




原视频链接:attention
一. 基本问题分析
1. 模型的input
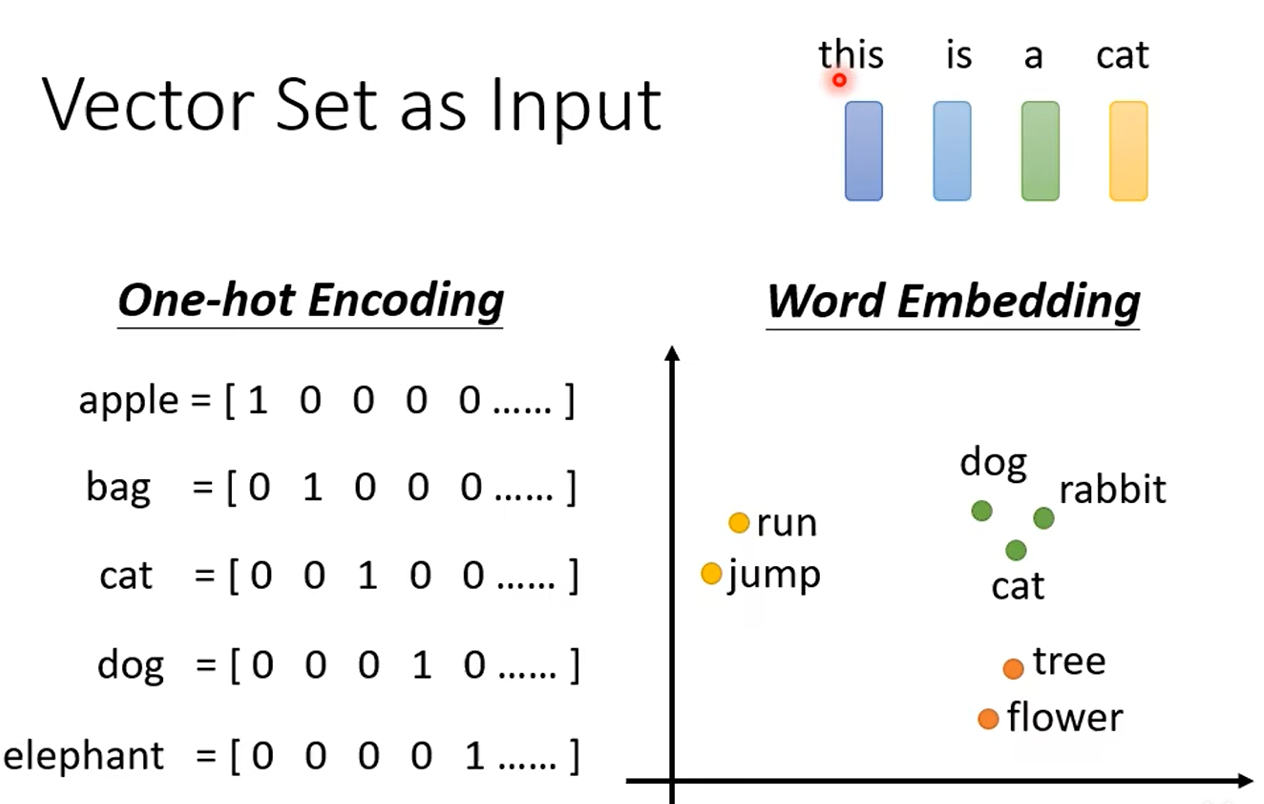
无论是预测视频观看人数还是图像处理,输入都可以看作是一个向量,输出是一个数值或类别。然而,若输入是一系列向量,长度可能会不同,例如把句子里的单词都描述为向量,那么模型的输入就是一个向量集合,并且每个向量的大小都不一样。解决这个问题的方法是One-hot Encoding以及Word Embedding,其中Word Embedding更能考虑到相似向量的语义信息,如下所示:
2. 模型的output
