



1. Claude模型推出Prompt Cache
早在8月份,Anthropic的Claude模型 API 推出了提示缓存功能现( Prompt Cache) 已在Anthropic API上推出,Prompt Cache可以让开发者在调用API时,复用缓存的上下文,从而降低成本、降低延时。根据官方文档,号称可以降低90%的成本,85%的延迟。

今天这篇文章,我们来看看 Claude API 所使用的 Prompt Cache到底是何方神圣,能带来这么大的收益。
2. 为什么要提出Prompt Cache?
大语言模型应用开发者应该都有感觉,在具体应用中,往往会有大量的提示词可以被复用,比如:System Prompt、RAG中的文档(特别是长上下文)、提示词模板等。
正因为有这些可以被复用的提示词存在,Prompt Cache就有了其存在的价值。Prompt Cache正式利用了LLM提示词中的可复用部分,在内存中预算计算好,并在这些部分出现在提示词中时直接复用,从而降低延迟。
目前在单个提示请求服务中,常见的复用注意力状态( attention states)的方法是 KV-Cache。而Prompt Cache则是在KV-Cache的基础上,将注意力状态复用从单个提示请求扩展到了多个提示请求。
而跨提示复用注意力状态存在两方面问题:
-
• 1、由于 Transformer 中的位置编码,注意力状态是位置依赖的。所以,只有当文本段出现在相同位置时,其注意力状态才能被复用。
-
• 2、系统必须能够高效识别出其注意力状态可能已被缓存的文本段,以便复用。
3. Prompt Cache到底是个啥?
上面部分介绍了本篇论文作者引入Prompt Cache的背景,接下来,我们看看Prompt Cache到底是个啥?
为了解决上一部分中提出的两个问题,作者提出了两个思路:
-
• 1、运用“提示标记语言”(Prompt Markup Language,PML)使提示的接近结构化表达。PML 将可复用的文本段明确为模块,即“提示模块”。PML不仅可以已解决第二个问题,还为解决第一个问题开辟了途径,因为每个提示模块都能被赋予唯一的位置 ID。
-
• 2、LLM 能够对具有不连续位置 ID 的注意力状态进行操作。提取不同的注意力状态段并将它们拼接起来以形成意义的子集。让用户能够依照需求选择提示模块,甚至在运行时更新部分提示模块。
3.1 Prompt Cache 原理
