



目录
前置知识
TCP与HTTP
TCP是传输层的协议,HTTP是应用层的协议,HTTP基于TCP。
BIO和NIO
stream和channel
stream不会自动缓冲数据,channel会利用系统提供的发送缓冲区、接收缓冲区(更为底层)
stream仅支持阻塞api,channel都支持
二者均为全双工,即读写可以同时进行。
区别
BIO(Blocking I/O)和NIO(Non-blocking I/O)是两种不同的I/O模型
BIO :是一种阻塞式的I/O模型。在这种模型中,当一个线程执行I/O操作时,它会一直等待,直到I/O操作完成。这意味着线程在等待I/O操作完成期间不能做其他事情,因此是“阻塞”的。
NIO :是一种非阻塞式的I/O模型。在这种模型中,线程在执行I/O操作时不会被阻塞,而是可以继续执行其他任务。NIO模型通常使用选择器(Selector)来管理多个通道(Channel),并通过事件驱动的方式来处理I/O操作(多路复用)。
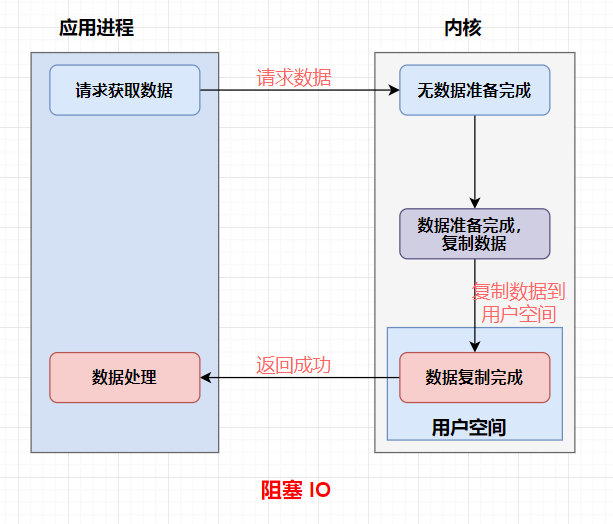
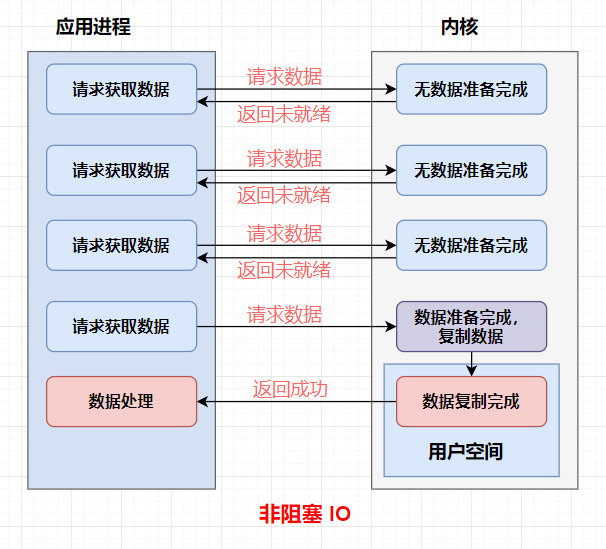
总结:
BIO 线程在执行 I/O 操作(如读取请求、写入响应read()/write())时会被阻塞,直到操作完成。
NIO 线程通过事件驱动机制轮询多个通道的 I/O 就绪状态,仅处理实际可读/可写的操作,避免空闲等待。
BIO 适用于连接数较少、I/O操作频繁的场景,简单易用但资源消耗较大。
NIO 适用于高并发、连接数较多的场景,资源消耗较小但实现相对复杂。
| 特性 | BIO (Blocking I/O) | NIO (Non-blocking I/O) |
|---|---|---|
| 阻塞点 | I/O 操作(如 read()/write()) | 无阻塞,通过 Selector 轮询事件 |
| 线程模型 | 1 线程 = 1 连接 | 1 线程管理多连接(多路复用) |
| 编程复杂度 | 简单(线性逻辑) | 复杂(需事件循环、状态管理) |
| 适用场景 | 低并发、长耗时 I/O | 高并发、短耗时 I/O(如即时请求) |
| 资源消耗 | 高(线程数随连接数增长) | 低(固定少量线程) |
| 典型应用 | 传统文件服务器、简单 HTTP 服务 | 高性能网关(Netty)、实时通信系统 |
NIO
三大组件
Channel&Buffer
双向数据传输的通道,java基础学的io流是单向的,要么输入流要么输出流。Buffer数据缓存区(在内存中)。
Selector
- 一次链接就安排一个线程:内存占用高,线程上下文切换时间长,所以只适合链接少的场景
- 线程池控制线程数:阻塞模式下,线程仅能处理一个socket连接,即使啥事没干也要处理完之后再处理下一个socket,所有仅适合短连接场景(一般http就是短连接)
- selector:配合一个线程管理多个channel,获取这些channel上发生的事件,这些channel工作在非阻塞模式下,不会让线程吊死在一个channel上,适合连接数特别多但流量低的场景(low traffic读写操作少)

