



作者:叶千树,阿里巴巴集团 自然语言处理
原文:https://zhuanlan.zhihu.com/p/13764430167
前言-当预训练数据不再增长
Ilya Sutskever在12月份NeurIPS 2024演讲,提到LLM预训练数据不再增长,因为只有一个互联网。这句话完整意思应该是相对于以前,OpenAI 提出LLM的scaling laws(Scaling Laws for Neural Language Models[1]), 模型的性能随着数据,计算量,模型参数大小的增加而增加。在之前模型参数量从GPT-1 117M 到GPT-3 175B,训练数据也从4.5GB文本到499 billions token (GPT-3使用的预训练数据量没有找到官方数据,一般认为在570B到45T之间)。GPT-4不再开源不清楚用了多少数据,近期开源的llama3.1使用了15.6T的预训练tokens (llama2 使用了1.8T ), Qwen2.5使用了18T的预训练tokens( Qwen2 使用了 7T )。模型的参数也许还在膨胀,但至少现在,数据却不能再像以前那般百倍增长。
Ilya Sutskever演讲中提出了三个方向来解决数据不再像以前增长的情况下却还要提升模型性能这个挑战:代理(agent), 生成数据(synthetic data), 推理计算时间(openai o1模型系列推理能力)。
在9月份OpenAI推出o1模型系列, 在Learning to Reason with LLMs[2] 就提到:We have found that the performance of o1 consistently improves with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute). o1的性能随着更多的强化训练(训练时间)和更多的思考时间(推理时间)而持续增强。然后OpenAI 9月份在推特上招募ML工程师组建multi-agents研究组,其认为multi-agent是达到更好的AI推理的一种路径(We view multi-agent as a path to even better AI reasoning)。
在某种程度上,Ilya Sutskever提到的问题和思路,也是OpenAI看到的问题和解决问题的思路。区别是OpenAI在其9月份的文章中暗搓搓的埋进去,Ilya Sutskever在12月份演讲中强调了一遍。
Multi-agents比较好理解,蜂群拥有比单个蜜蜂更高的能力, 人类社会也拥有比个体更强的能力。本文不做涉及。
问题在于怎么理解 更多的强化训练 和 更多的思考时间。OpenAI提到了这两个方向,他们很可能是这么实践的,但是我们还不知道怎么去做。
因而衍生一些问题,例如更多的强化训练和以前RLHF(Reinforce learning from human feedback)有什么区别, 更多的思考时间和以前的COT(chain of thought)有什么区别。本文主要聚焦在更多的强化训练和更多的思考时间两方面的探索和理解,通过梳理,希望找到这两方面可实践的方法,去知道怎么做。
更多的强化训练-more reinforcement learning
训练方法
OpenAI论文 Training language models to follow instructions with human feedback [3]在预训练的基础上引入了RLHF来让模型理解人的提出的问题,从而产出更符合人期望的答案。关于强化学习的相关方法演化, 可以参考文章 理解LLM偏好对齐和DPO[4] 。
在llma3.1 和 Qwen2.5 的技术文档中,没有透露post trainning阶段使用了多少token数据。

图1, 来自 The Llama 3 Herd of Models
大概来说,在post training阶段,llama3使用了多个迭代,在每个迭代中,它会使用偏好数据训练奖励模型(reward model), 基于奖励模型对当前的模型进行Question/prompt抽样,从而生成数据用于后续的SFT和DPO训练。
对于SFT, llama3会使用reject sampling(拒绝采样,抽样K条, k 在10~30之间,用奖励模型评分选择最好的一条), 对于DPO, 则是会选择那些正样本明显好于负样本的样本对, 其他样本则会丢弃掉。在文章中提到相对于PPO这种方法,DPO训练需要的计算资源更少,在指令遵循评测集上评测指标还会更高。
DPO简化了PPO的训练复杂度,也因为其简化,引入了新的问题,例如对于正负样本对相似度比较高的样本集,模型训练后在正样本的概率相对于原始模型(参考模型)概率会下降,这个现象不在预期之内,因为我们会期望通过训练,提升模型在正样本上的概率。llama为了解决这个问题,在DPO的基础上增加了一个正样本的额外loss(DPO+NLL), 来提升训练模型在正样本上的概率。上文所述DPO的样本选择那些正样本明显好于负样本的样本对,也是借此增加正负样本的差异来减少前面提到的正样本概率下降问题。此外,DPO通过正负样本的间距(margin)潜在改变了训练样本的分布,某种程度上让模型更专注于那些难以分辨的正负样本对,这也可以解释为什么在一些数据集上DPO的能获得更好的评测指标。DPO相关的问题分析及解决方案在理解LLM偏好对齐和DPO有详细探讨,有兴趣可以参考。
但是因为llama的技术选型, 用拒绝采样来做SFT因而sft数据的利用率是1/30~1/10, 用筛选正负样本差距比较明显的样本对来做DPO, 因而DPO数据的利用率也是只有部分利用,因而我们发现这里有很大一部分数据被丢弃掉了。假设llama在sft + dpo的基础上,叠加PPO的训练流程,充分利用所有的数据,或者基于sft+所有数据做ppo来训练,结果是否会变的更好?