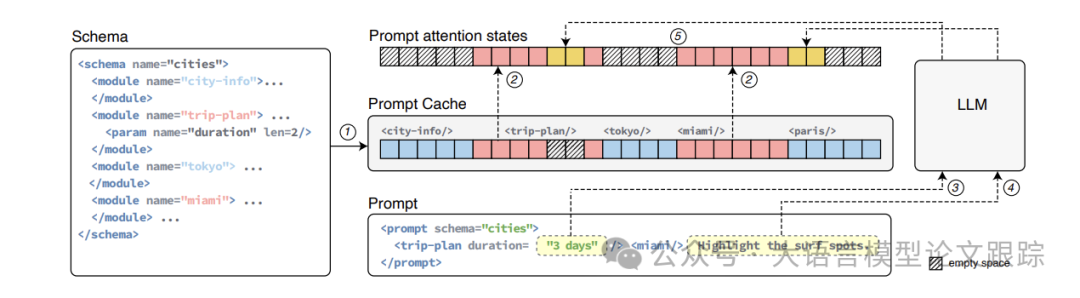
上图展示了Prompt Cache的提示词缓存复用原理:
-
• 首先,PML在模式和提示中明确了可重用的提示模块。提示模块中可以包含参数,比如行程规划模块里,可以包括持续时间这样的参数。
-
• 提示模块编码预先计算了模式中所有模块的注意力状态①,并将它们缓存起来以备使用。
-
• 当提示被调用时,提示缓存采用缓存推理:
-
• 检索已缓存的导入提示模块的注意力状态②
-
• 为参数③和新文本片段④计算注意力状态
-
• 最后将它们合并,生成整个提示的注意力状态⑤
-
这一步不仅解决最开始提出的第二个难题,还为解决第一个难题开辟了途径,因为每个提示模块都能被分配唯一的位置 ID。
另外,基于作者的经验发现,LLM 能够处理具有不连续位置 ID 的注意力状态。只要令牌的相对位置得以保留,输出质量就不会受到影响。这意味着能够提取不同的注意力状态段落,并将它们连接起来形成新的含义。利用这一点,使用户能够依据需求选择提示模块,甚至在运行时替换某些含义。
3.2 提示标记语言(PML)
Schema是定义提示模块并描述其相对位置和层次结构的文档。
每个Schema都有一个唯一的标识符(通过名称属性),并使用<module>标签指定提示模块。未被<module>标签包围或未指定标识符的文本被视为匿名提示模块,并始终包含在从该模式构建的提示中。
对于 LLM 用户,模式充当为提示模块创建和复用注意力状态
PML通过参数化提示模块,极大地提升了重用的可能性。
参数是具有特定长度的命名占位符,可以在模式中的提示模块中任意位置出现。通过<param>标签定义,标签中的name和len属性分别指定了参数的名称和最大令牌数。当提示导入该模块时,可以为参数指定一个值。
正如前面的图中所提到的,一个参数化的提示模块(如行程规划)和提示如何包含该模块并为其参数(例如持续时间)提供值(如3天)。
增强值不会进行缓存。参数化提示模块有两个关键用途:
-
• 首先,当一个提示模块与另一个模块只在某些明确定义的地方有所不同时,参数允许用户在运行时提供特定参数来定制模块,同时还能享受重用的好处。图2通过行程规划示例说明了这一点,这对于模板化提示尤其有用。
-
• 其次,参数可以在模式中的提示模块的开头或结尾创建一个“缓冲区”,允许用户在提示中添加任意文本段,只要这段文本不超过它所替代的参数的令牌长度。
4. 效果评估
效果评估这里,作者主要验证以下三个问题:
-