ByteBuffer
基本使用
初始的10字节大小的buffer:

写入四个字节后:

切换为读模式:

代码实现
//获取输入输出流的channel
try (FileChannel channel = new FileInputStream("cloudAlibaba-commons/myFile.txt").getChannel()) {
//使用allocate方法获取buffer实例,5为缓冲区大小(字节)
ByteBuffer buffer = ByteBuffer.allocate(5);
while (true){
//buffer默认为写模式,从channel读出来往buffer里写数据,read方法的返回值表示实际读到的字节数,如果返回-1表示已经读完channel了
int read = channel.read(buffer);
if(read == -1){
break;
}
//切换为读模式
buffer.flip();
while (buffer.hasRemaining()){
byte b = buffer.get();
System.out.println((char) b);
}
//切换为写模式
buffer.clear();
}
} catch (IOException e) {
throw new RuntimeException(e);
}常用api
| 方法名 | 描述 | 示例 |
|---|---|---|
allocate(int capacity) | 分配一个新的字节缓冲区,容量为 capacity。 | ByteBuffer buffer = ByteBuffer.allocate(10); |
allocateDirect(int capacity) | 分配一个新的直接字节缓冲区,容量为 capacity。直接使用操作系统的内存,速度更快,不受GC影响。 | ByteBuffer buffer = ByteBuffer.allocateDirect(10); |
get() | 从当前位置读取一个字节,并增加location。 | byte b = buffer.get(); |
put(byte b) | 在当前位置写入一个字节,并增加location。 | buffer.put((byte) 10); |
get(int index) | 从指定位置读取一个字节,不改变location。 | byte b = buffer.get(2); |
put(int index, byte b) | 在指定位置写入一个字节,不改变location。 | buffer.put(2, (byte) 20); |
get(byte[] dst) | 从当前位置读取多个字节到目标数组中,并增加location。 | byte[] dst = new byte[3]; buffer.get(dst); |
put(byte[] src) | 从当前位置写入多个字节,并增加location。 | byte[] src = {1, 2, 3}; buffer.put(src); |
mark() | 设置当前location为标记位置。 | buffer.mark(); |
reset() | 将location重置为之前标记的位置。 | buffer.reset(); |
flip() | 将缓冲区从写模式切换到读模式,将limit设置为当前位置,然后将位置重置为0。 | buffer.flip(); |
rewind() | 将location重置为0,并丢弃标记。 | buffer.rewind(); |
clear() | 切换到写模式,清空缓冲区,将位置设置为0,将limit设置为容量,并丢弃标记。 | buffer.clear(); |
compact() | 切换为写模式,压缩缓冲区,将未读取的数据移动到缓冲区的开头,并将location设置为未读取数据的末尾。 | buffer.compact(); |
hasRemaining() | 判断当前location和limit之间是否还有元素。 | boolean hasRemaining = buffer.hasRemaining(); |
remaining() | 返回当前位置和限制之间的元素数量。 | int remaining = buffer.remaining(); |
粘包、半包
网络传输的数据用/n分隔,但由于某种原因这些数据在接收时,被进行了重新组合,例如原始数据有3条为 Hello,world\n
I'm zhangsan\n
How are you?\n
变成了下面的两个 byteBuffer(粘包,半包),第一个包和第二个包粘在一起了,第三个包被分成两半了 Hello,world\nI'm zhangsan\nHo w are you?\n
Selector
多路复用:
也就是单线程可以配合selector完成对多个channel读写事件的监听
多路复用仅针对网络io,普通文件io没法多路复用
监听channel的四种事件
accept - 会在有连接请求时触发
connect - 是客户端连接建立后触发
read - 可读事件
write - 可写事件
selector模型中一般专门安排一个selector负责建立连接(boss),多个selector处理读写事件(worker)
