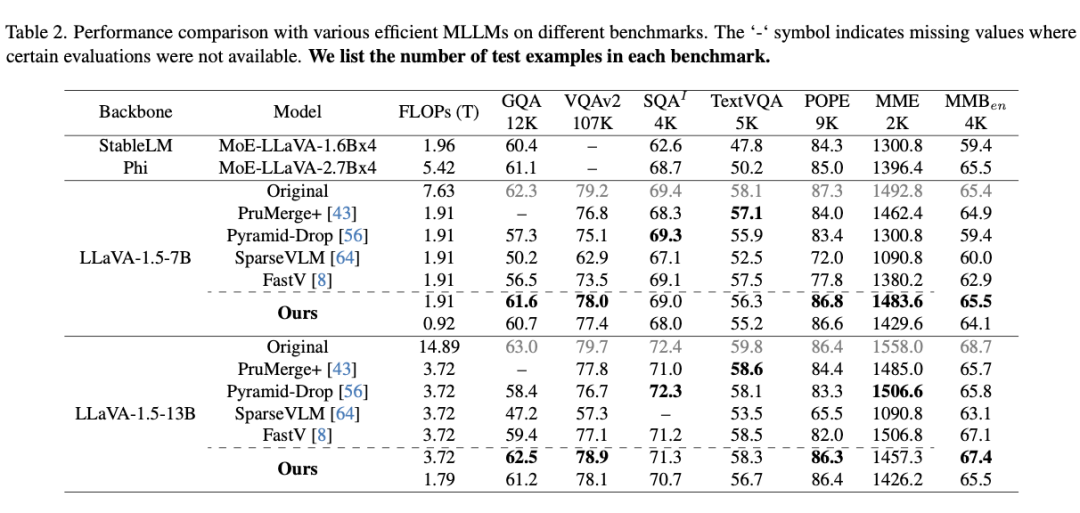
研究团队对 LLaVA-1.5-7B 和 LLaVA-1.5-13B 模型应用提出的四种剪枝策略并进行了评估,结果显示剪枝后 FLOPs 分别减少至原始模型的 25% 和 12%。
在相同计算预算下,剪枝模型在四个基准任务(GQA、VQAv2、POPE 和 MMBench)上均表现最佳,分别超出第二名方法 3.7%、1.1%、2.2% 和 0.45%。
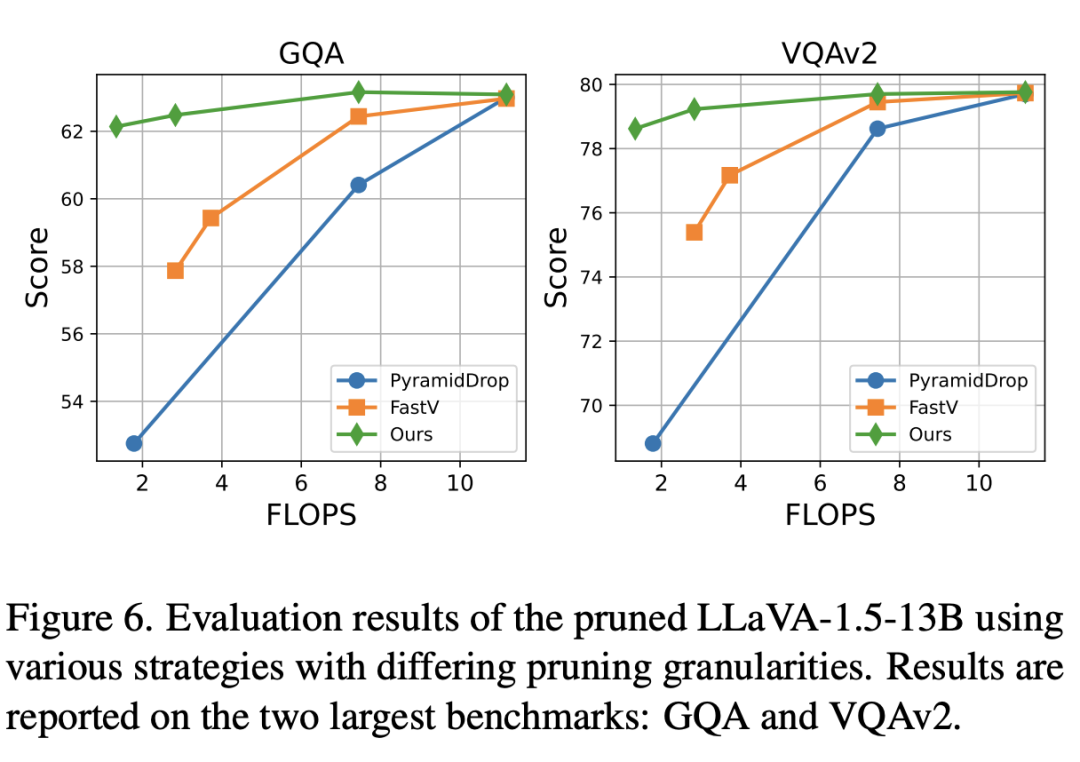
为验证方法在剪枝视觉计算冗余方面的可扩展性,本文将提出的策略与 PyramidDrop 和 FastV 方法在 VQAv2 和 GQA 两个大型基准上的不同剪枝粒度进行了比较。
实验结果表明,随着 FLOPs 减少,模型性能也有所下降。例如,使用 FastV 方法将 FLOPs 从75%减少到 19% 时,平均性能从 71.35%下降到 66.63%。
相比之下,本文的方法不直接剪枝 token,而是针对参数和计算模式层面的冗余优化,在相同 FLOPs 下性能仅下降 0.5%。这一结果进一步证明,当前多模态大模型中的大量视觉计算冗余可以通过有效剪枝加以优化。
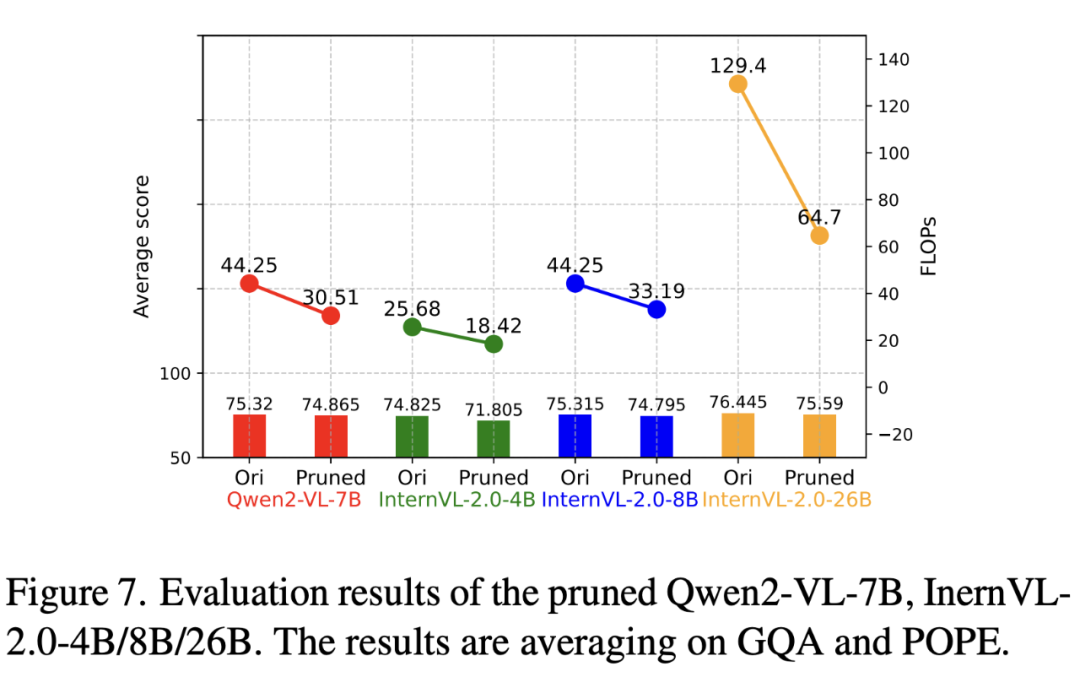