• 1、Prompt Cache 对首次令牌生成时间(TTFT)延迟和输出质量有何影响 ?
-
• 2、Prompt Cache 内存存储开销如何 ?
-
• 3、哪些应用适合采用提示缓存(§5.6)。
以常规的 KV 缓存作为基线。提示缓存和 KV 缓存除了注意力状态计算环节不同,其余推理流程完全相同。通过比较 TTFT 延迟来进行评估,因为提示缓存和 KV 缓存在生成首个令牌后的解码延迟相同,而 TTFT 延迟衡量的是生成首个令牌所需的时间。
3.1 评估环境
在两种 CPU 配置上对提示缓存进行评估:
-
• 英特尔 i9-13900K,搭配 128GB DDR5 RAM,速度达 5600 MT/s;
-
• AMD Ryzen 9 7950X,搭配 128GB DDR4 RAM,速度为 3600 MT/s。
针对 GPU 基准测试,部署了三块 NVIDIA GPU:
-
• 与英特尔 i9-13900K 配对的 RTX 4090
-
• 在 NCSA Delta 上托管的虚拟节点 A40 和 A100,它们各自配备了 16 核 AMD EPIC 7763 和 224GB RAM。
选用多个开源大型语言模型(LLM),包括 Llama2、CodeLlama、MPT 和 Falcon。
使用 LongBench 套件来评估 TTFT 的改进情况和输出质量的变化。LongBench 涵盖了从 4K 到 10K 上下文长度的精选子样本,包含来自 6 个类别、21 个数据集的摘录,涉及多文档问答、摘要和代码完成等任务。将 LongBench 数据集中的文档,比如维基页面和新闻文章,定义为提示模块。把特定任务的指令当作未缓存的用户文本。
3.2 基准数据集上的延迟改进
3.2.1 GPU推理延迟测试
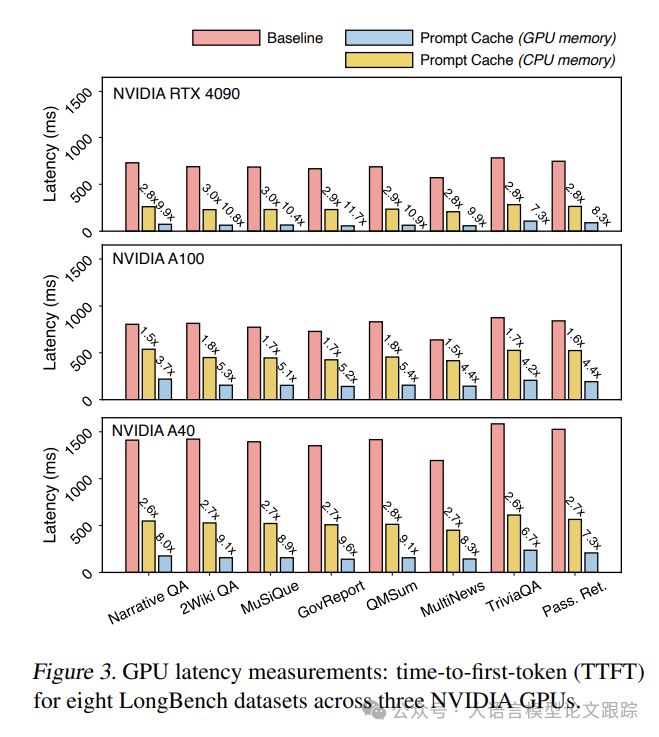
在 GPU 评估中,采用了两种内存设置:将提示模块存储在 CPU 或 GPU 内存中。黄色条代表从 CPU 内存加载提示模块,蓝色条则表示在 GPU 内存中的情况。由于 LongBench 样本的长度相近,平均为 5K 令牌,所以各数据集呈现出一致的延迟趋势。
无论是使用CPU还是GPU内存,所有数据集和GPU上的TTFT延迟都显著减少,CPU内存下减少1.5至3倍,GPU内存下减少5至10倍。
使用提示缓存可能实现的延迟减少的最大和最小范围。实际的延迟减少幅度将根据使用内存类型的多少而有所不同。
3.2.2 CPU 推理延迟
