




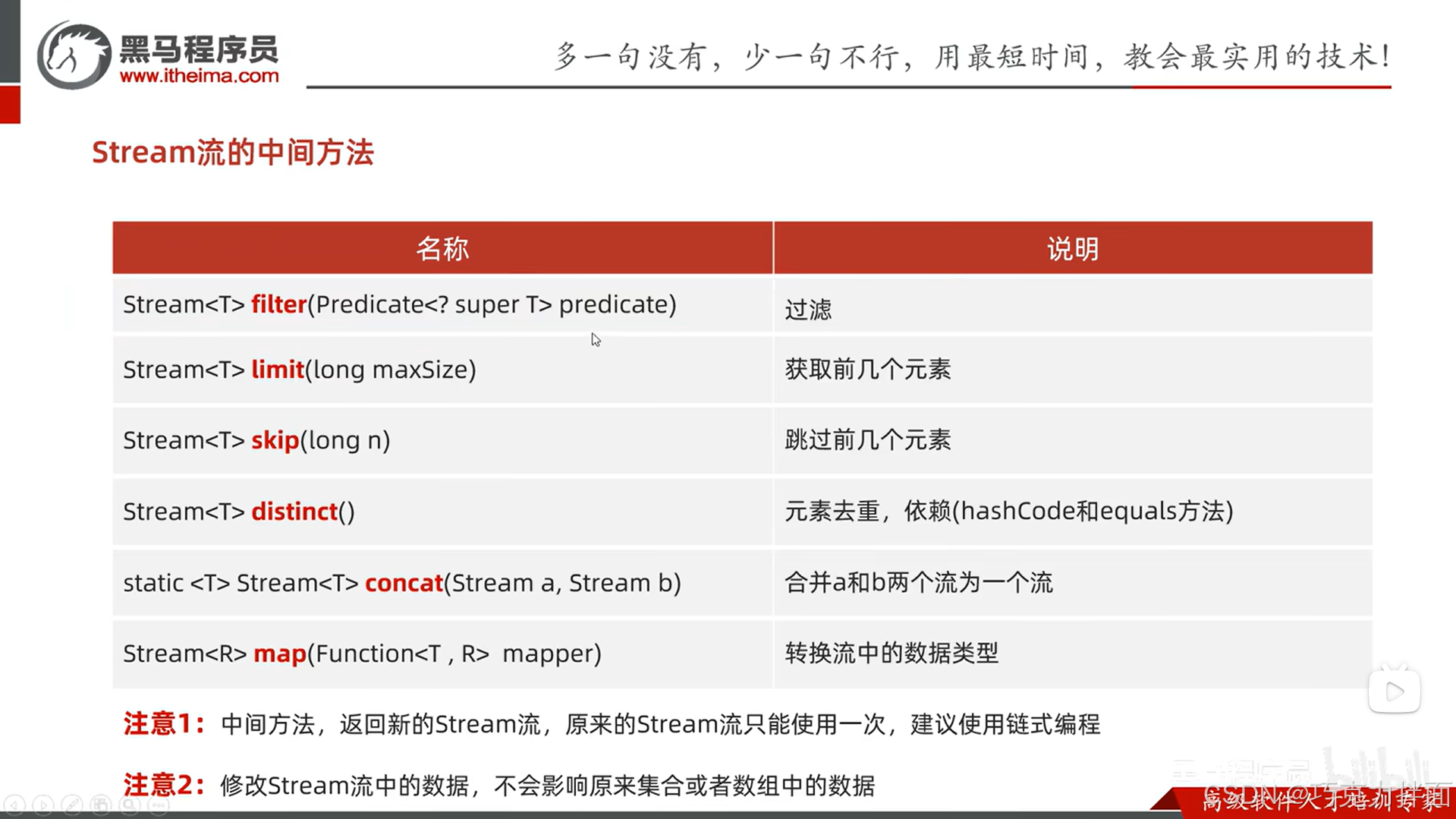
一.Stream流的中间方法:
1.distinct方法底层依赖hashCode方法和equals方法去重,使用时对于自定义数据类型根据需求重写hashCode方法和equals方法(注:基本数据类型和字符串类型不需要重写hashCode方法和equals方法就可以实现去重)。distinct方法底层利用HashSet集合进行去重,所以除了字符串类型外的自定义类型要根据需求重写hashCode方法和equals方法才能进行属性值去重;
2.concat方法用于合并两个流,这两个流的数据类型尽可能的保持一致,如果数据类型不一致,那么最终的数据类型就是这两个流共同的父类类型,相当于进行了类型提升,导致无法使用子类里特有的功能;
3.map方法里的参数mapper是接口类型Function<T, R>,而且该接口是函数式接口,因此可用lambda表达式:
解析接口类型Function<T, R>:T表示流里原本的类型,R表示之后要转成的类型,方法apply的形参s依次表示流里面的每一个数据,方法apply的返回值表示转换之后的数据(注:T和R是泛型,不能是基本数据类型,如果写基本数据类型的话要用包装类,如int要用Integer)
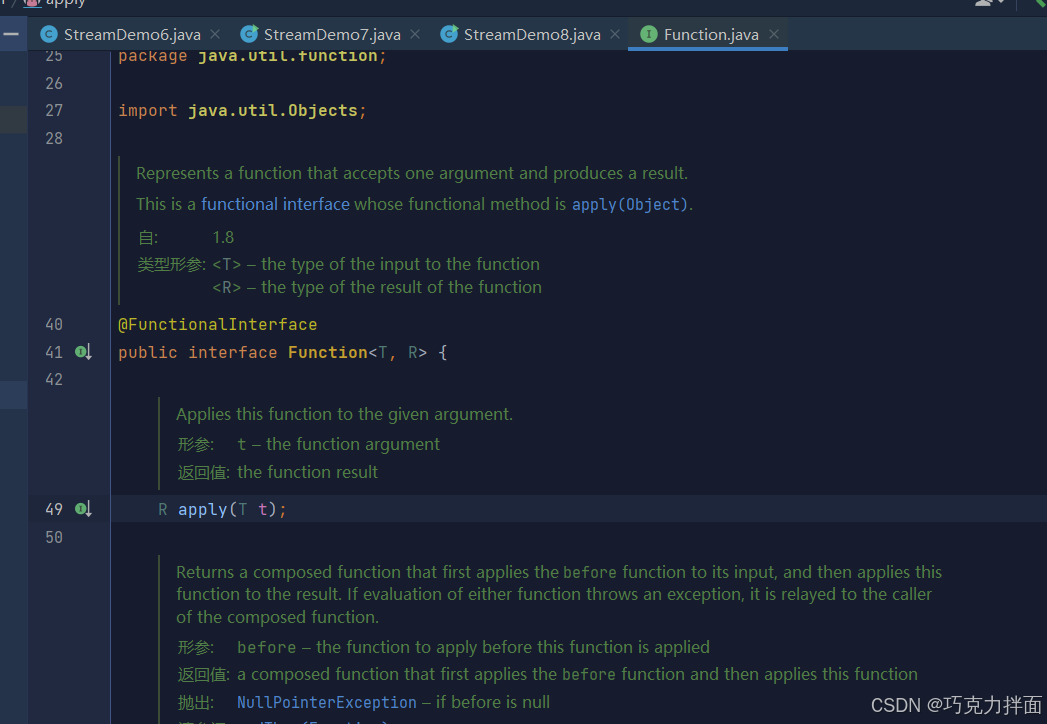
4.concat方法是静态方法,因此可以类名.方法名进行调用:
5.filter方法里的形参predicate的数据类型是函数式接口,因此可以先写匿名内部类,再用lambda表达式进行优化:


6.stream流中间方法的特点是调用完stream流的中间方法后还可以继续使用stream流里的其他方法。
二.代码演示:
1.filter方法(过滤):
package com.itheima.a01mystream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.function.Predicate;
public class StreamDemo6 {