selector demo
public static void main(String[] args) throws IOException {
Thread.currentThread().setName("boss");
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);
//创建专门用来建立连接的boss selector
Selector boss = Selector.open();
//绑定key,监听请求连接的事件
SelectionKey bossKey = ssc.register(boss, SelectionKey.OP_ACCEPT, null);
ssc.bind(new InetSocketAddress(8080));
//创建固定数量的worker一般和cpu核心数相等
Worker worker = new Worker("worker-01");
//worker-02
//.........
while (true) {
// select方法,没有事件发生,线程阻塞,有事件,线程才会恢复运行
//select方法在事件未处理时它不会阻塞(因为没处理所以继续放行去处理),所以事件发生之后要么处理,要么取消(cancel),不能置之不理
boss.select();
Iterator<SelectionKey> iter = boss.selectedKeys().iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
iter.remove();
//判断是不是连接请求
if (key.isAcceptable()) {
SocketChannel sc = ssc.accept();
sc.configureBlocking(false);
//初始化selector,启动worker-01
worker.register(sc);
}
}
}
}
/**
* worker类
*/
static class Worker implements Runnable {
private Thread thread;
private Selector selector;//还未初始化
private String name;
private boolean start = true;
private ConcurrentLinkedQueue<Runnable> queue = new ConcurrentLinkedQueue<>();
public Worker(String name) {
this.name = name;
}
//初始化线程和selector
public void register(SocketChannel sc) throws IOException {
if (!start) {
thread = new Thread(this, name);
thread.start();
selector = Selector.open();
}
//向队列添加的任务,没有立即执行
queue.add(() -> {
try {
//关联worker的selector
sc.register(selector, SelectionKey.OP_READ, null);
} catch (ClosedChannelException e) {
throw new RuntimeException(e);
}
});
selector.wakeup();//唤醒select方法
}
@Override
public void run() {
while (true) {
try {
selector.select();
Runnable task = queue.poll();
if(task != null){
task.run();//执行了sc.register(selector, SelectionKey.OP_READ, null),这样一来这段逻辑就一定在selector.select();之后执行了
}
Iterator<SelectionKey> iter = selector.selectedKeys().iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
iter.remove();
//读事件
if (key.isReadable()) {
//创建16字节大小的buffer
ByteBuffer buffer = ByteBuffer.allocate(16);
SocketChannel channel = (SocketChannel) key.channel();
channel.read(buffer);
buffer.flip();
}
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}Netty
是一个异步的(指调用的异步,不是指异步的io)、基于事件驱动(使用selector多路复用)的网络应用框架,用于快速开发可维护、高性能的网络服务器和客户端。
是一个基于NIO的框架,好处是不需要自己构建协议,解决了TCP传输问题,如粘包半包。解决了NIO的一些bug,如某些情况epoll空轮询导致cpu100%。对API进行了增强。

