






就在今天,阿里又发了个很好玩的大模型——QVQ-Max。
这款模型的特点是,它不仅能够“看懂”图片和视频里的内容,还能结合这些信息进行分析、推理,甚至给出解决方案。
它打破了传统AI模型只能处理单一类型信息的局限,开创了一个全新的交互方式。
比如可以用来看手相。
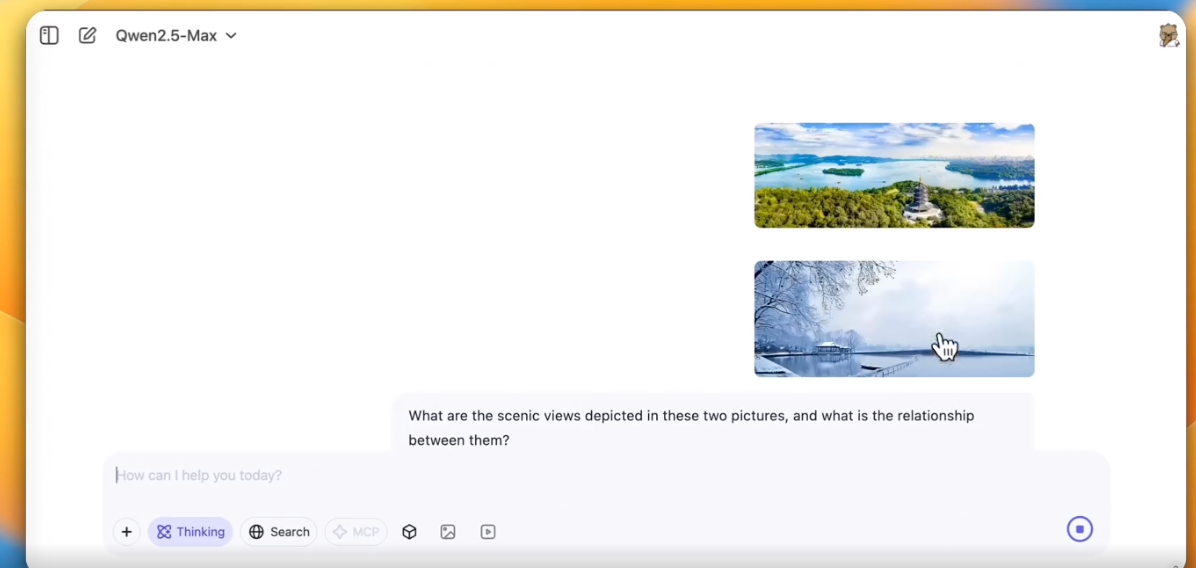
进行多张图片识别。
更牛的是,QVQ-Max还能看视频学编程。
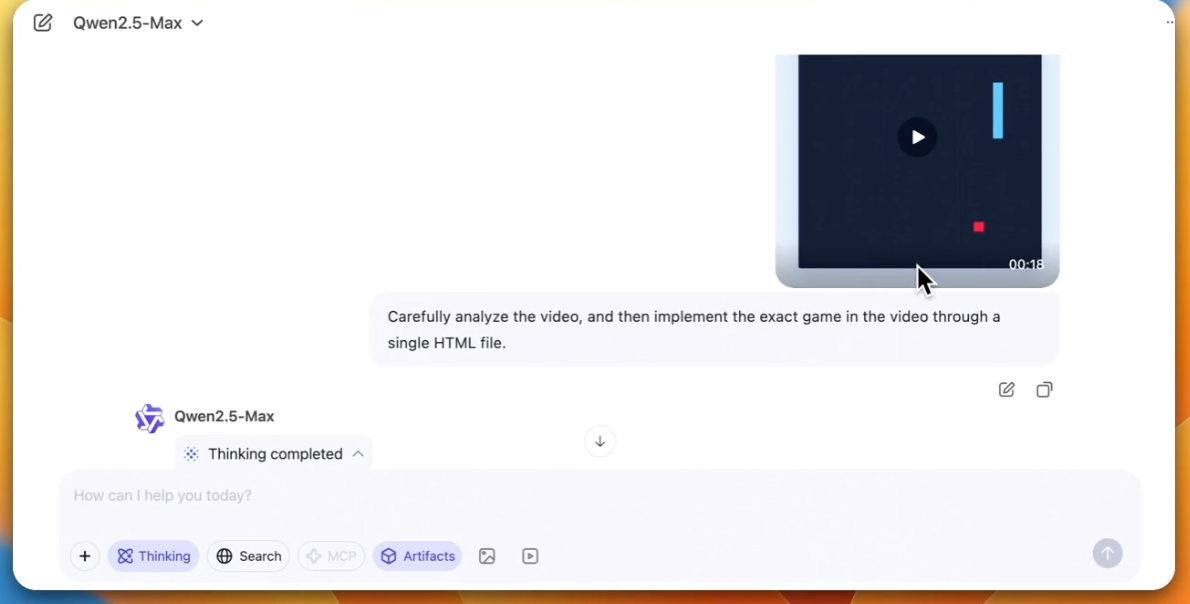
没想到吧,它还能边看视频边学习,是不是非常有意思,下面我们给大家深扒一下这款模型。
与传统视觉模型不同,QVQ-Max通过多层深度学习架构实现了感知与推理的闭环。
其核心技术融合了卷积神经网络(CNN)与自注意力机制,使得模型既能捕捉图像中的微观细节(如手相纹理、数学符号排列),又能通过动态权重分配建立跨元素关联。
例如在分析数学题图像时,模型不仅识别数字,还能构建数字间的逻辑关系网络,最终推导出正确答案。
这是一款既能看又能推理的模型!
核心能力:从观察到推理
QVQ-Max的能力可以总结为三个方面:细致观察、深入推理和灵活应用。下面分别来说说它在这些方面的表现。
-
细致观察:抓住每一个细节
QVQ-Max 对图片的解析能力非常强,无论是复杂的图表还是日常生活中随手拍的照片,它都能快速识别出关键元素。比如,它可以告诉你一张照片里有哪些物品、有什么文字标识,甚至还能指出一些你可能忽略的小细节。
-
深入推理:不只是“看到”,还要“想到”