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<>();
Collections.addAll(list,"张无忌","周芷若","赵敏","张强","张三丰","张翠山","张良","王二麻子","谢广坤");
//注:修改Stream流中的数据,不会影响原来集合或者数组中的数据
//1.filter:过滤->把"张"开头的留下,其余数据过滤不要
list.stream().filter(new Predicate<String>() { //list.stream()意思是获取Stream流,并把数据放到Stream流当中
@Override
public boolean test(String s) { //形参s代表流中的每一个数据
boolean flag=s.startsWith("张"); //startsWith返回布尔类型,是"张"开头返回true,不是返回false
return flag; //返回false,表示当前数据舍弃;返回true,表示当前数据保留
}
}).forEach(s-> System.out.println(s)); //打印结果
/*注:打印结果里的s是forEach里的s,不是test方法里的s*/
}
}
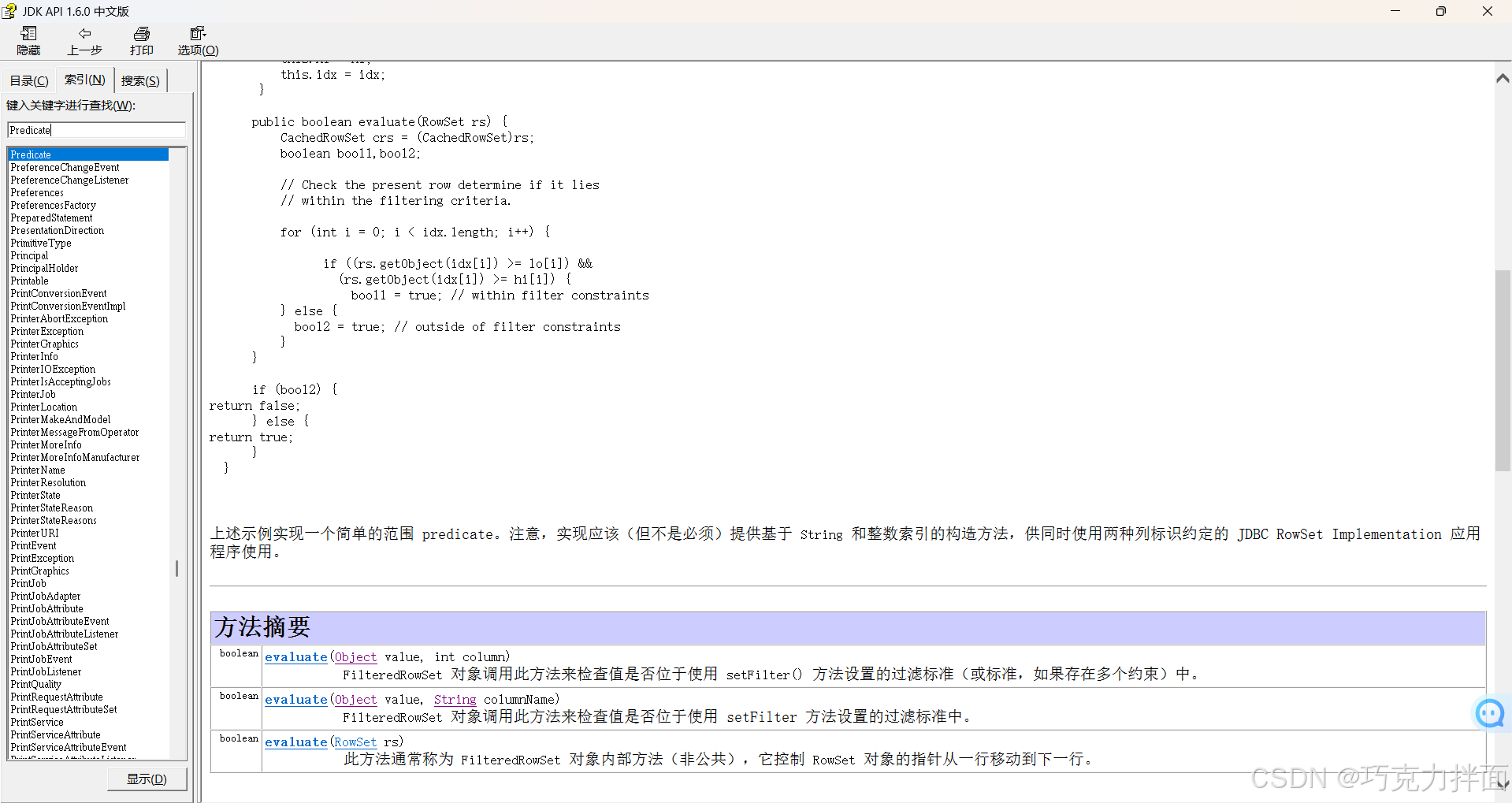
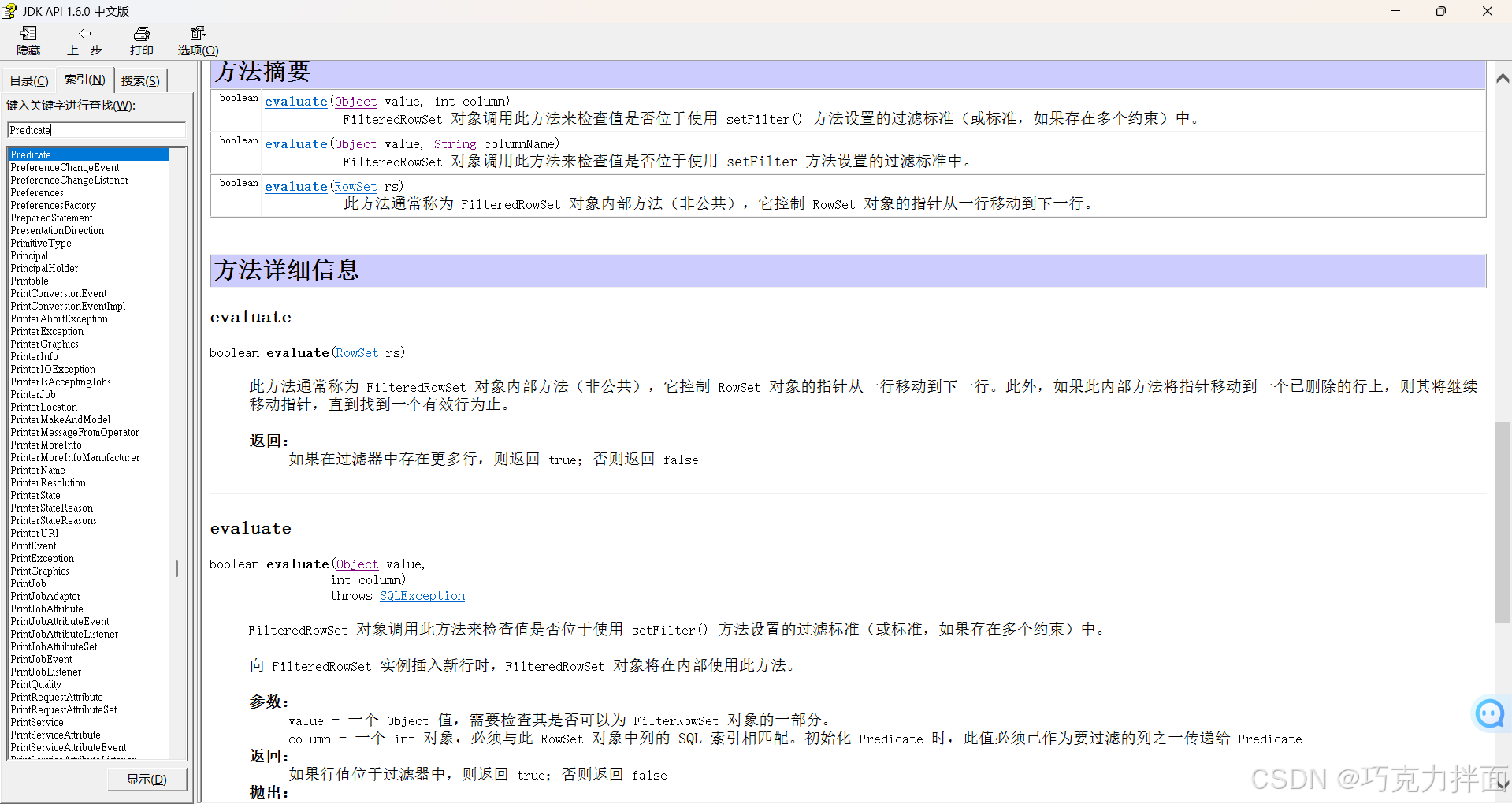
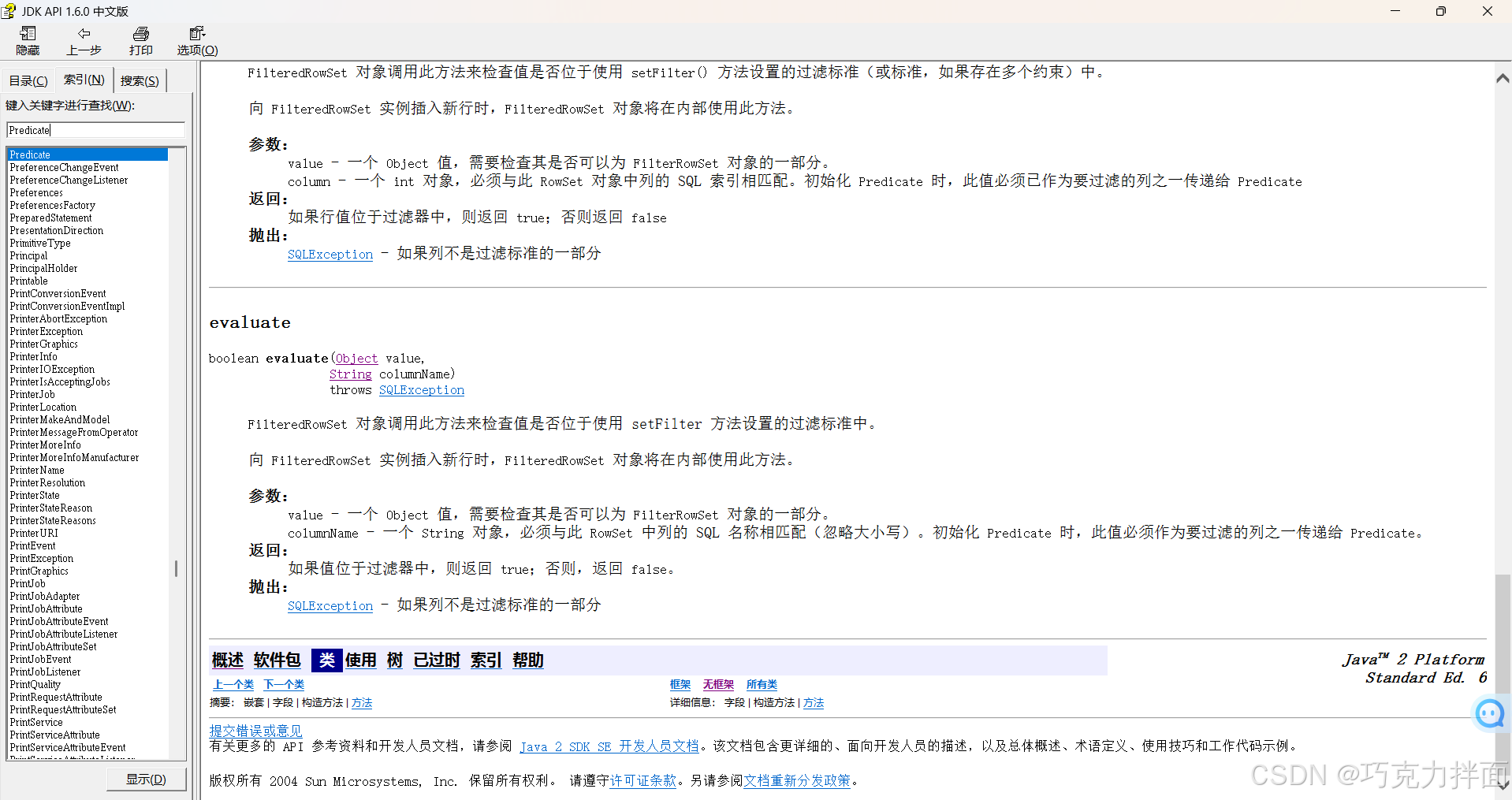
上述例子中filter方法的方法体只是用来指定过滤掉哪些数据,对于集合中的数据类型不会改变,打印集合依旧是打印集合中剩余的数据。 注:Predicate是函数式接口,上例中由于是在流里new的Predicate接口,所以Predicate接口的泛型和流里的数据的类型要保持一致,此时list集合获取的stream流,所以流里的数据的类型就是list集合的类型即String型,所以Predicate接口的泛型是String型
new Predicate<String>()用到了匿名内部类,可用lambda表达式优化:
package com.itheima.a01mystream;
import java.util.ArrayList;
import java.util.Collections;
public class StreamDemo6 {
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<>();
Collections.addAll(list,"张无忌","周芷若","赵敏","张强","张三丰","张翠山","张良","王二麻子","谢广坤");
//注:修改Stream流中的数据,不会影响原来集合或者数组中的数据
//1.filter:过滤->把"张"开头的留下,其余数据过滤不要
list.stream().filter(s -> s.startsWith("张")).forEach(s -> System.out.println(s));
/*s依次表示流水线上的数据,s.startsWith("张")表示开始过滤不需要的数据,以"张"开头的留下 */
}
}
代码折行(折行处回车即可折行),可提高链式编程代码的可读性:
package com.itheima.a01mystream;
import java.util.ArrayList;
import java.util.Collections;
public class StreamDemo6 {
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<>();
Collections.addAll(list,"张无忌","周芷若","赵敏","张强","张三丰","张翠山","张良","王二麻子","谢广坤");
//注:修改Stream流中的数据,不会影响原来集合或者数组中的数据
//1.filter:过滤->把"张"开头的留下,其余数据过滤不要
list.stream().
filter(s -> s.startsWith("张")).
forEach(s -> System.out.println(s));
/*s依次表示流水线上的数据,s.startsWith("张")表示开始过滤不需要的数据,以"张"开头的留下 */
