






问题描述
海伦使用在线约会网站时,她遇到三种类型的约会对象:
-
不喜欢的人
-
一般喜欢的人
-
非常喜欢的人
每位潜在约会对象有三个特征:
我们的目标是开发一个分类器,根据这些特征预测海伦对某人的喜欢程度。
每年获得的飞行常客里程数
玩视频游戏所耗时间百分比
每周消费的冰淇淋公升数
K近邻算法简介
K近邻(K-Nearest Neighbors, KNN)是一种简单而有效的监督学习算法,适用于分类和回归问题。其核心思想是"物以类聚"——相似的对象往往具有相似的标签。
KNN工作原理
计算待分类样本与训练集中所有样本的距离
选择距离最近的K个邻居
根据这K个邻居的类别进行投票,得票最多的类别即为预测结果
1. 数据准备与预处理
不同特征的量纲差异很大,比如飞行里程可能是数万,而游戏时间百分比在0-100之间。直接计算距离会导致量纲大的特征主导结果。因此我们需要进行数据归一化:
实现步骤
def normalize_data(data):
min_vals = data.min(axis=0)
max_vals = data.max(axis=0)
ranges = max_vals - min_vals
ranges[ranges == 0] = 1 # 避免除以零
normalized_data = (data - min_vals) / ranges
return normalized_data2. 距离计算
我们使用欧几里得距离来衡量样本间的相似度:
def euclidean_distance(x, y):
return np.sqrt(np.sum((x - y) ** 2))3. KNN分类器实现
def knn_classify(X_train, y_train, X_test, k=3):
predictions = []
for test_point in X_test:
distances = []
for i in range(len(X_train)):
dist = euclidean_distance(test_point, X_train[i])
distances.append((dist, y_train[i]))
distances.sort(key=lambda x: x[0])
k_nearest_labels = [label for (_, label) in distances[:k]]
most_common = Counter(k_nearest_labels).most_common(1)
predictions.append(most_common[0][0])
return predictions4. 数据加载与标签处理
def load_data_from_file(file_path):
data = np.loadtxt(file_path, dtype='str', delimiter='\t')
X = data[:, :-1].astype(float)
# 创建标签映射
unique_labels = np.unique(data[:, -1])
label_mapping = {label: idx for idx, label in enumerate(unique_labels)}
y = np.array([label_mapping[label] for label in data[:, -1]])
return X, y模型评估
我们将数据集按80:20的比例划分为训练集和测试集:
split_ratio = 0.8
split_index = int(len(X) * split_ratio)
X_train, X_test = X[:split_index], X[split_index:]
y_train, y_test = y[:split_index], y[split_index:]归一化处理后进行预测并计算错误率:
normalized_X_train = normalize_data(X_train)
normalized_X_test = normalize_data(X_test)
k = 3
predictions = knn_classify(normalized_X_train, y_train, normalized_X_test, k)
errors = np.sum(predictions != y_test)
error_rate = errors / len(y_test)结果分析
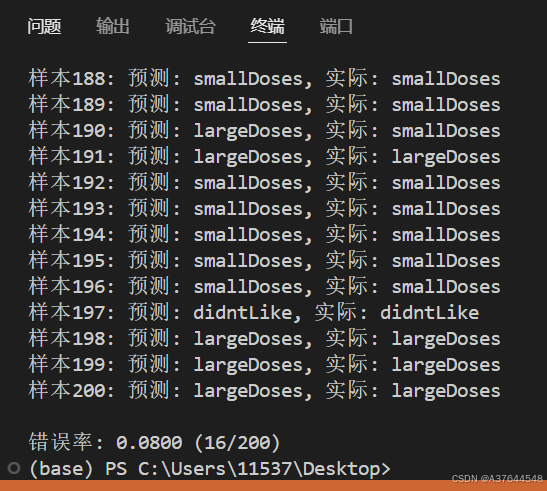
这是k=1的结果
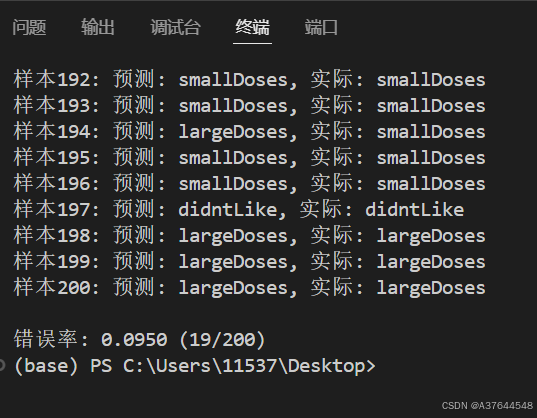
这是k=3的结果
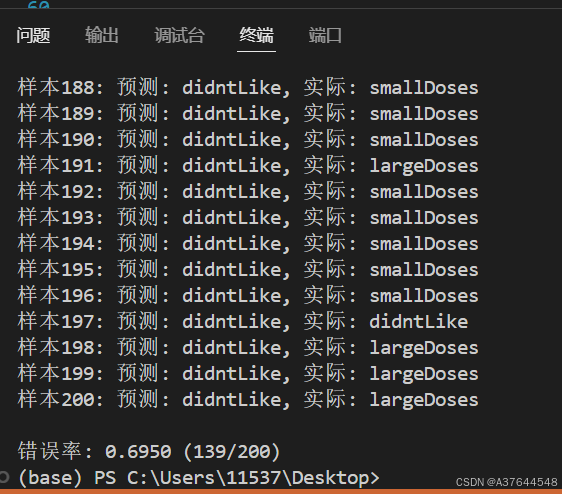
这是k=999的结果
总结
本文实现了基于KNN算法的约会对象分类器,展示了从数据预处理到模型评估的完整流程。KNN算法简单直观,无需训练过程,但在处理大规模数据时计算成本较高。在实际应用中,可以根据具体需求调整算法参数或尝试其他更复杂的模型。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









