







第01章 Java入门
1.计算机的硬件与软件
1.1计算机组成:硬件+软件
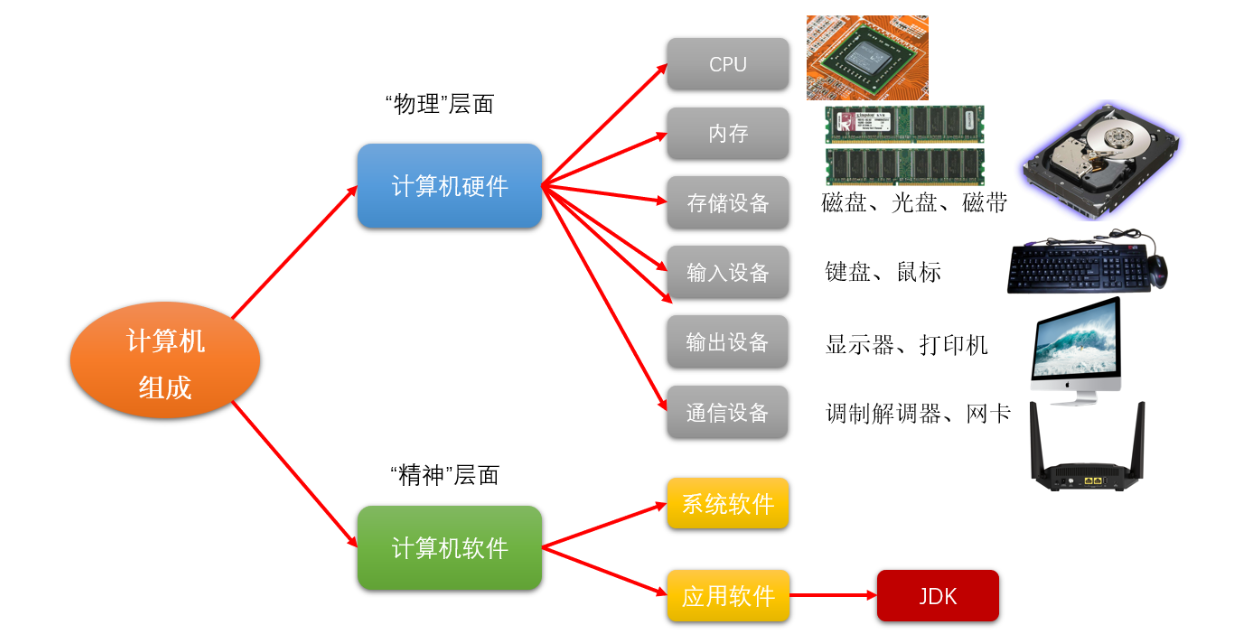
1.2 CPU、内存与硬盘
-
CPU(Central Processing Unit,中央处理器)
-
人靠大脑思考,电脑靠CPU来运算、控制。
-
-
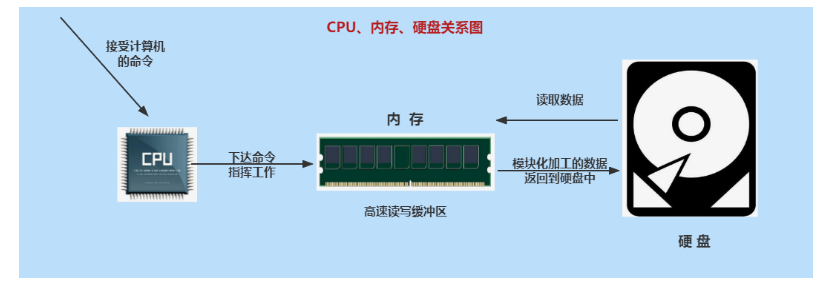
硬盘(Hard Disk Drive)
-
计算机最主要的存储设备,容量大,断电数据不丢失。
-
正常分类:
机械硬盘(HDD)、固态硬盘(SSD)以及混合硬盘(SSHD) -
固态硬盘在开机速度和程序加载速度远远高于机械硬盘,缺点就是贵,所有无法完全取代机械硬盘。
-
-
内存(Memory)
-
负责硬盘上的数据与CPU之间数据交换处理
-
具体的:保存从硬盘读取的数据,提供给CPU使用;保存CPU的一些临时执行结果,以便CPU下次使用或保存到硬盘。
-
断电后数据丢失。
-
-
1.3 输入设备:键盘输入
2. 软件相关介绍
2.1 什么是软件
软件,即一系列按照特定顺序组织的计算机数据和指令的集合。有系统软件和应用软件之分。
Pascal之父Nicklaus Wirth: “Programs = Data Structures + Algorithms”
系统软件:

应用软件:

2.2 人机交互方式
-
图形化界面(Graphical User Interface,GUI),这种方式简单直观,使用者易于接受,容易上手操作。
-
命令行方式(Command Line Interface,CLI),需要在控制台输入特定的
指令,让计算机完成一些操作。需要记忆一些指令,较为麻烦。
2.3 常用的DOS命令
DOS(Disk Operating System,磁盘操作系统)是Microsoft公司在Windows之前推出的一个操作系统,是
单用户、单任务(即只能执行一个任务)的操作系统。现在被Windows系统取代。
对于Java初学者,学习一些DOS命令,会非常有帮助。
进入DOS操作窗口:
按下Windows+R键盘,打开运行窗口,输入cmd回车,进入到DOS的操作窗口。
常用指令:
-
操作1:进入和回退
| 操作 | 说明 |
|---|---|
| 盘符名称: | 盘符切换。E:回车,表示切换到E盘。 |
| dir | 列出当前目录下的文件以及文件夹 |
| cd 目录 | 进入指定单级目录。 |
| cd 目录1\目录2\... | 进入指定多级目录。cd atguigu\JavaSE |
| cd .. | 回退到上一级目录。 |
| cd \ 或 cd / | 回退到盘符目录。 |
-
操作2:增、删
| 操作 | 说明 |
|---|---|
| md 文件目录名 | 创建指定的文件目录。 |
| rd 文件目录名 | 删除指定的文件目录(如文件目录内有数据,删除失败) |
-
操作3:其它
| 操作 | 说明 |
|---|---|
| cls | 清屏。 |
| exit | 退出命令提示符窗口。 |
| ← → | 移动光标 |
| ↑ ↓ | 调阅历史操作命令 |
| Delete和Backspace | 删除字符 |
3. 计算机编程语言
3.1 计算机语言是什么
-
语言:是人与人之间用于沟通的一种方式。例如:中国人与中国人用普通话沟通。而中国人要和英国人交流,可以使用普通话或英语。
-
计算机编程语言,就是人与计算机交流的方式。人们可以使用
编程语言对计算机下达命令,让计算机完成人们需要的功能。 -
计算机语言有很多种。如:C 、C++、Java、Go、JavaScript、Python,Scala等。
体会:语言 = 语法 + 逻辑
3.2 计算机语言简史
-
第一代:机器语言(相当于人类的石器时代)
-
1946年2月14日,世界上第一台计算机
ENAC诞生,使用的是最原始的穿孔卡片。这种卡片上使用的是二进制代码,这种语言就称为机器语言。比如:举例1 0000,0000,000000010000 代表 LOAD A, 16 举例2 0000,0001,000000000001 代表 LOAD B, 1 举例3 0001,0001,000000010000 代表 STORE B, 16
-
这种语言本质上是计算机能识别的唯一语言,人类很难理解。可以大胆想象"
此时的程序员99.9%都是异类!"
