




AI好似火焰。
近年来,我们在技术上取得了突破性进展。比如社交媒体、增强现实、平台转换如Web、移动设备等,不过,AI是一项更为重要的技术,它的意义堪比火种的发现,它有潜力改变我们物种进化的轨迹。
解锁AI潜力的“圣杯”之一就是构建能够像人类一样逻辑推理的系统。通过提升AI,尤其是大语言模型(LLM),可以分析复杂问题并应用逻辑步骤的能力。
Bagel的研究团队一直在探索这个问题。我们分析了LLM的构建技术,特别是微调技术,旨在让LLM从模式识别预测智能体发展成为真正的认知智能体。我们的深入研究涵盖了三种主要的逻辑推理类型,也就是智能:算术、常识和符号。
现在,我们想和大家分享研究成果。该研究针对的是我们认为AI进化最终目标的核心问题——人类级逻辑推理,甚至超越人类级逻辑推理(神级推理?)。
我们探索了模型开发中训练和微调阶段的技术,也探索了推理时阶段的逻辑推理,在这个阶段,LLM可以在推理过程中生成新的解决方案,即使这些解决方案并不包含在它们的训练数据集中。
1
逻辑推理类型
各种逻辑推理任务拓展了AI的能力。首先,让我们了解一下它们的定义。
算术逻辑推理促使机器学习以明确的方式测试问题解决能力。它迫使模型分解问题,选择多种策略,从而连接步骤以找到解决方案。这使得数学逻辑推理与其他不同。它清晰地展示了模型能在多大程度上掌握细节,并按正确的步骤使用解决方案。
常识逻辑推理颠覆了我们的预期。模型必须理解人们日常生活中奇怪的逻辑。当系统面对人类互动的怪癖时,挑战就出现了。我们理所当然的隐性规则,如门在你走进之前会打开;时间是向前流动的而非倒流的;水让物体变湿,这些显而易见的真理变成了AI系统必须解开的复杂难题。
符号逻辑推理打破了传统机器学习的模式。虽然神经网络在模糊模式匹配上表现出色,但符号要求精确。模型必须遵循严格的规则,操控抽象概念,链式逻辑推理。像一个严谨的数学家,而不是一个直觉艺术家。符号本身没有固有意义,但通过它们,我们建立起指向人类级逻辑推理的逻辑塔。
除了这些核心类型,逻辑推理还有多种形式。逻辑推理得出严格的结论,而归纳推理则进行创造性的跳跃。因果逻辑推理追踪行动与后果之间隐藏的线索。多模态逻辑推理在文本、图像和数据的复杂组合中进行理解。知识图谱则映射事实与关系之间的联系。然而,所有这些逻辑推理形式都服务于一个目标——将AI从模式匹配推动到真正的理解。从记忆的回应到新颖的见解,从预测到理解。
接下来,我们将探讨训练时间(training-time)和推理时间(Inference-time),以增强这些推理类型的能力。
1. 训练时间的策略
1.1 微调方法
-
参数高效微调(PEFT)
工作原理:PEFT颠覆了传统的模型适应方法(https://arxiv.org/abs/2304.01933)。通过四种方法揭示了新的技术。
基于提示的学习将可调信号嵌入到冻结(frozen)的模型中。前缀微调(Prefix-tuning)和P微调(P-tuning)引入了微小的变化。这些变化不会改变主体模型,但会改变输出结果。
重参数化方法,如LoRA简化复杂的权重矩阵将大规模更新转化为高效的低秩形式。LoRA通过最小的调整从高维空间中捕捉模式。
适配器创建额外的神经通路。串行适配器层层叠加,每一层逐步调整输出。并行适配器发展侧面技能,保持基础模型不变。
适配器的位置至关重要。串行适配器位于MLP层后面,并行适配器则在这些层内表现更好。LoRA涉及注意力层和MLP层。每种方法都瞄准正确的位置。
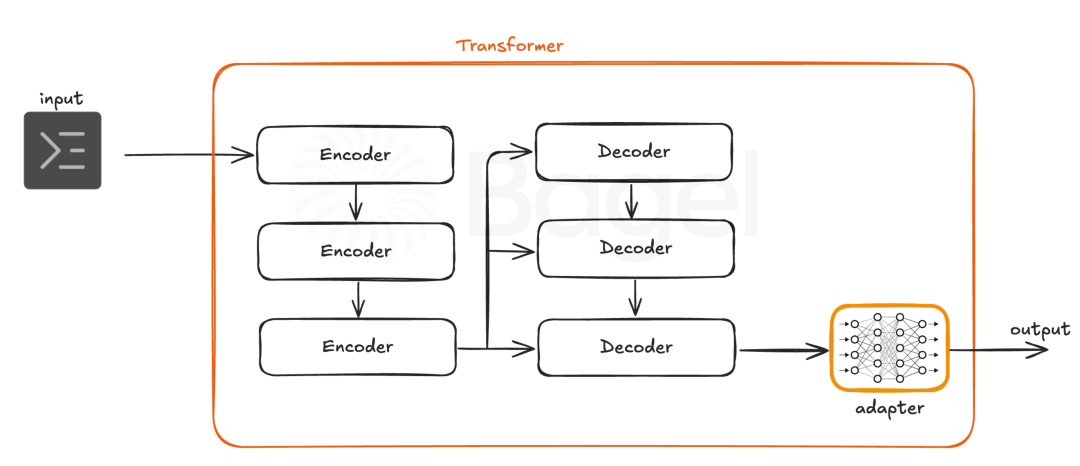
实用价值:PEFT减少了资源需求。大模型可以在不做重大改动的情况下获得新能力。PEFT在保留基础模型的同时增加了专业技能。原本在微调方面受限的硬件现在能够处理复杂的更新。
权衡取舍:并非所有任务都适合PEFT。有些模型需要更深入的变化,基础模型的限制仍然存在。结合不同方法可能会很复杂。PEFT在处理非常复杂的任务时可能会遇到困难。
-
WizardMath
工作原理:WizardMath通过三个不同的步骤进行学习(https://arxiv.org/abs/2308.0958
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1354
1354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









