







关注和取关
实现关注和取关会通过同一个接口实现/api/follow/2/true,2是被关注人的用户Id,true表示关注,false表示取关
再实现关注和取关之前是要实现一个判断是否关注用户的接口/follow/or/not/2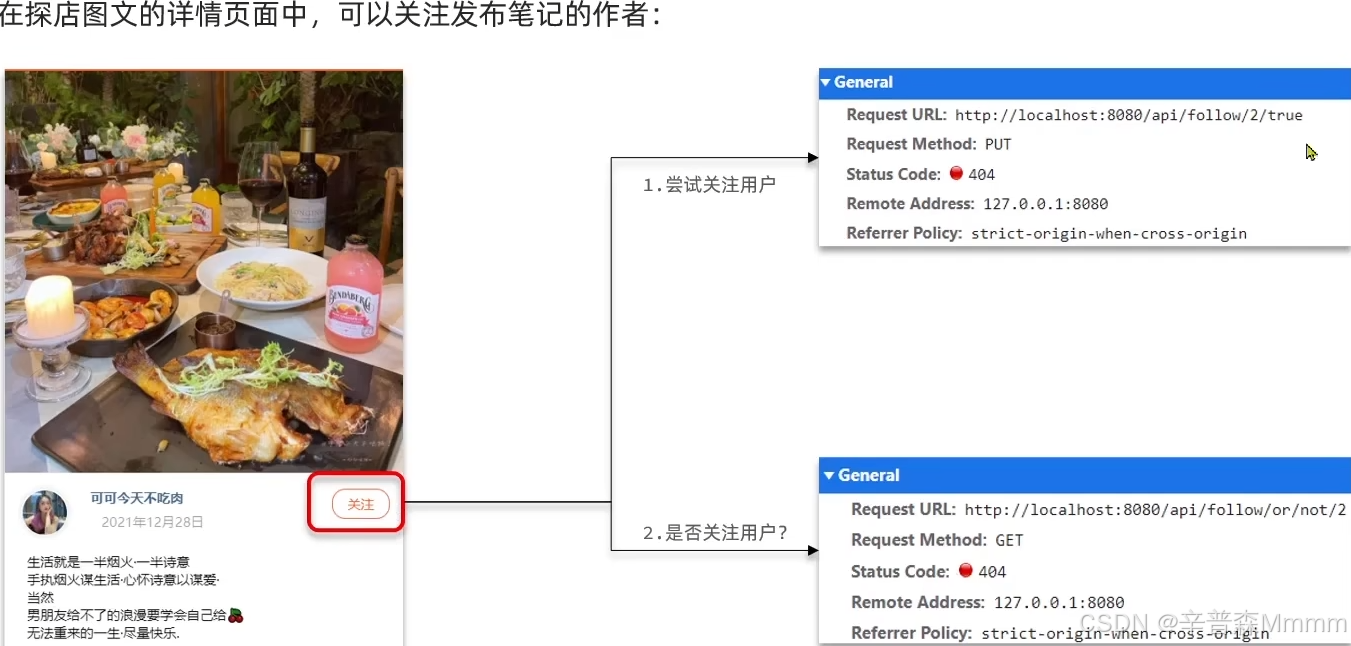
实现关注和取关的用户表有一下字段,注意id应该处理为自增长
!!为什么这里选择数据库表去处理关注和取关的功能,不选择redis中的set数据结构来存储?