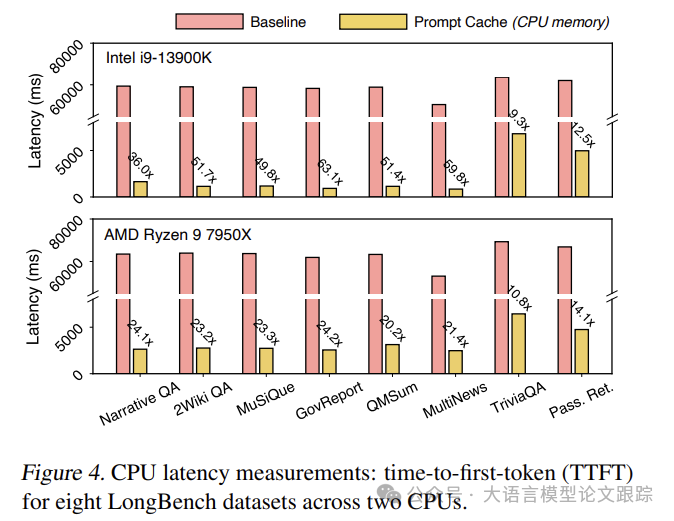
上图展示了 Prompt Cache在Intel和AMD CPU上分别实现了高达70倍和20倍的延迟降低。这种差异可能源于系统内存带宽的不同(Intel CPU配备了5600MT/s的DDR5 RAM,而AMD CPU则使用了3600MT/s的DDR4 RAM)。
正如所料,对于那些未缓存提示比例较高的数据集,例如TriviaQA,延迟表现得更为明显。值得注意的是,与GPU推理相比,CPU推理从Prompt Cache中获得了更显著的性能提升。主要是因为CPU在进行注意力计算时的延迟较大,尤其是在处理较长序列时(例如,与GPU相比,其FP16/FP32浮点运算性能较低)。
Prompt Cache在资源受限的环境中,如边缘设备或GPU资源受限的云服务器上,对于优化推理性能尤为有效。
3.3 Prompt Cache对准确性的影响
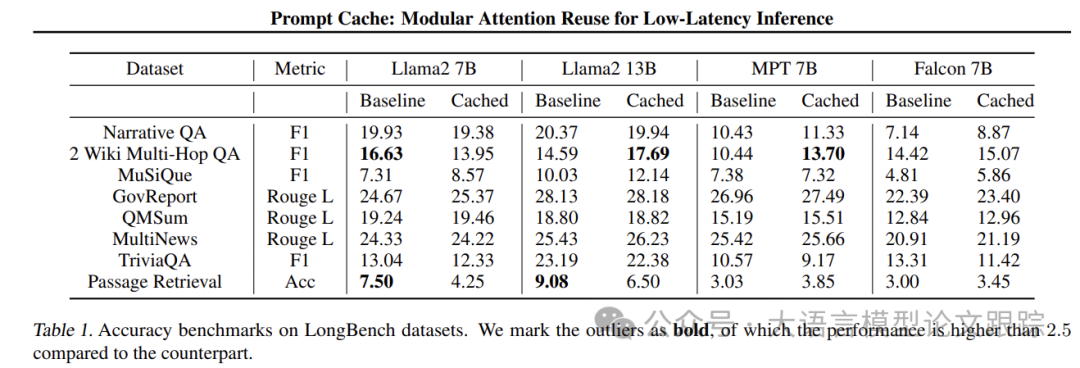
将Prompt Cache应用于三种不同transformers架构的LLM:Llama2、MPT和Falcon。上表展示了准确度基准测试结果,Prompt Cache能够维持输出的精确性。
采用确定性采样策略,即每一步都选取概率最高的令牌,确保有无提示缓存的测试结果具有可比性。在所有数据集上,使用提示缓存的输出准确度与基准线保持一致。
3.4 理解延迟改进
理论上,Prompt Cache相较于常规KV缓存,在TTFT延迟上应展现出平方级的降低。
原因是:Prompt Cache的内存复制开销随序列长度线性增长,而自注意力计算的复杂度却与序列长度呈二次方关系。
为验证这一理论,对一个包含不同序列长度的合成数据集进行了测试,测试中假设所有提示均已缓存。利用Intel i9-13900K CPU和两款GPU(NVIDIA RTX 4090和A40),搭载Llama2 7B模型,对比了提示缓存与常规KV缓存的TTFT延迟。测试结果显示,无论是CPU还是GPU,使用CPU内存存储提示模块时,提示缓存的延迟优势随着序列长度的增加而呈平方级扩大。
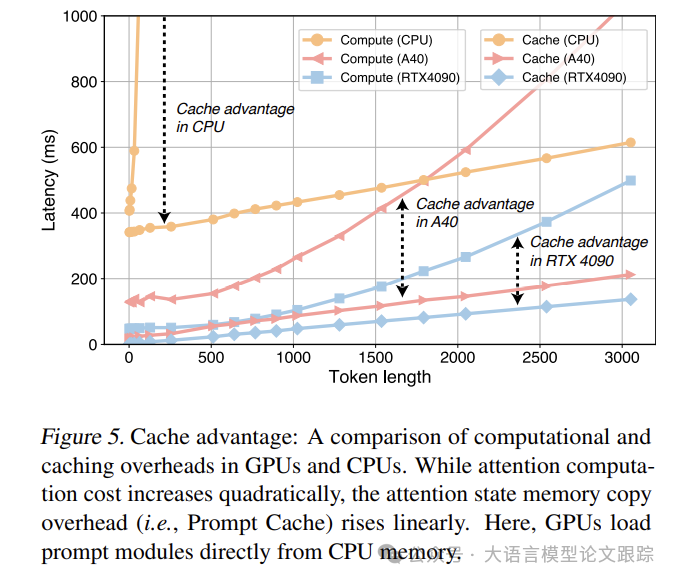
如上图,KV缓存的延迟随序列长度呈二次方增长,而提示缓存的内存复制成本则线性增长。表明提示缓存的延迟优势随着序列长度的增加而显著扩大,尤其在CPU上更为明显,因为CPU在注意力计算上的延迟更高,而提示缓存的开销,无论是GPU中的主机到设备内存复制,还是CPU中的主机到主机内存复制,差异并不显著。