-
-
第二代:汇编语言(相当于人类的青铜&铁器时代)
-
使用英文缩写的
助记符来表示基本的操作。比如:LOAD、MOVE等,使人更容易使用。因此,汇编语言也称为符号语言。 -
优点:能编写
高效率的程序 -
缺点:程序不易移植,较难调试。不同计算机机型特点不同,因此会有不同的汇编语言,彼此之间
不能通用。 -
第三代:高级语言(相当于人类的信息时代)
4. Java语言概述
4.1 Java概述
-
是
SUN(Stanford University Network,斯坦福大学网络公司 )1995年推出的一门高级编程语言。
4.2 Java语言简史
起步阶段:
1991年,Sun公司的工程师小组想要设计一种语言,应用在电视机、电话、闹钟、烤面包机等家用电器的控制和通信。由于这些设备的处理能力和内存都很有限,并且不同的厂商会选择不同的CPU,因此这种语言的关键是代码短小、紧凑且与平台无关(即不能与任何特定的体系结构捆绑在一起)。
Gosling团队率先创造了这个语言,并命名为“Oak"(起名的原因是因为他非常喜欢自己办公室外的橡树)。后因智能化家电的市场需求没有预期的高,Sun公司放弃了该项计划。
随着20世纪90年代互联网的发展,Sun公司发现该语言在互联网上应用的前景,于是改造了Oak,于1995年5月以Java的名称正式发布。(Java是印度尼西亚爪哇岛的英文名称,因盛产咖啡而闻名。)
4.3 Java之父
-
詹姆斯·高斯林(James Gosling)先生以“Java 技术之父”而闻名于世。他是Java 技术的创始人,他亲手设计了Java语言,并开发了Java编译器和Java虚拟机,使Java成为了世界上最流行的开发语言。 -
James Gosling于1984 年加入Sun公司,并一直服务于Sun公司,直至2010年前后,Sun被Oracle并购而加入Oracle,担任客户端软件集团的首席技术官; 2010年4月从Oracle离职。
4.4 Java技术体系平台
-
Java SE(Java Standard Edition)标准版
-
支持面向
桌面级应用(如Windows下的应用程序)的Java平台,即定位个人计算机的应用开发。 -
此版本以前称为
J2SE
-
-
Java EE(Java Enterprise Edition)企业版
-
为开发企业环境下的应用程序提供的一套解决方案,即定位
在服务器端的Web应用开发。 -
版本以前称为
J2EE
-
-
Java ME(Java Micro Edition)小型版
-
支持Java程序运行在
移动终端(手机、机顶盒)上的平台,即定位在消费性电子产品的应用开发 -
此版本以前称为
J2ME
-
5. Java开发环境搭建(掌握)
5.1 什么是JDK、JRE
-
JDK (
JavaDevelopmentKit):是Java程序开发工具包,包含JRE和开发人员使用的工具。 -
JRE (
JavaRuntimeEnvironment) :是Java程序的运行时环境,包含JVM和运行时所需要的核心类库。
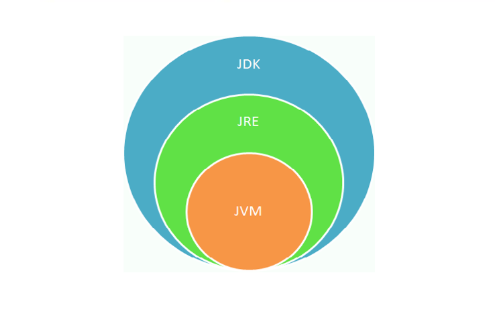
小结:
JDK = JRE + 开发工具集(例如Javac编译工具等)
JRE = JVM + Java SE标准类库
5.2 配置path环境变量
5.2.1 理解path环境变量
什么是path环境变量?
答:window操作系统执行命令时,所要搜寻的路径。
为什么配置path?