以前也在使用强化学习的方法来提升模型的偏好对齐/指令遵循能力,但在以前,并没有特意强调post training或强化学习训练数据量和训练计算量的重要性,post training更多的是用来做输出偏好/格式的对齐。当预训练数据量达到一个瓶颈的时候,OpenAI认为通过更多的强化训练(增加强化学习中用到的数据量),可以让模型性能继续得到一个增长。
生成训练数据
在上节训练方法中,提到了使用模型抽样来生成数据给模型做偏好对齐。生成数据的样式和质量和下文讨论的更多的思考时间在本质上密不可分,因为需要生成一种合适的数据样本,来让模型学会得到一种思考方式,从而在推理阶段能够自动触发这种思考方式,才能消耗更多的思考时间,得到更高的答案质量。
同时,生成数据又和奖励模型(reward model)密不可分, 生成数据可以等价为奖励模型的具象化,LLM是通过学习大量生成数据,从而在生成概率分布上来拟合奖励模型的期望。(通常认为 评价能力 比 生成能力 更容易达到, 因此LLM通过大量的数据学习,来提升更难的生成能力)。
OpenAI 论文 Let’s Verify Step by Step [5]提到相对 最终奖励模型(ORM,Outcome-supervised reward model), 过程奖励模型(PRM, Process-supervised reward model)的性能更好, 因为过程奖励模型能够识别出false positive的错误,即过程出错,但是结果恰好正确的情况。此外,借助于知道是哪一步出错,相对于只知道结果是否正确,给了模型额外的信息。

图二, 来自 Let’s Verify Step by Step
如图二所示, 过程奖励模型能对每一步(每一行做为一步)作出判断该步骤是否正确(正确标绿,中性标灰,错误标红)。
相对于PRM优于ORM的结论, OpenAI在论文中展现的工程实践更值得学习和赞叹。
1.生成具有中间过程的样本。为了得到具有中间过程的样本, 首先是使用few-shots来指导一个base模型输出期望的格式(手写了几个问题的答案过程), 然后筛选出答案和标准答案一致的样本来做模型训练(这些样本会包含false positive),产出一个能输出符合预期格式,含有中间过程的模型。
2.使用active learning得到一个高质量奖励模型。在标注数据时,使用多个阶段,每个阶段,让标注人员标注当下PRM模型认为是最佳, 但实际是错误的答案。
3.模型输出一个概率值,但是最后判断答案是否错误的阈值,选取了错误分类概率大于0.2(在整个数据集中,错误标签占总体标签差不多27%,但是他们发现奖励模型会偏好产出正标签,也就是错误标签概率值会被压低,因而选择阈值0.2低于标签的统计值0.27)
4.验证了随着抽样样本数量增加(增加到1000个),奖励模型的准确率在增加,如下图图三所示,呼应了需要更多的抽样样本来得到正确的答案,并且PRM和ORM之间的差距也在逐渐增加,过程奖励模型的优势在增加。
5.PRM和ORM的效果优于多数投票,多数投票是指在多个抽样中,选择输出答案一致计数最多的那个, 其基础的思路是认为模型在多次抽样中,越是复杂的问题,中间过程越是存在差异,但是最终会输出一致的答案。多数投票一般会做为模型的优化基线来做对比(Self-Consistency Improves Chain of Thought Reasoning in Language Models[6])。
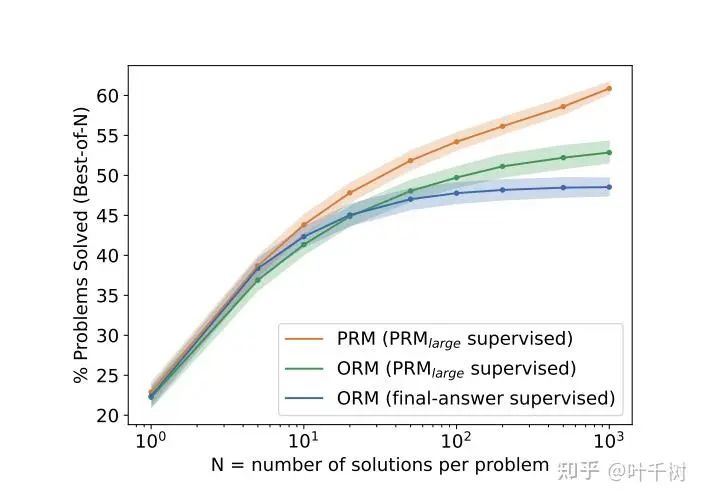
图三, 来自 Let’s Verify Step by Step
