







目录
学习目标:
①Flume海量日志聚合、Flume的能力
②Flume架构、Agent、Source、Channel、Sink、基础架构、多Agent架构、Flume多Agent合并
③Flume架构图、事件events、Source介绍、Channel介绍、Sink介绍
④Flume支持多级级联和多路复制
⑤Flume级联消息压缩、加密
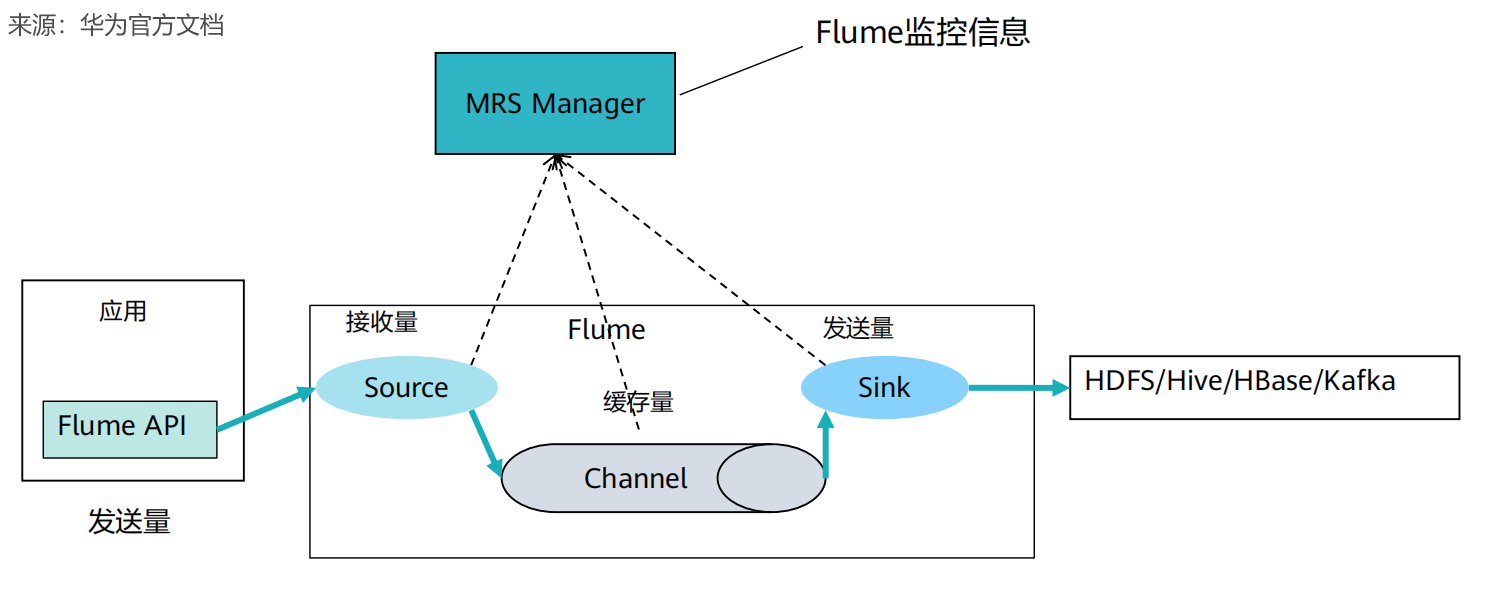
⑥Flume数据监控、MRS
1. Flume海量日志聚合
Flume是流式日志采集工具,Flume提供对数据进行简单处理并写到各种数据接收方的能力
Flume提供从本地文件(spooling directory source目录里采集新的文件内数据)、实时日志(taildir从目录或文件中采集增量数据,exec执行Linux命令的结果被采集)、REST消息、Thrift、Avro、Syslog、Kafka(消费Kafka上未读取的数据,相当于客户端)等数据源上收集数据的能力