仅仅识别出图片里的内容还不够,QVQ-Max 还能进一步分析这些信息,并结合背景知识得出结论。例如,在一道几何题中,它可以根据题目附带的图形推导出答案;在一段视频里,它能根据画面内容推测出接下来可能发生的情节。
-
灵活应用:从解答问题到创作
除了分析和推理,QVQ-Max 还能做一些有趣的事情,比如帮你设计插画、生成短视频脚本,甚至根据你的需求创作角色扮演的内容。如果你上传一幅草稿,它可能会帮你完善成一幅完整的作品;上传一个日常照片,它可以化身犀利的评论家,占卜师。
同时QVQ-Max 的应用范围很广,无论是在学习、工作还是日常生活中,它都能派上用场。
对于教育工作者而言,QVQ-Max可以:
-
将复杂的知识点可视化
-
根据学生的学习视频给出个性化建议
-
设计互动性的教学材料
在创意领域,它能够:
-
分析设计稿并提供改进建议
-
理解艺术作品的构图和色彩
-
辅助创作者完成作品
据悉,目前的 QVQ-Max 只是第一版,还有很多可以提升的空间。接下来,会重点关注以下几个方向:
-
更深入的场景理解能力
-
更自然的人机交互方式
-
更广泛的应用场景
QVQ-Max 是一款既有“眼力”又有“脑力”的视觉推理模型。它不仅能识别图片里的内容,还能结合这些信息进行分析和推理,甚至完成一些创造性的任务。
QVQ-Max的诞生,标志着AI技术在视觉认知领域迈出了重要的一步。它不仅仅是一个技术创新,更是未来智能生活的一个缩影。让我们期待它在未来会给我们带来更多惊喜!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