此外,随着模型参数规模的增长,KV缓存的计算负担也随之增加。
例如,从7B模型升级到13B模型,在3K令牌长度下,延迟增加了220毫秒,而提示缓存仅增加了30毫秒。这是因为LLM的复杂度也随着隐藏维度的增加而呈二次方增长。以注意力计算的FLOPS为例,其计算公式为6nd^2 + 4nd,用于预填充操作。这表明提示缓存相对于KV缓存的优势,随着模型规模的增长而呈二次方扩大。
在端到端延迟方面,由于提示缓存仅减少TTFT,随着生成令牌数量的增加,其对完整LLM响应所需时间的影响逐渐减小。
例如,在RTX 4090上使用Llama 7B模型处理3K上下文时,提示缓存将TTFT从900毫秒缩短至90毫秒,而令牌生成时间或TTST在KV缓存和提示缓存之间保持一致,平均每令牌32毫秒,不受令牌长度影响。
尽管如此,更快的响应时间对于提升用户体验和整体端到端延迟具有积极作用。例如,提示缓存将TTFT从900毫秒缩短至90毫秒,意味着在同一时间段内可以生成额外25个令牌。
此外,提示缓存还允许在同一批次内共享注意力状态。根据工作负载特性,提示缓存可以通过利用减少的内存占用来实现更大的批次大小,从而提高整体吞吐量。
例如,如果有100个请求,每个请求包含2K令牌的提示,且所有提示共享相同的1K令牌模块,那么提示缓存结合分页注意力等方法,可以将内存占用减少50%,允许更大的工作批次大小,从而提高吞吐量。
3.5 内存使用情况
提示缓存所需的内存开销与缓存的令牌总数成比例关系。
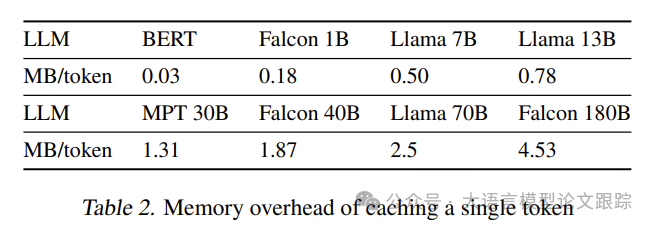
如上表所示,在假设采用16位浮点数精度的前提下,每个令牌的内存开销。
以Falcon 1B这类轻量级模型为例,缓存一个包含1K令牌的文档大约需要180MB的内存。
若存在数百个提示模块,总内存消耗可能达到数十GB,这在服务器级GPU的内存容量范围内。
然而,对于Llama 70B这样的大型模型,缓存一个1K长度的模块每个文档将占用高达2.5GB的内存,这使得CPU内存成为存储提示模块的唯一可行选择。
基于这些考量,未来在提示缓存技术的研究中,注意力状态的压缩方法仍然是一个值得探索的领域。
来源 | 大语言模型论文综述

















 913
913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