为了减缓标注昂贵的问题,有些方法利用数学问题有标准答案这个特性,从而使用蒙特卡罗抽样的方式来自动化判断答案过程中哪一步出问题, 来生成训练数据来训练过程奖励模型。( Math-Shepherd: Verify and reinforce LLMs step-by-step without human annotations[7] , Multi-step Problem Solving Through a Verifier: An Empirical Analysis on Model-induced Process Supervision[8], Improve Mathematical Reasoning in Language Models by Automated Process Supervision[9], Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning[10] )
OpenAI论文 Scaling Laws for Reward Model Overoptimization[11] 提出了奖励模型效果和奖励模型的大小,数据量之间的关系。基本思路基于Goodhart's law,Goodhart’s law是指一个指标被变成一个目标时,它便无法成为一个好的指标, 举例来说代码行数可以反映程序员的产出,但是如果追求代码行数,那程序员就会为了代码行数而增加代码,因而脱离用代码行数来衡量程序员产出这个目的。在LLM强化学习中,在使用代理(proxy,奖励模型或者判别模型)来优化模型时,Goodhart's law便会出现,这里的本质原因是代理(奖励模型/判别模型)只能反应客观的一部分。在代理的指导下过度优化,有可能会导致模型过拟合到代理目标上却在客观的指标上性能下降太多。
为了验证这个假设, 论文使用一个6B的模型来表征ground truth, 来解决现实中衡量结果需要大量的人工标注的问题。6B奖励模型同时提供训练数据,并参与后续优化模型的评测。
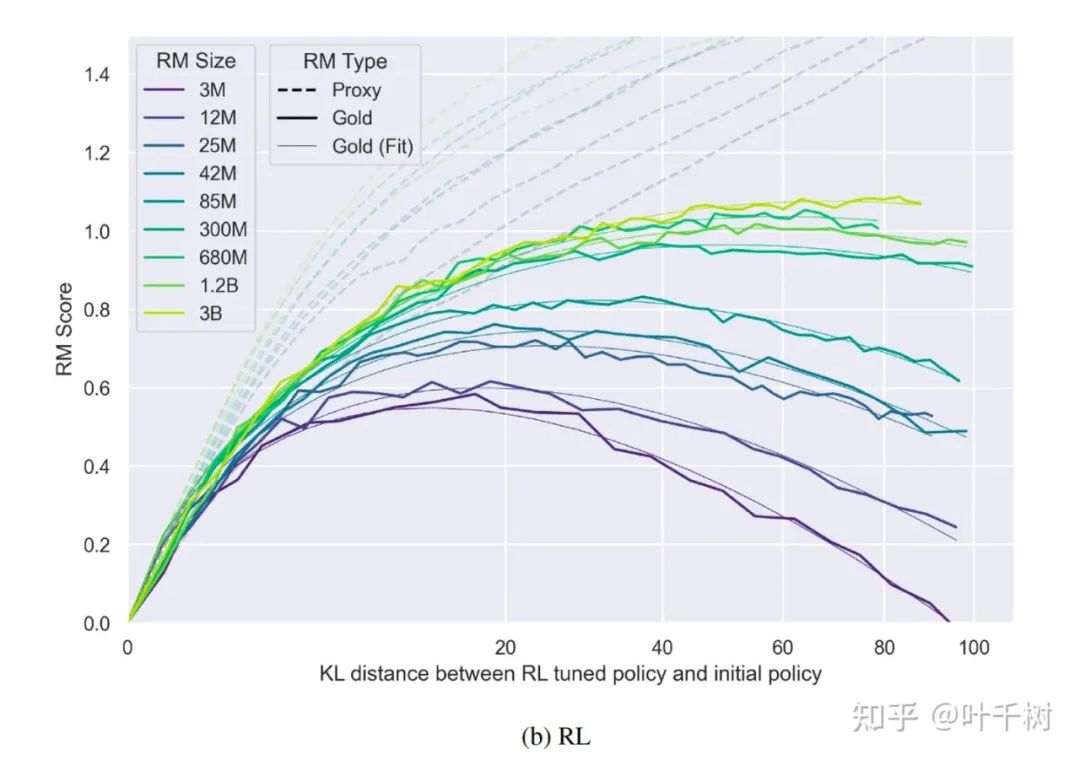
图4, 来自 Scaling Laws for Reward Model Overoptimization
如图4所示,不同颜色表示不同size的proxy reward model, 横轴表示policy model(经过proxy reward model 指导,经由强化学习训练后的模型)相对原始模型的KL散度(KL散度越大,说明训练越多,偏离参考模型越远), 虚线表示policy model在proxy reward model下的得分 , 实线表示policy model在ground truth model下的得分。
1.对于同一个size的proxy reward model, 同一个颜色,可以看到Gold score(ground truth模型)随着KL变大到一定程度后开始衰减,而此时proxy rewards的评分随着KL变大还是在增加
2.对于不同size模型proxy reward model,可以看到Gold的曲线高点不同,简单来看, proxy reward model size越高,对应的Gold score(ground truth模型)越高,并且衰减需要的DL 越大,也可以看作是越不容易过拟合。论文得出的拟合形式为
Best of N (bon, 拒绝抽样)和RL 在系数曲线上略有区别,这两个公式,基本都是
1.和d成负的二次方,也就是当d变到足够大时, Reward就会开始下降
2.公式中有多个参数, alpha, beta alpha代表的是线性增长,beta代表的是多次方衰减,简单理解aplha越大,beta越小那么score的值会越高,且开始衰减所需要的d就会越大。
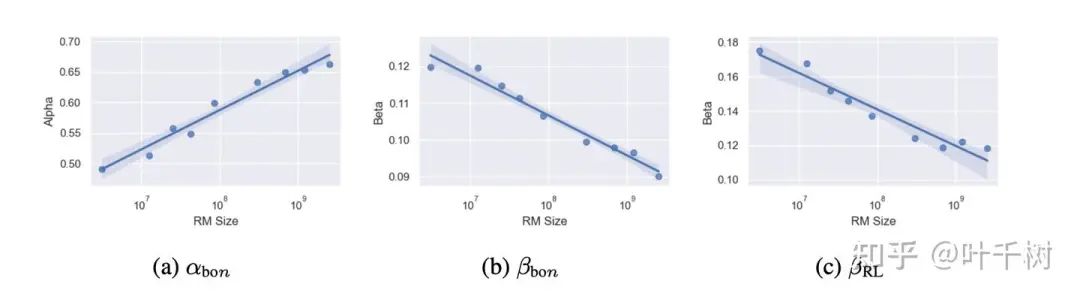
图5, 来自 Scaling Laws for Reward Model Overoptimization
