




传统的注意力机制由于时间和空间复杂度的二次方增长,以及在生成过程中键值缓存的内存消耗不断增加,限制了模型处理长文本的能力。相关的解决方案包括减少计算复杂度、改进记忆选择和引入检索增强语言建模。
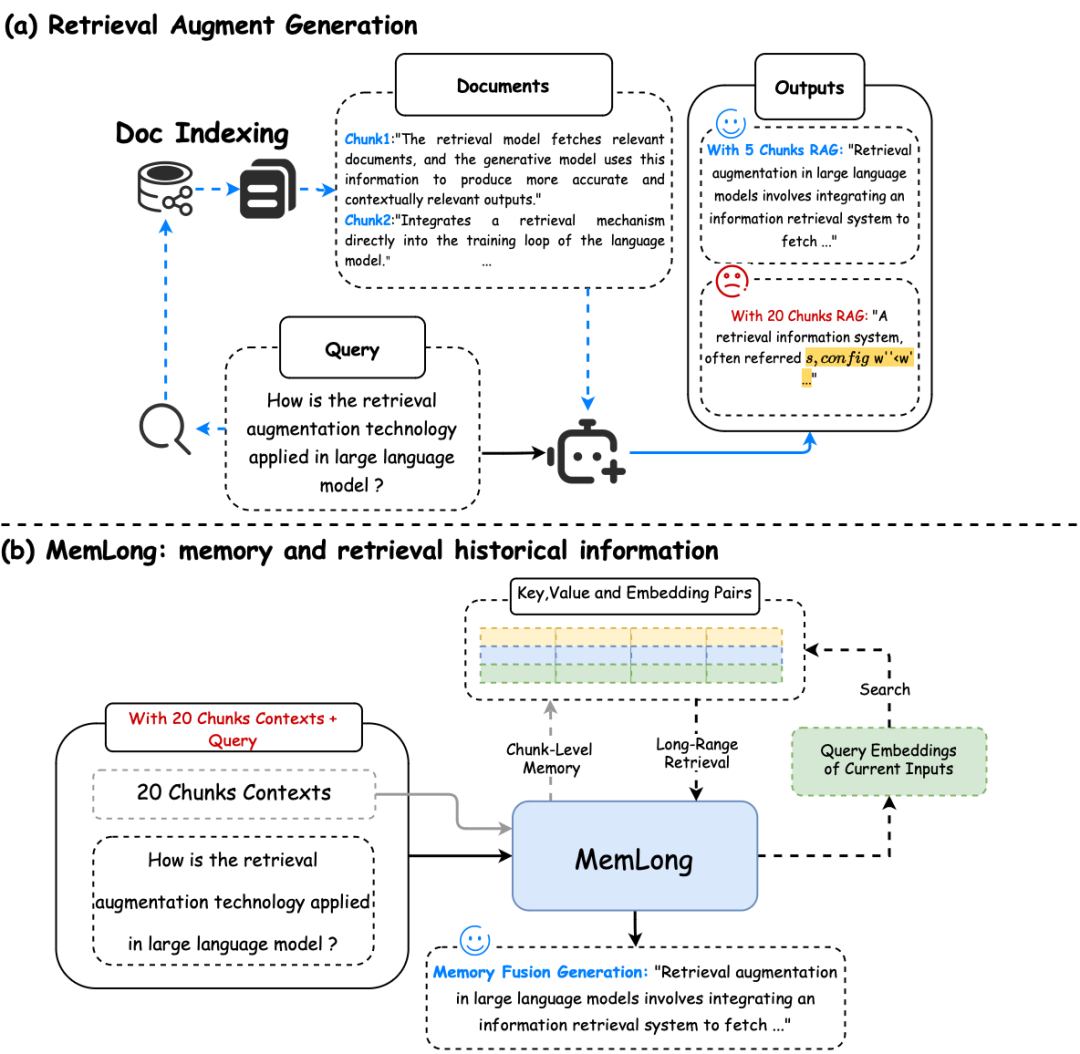
检索增强生成(RAG)和MemLong的记忆检索流程。 (a) 当检索到的信息长度超过模型的处理能力时,RAG甚至可能会降低生成性能(黄色)(b) MemLong利用外部检索器来获取历史信息,然后将这些信息以键值对(K-V)的形式而不是文本形式传递给模型。
提出一种新方案MemLong,结合一个非可微分的检索-记忆模块和一个部分可训练的解码器语言模型,来增强长文本上下文的语言建模能力。
MemLong利用外部检索器来检索历史信息,并通过细粒度、可控的检索注意力机制,将语义级别的相关信息块整合到模型中。这种方法不仅提高了模型处理长文本的能力,还保持了信息分布的一致性,避免了训练过程中的分布偏移问题。
MemLong的一个示例:在底层,模型保持静态,对整个数据块Ci进行因果语言建模,随后,Ci被缓存为嵌入和键值对(K-V)形式。最后,上层进行微调,以协调检索偏好并整合检索到的内容。
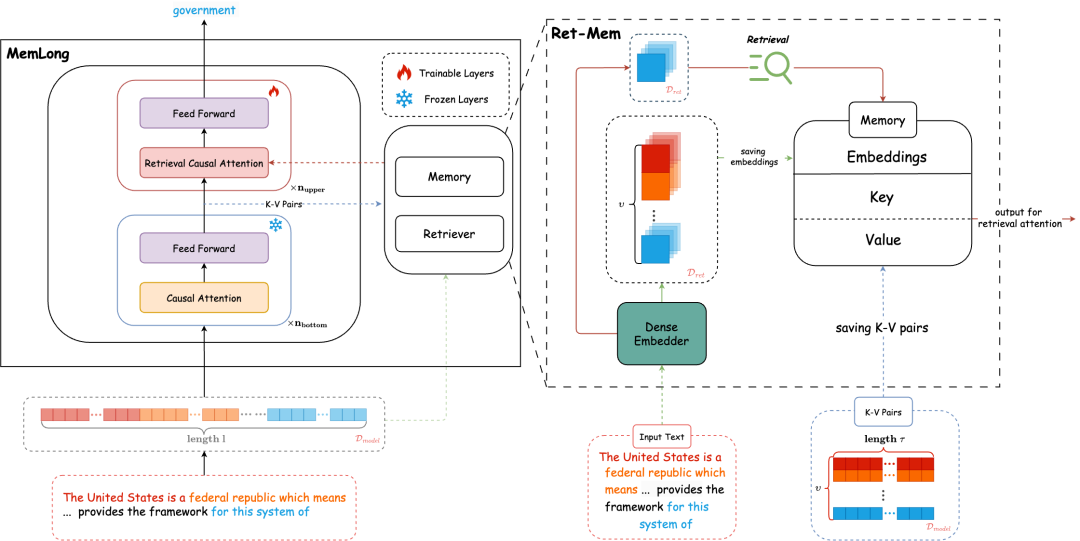
MemLong的核心原理包括以下几个方面:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 983
983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