(1)提供从固定目录下采集日志信息到目的端(HDFS、HBase、Kafka)能力
(2)提供实时采集日志信息(taildir)到目的地能力
(3)Flume支持级联(多个Flume对接起来),合并数据的能力(远端本端)
(4)Flume支持按照用户定制采集数据的能力
2. Flume架构
由 Source + Channel + Sink = Agent
(1)Flume基础架构,可以单节点直接采集数据,用于集群内数据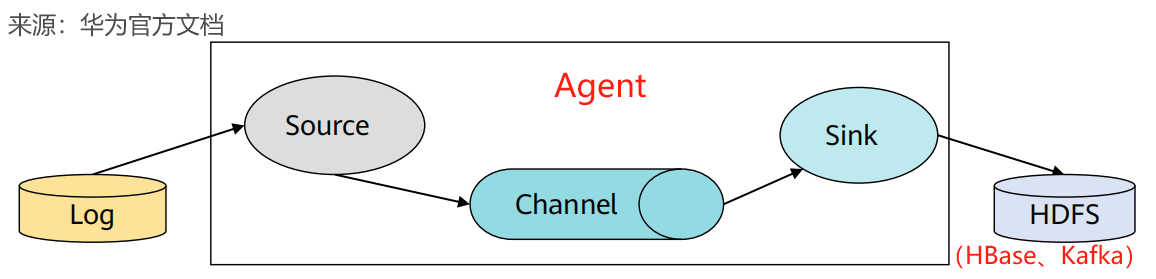
(2)Flume多Agent架构,将多节点连接起来,将最初的数据源经过收集,存储在最终的存储系统中。用于集群外数据导入集群内
(3)Flume多Agent合并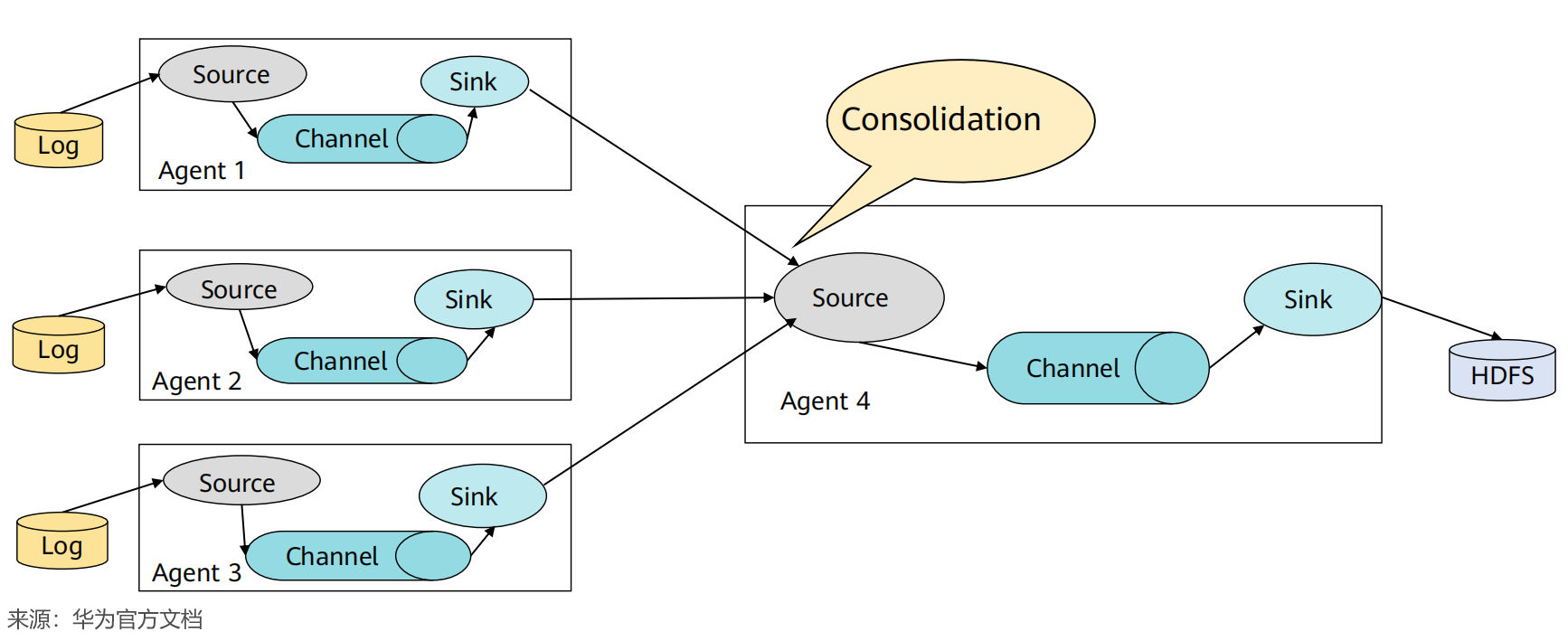
3. Flume架构图
在Flume传递的数据叫"事件events"(事务管理方式)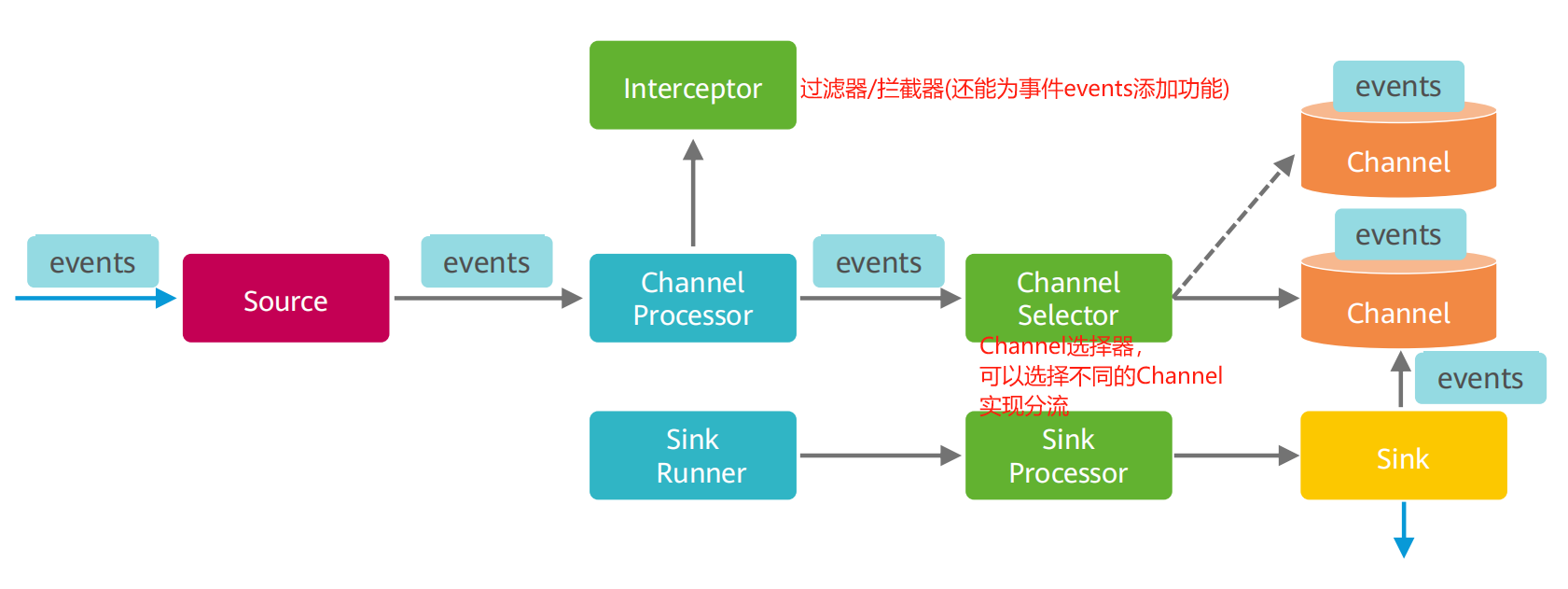
(1)Source
负责接收events或通过特殊机制产生events,并将events批量放到一个或多个Channels