如图5所示,是模型大小和gold score的关系,对于每个size的reward, alpha,beta是不同的, 随着模型size增加,alpha在变大,beta值在减小,如同上面第二点提到的,反映的是训练出来的模型,gold score(ground truth)值更高, 更慢开始衰减。
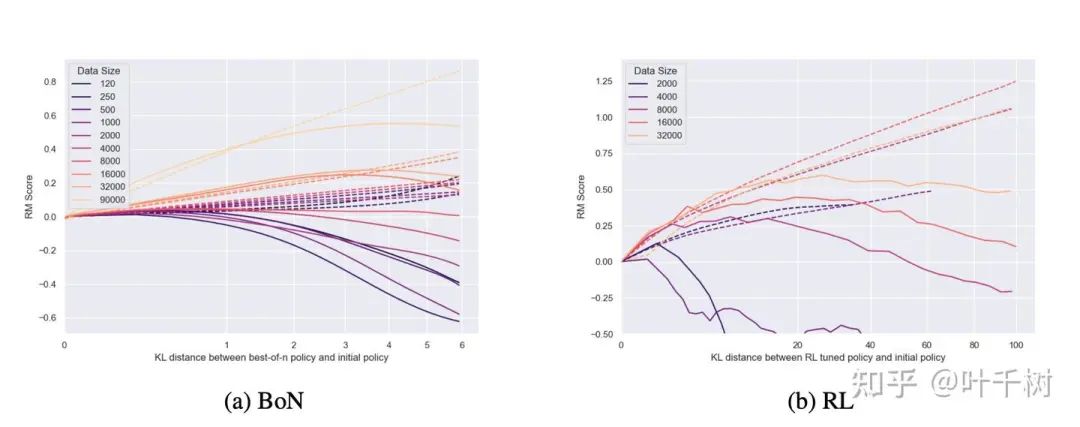
图6, 来自 Scaling Laws for Reward Model Overoptimization
如图6所示, 文章还衡量了训练proxy reward model 所需的数据量,在固定reward model size的情况下,数据量越多,由此reward model指导训练的policy model得到的gold score会越高。在数据量小于2000的情况下下,基本上对于优化policy model无帮助。
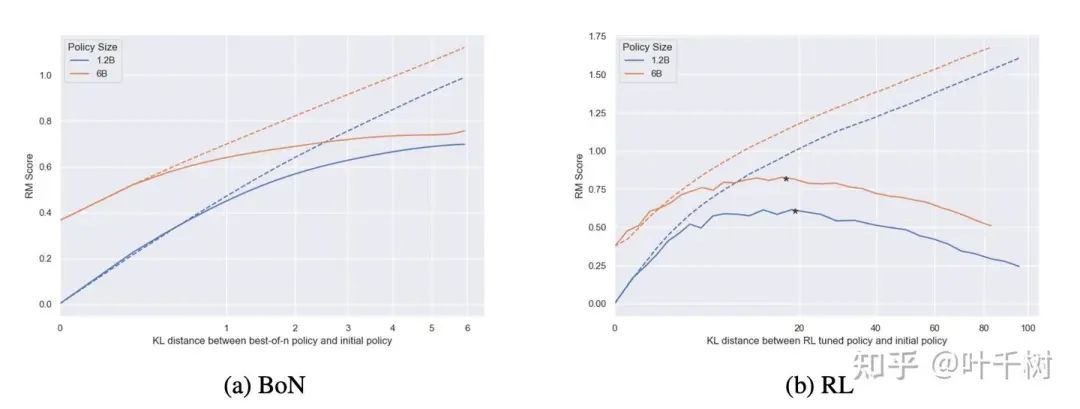
图7, 来自 Scaling Laws for Reward Model Overoptimization
如图7所示,文章衡量了在固定reward model情况下,不同policy model大小对于reward model的响应, policy model size越大,从reward model得到的性能增长越少, 越早到达指标高点,对KL变化的容忍度越高,更不容易过拟合。
OpenAI论文 Rule Based Rewards for Language Model Safety[12], 这篇论文介绍了怎么将规则应用于训练数据产出一个奖励模型,这个奖励模型参与后续的policy model的强化学习过程。从这个论文中得到的一个重要观点是,通过数据学习,LLM可以学习到reward model所表征的逻辑,无论这个逻辑是来自于人类的标注数据,还是来自于逻辑规则。同时进一步的思考点在于,将规则应用在prompt中,和通过规则-reward model-policy model 训练的强化学习流程,是否存在差别。
在OpenAI论文 Training language models to follow instructions with human feedback[13]中有提到 policy model经由强化学习后,效果优于加了 few-shot prompt的模型。
我们假设,经由强化学习,能够将某些逻辑内化在模型内部。而这个内化的过程,需要足够多的训练数据和引导,因此围绕一个有足够参数,足够训练数据的过程奖励模型, 一个有足够参数,对KL变化容忍度高的base待优化模型,抽样阈值K远大于30, 可以高达1000, 2000从而有足够多样性的抽样数据,充分利用所有数据的训练流程等因素,来得到更多的强化学习。通过这个训练,我们或许可以将思维链内化在模型内部,如同 Rule based reward可以将规则经由数据训练内化到模型上一样,用户可以将思维链经由模型训练内化到模型上,在这种情况下,不再需要通过prompt来触发模型的思维链,而模型能够自主自动的使用思维链。
更多的思考时间-more time spent thinking
一个纯理论解释
在计算机操作中,我们会使用输入参数的大小来表示相应的计算复杂度,例如经典的快速排序算法,对输入size为N的序列, 计算复杂度在O( NlogN ) , 对于两个矩阵( )相乘,计算复杂度是O( ),也就是输入size越大, 需要的计算时间越长。
对于LLM,从理论上来说,在输入长度为L, 向量维度为d情况下 预测下一个token时, 我们大致认为其计算复杂度为O( )。(假设d=4096,此时L的平衡点约为24576, 在L>24576情况下,L占主导,在L<24576情况下, d占主导)