Set是一个无序的集合,里面的元素是不重复的,支持交集、并集、差集等操作。每个用户可以用一个set来存储他们的关注列表,另一个set存储粉丝列表。例如,用户A关注用户B,那么可以在user:A:following这个set中添加用户B的ID,同时在user:B:followers这个set中添加用户A的ID。这样,关注和取关操作可以通过SADD和SREM命令来实现,非常快速,而且可以确保不重复。
1.在数据持久化存储和数据量方面:Redis默认是内存存储,虽然有持久化机制(如RDB和AOF),但在极端情况下可能会有数据丢失的风险。而数据库的数据持久化更可靠,事务支持也更完善。在大数据量的情况下,Redis的内存占用会变得很高,需要考虑成本问题。而数据库表存储在磁盘上,虽然查询可能慢一些,但存储成本相对较低。
2.除了关注和取关之外,还需要复杂的查询,比如共同关注、推荐关注等,Redis的set操作可以直接用SINTER来求交集,非常方便。而数据库可能需要复杂的JOIN操作或者多次查询才能实现,效率可能不如Redis。
创建两个方法接口
@RestController
@RequestMapping("/follow")
public class FollowController {
@Resource
private IFollowService followService;
@PutMapping("/{id}/{isFollow}")
public Result follow(@PathVariable("id") Long followUserId, @PathVariable("isFollow") Boolean isFollow) {
return followService.follow(followUserId, isFollow);
}
@GetMapping("/or/not/{id}")
public Result isFollow(@PathVariable("id") Long followUserId) {
return followService.isFollow(followUserId);
}
}service层方法实现类
public interface IFollowService extends IService<Follow> {
