




1. GMeLLo 提出的背景
1.1 多跳问答
多跳问答的难度往往比较大,因为不仅要追溯事实,还要聚合与串联事实。
事实的来源可以是知识图谱、表格、自由格式文本,或者是这些来源的异构组合。
随着大型语言模型的发展,基于提示的方法搭配可选的检索模块已成为处理多跳问答的常用手段,但以往多数工作侧重于静态信息库。
1.2 知识编辑
知识编辑目前有两种主流方案:修改模型参数和保留模型参数。
1.2.1 修改模型参数
可进一步细分为元学习和定位-编辑方法。
-
• 元学习方法(meta-learning):利用超网络来学习编辑大型语言模型所需的调整。
-
• 定位-然后-编辑(locate-then-edit)范例,首先识别与特定知识对应的参数,然后通过直接更新目标参数来进行修改。
2.2.2 保留模型参数
在保留模型参数的情况下,主要方法是引入额外的参数或外部存储器。
-
• 额外参数范式( additional parameters ):将额外的可训练参数纳入语言模型。这些参数在修改后的知识数据集上进行训练,而原始模型参数保持不变。
-
• 基于存储器的模型(memory-based models):将所有编辑的示例存储在存储器中,并使用检索器为每个新输入提取相关的编辑事实,从而引导模型生成编辑后的输出。
2. GMeLLo
基于以上背景,作者提出了 GMeLLo (Graph Memory-based Editing for Large Language Models)方法,通过整合大语言模型和知识图谱(Knowgledge Graph),解决知识编辑后的多跳问答任务。
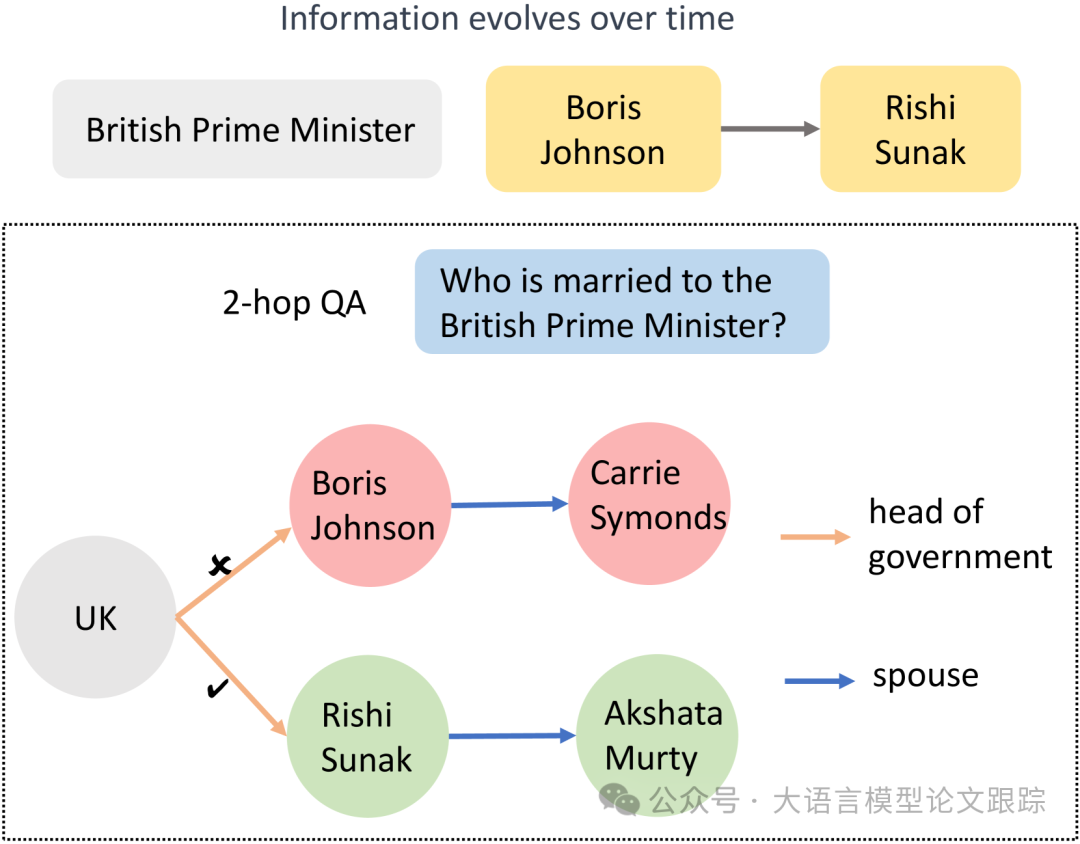
如上图,在更新了有关英国首相的信息后,显然相应的配偶信息也应予以修改。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