在一定长度内,d占主导情况下,其计算复杂度简化成O( ),又因为对于模型自身而言,d是一个固定值,因此计算复杂度退化成O(1),也即基本认为是一个固定的计算量,某种程度上反映出LLM的计算复杂度基线之高,能从计算角度解释为什么LLM在某些问题下,有直接输出答案的能力。或许Open AI o1的名字也和这个有关系,其期望o1系列模型拥有足够的能力来直接输出答案。
在一定长度上,L占主导情况下, 其计算复杂度简化成O( ), 因为LM的计算能力的基线很高,也许LLM是远高于别的算法的O( )计算量, 但是仅仅从LLM自身计算这个角度来说,一个复杂问题求解,如果LLM没有办法在O( )求解, 而又需要LLM生成正确的答案,LLM唯一可行的方式就是展开中间过程,将长度从L展开成足够大的M,此时O()计算量来满足问题的复杂性。
这个展开中间过程的逻辑也适合于上述提到的d占主导的场景,从LLM计算复杂度的角度来看待,就是通过展开中间逻辑来获取更高的计算量,达到解决问题所需要的计算量。
所以我们会发现,在面对一个复杂(计算,路由,迷宫)问题情况下,强迫LLM模型直接输出答案,LLM模型输出的答案大概率是错误的。而如果能引导模型展开中间过程,产生所谓的思维链, 增加计算量,模型又能产出正确的结果。
上文提到的计算复杂度,是从一个纯理论的角度的来考虑LLM模型的生成,因为LLM模型本身拥有大量通过训练得到的参数,拥有学习模式/识别模式/记住模式的能力,类似于人的肌肉记忆/潜意识行为,对于某些问题,模型能快速的出结论。这是在某些场景下,例如天气预报,通过训练模型,利用训练好的模型而非传统算法计算来解决问题,能降低总体计算量的一个重要逻辑。
这也是上面提到OpenAI o1的名字的寄望,经过数据训练后,拥有强大的知识记忆/模式识别下,在高计算复杂度基线条件下,可以在O(1)的计算复杂度输出问题的答案。
大概来说,我们从理论上,实践中都认为模型如果在解决问题过程中,能展开思维链,对模型生成正确的答案又帮助。因此问题变成, 如何让模型展开思维链。
prompt cot - 通过prompt引导模型展开思维链
Google 论文 Chain-of-Thought Prompting Elicits Reasoning in Large Language Models [14]提出在few shot 情况下,在示例答案中,给出中间的计算过程,能够引导模型模拟这种思考过程,帮助模型得到正确的答案,称为few-shot cot. 某种程度上,这是是思维链的起点。
OpenAI 论文 Large Language Models are Zero-Shot Reasoners[15] 则是在模型生成答案之前,预先填入 let's think step by step, 发现也能有效的触发模型的思考过程,不需要针对不同task设计不同的cot样例, 这个方法称为zero-shot cot。在文中提出,虽然zero-shot cot效果比精心设计的few-shot cot 效果要差,但是相对于zero-shot本身,其指标有较大提升。当然在后面的实践中,大家也发现, 在经过强化学习后,可以通过指令直接在prompt中引入let's think step by step也能有效提升的思考过程。
论文 Automatic Chain of Thought Prompting in Large Language Models [16]提供了一种Auto cot的思路,其利用zero-shot cot产生一些包含中间过程的答案,而后将这些含中间过程的答案作为示例来提供给模型从而从而形成few-shot cot. 在此过程中,论文认为示例需要有多样性,因此将样本集基于问题聚类成8个类别,而后从这8个类别来获取示例来增强示例的多样性,在多个评测集上优于manual few-shot cot.