答:希望在命令行使用javac.exe等工具时,任意目录下都可以找到这个工具所在的目录。
5.2.2 JDK17配置方案1:只配置path
-
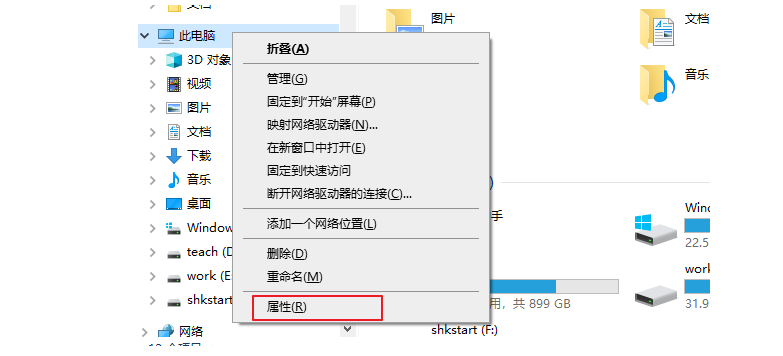
步骤:
(1)打开桌面上的计算机,进入后在左侧找到此电脑,单击鼠标右键,选择属性,如图所示:
(2)选择高级系统设置,如图所示:

(3)在高级选项卡,单击环境变量,如图所示:
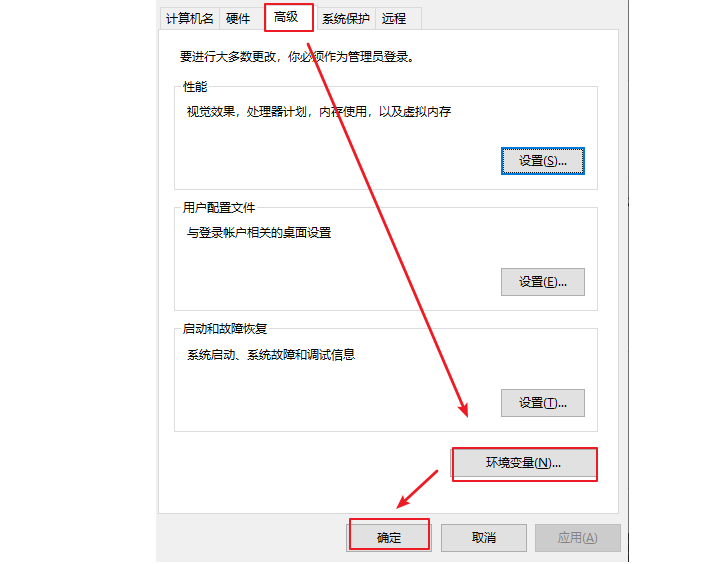
(4)在系统变量中,选中Path 环境变量,双击或者点击编辑 ,如图所示:
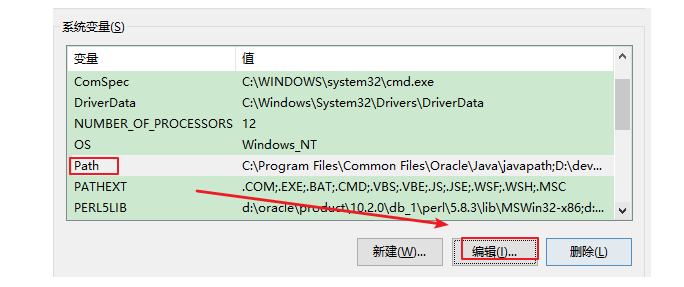
(5)点击新建,填入(具体的JDK的安装目录) ,并将此值上移到变量列表的首位。如图所示:
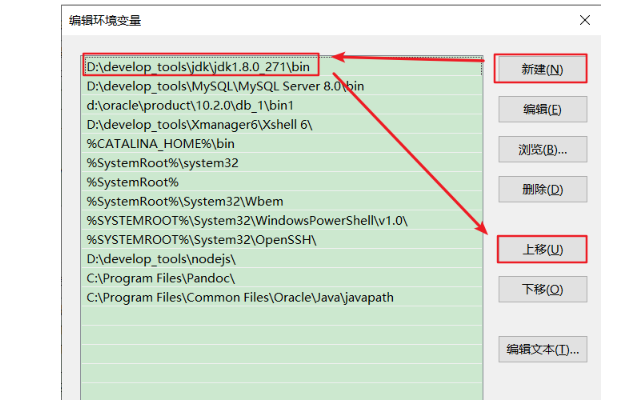
(6)环境变量配置完成,重新开启DOS命令行,在任意目录下输入javac 或java命令或java -version,运行成功。
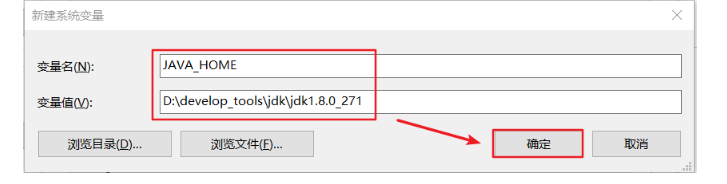
5.2.3 JDK17配置方案2:配置JAVA_HOME+path(推荐)
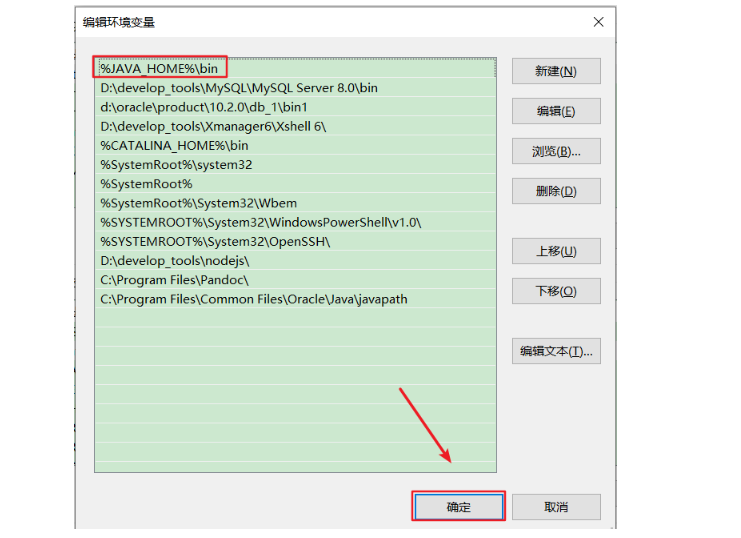

6. 开发体验:HelloWorld(掌握)
JDK安装完毕,我们就可以开发第一个Java程序了,习惯性的称为:HelloWorld。
6.1 开发步骤
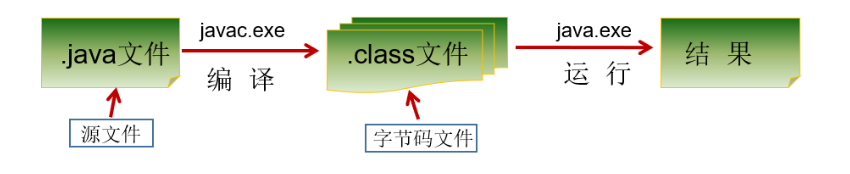
Java程序开发三步骤:编写、编译、运行。
-
将 Java 代码编写到扩展名为 .java 的源文件中
-
通过 javac.exe 命令对该 java 文件进行编译,生成一个或多个字节码文件
-
通过 java.exe 命令对生成的 class 文件进行运行
6.2注意点:
(1)源文件名是否必须与类名一致?public呢?
