







附近商户,附近地图都是基于地理坐标实现的
redis中实现附近商户的功能是基于GEO数据结构
GEO数据结构
geo代表地理坐标,允许存储地理坐标信息,帮助根据经纬度来检索数据
相关命令
GEOHASH:是将坐标以01进制的形式进行编码,在返回
GEOSEARCHSOTRE:以sortedset返回搜索的结果

练习

1.输入三个地址的坐标,先输入经纬度,后输入经纬度坐标名称
![]()
可以看见,redis中以ZET存储,也就是sortedset集合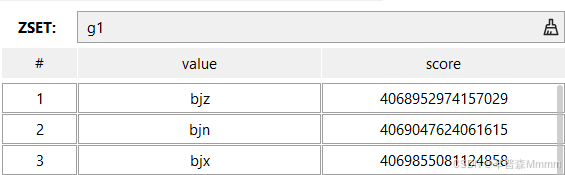
2.可以指定输出的距离,可以看见bjn到bjx的距离是111.2264千米
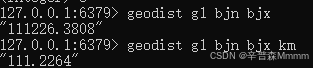
3.搜索排序可以用GEORADIUS或者GEOSEARCH


下面的命令表示按照天安门的经纬度坐标(116.39 39.411)在g1中按照半径200km的范围搜索坐标,并附上距离。
其中,还可以按照矩形的范围搜索,以及按照升序降序的功能,还能实现搜索最大数量内的坐标

附近商户搜索
分析一下流程,首先点击某个频道,可以看见频道下的对应商户,这是GET请求类型,请求接口是,shop/of/type?&typeId=1,1就是对应的美食频道,申请的请求中带有请求分页查询和用户的当前位置坐标
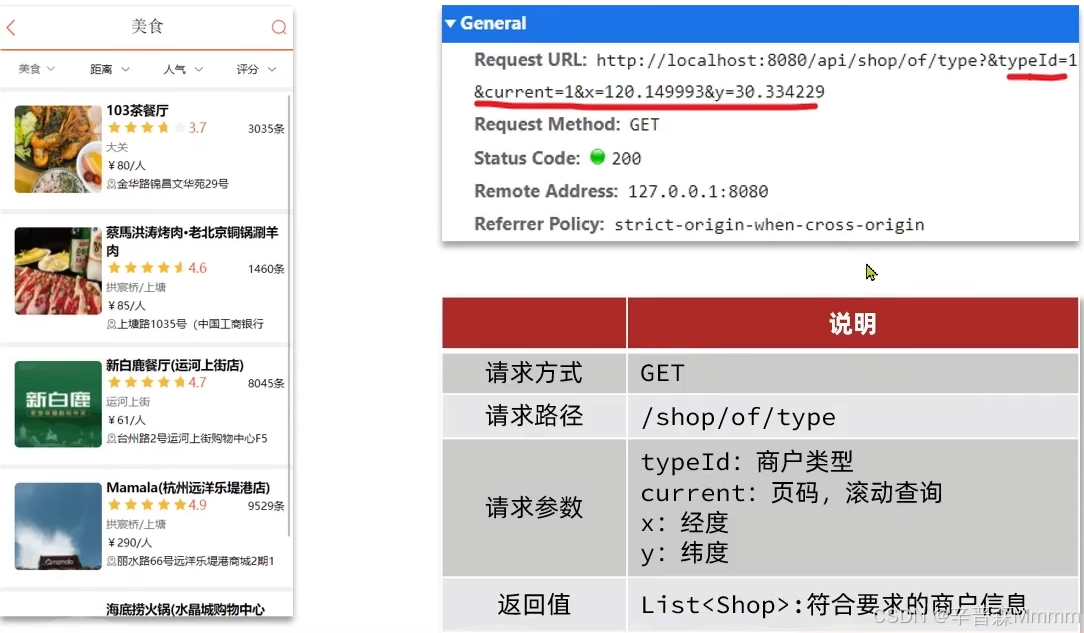
实现思路
由于要计算距离,而商户的坐标存储在数据库中,计算后在返回就会大量的消耗计算资源,所以先将数据库中的商户信息的id和坐标存储在redis中的geo数据结构中,然后计算后在返回对应商户id,去数据库中查询店铺信息,这样提升了并发性。
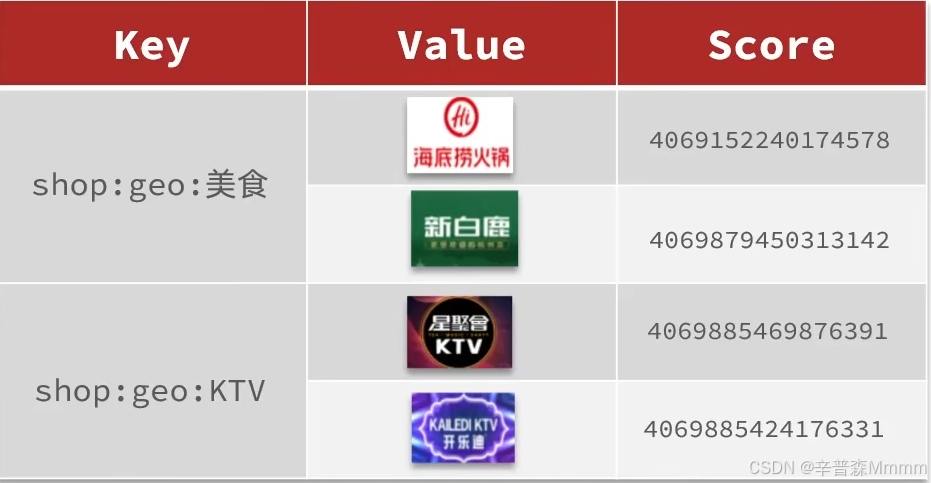
首先先将店铺的坐标和id按照typeId分组存储在redis中
@Resource
private ShopServiceImpl shopService;
@Resource
private StringRedisTemplate stringRedisTemplate;
@Test
void loadShopData() {
//1.查询店铺信息
List<Shop> list = shopService.list();
//2.将店铺按照typeId进行分组,typeId一致的放到一个集合中,Long存入的是typeId,list存入相应的店铺集合
//可以利用for循环一个一个遍历存入map类型中,但可以直接利用stream流,按照typeId进行分组
Map<Long, List<Shop>> map = list.stream().collect(Collectors.groupingBy(Shop::getTypeId));
//3.分组写入redis中
for(Map.Entry<Long,List<Shop>> entry:map.entrySet()) {
//3.1获取类型id
Long typeId = entry.getKey();
String key = "shop:geo:" + typeId;
//3.2获取同类型店铺的集合
List<Shop> value = entry.getValue();
//3.3写入redis GEOADD key x y member
for (Shop shop : value) {
stringRedisTemplate.opsForGeo().add(key, new Point(shop.getX(), shop.getX()), shop.getId().toString());
}
}
}redis对应的存储信息

















 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