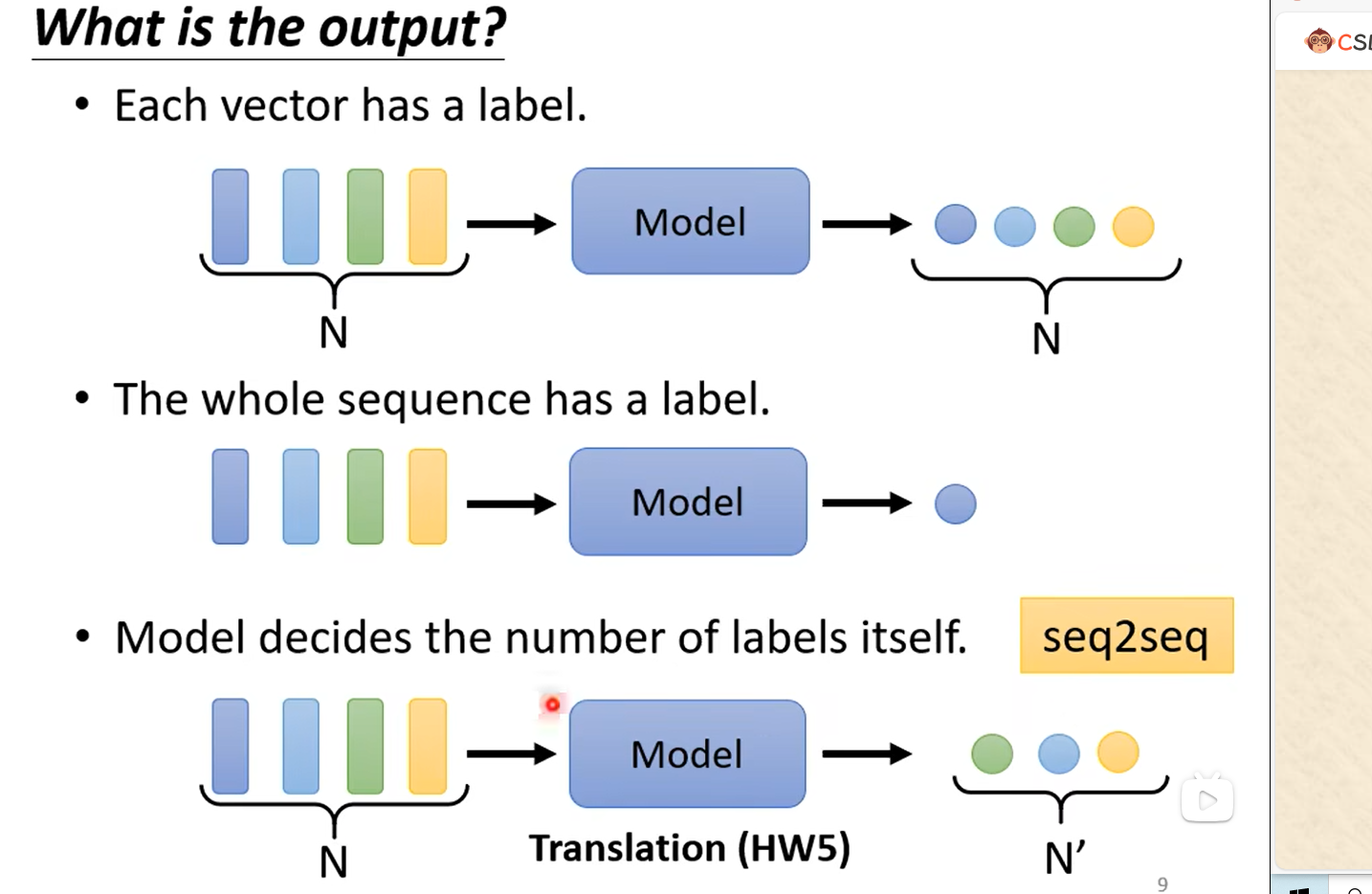
输出可以是每个vector都产生个对应的label,即N to N。如:在社交网络中,推荐某个用户商品(这个用户可能会买或者不买);
也可以是N to 1。如:情感分析,给出一句话this is good,输出positive;反之给出另一段消极的话输出negative;
也可以是N to M。如:翻译工作,翻译到另一个语言可能和原语言单词长度不一样
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