- 如果这个类不是public,那么源文件名可以和类名不一致。但是不便于代码维护。
- 如果这个类是public,那么要求源文件名必须与类名一致。否则编译报错。
- 我们建议大家,不管是否是public,都与源文件名保持一致,而且一个源文件尽量只写一个类,目的是为了好维护。
(2)一个源文件中是否可以有多个类?public呢?
- 一个源文件中可以有多个类,编译后会生成多个.class字节码文件。
- 但是一个源文件只能有一个public的类。
7. 注释(comment)
7.1 什么是注释
-
什么是注释?
-
源文件中用于解释、说明程序的文字就是注释。
-
-
注释的作用
-
它提升了程序的可阅读性。
-
调试程序的重要方法。
-
-
不加注释的危害
注释是一个程序员必须要具有的良好编程习惯。实际开发中,程序员可以先将自己的思想通过注释整理出来,再用代码去体现。
程序员最讨厌两件事:
一件是自己写代码被要求加注释
另一件是接手别人代码,发现没有注释
7.2 Java中的注释类型
- 单行注释
//注释文字
- 多行注释
/*
注释文字1
注释文字2
注释文字3
*/
- 文档注释 (Java特有)
/**
@author 指定java程序的作者
@version 指定源文件的版本
*/
说明:
-
多行注释里面不允许有多行注释嵌套。
-
对于单行和多行注释,被注释的文字,不会不会出现在字节码文件中,进而不会被JVM(java虚拟机)解释执行。
8. Java API文档
-
。API (Application Programming Interface,应用程序编程接口)是 Java 提供的基本编程接口。
-
Java语言提供了大量的基础类,因此 Oracle 也为这些基础类提供了相应的说明文档,用于告诉开发者如何使用这些类,以及这些类里包含的方法。大多数Java书籍中的类的介绍都要参照它来完成,它是编程者经常查阅的资料。
-
Java API文档,即为JDK使用说明书、帮助文档。
9. Java核心机制:JVM(了解)
9.1 Java语言的优点
Java确实是从C语言和C++语言继承了许多成份,甚至可以将Java看成是类C语言发展和衍生的产物。“青出于蓝,而胜于蓝”。
特性1:跨平台性
-
这是Java的核心优势。Java在最初设计时就很注重移植和跨平台性。比如:Java的int永远都是32位。不像C++可能是16,32,可能是根据编译器厂商规定的变化。
-
通过Java语言编写的应用程序在不同的系统平台上都可以运行。“
Write once , Run Anywhere”。 -
原理:只要在需要运行 java 应用程序的操作系统上,先安装一个Java虚拟机 (
JVM ,JavaVirtualMachine) 即可。由JVM来负责Java程序在该系统中的运行。
特性2:面向对象性
面向对象是一种程序设计技术,非常适合大型软件的设计和开发。面向对象编程支持封装、继承、多态等特性,让程序更好达到高内聚,低耦合的标准。
特性3:健壮性
吸收了C/C++语言的优点,但去掉了其影响程序健壮性的部分(如指针、内存的申请与释放等),提供了一个相对安全的内存管理和访问机制。
9.2 JVM功能说明
JVM(Java Virtual Machine ,Java虚拟机):是一个虚拟的计算机,是Java程序的运行环境。JVM具有指令集并使用不同的存储区域,负责执行指令,管理数据、内存、寄存器。
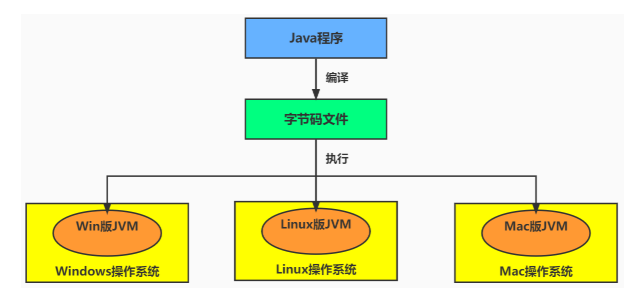
9.2.1 功能1:实现Java程序的跨平台性
我们编写的Java代码,都运行在JVM 之上。正是因为有了JVM,才使得Java程序具备了跨平台性。
9.2.2 功能2:自动内存管理(内存分配、内存回收)
-
Java程序在运行过程中,涉及到运算的
数据的分配、存储等都由JVM自动来完成。 -
Java消除了程序员回收无用内存空间的职责。提供了一种系统级线程跟踪存储空间的分配情况,在内存空间达到相应阈值时,检查并释放可被释放的存储器空间。
-
GC的自动回收,提高了内存空间的利用效率,也提高了编程人员的效率,很大程度上
减少了因为没有释放空间而导致的内存泄漏。
面试题:
Java程序还会出现内存溢出和内存泄漏问题吗? Yes
10. 工程与模块管理
10.1 IDEA项目结构
层级关系:
project(工程) - module(模块) - package(包) - class(类)
具体的:
- 一个project中可以创建多个module
- 一个module中可以创建多个package
- 一个package中可以创建多个class
这些结构的划分,是为了方便管理功能代码。
在 IntelliJ IDEA 中Project是最顶级的结构单元,然后就是Module。目前,主流的大型项目结构基本都是多Module的结构,这类项目一般是按功能划分的,比如:user-core-module、user-facade-module和user-hessian-module等等,模块之间彼此可以相互依赖,有着不可分割的业务关系。因此,对于一个Project来说:
-
当为单Module项目的时候,这个单独的Module实际上就是一个Project。
-
当为多Module项目的时候,多个模块处于同一个Project之中,此时彼此之间具有
互相依赖的关联关系。 -
当然多个模块没有建立依赖关系的话,也可以作为单独一个“小项目”运行。
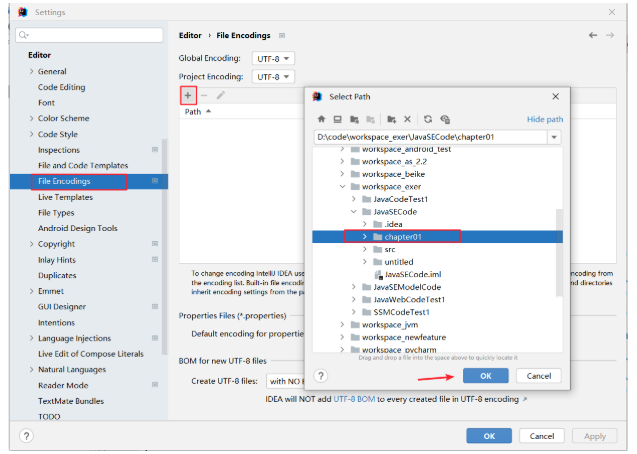
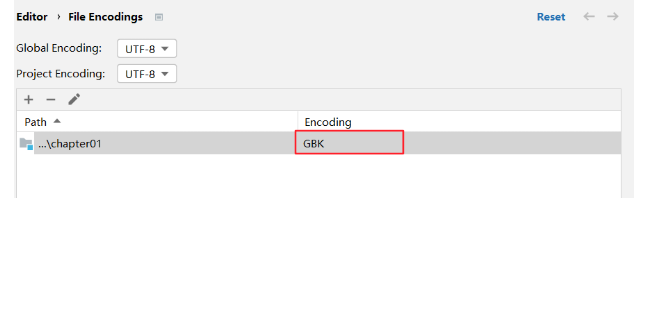
当前项目是UTF-8。如果原来的.java文件都是GBK的(如果原来.java文件有的是GBK,有的是UTF-8就比较麻烦了)。
可以单独把这两个模块设置为GBK编码的。
第02章_变量与进制
1. 关键字(keyword)
-
定义:被Java语言赋予了特殊含义,用做专门用途的字符串(或单词)
-
HelloWorld案例中,出现的关键字有
class、public、static、void等,这些单词已经被Java定义好了。
-
-
特点:全部关键字都是
小写字母。 -
关键字比较多,不需要死记硬背,学到哪里记到哪里即可。
-
官方地址: https://docs.oracle.com/javase/tutorial/java/nutsandbolts/_keywords.html
说明:
关键字一共
50个,其中const和goto是保留字(reserved word)。
true,false,null不在其中,它们看起来像关键字,其实是字面量,表示特殊的布尔值和空值。
2. 标识符( identifier)
Java中变量、方法、类等要素命名时使用的字符序列,称为标识符。
技巧:凡是自己可以起名字的地方都叫标识符。
标识符的命名规则(必须遵守的硬性规定):
> 由26个英文字母大小写,0-9 ,_或 $ 组成 > 数字不可以开头。 > 不可以使用关键字和保留字,但能包含关键字和保留字。 > Java中严格区分大小写,长度无限制。 > 标识符不能包含空格。
标识符的命名规范(建议遵守的软性要求,否则工作时容易被鄙视):
> 包名:多单词组成时所有字母都小写:xxxyyyzzz。
例如:java.lang、com.atguigu.bean
> 类名、接口名:多单词组成时,所有单词的首字母大写:XxxYyyZzz
例如:HelloWorld,String,System等
> 变量名、方法名:多单词组成时,第一个单词首字母小写,第二个单词开始每个单词首字母大写:xxxYyyZzz
例如:age,name,bookName,main,binarySearch,getName
> 常量名:所有字母都大写。多单词时每个单词用下划线连接:XXX_YYY_ZZZ
例如:MAX_VALUE,PI,DEFAULT_CAPACITY
同时在起那个包名的时候不要直接用java,不然会触发双亲委派机制,会报错的。
注意:在起名字时,为了提高阅读性,要尽量有意义,“见名知意”。
一个包下,不能出现同名的类。原因:调用时,无法通过包名+类名区分这两个类。
不同的包下,可以存在同名的类。
3. 变量
3.1 为什么需要变量
变量是程序中不可或缺的组成单位,最基本的存储单元。
3.2 初识变量
-
变量的概念:
-
内存中的一个存储区域,该区域的数据可以在同一类型范围内不断变化
-
变量的构成包含三个要素:
数据类型、变量名、存储的值 -
Java中变量声明的格式:
数据类型 变量名 = 变量值
-
-
变量的作用:用于在内存中保存数据。
-
使用变量注意:
-
Java中每个变量必须先声明,后使用。
-
使用变量名来访问这块区域的数据。
-
变量的作用域:其定义所在的一对{ }内。
-
变量只有在其
作用域内才有效。出了作用域,变量不可以再被调用。 -
同一个作用域内,不能定义重名的变量。
-
3.3 Java中变量的数据类型
Java中变量的数据类型分为两大类:
-
基本数据类型:包括
整数类型、浮点数类型、字符类型、布尔类型。 -
引用数据类型:包括
数组(array)、类(class)、接口(interface)、枚举(enum)、注解(annotation)、记录(record)。
4. 基本数据类型介绍
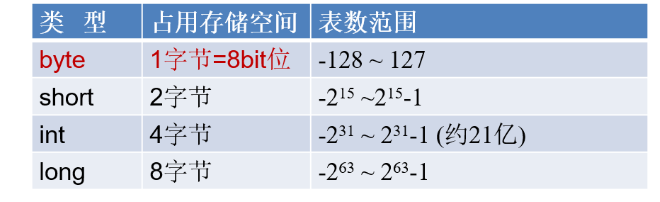
4.1 整数类型:byte、short、int、long
-
Java各整数类型有固定的表数范围和字段长度,不受具体操作系统的影响,以保证Java程序的可移植性。
-
-
定义long类型的变量,赋值时需要以"
l"或"L"作为后缀。 -
Java程序中变量通常声明为int型,除非不足以表示较大的数,才使用long。
-
Java的整型
常量默认为 int 型。
4.1.1 补充:计算机存储单位
-
字节(Byte):是计算机用于
计量存储容量的基本单位,一个字节等于8 bit。 -
位(bit):是数据存储的
