






transforms
torchvision是一个常用的计算机视觉工具库,包含了模型(model)、数据集(datasets)、数据预处理(transforms)和工具函数(utils)等部分。
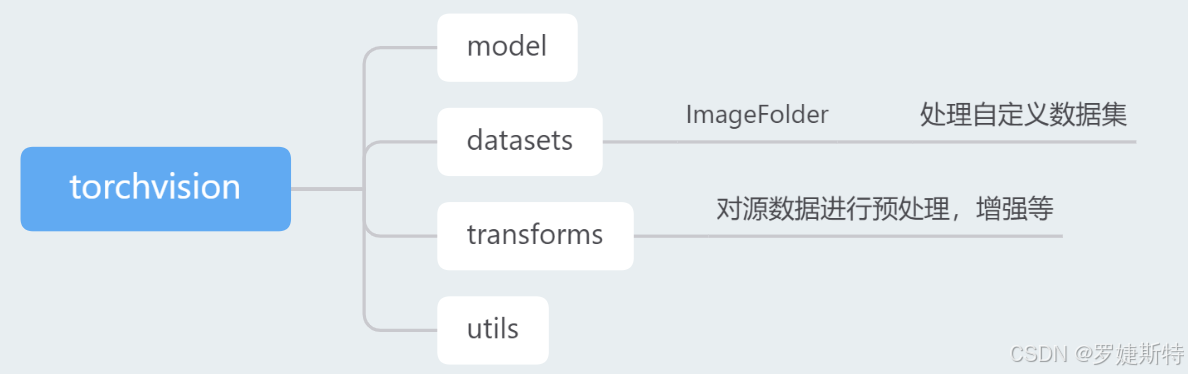
其中,transforms模块提供了对PIL Image对象和Tensor对象的常用操作:
对PIL Image对象的操作,如调整尺寸(Scale/Resize)、裁剪(CenterCrop等)、填充(Pad)、转换为Tensor(ToTensor)、随机水平或垂直翻转(RandomHorizontalFlip、RandomVerticalFlip)、修改亮度对比度饱和度(ColorJitter)等。
对Tensor对象的操作,如标准化(Normalize)和转换为PIL Image(ToPILImage) 。
如果要对数据集进行多个操作,可以使用Compose将这些操作按顺序拼接起来,就像nn.Sequential一样,方便对数据进行批量处理。
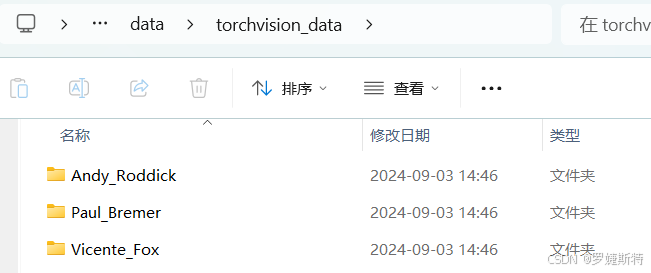
ImageFolderImageFolder类:
它是torchvision库中用于读取图像数据的工具,可以读取不同目录下的图像数据。目录结构示例中,不同人物名字命名的文件夹(如Andy_Roddick、Paul_Bremer等)里存放对应类别的图像。
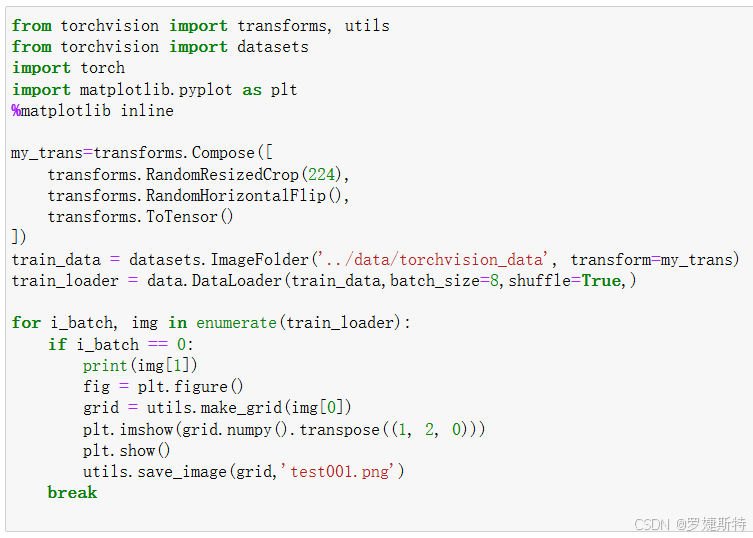
可视化工具:借助matplotlib和torchvision.utils等工具,将加载的图像数据进行可视化,便于直观查看数据样本。这在图像数据集处理和模型训练前的数据分析环节很有用,帮助确认数据是否正确加载和预处理。
可视化工具;
TensorBoard简介使用TensorBoard的一般步骤如下。
1)导入tensorboard,实例化SummaryWriter类,指明记录日志路径等信息。from torch.utils.tensorboard import SummaryWriter#实例化SummaryWriter,并指明日志存放路径。在当前目录没有logs目录将自动创建。
writer = SummaryWriter(log_dir='logs')#调用实例writer.add_xxx()#关闭writerwriter.close()使用TensorBoard的一般步骤如下。
2)调用相应的API接口,接口一般格式为:add_xxx(tag-name, object, iteration-number)#即add_xxx(标签,记录的对象,迭代次数)其中,xxx指的是各种可视化方法。各种可视化方法如下表所示
3)启动tensorboard服务。cd到logs目录所在的同级目录,在命令行输入如下命令,logdir等式右边可以是相对路径或绝对路径。tensorboard --logdir=logs --port 6006
#如果是windows环境,要注意路径解析
如#tensorboard --logdir=r'D:\myboard\test\logs' --port 60064)Web展示。在浏览器输入:http://服务器IP或名称:6006
#如果是本机,服务器名称可以使用localhost用TensorBoard可视化神经网络。
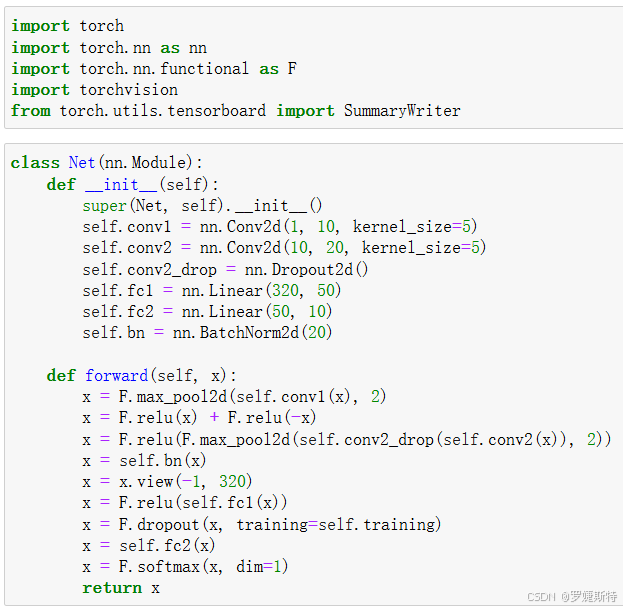
可视化神经网络结构:代码部分定义了一个名为Net的神经网络类,包含卷积层、池化层、全连接层等组件。
通过SummaryWriter类和add_graph方法,将神经网络模型和输入数据传入,保存为graph并记录到指定日志目录。运行结果展示了可视化后的神经网络结构流程图,能直观看到数据在各层之间的流动。

