 阿里ZeroSearch激发LLM检索推理能力
阿里ZeroSearch激发LLM检索推理能力




有效的信息搜索对于提升 LLMs 的推理和生成能力至关重要。近期探索的强化学习(RL)方法面临两大主要挑战:(1)文档质量不可控:搜索引擎返回的文档质量往往是不可预测的;(2)高昂的API成本:RL训练频繁地进行模拟运行,涉及数十万次搜索请求,导致了巨大的API费用。
为此,阿里通义Lab提出了ZEROSEARCH,这是一个无需与真实搜索引擎交互即可激励LLMs搜索能力的强化学习框架。

ZEROSEARCH从轻量级的监督微调开始,将LLM转化为一个检索模块,使其能够根据查询生成相关和噪声文档。在强化学习训练过程中,采用基于课程式训练策略,逐步降低生成文档的质量,通过让模型逐渐适应更具挑战性的检索场景,逐步激发其推理能力。
-
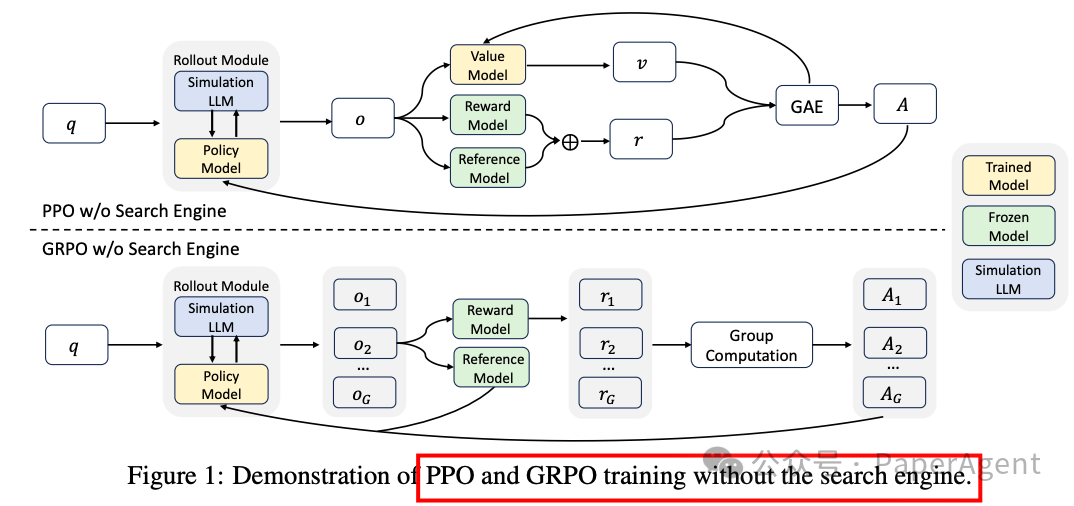
训练模板:采用多轮交互模板,引导策略模型进行迭代推理和信息检索,直到得出最终答案。模板分为三个阶段:内部推理(<think>...</think>)、搜索查询(<search>...</search>)和答案提供(<answer>...</answer>)。
-
搜索模拟微调:通过收集与真实搜索引擎交互的轨迹,并对其进行标注(正确答案为正,错误答案为负),然后提取查询-文档对进行微调,使LLM能够生成有用或噪声文档。
-
课程式训练策略:在训练过程中,逐步增加生成文档的噪声概率,使策略模型逐渐适应更具挑战性的检索场景。
-
奖励设计:采用基于F1分数的奖励函数,平衡精确率和召回率,避免模型通过生成过长答案来增加正确答案的出现概率。
-
训练算法:兼容多种强化学习算法,如PPO、GRPO和Reinforce++,并通过损失掩码机制稳定训练过程。


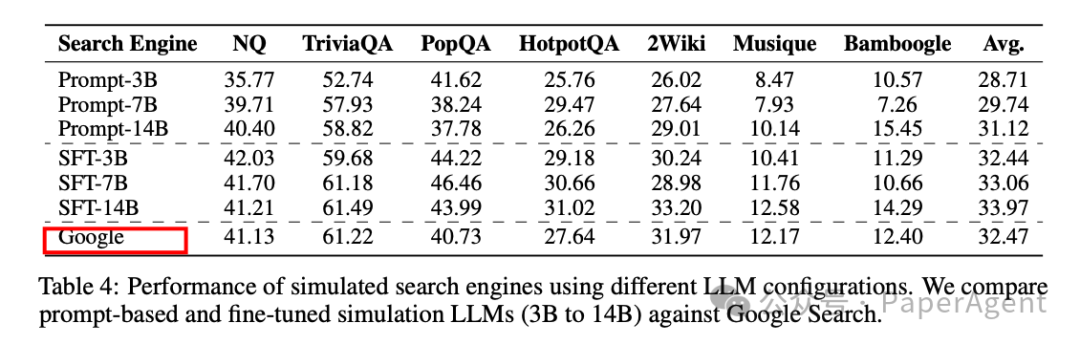
实验使用了Qwen-2.5-7B、Qwen-2.5-3B和LLaMA-3.2-3B等模型家族,并通过SerpAPI与Google Web Search进行交互。训练时,将NQ和HotpotQA的训练集合并为统一数据集进行微调,并在七个数据集上评估性能。
-
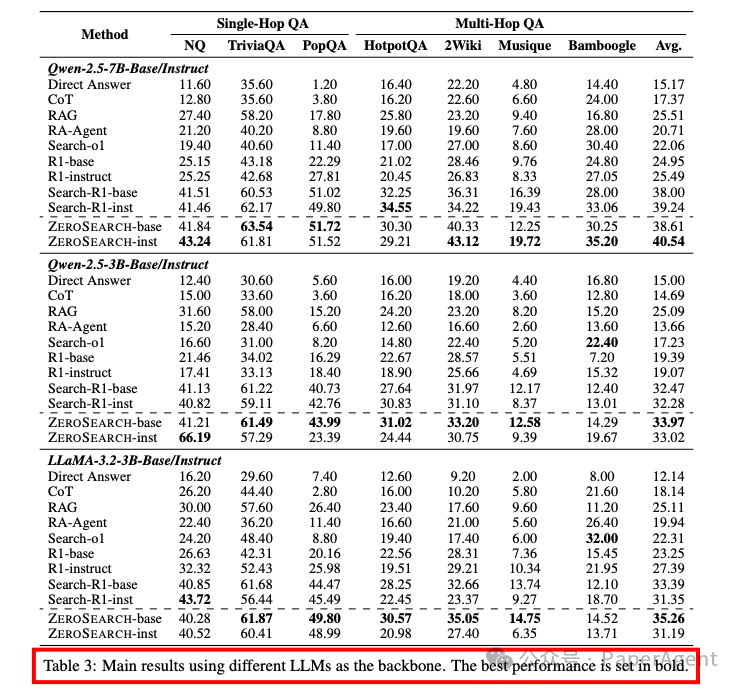
ZEROSEARCH在7B检索模块时与Google Search性能相当,在14B检索模块时甚至超越了Google Search。
-
ZEROSEARCH在不同模型家族、参数大小和类型(基础模型或指令调整模型)上均表现出良好的泛化能力。


来源 | PaperAgent


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