最小单位。二进制数系统中,每个0或1就是一个位,叫做bit(比特),其中8 bit 就称为一个字节(Byte)。 -
转换关系:
-
8 bit = 1 Byte
-
1024 Byte = 1 KB
-
1024 KB = 1 MB
-
1024 MB = 1 GB
-
1024 GB = 1 TB
-
4.2 浮点类型:float、double
-
与整数类型类似,Java 浮点类型也有固定的表数范围和字段长度,不受具体操作系统的影响。
-

-
浮点型常量有两种表示形式:
-
十进制数形式。如:5.12 512.0f .512 (必须有小数点)
-
科学计数法形式。如:5.12e2 512E2 100E-2
-
-
float:
单精度,尾数可以精确到7位有效数字。很多情况下,精度很难满足需求。 -
double:
双精度,精度是float的两倍。通常采用此类型。 -
定义float类型的变量,赋值时需要以"
f"或"F"作为后缀。 -
Java 的浮点型
常量默认为double型。 -
float类型的表述范围要大于long类型的表述范围。
Math.round()可以对小数进行四舍五入
4.2.1 关于浮点型精度的说明
-
并不是所有的小数都能可以精确的用二进制浮点数表示。二进制浮点数不能精确的表示0.1、0.01、0.001这样10的负次幂。
-
浮点类型float、double的数据不适合在
不容许舍入误差的金融计算领域。如果需要精确数字计算或保留指定位数的精度,需要使用BigDecimal类。
4.3 字符类型:char
-
char 型数据用来表示通常意义上“
字符”(占2字节) -
Java中的所有字符都使用Unicode编码,故一个字符可以存储一个字母,一个汉字,或其他书面语的一个字符。
-
字符型变量的三种表现形式:
-
形式1:使用单引号(' ')括起来的
单个字符。例如:char c1 = 'a'; char c2 = '中'; char c3 = '9';
-
形式2:直接使用
Unicode值来表示字符型常量:‘\uXXXX’。其中,XXXX代表一个十六进制整数。例如:\u0023 表示 '#'。
-
形式3:Java中还允许使用
转义字符‘\’来将其后的字符转变为特殊字符型常量。例如:char c3 = '\n'; // '\n'表示换行符
-
| 转义字符 | 说明 | Unicode表示方式 |
|---|---|---|
\n | 换行符 | \u000a |
\t | 制表符 | \u0009 |
\" | 双引号 | \u0022 |
\' | 单引号 | \u0027 |
\\ | 反斜线 | \u005c |
\b | 退格符 | \u0008 |
\r | 回车符 | \u000d |
- char类型是可以进行运算的。因为它都对应有Unicode码,可以看做是一个数值。
4.4 布尔类型:boolean
-
boolean 类型用来判断逻辑条件,一般用于流程控制语句中:
-
if条件控制语句;
-
while循环控制语句;
-
for循环控制语句;
-
do-while循环控制语句;
-
-
boolean类型数据只有两个值:true、false,无其它。
-
不可以使用0或非 0 的整数替代false和true,这点和C语言不同。
-
拓展:Java虚拟机中没有任何供boolean值专用的字节码指令,Java语言表达所操作的boolean值,在编译之后都使用java虚拟机中的int数据类型来代替:true用1表示,false用0表示。——《java虚拟机规范 8版》
-
经验之谈:
Less is More!建议不要这样写:if ( isFlag = = true ),只有新手才如此。关键也很容易写错成if(isFlag = true),这样就变成赋值isFlag为true而不是判断!
老鸟的写法是if (isFlag)或者if ( !isFlag)。
5. 基本数据类型变量间运算规则
在Java程序中,不同的基本数据类型(只有7种,不包含boolean类型)变量的值经常需要进行相互转换。
转换的方式有两种:自动类型提升和强制类型转换。
5.1 自动类型提升(隐式类型转换)
规则:将取值范围小(或容量小)的类型自动提升为取值范围大(或容量大)的类型 。
注意点:此时的容量大小,指的是表示数据的范围的大小,而并非占用字节数的大小。比如:float的容量要大于long的容量。
特殊情况:byte,short,char三者之间做运算时,结果默认为int类型。
基本数据类型的转换规则如图所示:

5.2 强制类型转换(显式类型转换)
规则:将取值范围大(或容量大)的类型强制转换成取值范围小(或容量小)的类型。
自动类型提升是Java自动执行的,而强制类型转换是自动类型提升的逆运算,需要我们自己手动执行。
(1)当把存储范围大的值(常量值、变量的值、表达式计算的结果值)强制转换为存储范围小的变量时,可能会损失精度或溢出。
(2)声明long类型变量时,可以出现省略后缀的情况。float则不同。
问答:为什么标识符的声明规则里要求不能数字开头?
