



原标题:有想入坑RL-LLM的同学吗?强推曾经的TimeChamber,一个GPU够了
知乎:Flood Sung
链接:https://zhuanlan.zhihu.com/p/715131589
1 Why RL-LLM?
上图,David Silver 最新Talk里的两张ppt:
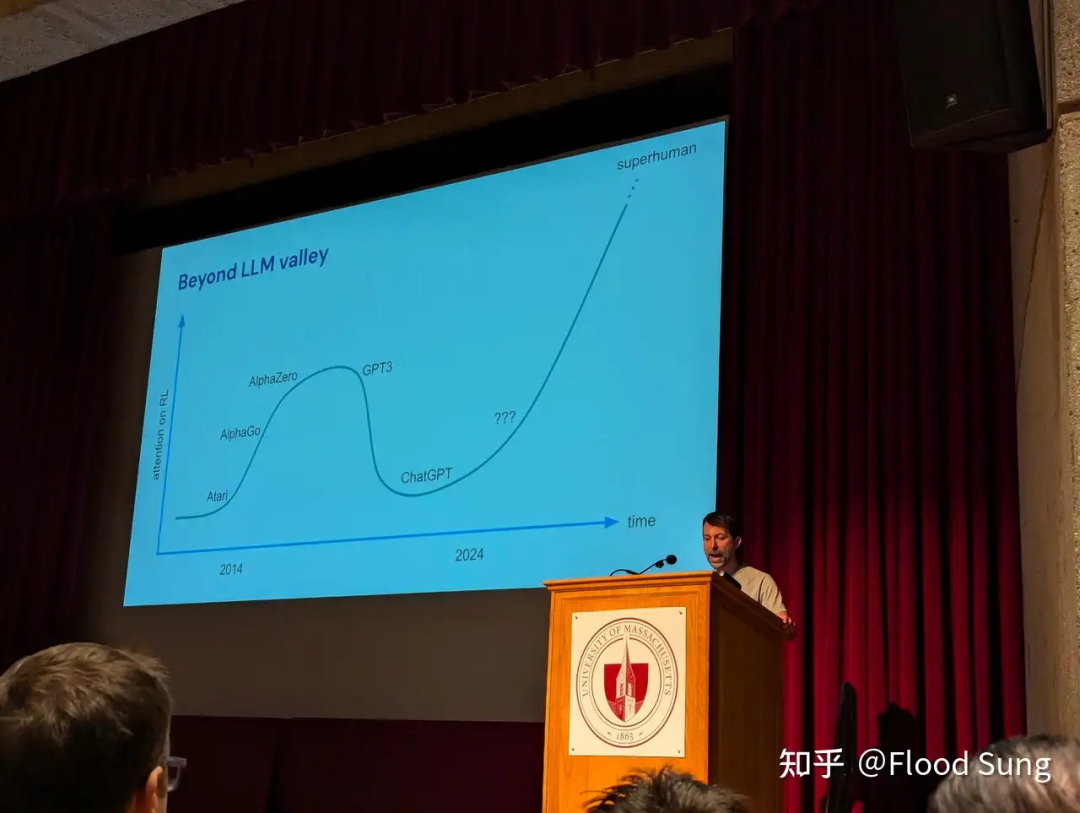

RL+LLM 就是AGI的未来!
那么问题来了,很多同学,特别是在校的同学,没有那么多的GPU,怎么来研究RL+LLM?
我算了一下,整个中国有上一代Game AI 做Large Scale RL 的经历和当前的大模型时代 做 Large Scale RL + LLM 经历的人屈指可数。具体情况是上一代Game AI 做Large Scale RL也就集中在启元世界,腾讯,字节,网易,超参数等有限的几个团队,这里面的同学还参与到大模型的就寥寥无几了。
所以,对于还在学校的同学,难道就只能看看当年的AlphaGo, AlphaStar,没法实操攒Large Scale RL经验吗?而这个经验对于RL+LLM 非常重要。为什么这么说?LLM只是换了更大的模型,更复杂的场景,但RL内核没有任何变化。所以,如果你对Large Scale RL 非常理解,那么迁移到LLM是很自然的事情。
然后,我就想到了之前在启元世界做physical based character animation 的时候开源了一个有意思的project:
https://github.com/inspirai/TimeChamber/tree/main/timechamber
这个project 研究的是控制虚拟机器人进行对战的事情,然后基于Nvidia的Isaac Gym, Isaac Gym 特别牛逼的点在于能够仅用1个GPU 就做超大规模的并行来训练机器人,所以,TimeChamber 是一个麻雀虽小,五脏俱全的Large Scale RL实现。
Isaac Gym 现在变成Isaac Lab,是当前最好的机器人模拟器,搞具身智能就用它,主要是前所未有的快呀。
https://developer.nvidia.com/isaac/sim#isaac-lab