Result follow(Long followUserId, Boolean isFollow);
Result isFollow(Long followUserId);
}
实现关注和取关
@Override
public Result follow(Long followUserId, Boolean isFollow) {
//1.拿到登录用户id
Long userId = UserHolder.getUser().getId();
//2.判断关注还是取关
if(isFollow){
//关注就返回成功信息,并写入数据库表
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
save(follow);
}else{
//取关就删除数据库表的数据, delete from tb_follow where user_id = ? and follow_user_Id = ?
//表示删除时应该两个id等于传入的两个用户id
remove(new QueryWrapper<Follow>().eq("user_id", userId).eq("follow_user_Id", followUserId));
}
return Result.ok();
}实现查询是否关注
@Override
public Result isFollow(Long followUserId) {
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
// 2.查询是否关注 select count(*) from tb_follow where user_id = ? and follow_user_id = ?
//并不需要查出存在不存在,只需要用计数器即可,关注了就>0
Integer count = query().eq("user_id", userId).eq("follow_user_id", followUserId).count();
// 3.判断
return Result.ok(count > 0);
}共同关注
必须要实现两个功能才能进入用户的主页,一个是用户的个人信息功能接口/user/{id},一个是查看当前用户的笔记功能接口/blog/of/user
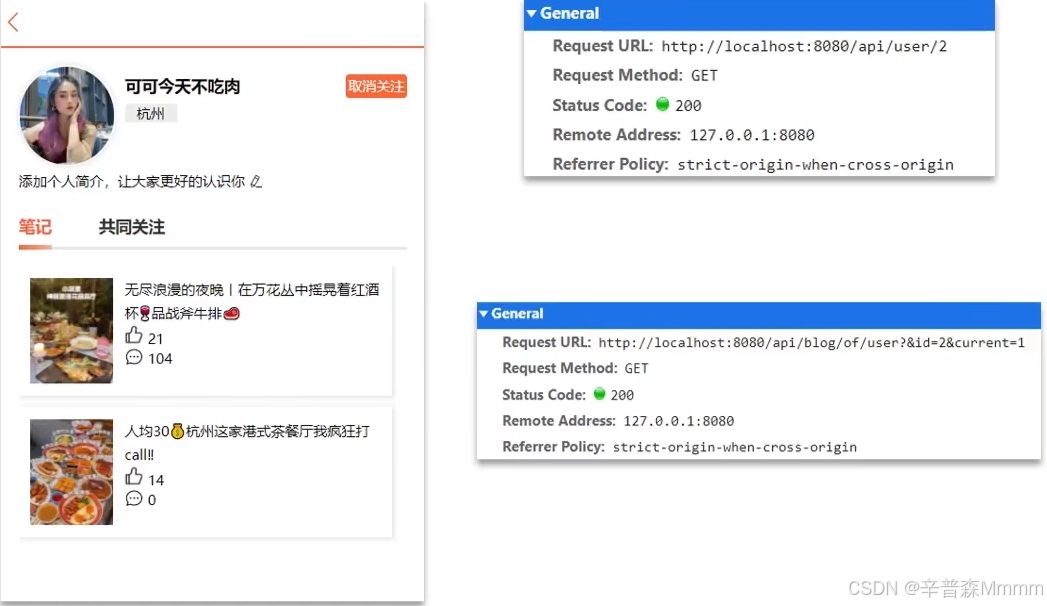