Reasoning cot- 挖掘模型内在的思维链能力
论文 Self-Consistency Improves Chain of Thought Reasoning in Language Models[17] 本质是多数投票,认为对于复杂问题,模型可能会有不同的中间思考过程,但是最终达到的终点一致,因此多数一致即为正确的答案。这个方法通常被当作其他方法的对比基线。
Google 论文 Chain-of-Thought Reasoning without Prompting[18] 提供了一种在推理时挖掘cot的方法。其认为在greedy decoding的情况下,模型可能会丢失掉cot能力,因为训练数据中会有直接产生答案的语料导致模型偏向于直接生成答案,而导致模型偏向于直接生成答案。而模型可能内部具有cot能力,但是需要合适的方法激发出来。因而提供了一种激发模型cot能力(topk decoding)和评估选择(max min(margin))的方法。Topk decoding是指第一个token decoding是,用topk个选择,期望在这k个选项中能有激发出模型的cot的存在。而评估选择思维链方法使用max min margin: 是指选择 答案符号和 该token上的第二高概率token的margin (也就是min margin), 是所有path里最大的,通过这种形式选择该path为最优。在其评测结果中优于self-consistency的方案。
用critic model来评估/选择模型的中间过程。
论文 Tree of Thoughts: Deliberate Problem Solving with Large Language Models [19]利用一个模型来生成中间过程(propose),利用另外一组模型来评价每步中间过程(vote)。而利用树探索方案(深度优先,广度优先)来展开新节点。
论文 Let's reward step by step: Step-Level reward model as the Navigators for Reasoning[20] 则是利用process reward model, 不同于TOT树形(深度优先,广度优先,回退)探索, 其在每个阶段抽样3个选择,利用PRM评价greedy探索的方式,选择评价好的。如果PRM对当前step评价全部为坏,则需要依次回退到上一层中去展开剩下评价好的节点。
也有其它结合PRM做树探索的方法,例如基于MCTS的树搜索。用critic model 来评估/选择模型中间过程这个思路的假设在于,我们认为思维链不是一个字符一个字符展开,对于人来说, 人的思维是一个概念,一个概念的展开。概念通常意义上是一句话,或者一段话。因此引入一个评价者对这个概念做评价,来发现该概念是否走向合适的答案,或者拒绝该概念回到上一一个节点的思考中,整个逻辑是符合人的思考过程的。引入一个critic model做生成搜索思考了更多路径,在某种程度上也符合更多思考时间这个点。
但是和alpha go不同在于,alpha go 最终可以利用roll out 展开到最终节点,利用围棋的规则来判断最终节点是赢还是是输得到一个ground truth, 利用roll out提升mcts的性能。而LLM的生成缺少ground truth的判断者, 利用critic model来评估/选择最终还是受限于critic model的能力。这个的假设在于评价模型比生成模型更容易学习(不会做菜,但是会评价菜的好坏),也就是生成模型和评价模型存在gap的情况下是能提升生成模型的能力的。但是我们也会发现,生成模型性能提升的上限也必然受限于critic model.