}
}
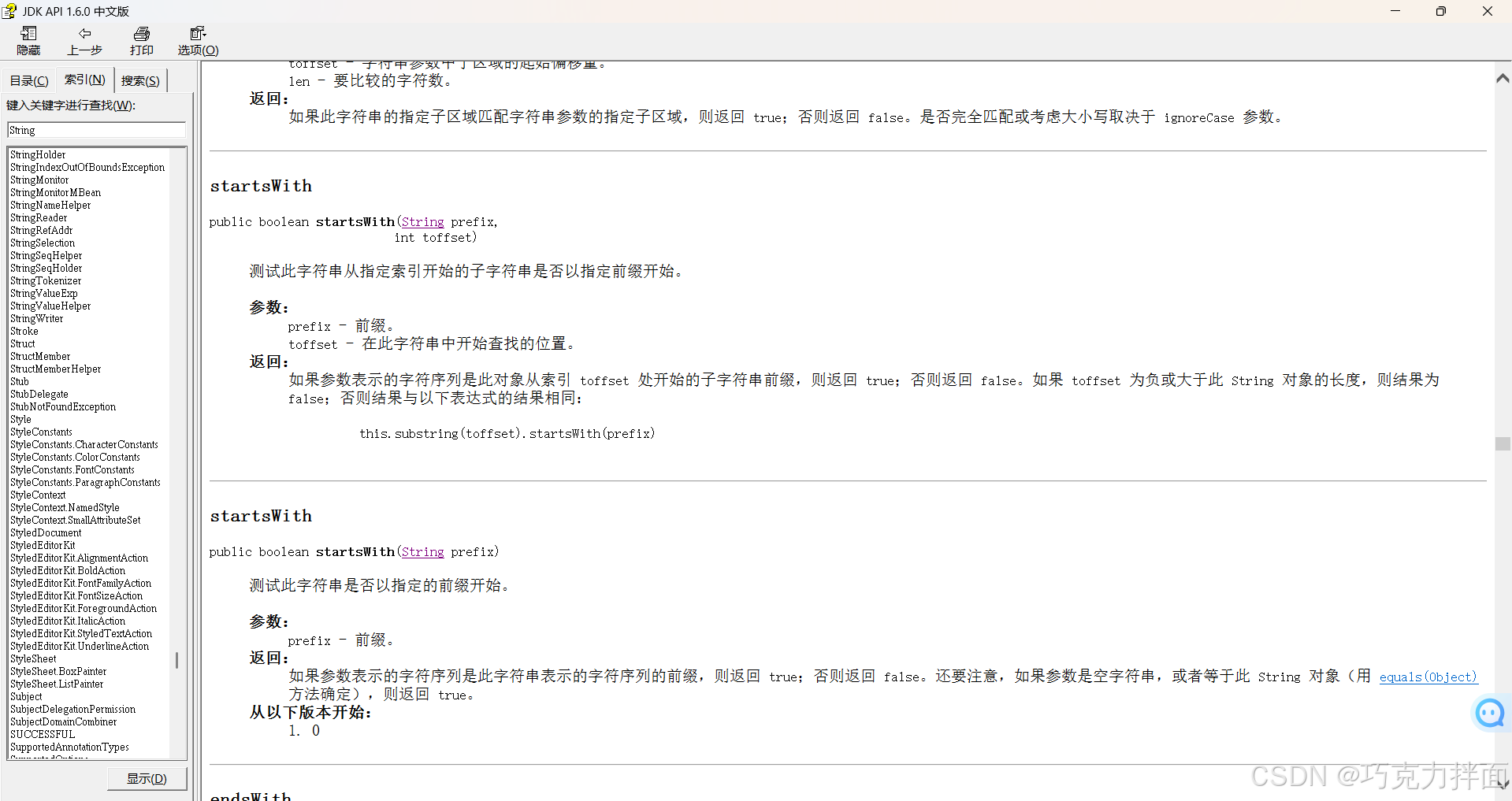
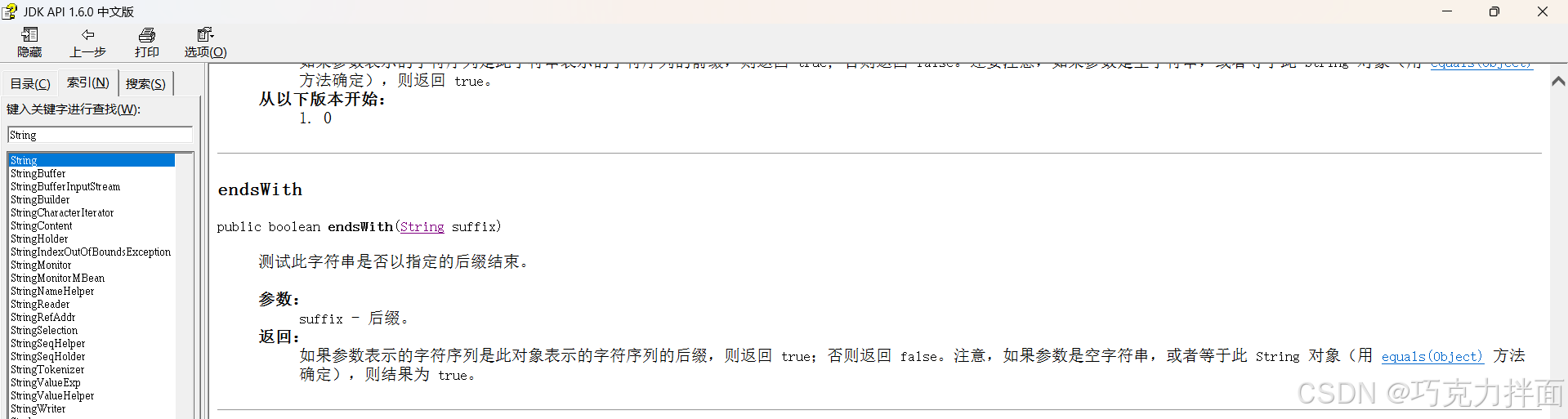
注:String类里的startsWith方法和endsWith方法
2.中间方法,返回新的Stream流,原来的Stream流只能使用一次,建议使用链式编程:
例如:
package com.itheima.a01mystream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.stream.Stream;
public class StreamDemo6 {
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<>();
Collections.addAll(list,"张无忌","周芷若","赵敏","张强","张三丰","张翠山","张良","王二麻子","谢广坤");
//注:修改Stream流中的数据,不会影响原来集合或者数组中的数据
Stream<String> stream1 = list.stream().filter(s -> s.startsWith("张"));/*留下以"张"开头*/
Stream<String> stream2 = stream1.filter(s -> s.length() == 3);/*留下长度为3,stream1调用了方法即使用了stream1。stream流只能用一次,因此stream1之后不能再用了*/
stream2.forEach(s -> System.out.println(s));/*遍历,stream2调用了方法即使用了stream2。stream流只能用一次,因此stream2之后不能再用了*/
/*注:之后stream1和stream2这两个流就不能再用了,这样使得代码占用内存较大,因此可使用链式编程节省内存 */
}
}
3.修改Stream流中的数据,不会影响原来集合或者数组中的数据:
例如:
package com.itheima.a01mystream;