hello world
server:
//创建一个默认的线程组,默认的线程数是CPU核数*2
DefaultEventLoopGroup myExecutors = new DefaultEventLoopGroup();
//1.启动器,负责组装netty组件,启动服务器
new ServerBootstrap()
//2.第一个是BossEventLoop,只负责ServerSocketChannel上的accept事件,第二个是WorkerEventLoop,只负责socketChannel上的io
.group(new NioEventLoopGroup(),new NioEventLoopGroup())
//3.选择服务器ServerSocketChannel实现,NIO还是BIO
.channel(NioServerSocketChannel.class)
//4.告诉worker(就是这里的child)要执行哪些逻辑(handler)
.childHandler(
// 5.channel 代表和客户端进行数据读写的通道 Initializer是初始化器的意思,负责添加别的handler
new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
//6. 添加具体handler
ch.pipeline().addLast(new ObjectDecoder());//解码,将ByteBuf转换为字符串
ch.pipeline().addLast(new ObjectEncoder());//编码,将字符串编码为ByteBuf
//自定义handler,指定线程组为最开始创建的myExecutors,如果不手动指定则默认使用.group()第二个参数指定的worker->NioEventLoopGroup
ch.pipeline().addLast(myExecutors,"name",new ChannelInboundHandlerAdapter(){
//读事件
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
//打印上一步转换好的字符串
System.out.println(msg);
//channelRead会将msg传给pipeline上的下一个handler
// super.channelRead(ctx, msg + "asd");
super.channelRead(ctx, BenqResult.success(new TestUser(1,"user1")));
}
});
//自定义handler
ch.pipeline().addLast("name2",new ChannelInboundHandlerAdapter(){
//读事件
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
System.out.println(msg);
// ch.writeAndFlush(ctx.alloc().buffer().writeBytes("server...".getBytes()));
ch.writeAndFlush(BenqResult.success(new TestUser(2,"user2")));
}
});
// ch.pipeline().addLast(new ChannelOutboundHandlerAdapter(){
// @Override
// public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
// System.out.println("出站handler。。。。");
// super.write(ctx, msg, promise);
// }
// });
}
})
//7. 绑定监听端口
.bind(8080);client:
//1.启动类
new Bootstrap()
//2.BossEventLoop,WorkerEventLoop(loop包含selector+thread)组
.group(new NioEventLoopGroup())
//3.选择客户端channel实现
.channel(NioSocketChannel.class)
//4.添加处理器
.handler(new ChannelInitializer<NioSocketChannel>() {
//在建立连接之后调用的方法
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ch.pipeline().addLast(new ObjectDecoder());//转为ByteBuf
ch.pipeline().addLast(new ObjectEncoder());
ch.pipeline().addLast(new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
System.out.println(msg);
super.channelRead(ctx, msg);
}
});
}
})
//5.连接到服务器
.connect(new InetSocketAddress("localhost",8080))
.sync()
.channel()
//6.向服务端发送内容
.writeAndFlush("hello world");Netty组件
EventLoop(事件循环)
本质是一个单线程执行器(同时维护了一个Selector),里面有run方法处理Channel上源源不断的io事件
-
每个
EventLoop绑定固定线程,避免多线程竞争锁和上下文切换,提高吞吐量。 -
如果每个
Channel独占线程,高并发时线程数爆炸(类似传统 BIO 模型)。
EventLoopGroup就是一组EventLoop,channel一般会调用EventLoopGroup的register方法来绑定其中一个EventLoop,后续这个Channel上的io事件都由此EventLoop来处理(保证io的线程安全),但是此EventLoop还能继续绑定其他channel。所有绑定到同一个 EventLoop 的 Channel,它们的 I/O 事件(如 channelRead、write)和非IO事件会由该 EventLoop 线程 按顺序依次处理,不会并发执行。所以所有耗时操作(无论是否 I/O)都应异步化,保持 EventLoop 仅处理轻量级任务。
bossEventLoopGroup只负责建立连接,所以通常安排一个线程也就是一个eventLoop就够了
new EventLoopGroup()若不指定线程数,则默认为cpu核心数*2
细化分工
1、boss和worker
new ServerBootstrap()
//2.第一个是BossEventLoop,只负责ServerSocketChannel上的accept事件,第二个是WorkerEventLoop,只负责socketChannel上的io
.group(new NioEventLoopGroup(),new NioEventLoopGroup())2、指定某个handler由某个eventLoopGroup执行
往pipeline添加handler时,第一个参数指定eventLoopGroup
ch.pipeline().addLast(myExecutors,"name",new ChannelInboundHandlerAdapter(){ //自定义handler
//读事件
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
//打印上一步转换好的字符串
System.out.println(msg);
super.channelRead(ctx, msg);
}
});ChannelFuture
客户端中BootStrap启动类建立连接的返回值实际上就是一个ChannelFuture,它代表的大概是一个建立连接任务的异步对象,使用这个异步任务对象调用sync()方法就表示等connect异步任务完成之后再接着执行后面的内容。
//connect是一个异步非阻塞方法
.connect(new InetSocketAddress("localhost",8080))//ChannelFuture
channelFuture.sync().channel()//.channel()获取连接建立后的channel对象
.writeAndFlush("hello world");;Future&Promise
和jdk Future之间的关系,Promise继承于netty Future继承于jdk Future
netty Future相较于jdk Future能异步等待结果
netty Pormise脱离了任务独立存在,只作为两个线程间传递结果的容器
EventLoop eventLoop = new NioEventLoopGroup().next();
//主动创建promise结果容器
DefaultPromise<Integer> promise = new DefaultPromise<>(eventLoop);
//创建线程任务
new Thread(() -> {
try {
int i = 222;
int b = 1/0;
//往promise填充结果
promise.setSuccess(i);
} catch (Exception e) {
//往promise填充结果
promise.setFailure(e);
}
}).start();
//从promise获取任务中填充地结果,无论是否有异常都能获取到
System.out.println(promise.get());两个Future都是任务的返回结果,而promis像一个参数一个结果容器,能在任务执行的过程中动态灵活地设置结果。
pipeline
如之前说到的,pipeline可以理解为流水线,handler们是流水线上的一道道工序