用TensorBoard可视化损失值
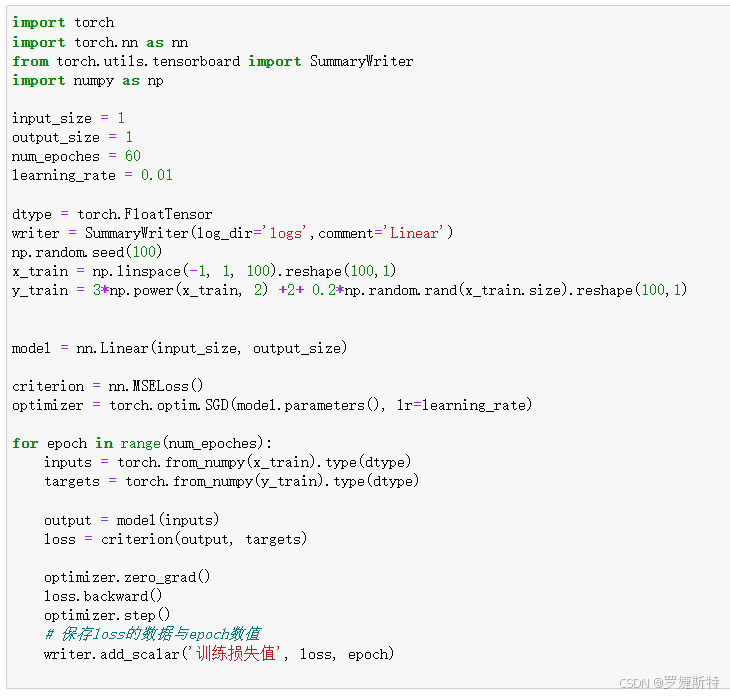
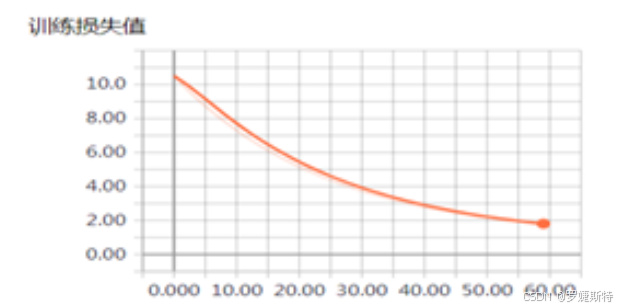
可视化损失值:代码构建了一个简单的线性模型,设置训练参数,利用循环进行训练,并通过SummaryWriter的add_scalar方法记录每个epoch的训练损失值。运行结果以折线图形式呈现损失值随训练轮次的变化趋势,便于观察模型的收敛情况。


用TensorBoard可视化特征图
代码部分:导入相关工具包后,初始化SummaryWriter用于记录日志。通过循环从训练数据加载器中获取数据,对输入数据进行处理。接着遍历神经网络的各层,针对包含“conv”的层(卷积层),提取其特征图,利用make_grid函数将特征图整理成网格形式,并通过add_image方法将特征图写入日志,以便在TensorBoard中可视化。



















 729
729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