//如果允许数字开头,则如下的声明编译就可以通过:
int 123L = 12;
//进而,如下的声明中l的值到底是123?还是变量123L对应的取值12呢? 出现歧义了。
long l = 123L;5.3 基本数据类型与String的运算
5.3.1 字符串类型:String
-
String不是基本数据类型,属于引用数据类型,俗称字符串。
-
使用一对
""来表示一个字符串,内部可以包含0个、1个或多个字符。 -
声明方式与基本数据类型类似。例如:String str = “学Java”;
5.3.2 运算规则
1、任意八种基本数据类型的数据与String类型只能进行连接“+”运算,且结果一定也是String类型
System.out.println("" + 1 + 2);//12
int num = 10;
boolean b1 = true;
String s1 = "abc";
String s2 = s1 + num + b1;
System.out.println(s2);//abc10true
//String s3 = num + b1 + s1;//编译不通过,因为int类型不能与boolean运算
String s4 = num + (b1 + s1);//编译通过2、String类型不能通过强制类型()转换,转为其他的类型
String str = "123";
int num = (int)str;//错误的
int num = Integer.parseInt(str);//正确的,后面才能讲到,借助包装类的方法才能转5.4Unicode码
-
Unicode编码为表达
任意语言的任意字符而设计,也称为统一码、标准万国码。Unicode 将世界上所有的文字用2个字节统一进行编码,为每个字符设定唯一的二进制编码,以满足跨语言、跨平台进行文本处理的要求。 -
Unicode 的缺点:这里有三个问题:
-
第一,英文字母只用一个字节表示就够了,如果用更多的字节存储是
极大的浪费。 -
第二,如何才能
区别Unicode和ASCII?计算机怎么知道两个字节表示一个符号,而不是分别表示两个符号呢? -
第三,如果和GBK等双字节编码方式一样,用最高位是1或0表示两个字节和一个字节,就少了很多值无法用于表示字符,
不够表示所有字符。
-
-
Unicode在很长一段时间内无法推广,直到互联网的出现,为解决Unicode如何在网络上传输的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现。具体来说,有三种编码方案,UTF-8、UTF-16和UTF-32。
-
准出现。具体来说,有三种编码方案,UTF-8、UTF-16和UTF-32。
5.5 UTF-8
-
Unicode是字符集,UTF-8、UTF-16、UTF-32是三种
将数字转换到程序数据的编码方案。顾名思义,UTF-8就是每次8个位传输数据,而UTF-16就是每次16个位。其中,UTF-8 是在互联网上使用最广的一种 Unicode 的实现方式。 -
互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。所以,我们开发Web应用,也要使用UTF-8编码。UTF-8 是一种
变长的编码方式。它可以使用 1-4 个字节表示一个符号它使用一至四个字节为每个字符编码,编码规则:-
128个US-ASCII字符,只需一个字节编码。
-
拉丁文等字符,需要二个字节编码。
-
大部分常用字(含中文),使用三个字节编码。
-
其他极少使用的Unicode辅助字符,使用四字节编码。
-
第03章_运算符与流程控制
1. 运算符(Operator)
运算符是一种特殊的符号,用以表示数据的运算、赋值和比较等。
运算符的分类:
- -按照功能分为:算术运算符、赋值运算符、比较(或关系)运算符、逻辑运算符、位运算符、条件运算符、Lambda运算符。
| 分类 | 运算符 |
|---|---|
| 算术运算符(7个) | +、-、*、/、%、++、-- |
| 赋值运算符(12个) | =、+=、-=、*=、/=、%=、>>=、<<=、>>>=、&=、|=、^=等 |
| 比较(或关系)运算符(6个) | >、>=、<、<=、==、!= |
| 逻辑运算符(6个) | &、|、^、!、&&、|| |
| 位运算符(7个) | &、|、^、~、<<、>>、>>> |
| 条件运算符(1个) | (条件表达式)?结果1:结果2 |
| Lambda运算符(1个) | ->(第18章时讲解) |
- 按照操作数个数分为:一元运算符(单目运算符)、二元运算符(双目运算符)、三元运算符 (三目运算符)
-
分类 运算符 一元运算符(单目运算符) 正号(+)、负号(-)、++、--、!、~ 二元运算符(双目运算符) 除了一元和三元运算符剩下的都是二元运算符 三元运算符 (三目运算符) (条件表达式)?结果1:结果2
1.1 算术运算符
1.1.1 基本语法
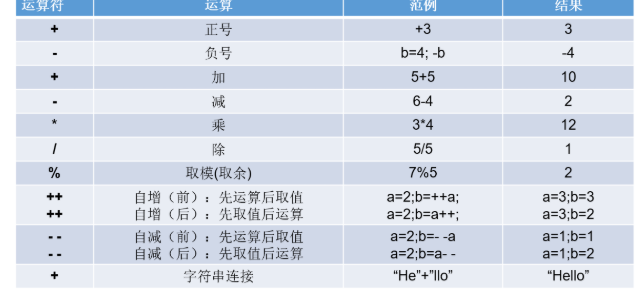
//结果与被模数符号相同
System.out.println(5%2);//1
System.out.println(5%-2);//1
System.out.println(-5%2);//-1
System.out.println(-5%-2);//-1 // 和输出语句一起
int z = 5;
//System.out.println(++z);// 输出结果是6,z的值也是6
System.out.println(z++);// 输出结果是5,z的值是6int i = 1;
int j = i++ + ++i * i++;
System.out.println("j = " + j);
//最终j=10int m = 2;
m = m++; //(1)先取b的值“2”放操作数栈 (2)m再自增,m=3 (3)再把操作数栈中的"2"赋值给m,m=2
System.out.println(m); //最终m=21.2 赋值运算符
1.2.1 基本语法
-
符号:=
-
当“=”两侧数据类型不一致时,可以使用自动类型转换或使用强制类型转换原则进行处理。
-
支持
连续赋值。
-
-
扩展赋值运算符: +=、 -=、*=、 /=、%=
| 赋值运算符 | 符号解释 |
|---|---|
+= | 将符号左边的值和右边的值进行相加操作,最后将结果赋值给左边的变量 |
-= | 将符号左边的值和右边的值进行相减操作,最后将结果赋值给左边的变量 |
*= | 将符号左边的值和右边的值进行相乘操作,最后将结果赋值给左边的变量 |
/= | 将符号左边的值和右边的值进行相除操作,最后将结果赋值给左边的变量 |
%= | 将符号左边的值和右边的值进行取余操作,最后将结果赋值给左边的变量 |
//练习1:开发中,如何实现一个变量+2的操作呢?