import java.util.ArrayList;
import java.util.Collections;
public class StreamDemo6 {
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<>();
Collections.addAll(list,"张无忌","周芷若","赵敏","张强","张三丰","张翠山","张良","王二麻子","谢广坤");
//注:修改Stream流中的数据,不会影响原来集合或者数组中的数据
//1.filter:过滤->把"张"开头的留下,其余数据过滤不要
list.stream().
filter(s -> s.startsWith("张")).
forEach(s -> System.out.println(s));
/*s依次表示流水线上的数据,s.startsWith("张")表示开始过滤不需要的数据,以"张"开头的留下 */
System.out.println("========================================");
System.out.println(list);
/*运行结果为[张无忌, 周芷若, 赵敏, 张强, 张三丰, 张翠山, 张良, 王二麻子, 谢广坤]
集合中的数据没发生改变*/
}
}
4.limit方法(获取前几个元素):
package com.itheima.a01mystream;
import java.util.ArrayList;
import java.util.Collections;
public class StreamDemo6 {
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<>();
Collections.addAll(list,"张无忌","周芷若","赵敏","张强","张三丰","张翠山","张良","王二麻子","谢广坤");
//注:修改Stream流中的数据,不会影响原来集合或者数组中的数据
//2.limit:获取前几个元素
list.stream().