为验证剪枝策略的广泛适用性,本文将其应用于其他多模态大模型(如 Qwen2-VL-7B 和 InternVL-2.0),并在无需微调的情况下进行评估。通过在 GQA 和 POPE 基准上调整剪枝粒度以匹配原始模型性能和最小 FLOPs,结果显示,这些模型在适当的剪枝比例下,即使不进行微调,性能也未受影响。
此外,较大的多模态模型能够容纳更高的剪枝比例,这一点在不同规模的 InternVL-2.0 模型的剪枝实验中得到了验证。
六. 总结
这篇论文通过分析视觉计算中的冗余,提出了一系列策略来减少视觉计算的开销,从而提高MLLMs的效率。实验结果表明,这些策略可以在保持模型性能的同时,显著减少计算成本。
在基本保持性能的同时,LLaVA 的计算开销被减少了 88%。在 Qwen2-VL-7B 和 InternVL-2.0-4B/8B/26B 上的额外实验进一步证实,视觉计算冗余在多模态大模型中普遍存在。
推荐阅读
社区简介:
《AIGCmagic星球》,五大AIGC方向正式上线!让我们在AIGC时代携手同行!限量活动中!
AI多模态核心架构五部曲:
AI多模态模型架构之模态编码器:图像编码、音频编码、视频编码
AI多模态模型架构之输入投影器:LP、MLP和Cross-Attention
AI多模态模型架构之输出映射器:Output Projector
AI多模态模型架构之模态生成器:Modality Generator
AI多模态实战教程:
AI多模态教程:从0到1搭建VisualGLM图文大模型案例




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









