



读取文本文件
1. 读取txt文件
代码:
data_txt = pd.read_csv('Data/meal_order_info.txt') #文件路径
print(data_txt)
结果:
info_id emp_id number_consumers mode dining_table_id dining_table_name expenditure dishes_count accounts_payable use_start_time check_closed lock_time cashier_id pc_id order_number org_id print_doc_bill_num lock_table_info order_status phone name
0 417 1442 4 1501 1022 165 5 165 "2016/8/1 11:0...
1 301 1095 3 1430 1031 321 6 321 "2016/8/1 11:1...
2 413 1147 6 1488 1009 854 15 854 "2016/8/1 12:...
3 415 1166 4 1502 1023 466 10 466 "2016/8/1 12:...
4 392 1094 10 1499 1020 704 24 704 "2016/8/1 12...
.. ...
sep=’ ’ 的作用:将元素之间用空格进行隔开
data_txt = pd.read_csv('Data/meal_order_info.txt', sep=' ')
print(data_txt)
info_id emp_id number_consumers ... order_status phone name
0 417 1442 4 ... 1 18688880641 苗宇怡
1 301 1095 3 ... 1 18688880174 赵颖
2 413 1147 6 ... 1 18688880276 徐毅凡
3 415 1166 4 ... 1 18688880231 张大鹏
4 392 1094 10 ... 1 18688880173 孙熙凯
.. ... ... ... ... ... ... ...
2. 读取csv文件
代码:
data_csv = pd.read_csv('Data/meal_order_info.csv', encoding='GBK', header=None) # 元素之间用空格隔开
print(data_csv)
"""
header参数是用来指定列名的,如果是None则会添加一个默认的列名
报错:UnicodeDecodeError:
'utf-8' codec can't decode byte 0xc3 in position 401: invalid continuation byte
读取:用存储文件的编码方式去解码才能正常进python内存里面
默认的encoding='utf-8',有时候中文并不是用utf-8去解码的,所以要用其他的:GBK...
"""
结果:
0 1 2 ... 18 19 20
0 info_id emp_id number_consumers ... order_status phone name
1 417 1442 4 ... 1 18688880641 苗宇怡
2 301 1095 3 ... 1 18688880174 赵颖
3 413 1147 6 ... 1 18688880276 徐毅凡
4 415 1166 4 ... 1 18688880231 张大鹏
.. ... ... ... ... ... ... ...
3. 读取excel文件:read_excel()函数来读取xls,xlsx文件
data_excel = pd.read_excel('Data/meal_order_detail.xlsx', sheet_name=1)
print(data_excel)
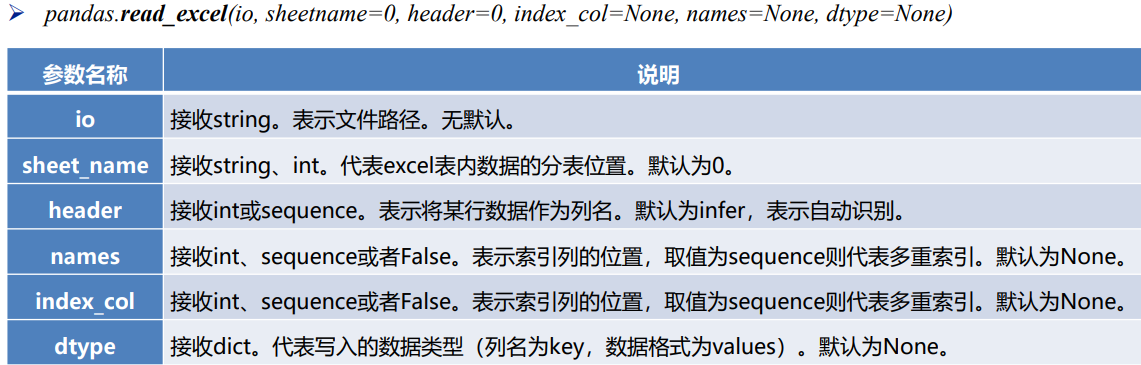
3. 文本文件读取
➢ sep参数是指定文本的分隔符的,如果分隔符指定错误,在读取数据的时候,每一行数据将连成一片。
➢ header参数是用来指定列名的,如果是None则会添加一个默认的列名。
➢ encoding代表文件的编码格式,常用的编码有utf-8、utf-16、gbk、gb2312、gb18030等。如果编码指定错误数据将无法读取,IPython解释器会报解析错误。
文本文件储存
1. 将数据框存储为文本文件:
to_csv()方法,前面要跟具体的数据框对象
data_csv.to_csv('DataSave/meal_order_info.csv', index=None, header=None)
"""
data_csv:表示需要存储的文件对象;
DataSave/meal_order_info.csv:表示存储的路径和文件名;
原来的数据框里面可能有默认的行列标号,通过index(行),header(列)参数去掉
index=None
header=None
"""
2. Excel文件储存
DataFrame.to_excel(excel_writer=None, sheetname=None’, na_rep=”, header=True, index=True,
index_label=None, mode=’w’, encoding=None)```
to_csv方法的常用参数基本一致,区别之处在于指定存储文件的文件路径参数名称为excel_writer,并且
没有sep参数,增加了一个sheetnames参数用来指定存储的Excel sheet的名称,默认为sheet1。


















 2047
2047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