limit(3). //3代表获取前3个元素,不是索引
forEach(s -> System.out.println(s)); //遍历
}
}
5.skip方法(跳过前几个元素):
package com.itheima.a01mystream;
import java.util.ArrayList;
import java.util.Collections;
public class StreamDemo6 {
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<>();
Collections.addAll(list,"张无忌","周芷若","赵敏","张强","张三丰","张翠山","张良","王二麻子","谢广坤");
//注:修改Stream流中的数据,不会影响原来集合或者数组中的数据
//3.skip:跳过前几个元素
list.stream().
skip(4). //4代表跳过前4个元素
forEach(s -> System.out.println(s)); //遍历
}
}
6.练习:
package com.itheima.a01mystream;
import java.util.ArrayList;
import java.util.Collections;
public class StreamDemo6 {
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<>();
Collections.addAll(list,"张无忌","周芷若","赵敏","张强","张三丰","张翠山","张良","王二麻子","谢广坤");
//注:修改Stream流中的数据,不会影响原来集合或者数组中的数据
//练习:获取 "张强","张三丰","张翠山" 这3个元素
/*方法一:先获取前6个元素,再跳过前3个元素*/
list.stream().limit(6).skip(3).forEach(s -> System.out.println(s));
/*方法二:先跳过前3个元素,再获取前3个元素*/
list.stream().skip(3).limit(3).forEach(s -> System.out.println(s));
}
}
7.distinct方法(元素去重,依赖hashCode和equals方法):
package com.itheima.a01mystream;
import java.util.ArrayList;
import java.util.Collections;
public class StreamDemo7 {
public static void main(String[] args) {
ArrayList<String> list1=new ArrayList<>();
Collections.addAll(list1,"张无忌","张无忌","张无忌","张强","张三丰","张翠山","张良","王二麻子","谢广坤");
list1.stream().distinct().forEach(s -> System.out.println(s));
/*运行结果为 张无忌
张强
张三丰
张翠山
张良
王二麻子
谢广坤 */
}
}
8.concat方法(合并a和b两个流为一个流):
package com.itheima.a01mystream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.stream.Stream;
public class StreamDemo7 {
public static void main(String[] args) {
ArrayList<String> list1=new ArrayList<>();
Collections.addAll(list1,"张无忌","张无忌","张无忌","张强","张三丰","张翠山","张良","王二麻子","谢广坤");
ArrayList<String> list2=new ArrayList<>();
Collections.addAll(list2,"周芷若","赵敏");
Stream.concat(list1.stream(),list2.stream()). //合并list1流和list2流
forEach(s -> System.out.println(s));//遍历
/*list1.stream()调用了stream()才成为了流 */
}
}
9.map方法(转换流中的数据类型):
普通:
package com.itheima.a01mystream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.function.Consumer;
import java.util.stream.Stream;
public class StreamDemo8 {
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<>();
Collections.addAll(list,"张无忌-15","周芷若-14","赵敏-13","张强-20",
"张三丰-100","张翠山-40","张良-35","王二麻子-37","谢广坤-41");
//要求:只获取里面的年龄并进行打印
//获取stream流
