




近年来,随着大模型(LLMs)逐步登上舞台,许多研究人员都在探索如何让它们更好地处理长上下文内容,特别是在那些需要大量知识支撑的任务中。然而,事实证明,单纯增加模型的上下文长度并不是万能的。因此,如何高效地利用这些模型的推理能力成为了一个亟待解决的问题。
什么是检索增强生成(RAG)?
检索增强生成(RAG)是一种通过引入外部知识来提升语言模型生成效果的方法。简单来说,它不仅依赖模型内部的知识,还会从外部资源中检索到相关信息,这样生成的内容就更有针对性、更有深度。
研究的核心问题
这篇论文研究主要集中在两个问题上:
-
如何通过优化推理计算来提升RAG的性能? 换句话说,如果我们聪明地分配计算资源,那么是否能让模型表现得更好?
-
能否预测出在给定计算资源的情况下,哪些配置能带来最好的效果? 这就好比在预算有限的情况下,怎么才能让花出去的钱带来最大的价值。
关键策略:让推理过程更高效
为了让推理变得更智能,研究者提出了两种新策略:
-
基于演示的RAG(DRAG): 这是一种通过给模型提供多个示例作为参考,让它更好地理解问题并生成回答的方法。就像给学生多做几道类似的题目,以便他们在考试中能举一反三。
-
迭代演示RAG(IterDRAG): 这种方法更进一步,它将复杂的问题拆解成多个小问题,逐步解决,并在每一步中引入新的信息。这类似于解决一个大难题时,先把它拆成若干个小问题,一步一步地推进。
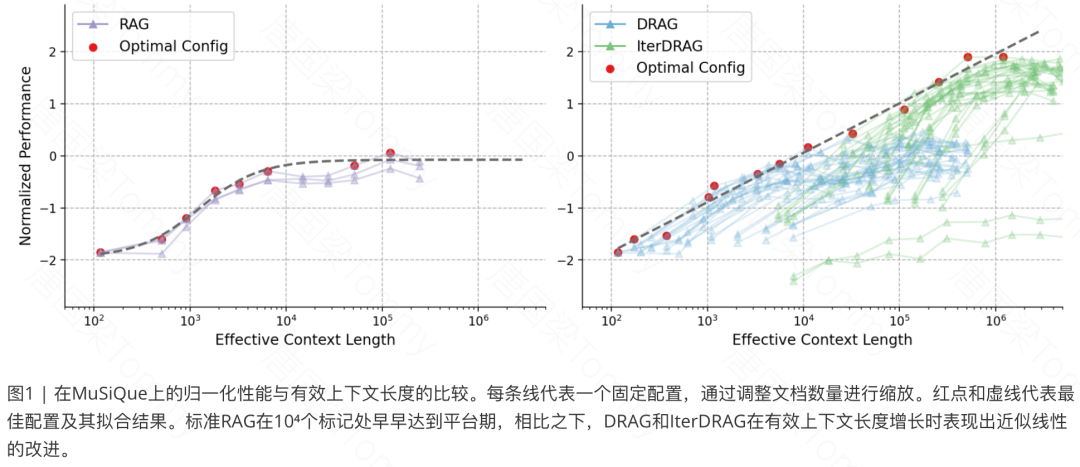
通过实验结果,表明在推理计算合理分配的情况下,长上下文RAG性能可以与计算预算的增大呈近似线性增长。
策略一:基于演示的RAG(DRAG)
-
工作原理:利用上下文学习,通过直接从扩展的输入上下文中生成答案来利用长上下文LLMs的能力。
-
实现方法:通过在输入提示中整合文档和上下文示例,并对文档进行排序,将排名更高的文档靠近查询放置。
-
改进之处:DRAG策略结合了多种上下文示例,使长上下文LLMs能够从丰富的输入上下文中提取相关信息并回答复杂问题。

策略二:迭代演示RAG(IterDRAG)
-
挑战与动机:多跳查询仍然因组合性差距而面临挑战,IterDRAG通过将复杂查询分解为更简单的子查询来解决这一问题。
-
工作流程:每个子查询执行检索以获取额外的上下文信息,然后将其与初始答案结合生成最终答案。
-
执行细节:迭代过程中会多次调用LLM,直到生成最终答案或达到最大迭代次数。
-
优势:IterDRAG通过分解查询和检索相关信息来回答子查询,缩小了组合性差距,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4154
4154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