addlist就是往流水线的双向链表倒数第二个位置加上一道工序(handler),最后一道工序是默认的tail工序所以是加到倒数第二。
入站handler和出站handler
即ChannelInboundHandlerAdapter和ChannelOutboundHandlerAdapter
入站handler的super.channelRead(ctx,msg)是用于唤醒pipeline中的下一个入站handler,依次唤醒就能让pipeline中的handler一个个执行了
入站handler的ch.writeAndFlush(ctx.alloc().buffer().writeBytes("server...".getBytes()));之类的写操作会触发出站handler,从流水线的尾部开始往前寻找出站handler来执行。也可以使用ctx.writeAndFlush()来写,但是ctx的写操作的方法是从当前handler往前找出站handler而不是尾部了。下图为使用ch来进行写操作时的流程。

Bytebuf
是java中ByteBuffer的增强类。
相对于ByteBuffer的优点:
- Bytebuf能自动扩容
- 不需要手动管理
position、limit和capacity等指针,提供了读写指针(readerIndex和writerIndex)不用读写模式切换来切换去了,不容易出错。 - 可以使用堆外内存(
DirectByteBuf) - API更加简洁好用
- 池化的
ByteBuf能重复利用ByteBuf,有高效的内存分配方法,可以显著减少内存分配和 GC 的开销。
零拷贝-slice:不复制内存地将一个bytebuf逻辑上分为两个buf,实际上还是原来那块内存,两个buf有自己独立的读指针和写指针。
零拷贝-composite:不复制内存地将两个bytebuf和成一个buf
这两个零拷贝api在release释放资源时都会把原内存的整个buf release掉,需要注意
黏包半包
原因
TCP是使用字节流的形式来传输数据的,没有消息的边界,所以一次接受多了就黏包了,一次接受少了就半包了
Netty解决方法
使用基于长度字段的帧解码器LengthFieldBasedFrameDecoder约定帧读取长度
构造方法5个字段的含义
maxFrameLength:帧的最大字节长度
lengthFieldOffset:长度字段偏移量,如果是0就表示没有偏移第一个字节开始就表示消息的长度,如果是1就表示第一个字节用来表示其他信息,第二个字节开始才表示消息本体的长度。
lengthFieldLength:长度字段的长度,也就是花费几个字节来表示消息本体长度
lengthAdjustment:长度字段的后面还有几个字节才表示消息本体的内容,如果为2就表示长度字段和消息字段之间还有2个字节表示额外内容
initialBytesToStrip:解码完之后剥离几个字节,比如你前三个字节是长度字段后面的才是消息字段,你想要解码完之后只取消息部分,你就可以设这个字段为3把前三个字段剥离。
例子:

LengthFieldBasedFrameDecoder在接受到一帧后如果发现长度没有达到长度字段表示的长度就不会传给后续的handler所以就避免了半包,反之如果帧超过了长度字段表示的长短就只读这么长就可以避免黏包了。

















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