@GetMapping("/of/user")
public Result queryBlogByUserId(
@RequestParam(value = "current", defaultValue = "1") Integer current,
@RequestParam("id") Long id) {
// 根据用户查询
Page<Blog> page = blogService.query()
.eq("user_id", id).page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));
// 获取当前页数据
List<Blog> records = page.getRecords();
return Result.ok(records);
}
@GetMapping("/{id}")
public Result queryUserById(@PathVariable("id") Long userId){
// 查询详情
User user = userService.getById(userId);
if (user == null) {
return Result.ok();
}
UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);
// 返回
return Result.ok(userDTO);
}共同关注的功能接口是/follow/common/{id},即你当前查看用户id的共同关注
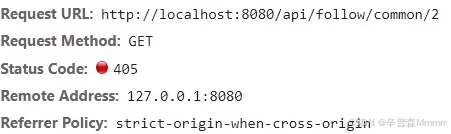
使用set数据结构可以实现交集、并集等功能,而共同关注即两个用户关注的交集部分
首先,修改关注和取关的逻辑,采取redis中set数据结构,在实现写入数据库的同时,将被关注用户Id放入set集合中,key采用关注用户id
@Override
public Result follow(Long followUserId, Boolean isFollow) {
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
String key = "follows:" + userId;
// 1.判断到底是关注还是取关
if (isFollow) {