2 TimeChamber 时光屋
当时取这个名字源自龙珠里的时光屋:

即AI 在里面修炼,外面一天,里面一年,然后就变得很强。
这个项目有完整的AlphaStar使用的PFSP/League:
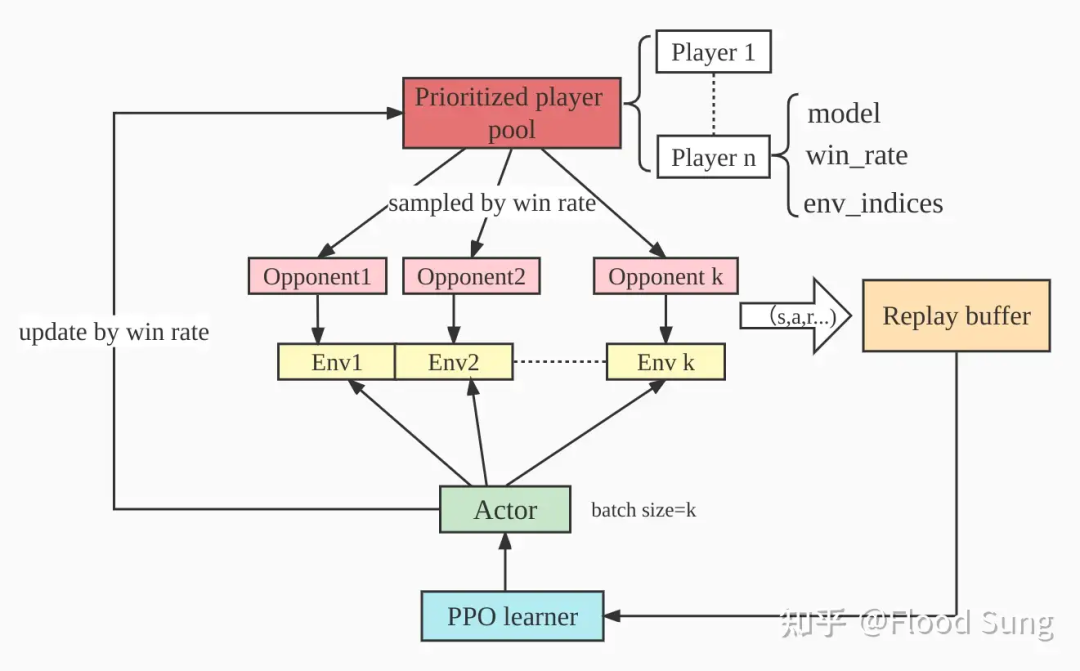
也就是我们会保持很多的对手模型,然后抓对厮杀做self-play.
Self-Play 恐怕是Large Scale RL最重要的概念了!
你可以设想一下在LLM做Self-Play的样子,非常美妙。当然,我们看到LMSYS出的chatbot arena已经成为了当前最重要的llm评估指标之一。
然后就是好玩的人形机器人格斗了:
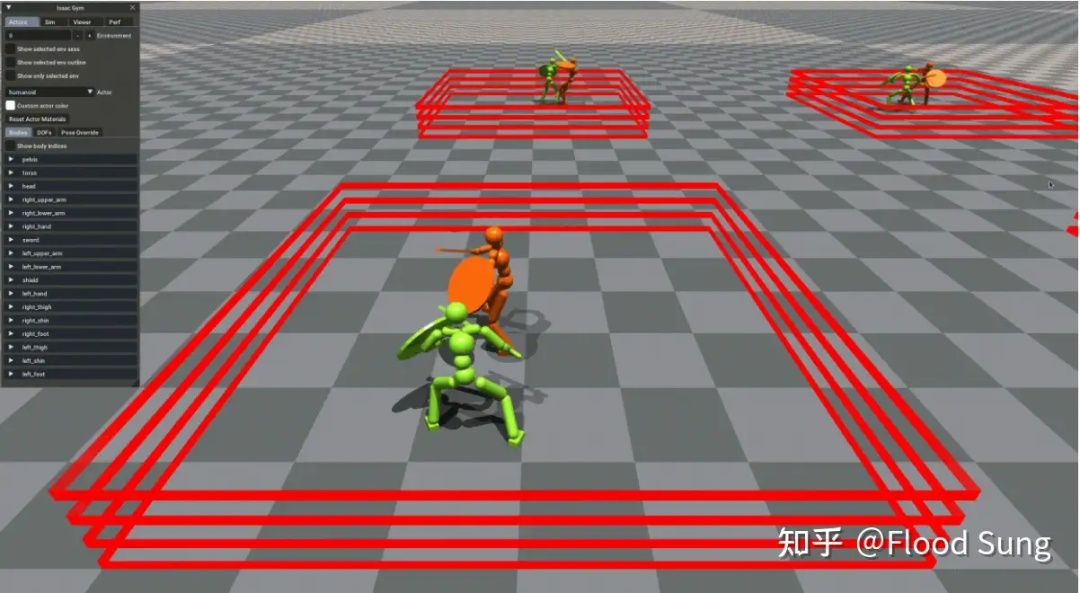
貌似到现在还是独一份。
这个机器人的控制器是Hierarchical分层的,顶层Policy做动作决策,而底层依赖于ASE训练的Policy输出具体动作。
由此,研究这份代码,你可以学习到的知识有:
-
PPO
-
PFSP
-
League/Self-Play/Population-based Training(PBT)
-
Multi-Agent Learning
-
ELO Rating
-
Hierarchical RL
-
ASE ( 机器人控制超牛逼的算法)
-
AMP (ASE基于AMP,想搞具身智能也OK)
-
Large Scale RL Training/Framework
-
Isaac Gym
-
Robot Learning
一个git包含这么多值得学习的内容,实在太超值了!只需要一个GPU,一次模拟4096个环境,80000+的FPS,太逆天了。
关键是好玩有木有!
当然,这个project的policy都比较小,还不是LLM,但如前面所说,掌握了它,再接入LLM是非常直接的。
3 小结
之所以写这个blog 重推这个project还是希望有越来越多的同学掌握RL的屠龙之术,这是AI的未来,是中国AGI的希望!

















 321
321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