内化推理链
基于当前的一些认知,更倾向于OpenAI o1当前的方案是通过强化内在推理链的方式来增强其推理能力。有两篇论文很值得参考。
Dualformer: Controllable Fast and Slow Thinking by Learning with Randomized Reasoning Traces[21] 这个论文的重点在于通过训练集的设置,利用模型对于模式(pattern)的学习和识别,可以让模型自主选择是否展开cot, 提供了一个非常好的实践. 其主要思路是对reasoning的过程 做一定程度的裁剪,来让模型在复杂问题的推理过程中,能有通过类似直觉的快速思考能力,也就是在一个system2 的思考模式中 引入了 system1 的快速跳过能力。该思路有来自于两个观测:一个是search transformer (用完整的trace做训练的)在inference 阶段, 会产生比a*更短的推理过程。第二个是他认为人类在某些pattern下会产生 直觉/短路,也就是人思考是混合了系统1/系统2.
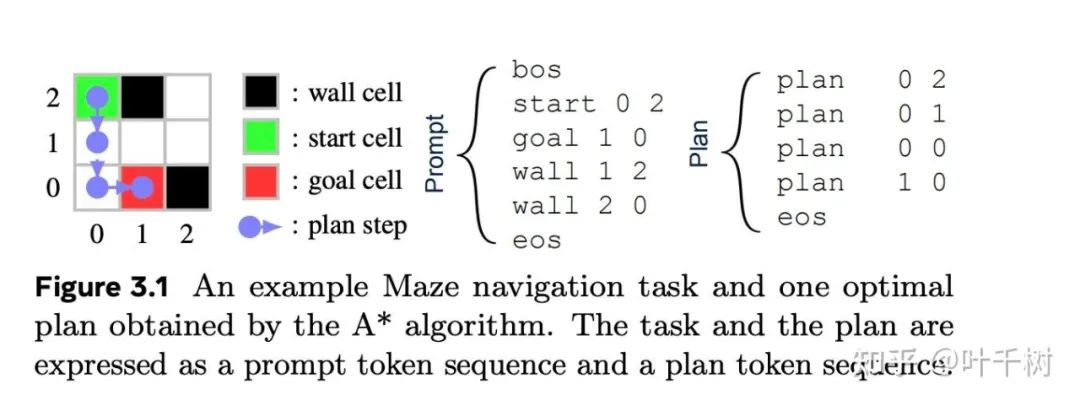
图8 来自Dualformer: Controllable Fast and Slow Thinking by Learning with Randomized Reasoning Traces
如图8所示,对于maze(迷宫, 找到一条从入口到出口的道路)
prompt 是迷宫的设置:入口,出口,墙(阻挡因素)(也就是模型的输入)。plan 是解决方案。

图9 来自Dualformer: Controllable Fast and Slow Thinking by Learning with Randomized Reasoning Traces
如图9, trace (A* search tree)是探索/推理过程。
模型在训练/推理过程中, 输入是 pompt, 输出是 trace + plan。
他对trace做了做了结构性的裁剪, 分成了4个程度
-
• 1.去除 close
-
• 2.去除 close + cost
-
• 3.去除 close + cost + samled(create)
-
• 4.去除整个trace
在训练过程中,对每个sample做抽样(p0, p1, p2, p3, p4), p0是不去除(0.45), p1=p2=p3=1/6, p4=0.05。
论文中提到的,通过插入控制符来决定是系统1思考,系统2思考,还是模型自动决定,本质背后是利用了训练语料的结构和模型对于模式的学习/识别。
-
• 决定系统1快思考,在prompt之后 加入 bos plan (plan是训练材料中输出解决方案的首个字符,也就是引导模型直接输出答案,训练材料中有5%的数据是直接输出答案)
-
• 决定系统2慢思考,在prompt之后 加入了 bos create (create是A* trace的起始符号,也就是引导模型偏向于产生trace)
-
• 自动决定,在prompt之后不加控制符, 期望模型能基于某些pattern, 自己决定最佳方案是什么
本质上还是期望模型能有学习/识别/理解pattern, 能够被符号控制快思考(不含中间推理过程)或者慢思考(含中间推理过程)。
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection[22] 这篇文章一个重要观点在于他认为模型能通过自省,自己学会是否需要获取额外信息,学会判断这些额外信息是否和问题相关,是否基于额外信息生成答案。也就是生成模型需要自己去判断一个问题是否需要补充额外信息进来,才能回答该问题。
因此给了一个假设,假设通过足够充分且多样的学习,模型能识别问题所属领域(这是数学, 物理, 迷宫, 24点计算等),在这个前提下,模型有该领域的过程展开能力并能展开基于PRM指导的推理链,并输出最终答案。
-
• 需要什么格式的数据:在本节中,提到了分门别类的产生不同领域的标志,来触发模型对于该领域问题对应的系统1/系统2的思维链展开(在dualformer中显示模型会基于某些特定符号展开思维链)。
-
• 怎么构建这种格式的数据:在PRM一节中,提到了如何从无到有来让模型输出某种能够展开中间思考的的格式,以便后续模型训练。
-
• 怎么学习这个数据:在更多强化学习中,提到如何将训练数据背后的reward逻辑内化到模型。
上述既是内化推理链的逻辑。
总结
让我们回到文章开始的两个问题
问1:更多的强化训练和以前RL HF(Reinforce learning from human feedback)有什么区别?