Stream<String> stream = list.stream();
//遍历
stream.forEach(new Consumer<String>() {
@Override
public void accept(String s) { //s代表集合的每一个元素
String[] result = s.split("-");
System.out.println(result[1]);
}
});
}
}
注:Consumer接口是一个函数式接口
用lambda表达式优化:
package com.itheima.a01mystream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.stream.Stream;
public class StreamDemo8 {
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<>();
Collections.addAll(list,"张无忌-15","周芷若-14","赵敏-13","张强-20",
"张三丰-100","张翠山-40","张良-35","王二麻子-37","谢广坤-41");
//需求:只获取里面的年龄并进行打印
//获取stream流
Stream<String> stream = list.stream();
//遍历
stream.forEach(s -> { //s代表集合的每一个元素
String[] result = s.split("-");
System.out.println(result[1]);
}
);
}
}
注:String类里的split方法,用于切割字符串
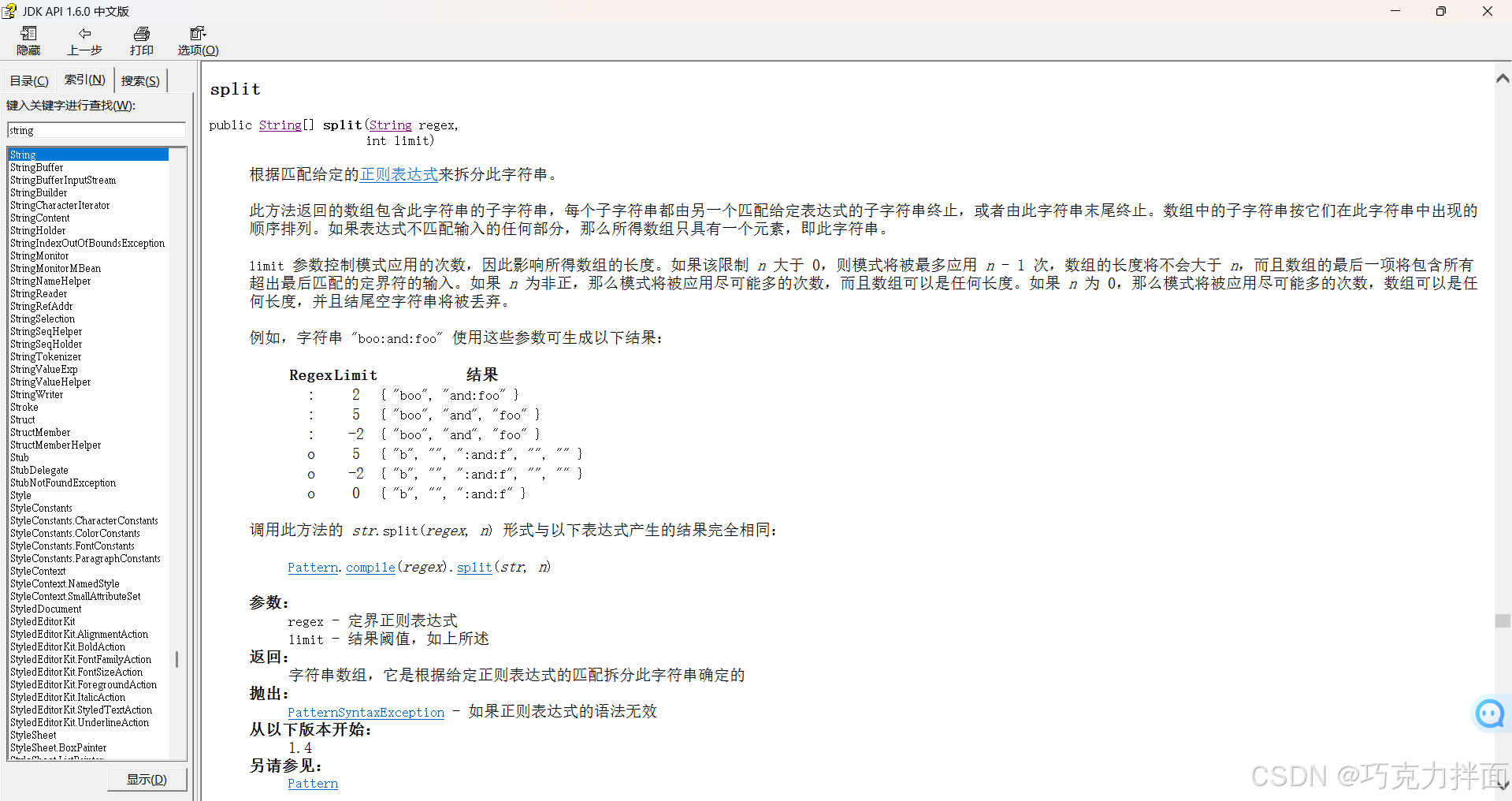
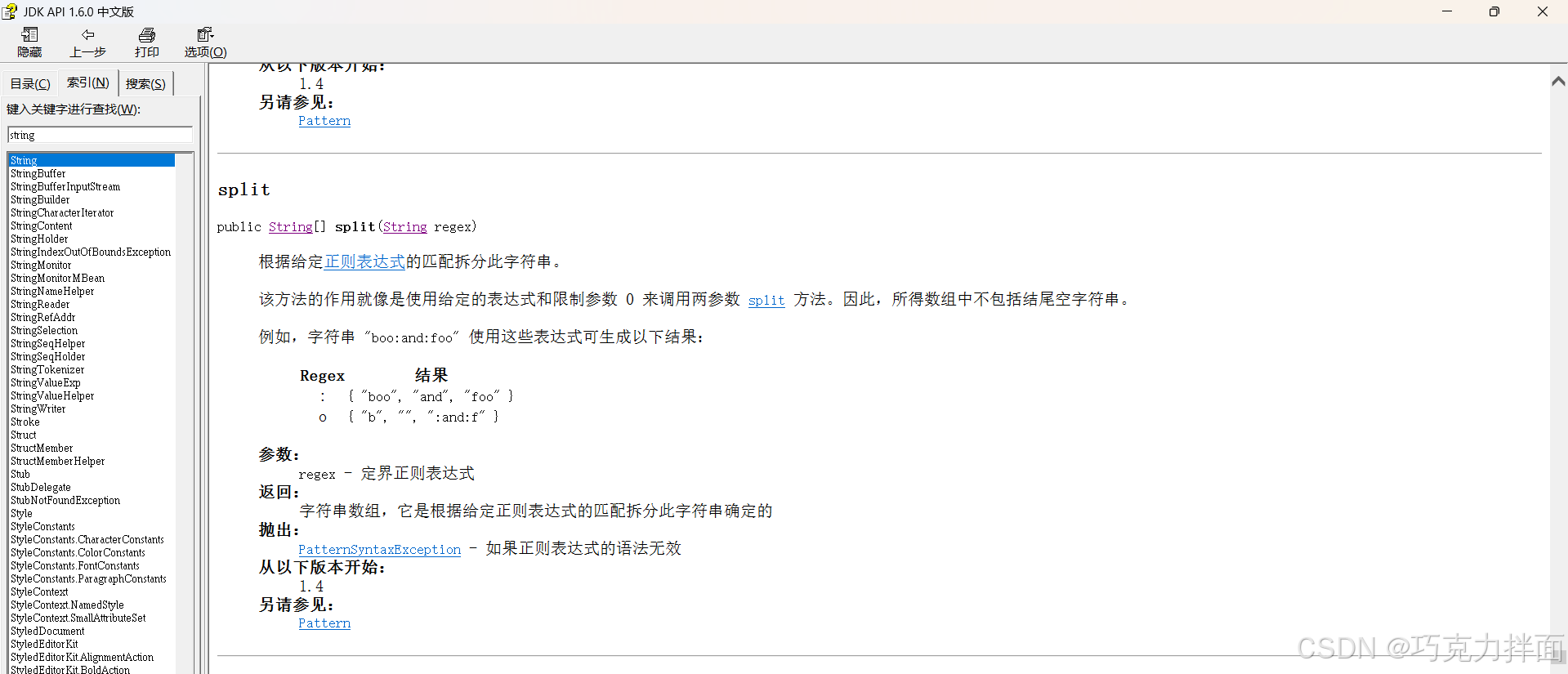
split方法举例:
public class Main {
public static void main(String[] args) {
String s="1-2-3";
String[] arr = s.split("-"); //代表要用-切割字符串s,结果为数组,但结果不包括-
for (String result : arr) {
System.out.printf("%s,",result);
}
//运行结果为1,2,3,
}
}
高级:
package com.itheima.a01mystream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.function.Function;
public class StreamDemo8 {
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<>();
Collections.addAll(list,"张无忌-15","周芷若-14","赵敏-13","张强-20",
"张三丰-100","张翠山-40","张良-35","王二麻子-37","谢广坤-41");
//需求:只获取里面的年龄并进行打印
/*相当于字符串里提取数字:String -> int*/
/*第一个类型:流中原本的类型
第二个类型:之后要转成的类型*/
//apply的形参s:依次表示流里面的每一个数据
//返回值:表示转换之后的数据
list.stream().map(new Function<String, Integer>() { //要用泛型
@Override
public Integer apply(String s) { //这个s表示集合里的每一个数据如张无忌-15
//1.切割:比如张无忌-15切割为张无忌和15,此时结果为数组,0索引上为张无忌,1索引上为15
String[] arr = s.split("-");
//2.获取年龄:但是为字符串
String ageString = arr[1];
//3.转换为int型,可利用int型的包装类Integer里的parseInt方法
int age = Integer.parseInt(ageString);
return age; //返回整型,所以apply方法的返回类型用整型Integer
}
}).forEach(s -> System.out.println(s));
/*当map方法执行完毕之后,流上的数据就变成了整数,
所以在调用forEach方法中,s依次表示流里面的每一个数据,这个数据现在就是整数了*/
}
}
用lambda表达式优化:
package com.itheima.a01mystream;
import java.util.ArrayList;
import java.util.Collections;
public class StreamDemo8 {
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<>();
Collections.addAll(list,"张无忌-15","周芷若-14","赵敏-13","张强-20",
"张三丰-100","张翠山-40","张良-35","王二麻子-37","谢广坤-41");
//需求:只获取里面的年龄并进行打印
/*相当于字符串里提取数字:String -> int*/
/*第一个类型:流中原本的类型
第二个类型:之后要转成的类型*/
list.stream().