// 2.关注,新增数据
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
boolean isSuccess = save(follow);
//若写入数据库成功的同时,将id放入redis的set集合
if (isSuccess) {
// 把关注用户的id,放入redis的set集合 sadd userId followerUserId
stringRedisTemplate.opsForSet().add(key, followUserId.toString());
}
} else {
// 3.取关,删除 delete from tb_follow where user_id = ? and follow_user_id = ?
boolean isSuccess = remove(new QueryWrapper<Follow>()
.eq("user_id", userId).eq("follow_user_id", followUserId));
if (isSuccess) {
// 把关注用户的id从Redis集合中移除
stringRedisTemplate.opsForSet().remove(key, followUserId.toString());
}
}
return Result.ok();
}共同关注功能
@Override
public Result followCommons(Long id) {
//传递的参数是目标用户
// 1.获取当前用户
Long userId = UserHolder.getUser().getId();
//当前用户key
String key = "follows:" + userId;
//目标用户key
String key2 = "follows:" + id;
// 2.求交集
Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key, key2);
if (intersect == null || intersect.isEmpty()) {
// 无交集
return Result.ok(Collections.emptyList());
}
// 3.解析id集合
List<Long> ids = intersect.stream().map(Long::valueOf).collect(Collectors.toList());
// 4.查询用户
List<UserDTO> users = userService.listByIds(ids)
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
return Result.ok(users);
}关注推送
也叫Feed流,范围为投喂,通过无线下拉刷新获取新的信息
Feed流有两种模式:Timeline和智能排序
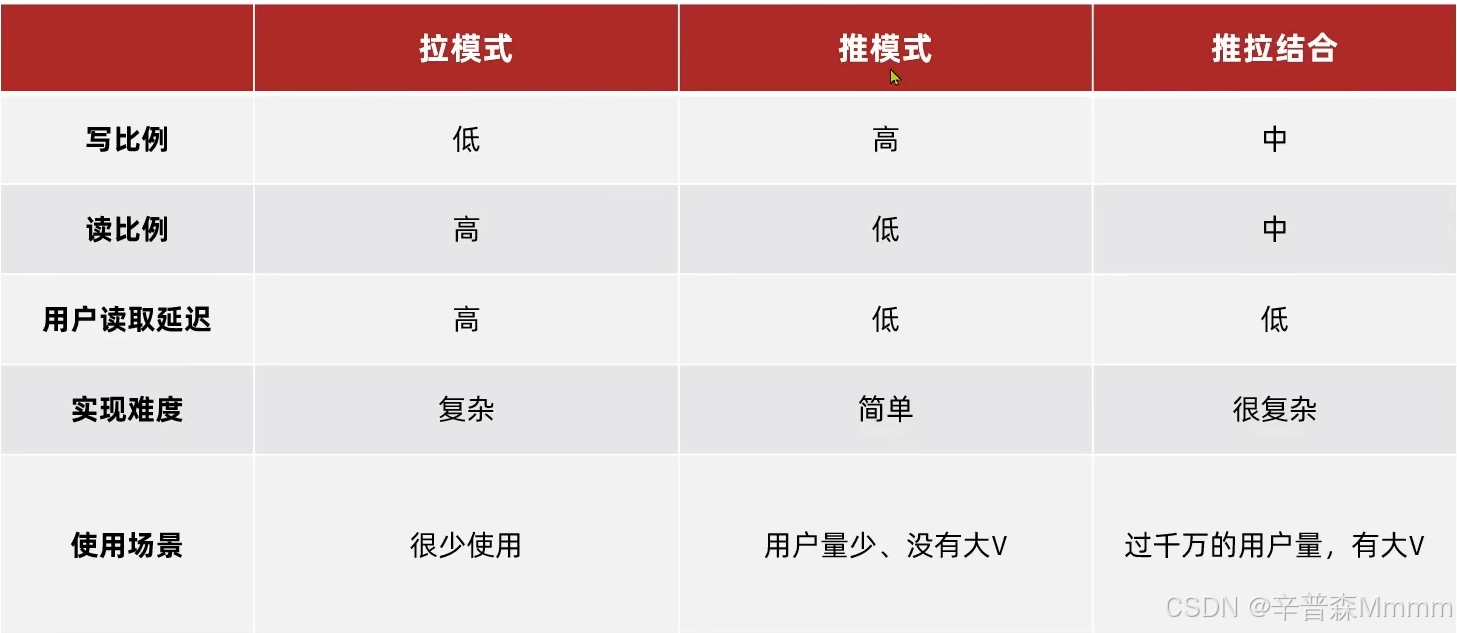
Timeline有三种实现方式:拉模式、推模式和推垃结合
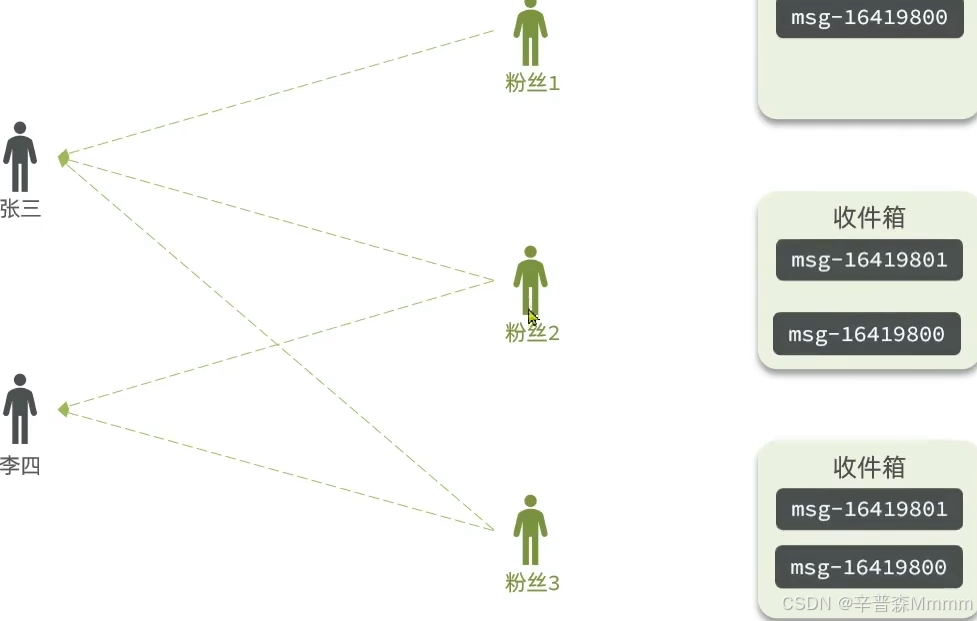
拉模式:也叫读扩散,即每次赵六读取的时候,都会从它关注的人的发件箱里拉取消息并且按照时间排序,缺点就是延迟高(为什么延迟高?因此要去发件箱里读取数据,所以时间长)
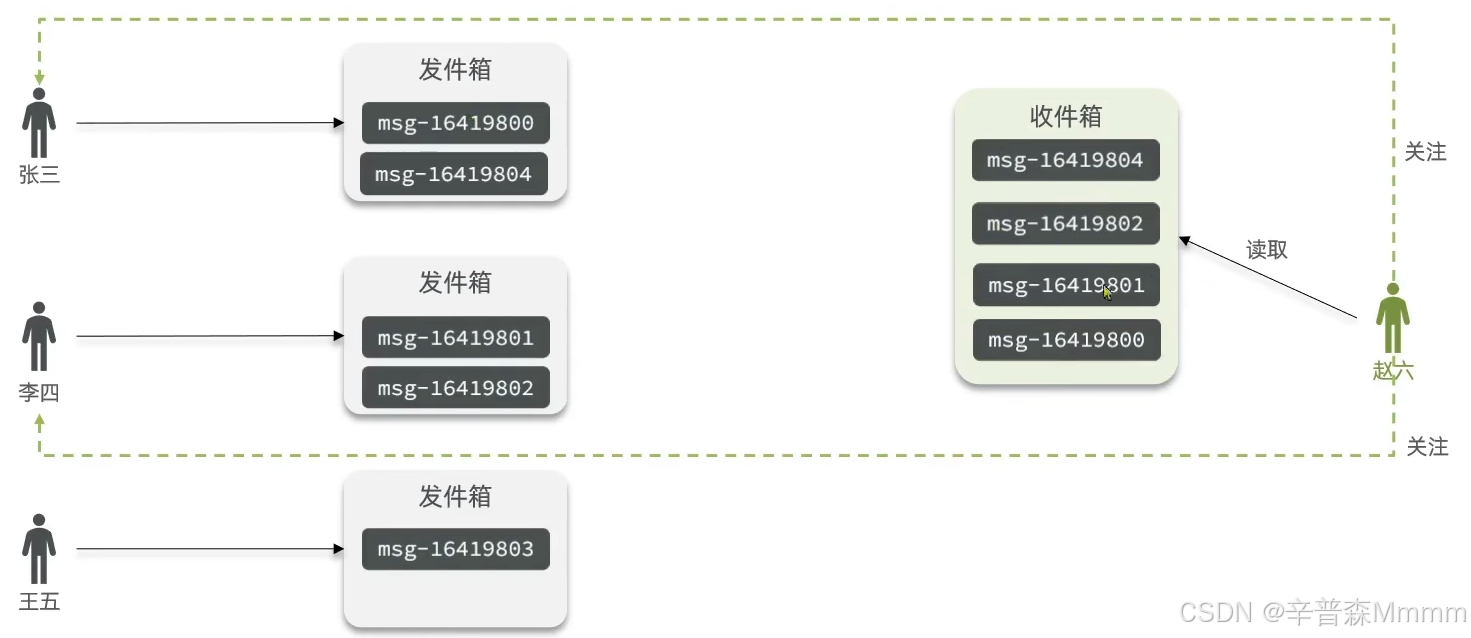
推模式:也叫写扩散,即有人发消息会直接推送到粉丝的收件箱中按照时间排序,优点延迟低,缺点:占用内存高,一次写可能写n份
推拉结合:也叫读写混合,具有推拉两种模式的有优点,即将根据身份的不同赋予不同的权力,针对少量活跃粉丝采取推模式,延迟低但耗点内存,针对大量普通粉丝采取拉模式,省内存但延迟高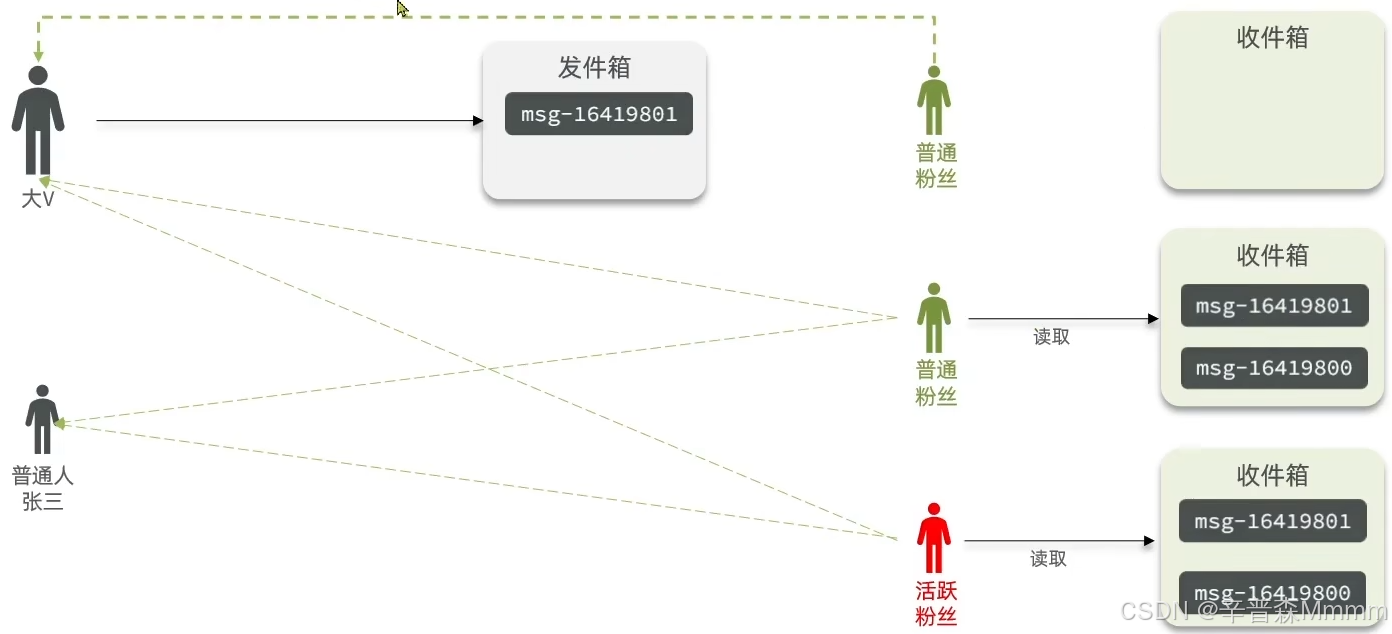
Feed总结
案例:基于推模式的关注推送
需求:
1.修改新增探店笔记的业务,将笔记内容保存到数据库的同时(相对来说,数据库持久且安全),只需要将用户id推到粉丝的收件箱中即可,然后按照用户id再去查询笔记
2.收件箱需要满足按照时间戳进行排序,使用redis数据结构实现(LIst和sortedset都满足排序和利用角标分页查询的功能,但list不支持滚动分页,sortedset支持滚动分页)
3.查询收件箱用户id时,再进行分页查询(因为feed流中的数据会不断更新,数据的角标也在随之变化,若采取传统的分页查询会导致出现内容重复 ,所以要采取滚动分页)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