答:以前RLHF主要关注的是偏好对齐,
而现在, 我们假设,经由强化训练,能够将某些逻辑内化在模型内部。而这个内化的过程,需要足够多的训练数据和引导,因此围绕一个有足够参数,足够训练数据的过程奖励模型, 一个有足够参数,对KL变化容忍度高的base待优化模型,抽样阈值K远大于30, 可以高达1000, 2000从而有足够多样性的抽样数据,充分利用所有数据的训练流程等因素,来得到更多的强化学习。最终通过这个强化训练,将思维链内化在模型内部。
两者在技巧上有共通点,但现在对强化学习有更明确的目的,将思维链内化在模型内部。
问2: 更多的思考时间和以前的COT(chain of thought)有什么区别?
答:以前的cot, 无论是prompt cot 还是 reasoning cot, 都是某种用户显式的引导或者筛选。而现在更多的思考时间,是指一种内化在模型中的cot展开能力,通过强化训练,将思维链内化在模型内部,通过模型的自省能力(知道自己在回答什么类型的问题),能主动的展开该思维链,或者基于模型对于模式的识别和理解,快速回答问题。
在最近的Open AI论文Deliberative alignment: reasoning enables safer language models [23]还是在讲同一个事情,通过更好的reward model, 经由更多的训练数据,更好的强化学习流程,构建一个具有内在推理链的模型。
我们都或多或少理解其中一部分逻辑,真正的困难在于懂的怎么构建和开始构建这么一个通用且具有内在推理链的模型,因为它必然需要巨大的投入并且会碰到众多的困难。但是庆幸且最重要的是,OpenAI向大家展现了那个目标是真实存在且可达,并且留下了一些如何到达的痕迹,给我们学习和探索。
引用链接
[1] Scaling Laws for Neural Language Models:https://arxiv.org/pdf/2001.08361[2]Learning to Reason with LLMs:https://openai.com/index/learning-to-reason-with-llms/[3]Training language models to follow instructions with human feedback :https://arxiv.org/abs/2203.02155[4]理解LLM偏好对齐和DPO:https://zhuanlan.zhihu.com/p/716947703[5]Let’s Verify Step by Step :https://cdn.openai.com/improving-mathematical-reasoning-with-process-supervision/Lets_Verify_Step_by_Step.pdf[6]Self-Consistency Improves Chain of Thought Reasoning in Language Models:https://arxiv.org/abs/2203.11171[7]Math-Shepherd: Verify and reinforce LLMs step-by-step without human annotations:https://arxiv.org/pdf/2312.08935[8]Multi-step Problem Solving Through a Verifier: An Empirical Analysis on Model-induced Process Supervision:https://arxiv.org/pdf/2402.02658[9]Improve Mathematical Reasoning in Language Models by Automated Process Supervision:https://arxiv.org/pdf/2406.06592[10]Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning:https://arxiv.org/pdf/2410.08146[11]Scaling Laws for Reward Model Overoptimization:https://arxiv.org/pdf/2210.10760[12]Rule Based Rewards for Language Model Safety:https://arxiv.org/pdf/2411.01111v1[13]Training language models to follow instructions with human feedback:https://arxiv.org/abs/2203.02155[14]Chain-of-Thought Prompting Elicits Reasoning in Large Language Models :https://arxiv.org/pdf/2201.11903[15]Large Language Models are Zero-Shot Reasoners:https://arxiv.org/pdf/2205.11916[16]Automatic Chain of Thought Prompting in Large Language Models :https://arxiv.org/pdf/2210.03493[17]Self-Consistency Improves Chain of Thought Reasoning in Language Models:https://arxiv.org/abs/2203.11171[18]Chain-of-Thought Reasoning without Prompting:https://arxiv.org/pdf/2402.10200[19]Tree of Thoughts: Deliberate Problem Solving with Large Language Models :https://arxiv.org/pdf/2305.10601[20]Let's reward step by step: Step-Level reward model as the Navigators for Reasoning:https://arxiv.org/pdf/2310.10080[21]Dualformer: Controllable Fast and Slow Thinking by Learning with Randomized Reasoning Traces:https://arxiv.org/pdf/2410.09918[22]Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection:https://arxiv.org/abs/2310.11511[23]Deliberative alignment: reasoning enables safer language models :https://openai.com/index/deliberative-alignment/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