map(s -> Integer.parseInt( s.split("-")[1] )). //这个s表示集合里的每一个数据如张无忌-15
forEach(s -> System.out.println(s)); //这个s就是最终要的年龄
//s.split("-")结果为字符串数组,s.split("-")[1]表示获取字符串数组1索引上的元素
//s.split("-")[1]是字符串型,Integer.parseInt( s.split("-")[1]为整型
}
}
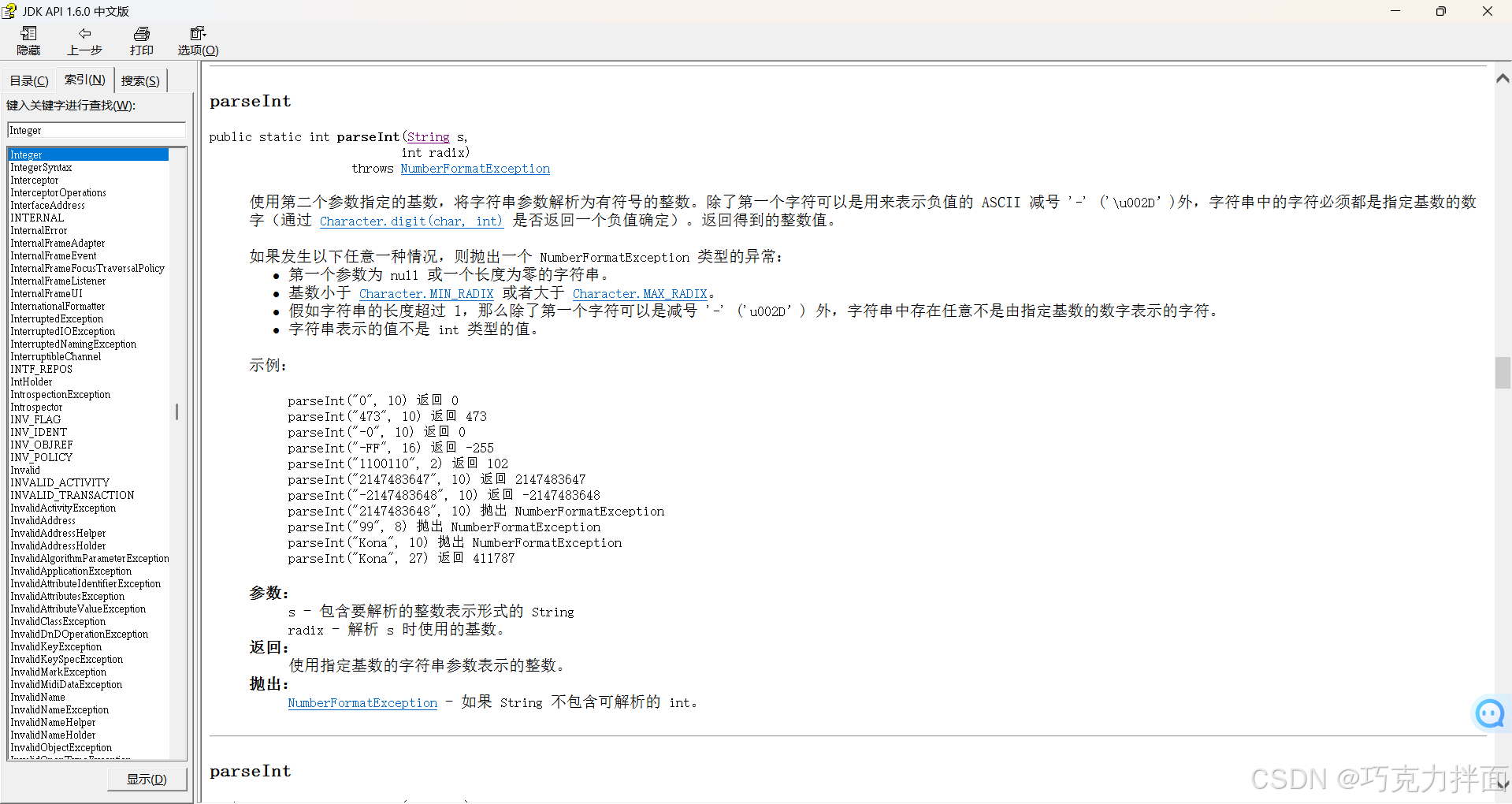
注:Integer类里的parseInt方法可以把字符串转化为整数,parseInt方法是静态方法,可以类名.方法名进行调用,也可以使用类名::静态方法名(方法引用)进行调用

















 6078
6078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









