




开源,就要开的彻彻底底。
这不,Meta一连放出三篇技术文章,从大模型适配方法出发,介绍了:
如何使用特定领域数据微调LLM,如何确定微调适配自己的用例,以及如何管理良好训练数据集的经验法则。
接下来,直接进入正题。
01
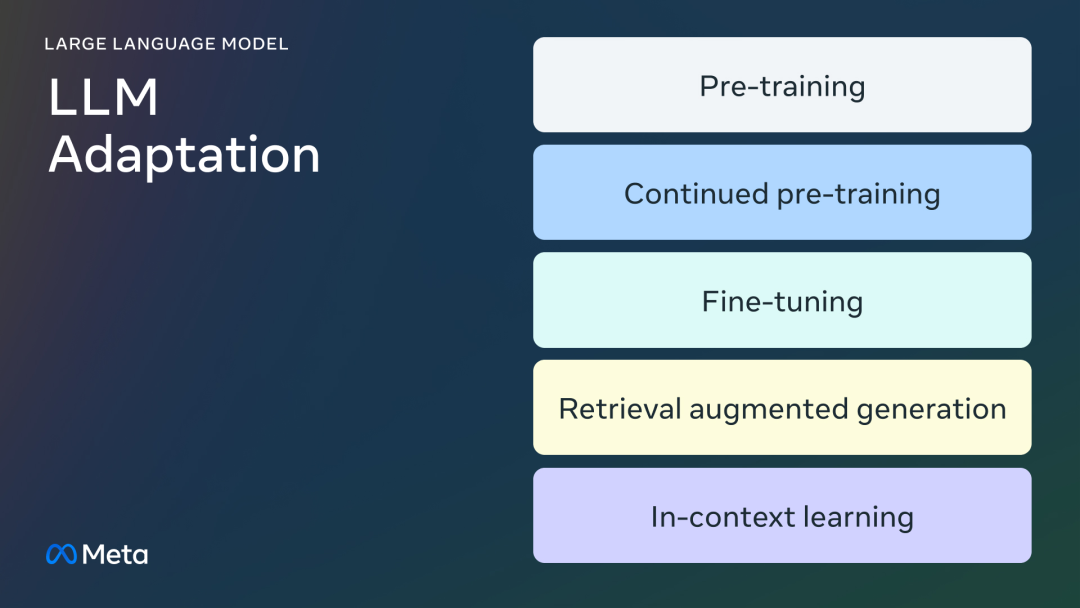
适配大模型
预训练
预训练是指,使用数万亿个token数据,从头开始训练LLM的过程,通常使用自监督算法进行训练。
最常见的情况是,训练通过自回归预测下一个token(也称为因果语言建模)。
预训练通常需要数千个GPU小时(105-107个),并分布在多个GPU上进行。
预训练的输出模型称为「基础模型」。
继续预训练
继续预训练(也称为第二阶段预训练)将使用全新的、未见过的领域数据进一步训练基础模型。
这里,同样使用与初始预训练相同的自监督算法。
通常会涉及所有模型权重,并将一部分原始数据与新数据混合。
微调
微调是以监督方式使用带注释的数据,或使用基于强化学习的技术,来适配预训练语言模型的过程。
与预训练相比,微调有两个主要区别:
- 在包含正确标签/答案/偏好的注释数据集上进行监督训练,而不是自监督训练
- 需要较少的token(数千或数百万,而不是预训练中需要的数十亿或数万亿),其主要目的是提高能力,如指令遵循、人类对齐、任务执行等。
而要了解微调的现状,可以从两个方面入手:参数变化的百分比和微调后新增的能力。
更改的参数百分比
根据更改的参数量,有两类算法:
- 全面微调:顾名思义,这包括更改模型的所有参数,包括在XLMR和BERT(100-300M参数)等小模型上所做的传统微调,以及对Llama 2、GPT3(1B+参数)等大模型上的微调。
- 参数高效微调(PEFT):PEFT算法只微调少量额外参数,或更新预训练参数的子集,通常是总参数的1%-6%,而不是对所有LLM权重进行离线微调。
基础模型新增的能力
微调的目的是为了向预训练的模型添加功能,比如指令遵循、人类对齐等。
聊天微调Llama 2,就是一个具有附加指令遵循和对齐能力的微调模型的例子。
检索增强生成(RAG)
企业还可以通过添加特定领域的知识库来适配LLM,RAG是典型的「搜索驱动的LLM文本生成」。
RAG于2020年推出,它使用动态提示上下文,通过用户问题检索并注入LLM提示,以引导其使用检索到的内容,而不是预训练的知识。
Chat LangChain是由RAG支持的、在Lang Chain文档上流行的Q/A聊天机器人。
上下文学习(ICL)
对于ICL,通过在提示符中放置原型示例来适配LLM。多项研究表明,「举一反三」是有效的。这些示例可以包含不同类型的信息:
- 仅输入和输出文本,也就是少样本学习
- 推理追踪:添加中间推理步骤,可参阅思维链(COT)提示
- 计划和反思追踪:添加信息,教LLM计划和反思其解决问题的策略,可参阅ReACT
02
选择正确的适配方法
要决定上述哪种方法适合特定应用,你应该考虑各种因素:所追求
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1812
1812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









