




 研究发现深度神经网络最后一层的信息瓶颈导致弱监督语义分割中定位图仅关注目标对象的小区域。为解决此问题,提出去除最后一层激活函数和采用新池化方法,从而提高定位图质量,实现更好的弱监督语义分割效果。实验结果显示这种方法在PASCALVOC2012和MSCOCO2014数据集上取得最新最优性能。
研究发现深度神经网络最后一层的信息瓶颈导致弱监督语义分割中定位图仅关注目标对象的小区域。为解决此问题,提出去除最后一层激活函数和采用新池化方法,从而提高定位图质量,实现更好的弱监督语义分割效果。实验结果显示这种方法在PASCALVOC2012和MSCOCO2014数据集上取得最新最优性能。
0.摘要
弱监督语义分割通过类别标签生成像素级定位,然而,使用这些标签训练的分类器往往只关注目标对象的小的可区分区域。我们使用信息瓶颈原理解释了这一现象:深度神经网络的最后一层通过sigmoid或softmax激活函数引起了信息瓶颈,结果只有任务相关信息的子集传递到输出层。我们首先通过一个模拟的玩具实验支持了这一论点,然后提出了一种通过去除最后一个激活函数来减小信息瓶颈的方法。此外,我们引入了一种新的池化方法,进一步鼓励从非判别区域传递信息到分类器。我们的实验评估表明,这个简单的修改显著提高了在PASCAL VOC 2012和MS COCO 2014数据集上的定位图质量,展示出了弱监督语义分割的最新最优性能。代码可在以下链接中找到:GitHub - jbeomlee93/RIB: Reducing Information Bottleneck for Weakly Supervised Semantic Segmentation (NeurIPS 2021)
1.引言
语义分割是使用像素级分配的语义标签来识别图像中的对象的任务。深度神经网络(DNNs)的发展在语义分割方面取得了重大进展。训练语义分割的DNN需要包含大量带有像素级标签的图像的数据集。然而,准备这样的数据集需要相当大的努力;例如,在Cityscapes数据集中为单个图像生成像素级注释需要超过90分钟的时间。通过弱监督学习可以减轻对像素级标签的高度依赖。
弱监督语义分割的目标是使用较弱的注释训练分割网络,这些注释提供的关于目标对象位置的信息比像素级标签要少,但获取成本更低。弱监督的形式可以是涂鸦(scribbles)、边界框(bounding boxes)或图像级别的类别标签。在本研究中,我们专注于图像级别的类别标签,因为它们是弱监督中成本最低且最流行的选项。大多数使用类别标签的方法会利用来自训练好的分类器(如CAM或Grad-CAM)得到的定位(归因)图生成伪造的真值,用于训练分割网络。然而,这些图仅识别目标对象在分类中起区分作用的小区域,并不能识别整个目标对象所占的区域,使得这些归因图不适合用于训练语义分割网络。我们使用信息瓶颈原理解释了这一现象。
信息瓶颈理论分析了顺序DNN层中的信息流动:输入信息在通过DNN的每一层时被尽可能地压缩,同时尽可能地保留任务相关的信息。这对于获得分类的最佳表示是有优势的,但对于将得到的分类器的归因图应用于弱监督语义分割时则是不利的。信息瓶颈阻止目标对象的非判别信息被考虑在分类逻辑中,因此归因图只关注目标对象的小的判别区域。
我们认为信息瓶颈在DNN的最后一层变得突出,是因为在该层中使用了双向饱和激活函数(例如sigmoid,softmax)。我们提出了一种方法,在DNN的最后一层重新训练时去除最后一个激活函数,从而减小信息瓶颈。此外,我们引入了一种新的池化方法,允许在DNN的最后一层中处理更多嵌入在非判别特征中的信息,而不是判别特征。因此,我们的方法所得到的分类器的归因图包含了更多关于目标对象的信息。
本研究的主要贡献总结如下。首先,我们强调信息瓶颈主要发生在DNN的最后一层,这导致从训练好的分类器得到的归因图仅限于目标对象的小的判别区域。其次,我们提出了一种通过简单修改现有的训练方案来减小这种信息瓶颈的方法。第三,我们的方法显著提高了从训练好的分类器中得到的定位图的质量,在弱监督语义分割的PASCAL VOC 2012和MS COCO 2014数据集上展现出了最新的性能水平。
2.预先准备工作
2.1.信息瓶颈
给定两个随机变量X和Y,互信息I(X; Y)量化了这两个变量之间的相互依赖关系。数据处理不等式(DPI)[13]推断出满足马尔可夫链X → Y → Z的任意三个变量X,Y和Z的互信息满足I(X; Y) ≥ I(X; Z)。DNN中的每一层只处理来自前一层的输入,这意味着DNN层形成了一个马尔可夫链。因此,通过这些层的信息流可以用DPI来表示。具体来说,当一个L层的DNN通过中间特征Tl (1 ≤ l ≤ L)从给定的输入X生成输出Yˆ时,它形成了一个马尔可夫链X → T1 → · · · → TL → Yˆ,并且相应的DPI链可以表示如下: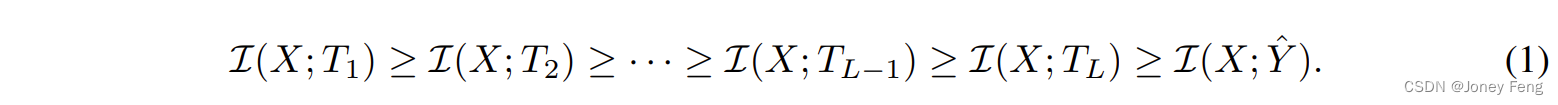
这意味着输入X的信息在通过DNN的层时被压缩。 训练分类网络可以被解释为提取输入的最大压缩特征,这些特征保留了尽可能多的信息以用于分类;这些特征通常被称为最小充分特征(即判别性信息)。最小充分特征(即最优表示T∗)可以通过互信息I(X; T)和I(T; Y)之间的信息瓶颈权衡来获得(压缩和分类)[54, 15]。换句话说,T∗ = argminT I(X; T) − βI(T; Y),其中β≥0是拉格朗日乘子。 Shwartz-Ziv等人观察到在找到最优表示T∗的过程中存在一个压缩阶段:当固定l时,观察到的I(X, Tl)在最初的几个时期稳定增加,但在后期时期减少[49]。Saxe等人认为压缩阶段主要出现在配备双向饱和非线性函数(例如tanh和sigmoid)的DNN中,而在配备单向饱和非线性函数(例如ReLU)的DNN中则不会出现[46]。这意味着相比于配备双向饱和非线性函数的DNN,配备单向饱和非线性函数的DNN经历了更少的信息瓶颈。这也可以从双向饱和非线性函数的梯度饱和性来理解:梯度与某个值以上的输入相关时,梯度饱和接近于零[8]。因此,在反向传播过程中,超过某个值的特征将具有接近零的梯度,并受到限制,不能进一步为分类做出贡献。
2.2.类激活图
类激活图(CAM)[66]识别分类器关注的图像区域。CAM基于一个卷积神经网络,在最终分类层之前使用全局平均池化(GAP)。这是通过考虑最后一个特征图的每个通道对分类得分的类特定贡献来实现的。给定一个由
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 863
863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