类型:
①驱动型Source:外部主动发送数据给Flume,驱动Flume接受数据
②轮询Source:是Flume周期性主动去获取数据
Source必须至少和一个Channel关联
(2)Channel
Channel位于Source和Sink之间,其作用类似队列,用于临时缓存进来的events,当Sink成功地将events发送到下一跳的Channel或最终目的,events会从Channel移除
Channel支持事务,提供较弱的顺序保证,可以连接任何数量的Source和Sink
类型:
(1)Memory Channel:不会持久化【最快但不安全】
(2)File Channel:基于WAL(预写式日志Write-AheadLog)实现【最安全但慢】
(3)JDBC Channel:基于嵌入式Database实现【兼容两者,不支持数据库扩展】
(1)Memory Channel消息存放在内存中,提供高吞吐,但不提供可靠性,可能丢数据
(2)File Channel对数据持久化,但配置麻烦,需要配置数据目录和checkpoint目录,不同的File Channel均需要配置一个Checkpoint目录
(3)JDBC Channel内置的derby数据库,对event进行了持久化,提供高可靠性,可以取代同样具有持久特性的File Channel(简单取代,文件系统容量还是大)
(3)Sink
Sink负责将events传输到下一跳或最终目的,成功完成后将events从Channel移除
Sink必须作用于一个确切的Channel
4. Flume支持多级级联和多路复制
Flume支持将多个Flume级联起来,同时级联节点内部支持数据复制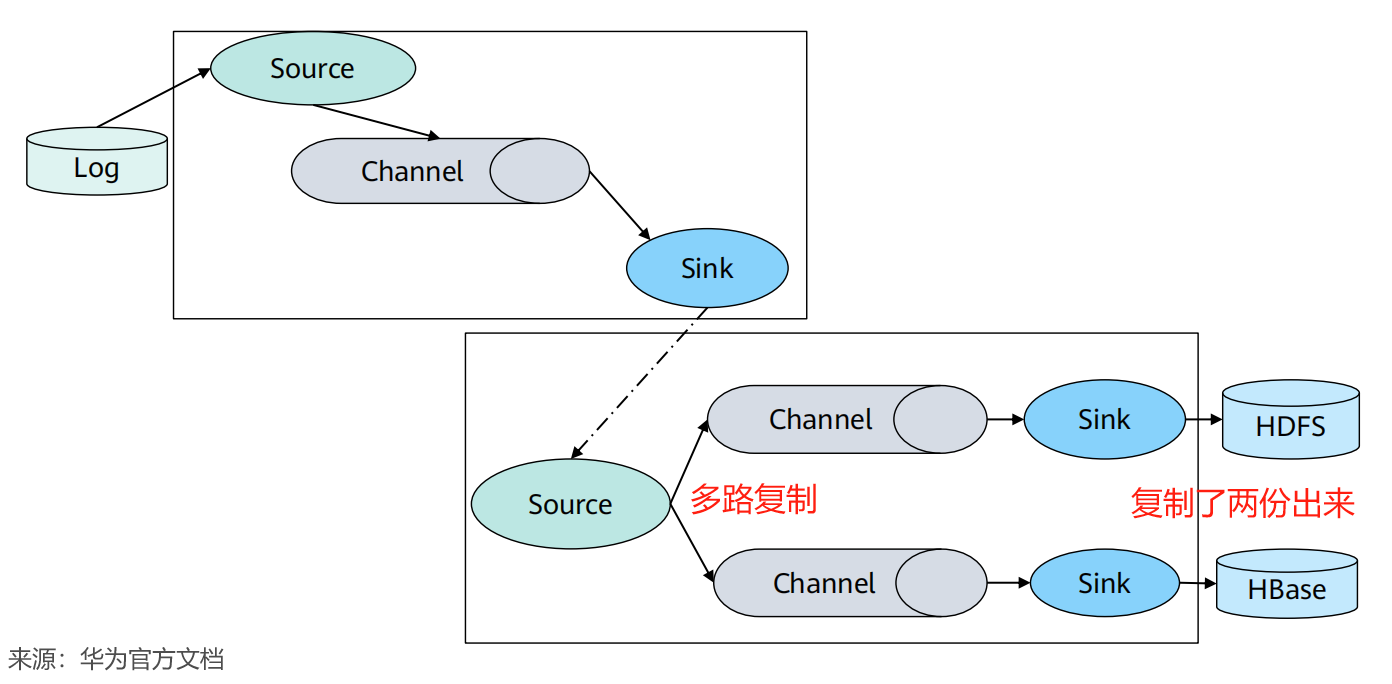
5. Flume级联消息压缩、加密
Flume级联节点之间的数据传输支持压缩和加密,提升数据传输效率和安全性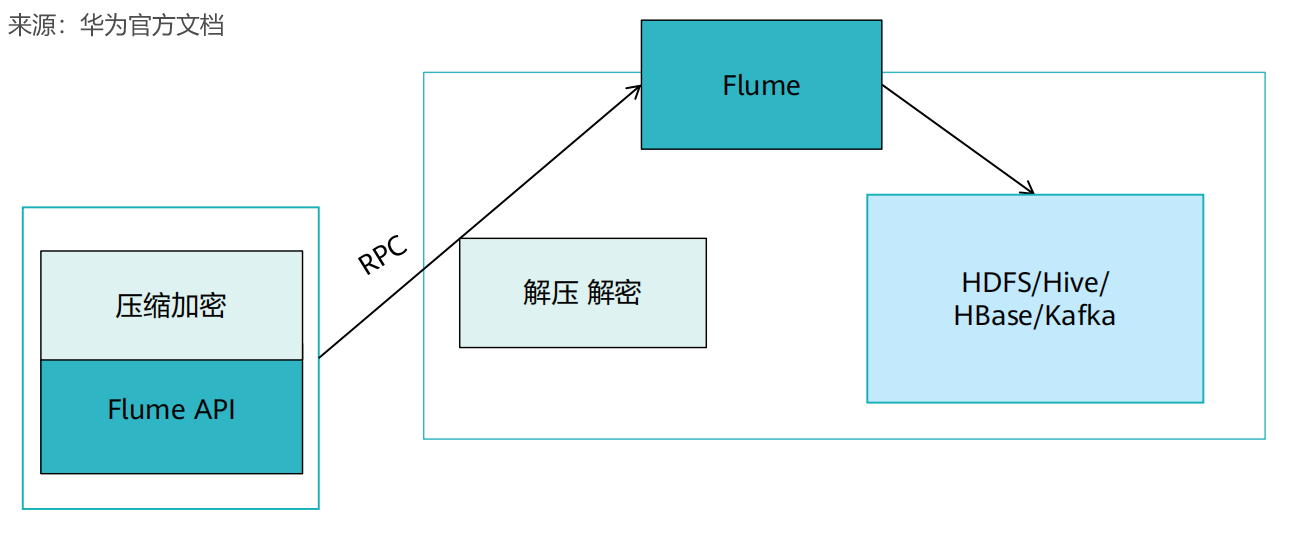


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









