




 本文介绍了PyTorch中的DataLoader和Dataset的概念及其作用。DataLoader是用于处理模型输入数据的工具,结合了Dataset和采样器,支持单线程或多线程迭代。关键参数包括epoch、iteration、batch_size、shuffle、num_workers和drop_last。文中通过示例展示了如何创建和使用DataLoader,以及如何利用Tensorboard进行可视化,其中示例数据集为CIFAR10。
本文介绍了PyTorch中的DataLoader和Dataset的概念及其作用。DataLoader是用于处理模型输入数据的工具,结合了Dataset和采样器,支持单线程或多线程迭代。关键参数包括epoch、iteration、batch_size、shuffle、num_workers和drop_last。文中通过示例展示了如何创建和使用DataLoader,以及如何利用Tensorboard进行可视化,其中示例数据集为CIFAR10。
DataLoader(1)
torch.utils.data.Dataset是代表这一数据的抽象类(也就是基类)。我们可以通过继承和重写这个抽象类实现自己的数据类,只需要定义__len__和__getitem__这个两个函数。
DataLoader是Pytorch中用来处理模型输入数据的一个工具类。组合了数据集(dataset) + 采样器(sampler),并在数据集上提供单线程或多线程(num_workers )的可迭代对象。在DataLoader中有多个参数,这些参数中重要的几个参数的含义说明如下:
epoch:所有的训练样本输入到模型中称为一个epoch;
iteration:一批样本输入到模型中,成为一个Iteration;
batchszie:一批样本大小,决定一个epoch有多少个Iteration;
迭代次数(iteration)=样本总数(epoch)/批尺寸(batchszie)
dataset (Dataset) – 决定数据从哪读取或者从何读取;
batch_size (python:int, optional) – 批尺寸(每次训练样本个数,默认为1)
shuffle (bool, optional) –每一个 epoch是否为乱序 (default: False);
num_workers (python:int, optional) – 是否多进程读取数据(默认为0);
drop_last (bool, optional) – 当样本数不能被batchsize整除时,最后一批数据是否舍弃(default: False 不舍去)
pin_memory(bool, optional) - 如果为True会将数据放置到GPU上去(默认为false)
DataLoader 与 DataSet 详情可参考:
https://blog.youkuaiyun.com/He3he3he/article/details/105441083
一、DataLoader使用
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备测试的数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
test_loader = DataLoader(dataset=test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
# 测试的数据集中的第一张图片及target
img,target = test_data[0]
print(img.shape) # torch.Size([3, 32, 32]) 3 通道彩色图片 长为32 宽为32
print(target) # target 为 3
writer = SummaryWriter("dataloader")
step = 0
for data in test_loader:
imgs,targets = data
print(imgs.shape) # torch.Size([4, 3, 32, 32]) 4张 3通道 32*32 的图片
print(targets) # tensor([3, 4, 6, 5]) 4张图片的target 分别是3 4 6 5
writer.add_images("test_data",imgs,step)
step += 1
writer.close()
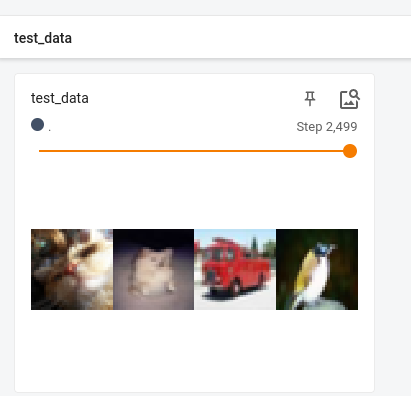
通过Tensorboard观察得到一批样本的图片数 是 4 张


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