// += 的操作不会改变变量本身的数据类型。其他拓展的运算符也如此。
//写法1:推荐
short s1 = 10;
s1 += 2; //编译通过,因为在得到int类型的结果后,JVM自动完成一步强制类型转换,将int类型强转成short
System.out.println(s1);//12
//写法2:
short s2 = 10;
//s2 = s2 + 2;//编译报错,因为将int类型的结果赋值给short类型的变量s时,可能损失精度
s2 = (short)(s2 + 2);
System.out.println(s2);int i = 1;
i *= 0.1;
System.out.println(i);//0
i++;
System.out.println(i);//1int m = 2;
int n = 3;
n *= m++; //n = n * m++;
System.out.println("m=" + m);//3
System.out.println("n=" + n);//6int n = 10;
n += (n++) + (++n); //n = n + (n++) + (++n)
System.out.println(n);//32
1.3 比较(关系)运算符
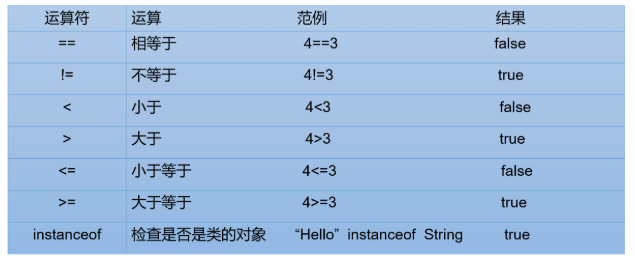
-
比较运算符的结果都是boolean型,也就是要么是true,要么是false。
-
> < >= <= :只适用于基本数据类型(除boolean类型之外)
== != :适用于基本数据类型和引用数据类型
-
比较运算符“
==”不能误写成“=”
1.4 逻辑运算符
1.4.1 基本语法
-
逻辑运算符,操作的都是boolean类型的变量或常量,而且运算得结果也是boolean类型的值。
-
运算符说明:
-
& 和 &&:表示"且"关系,当符号左右两边布尔值都是true时,结果才能为true。否则,为false。
-
| 和 || :表示"或"关系,当符号两边布尔值有一边为true时,结果为true。当两边都为false时,结果为false
-
! :表示"非"关系,当变量布尔值为true时,结果为false。当变量布尔值为false时,结果为true。
-
^ :当符号左右两边布尔值不同时,结果为true。当两边布尔值相同时,结果为false。
-
-
区分“&”和“&&”:
-
相同点:如果符号左边是true,则二者都执行符号右边的操作
-
不同点:& : 如果符号左边是false,则继续执行符号右边的操作
&& :如果符号左边是false,则不再继续执行符号右边的操作
-
建议:开发中,推荐使用 &&
-
-
区分“|”和“||”:
-
相同点:如果符号左边是false,则二者都执行符号右边的操作
-
不同点:| : 如果符号左边是true,则继续执行符号右边的操作
|| :如果符号左边是true,则不再继续执行符号右边的操作
-
建议:开发中,推荐使用 ||
1.5 位运算符
1.5.1 基本语法
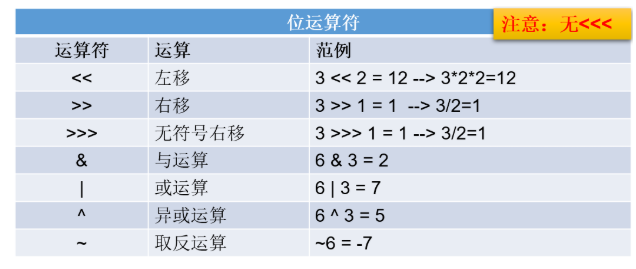
2. Scanner与随机数的获取
2.1 Scanner:键盘输入功能的实现
如何从键盘获取不同类型(基本数据类型、String类型)的变量:使用Scanner类。
2.1.1 键盘输入的四个步骤
-
导包:
import java.util.Scanner; -
创建Scanner类型的对象:
Scanner scan = new Scanner(System.in); -
调用Scanner类的相关方法(
next() / nextXxx()),来获取指定类型的变量 -
释放资源:
scan.close();
注意:需要根据相应的方法,来输入指定类型的值。如果输入的数据类型与要求的类型不匹配时,会报异常 导致程序终止。
2.2如何获取一个随机数
如何产生一个指定范围的随机整数?
1、Math类的random()的调用,会返回一个[0,1)范围的一个double型值
2、Math.random() * 100 ---> [0,100) (int)(Math.random() * 100) ---> [0,99] (int)(Math.random() * 100) + 5 ----> [5,104]
3、如何获取[a,b]范围内的随机整数呢?(int)(Math.random() * (b - a + 1)) + a
3. 流程控制与其顺序结构
3.1 流程控制介绍
-
流程控制语句是用来控制程序中各
语句执行顺序的语句,可以把语句组合成能完成一定功能的小逻辑模块。 -
程序设计中规定的
三种流程结构,即:-
顺序结构
-
程序从上到下逐行地执行,中间没有任何判断和跳转。
-
-
分支结构
-
根据条件,选择性地执行某段代码。
-
有
if…else和switch-case两种分支语句。
-
-
循环结构
-
根据循环条件,重复性的执行某段代码。
-
有
for、while、do-while三种循环语句。 -
补充:JDK5.0 提供了
foreach循环,方便的遍历集合、数组元素。(第12章集合中讲解)
-
-
Switch:
使用注意点:
-
switch(表达式)中表达式的值必须是下述几种类型之一:byte,short,char,int,枚举 (jdk 5.0),String (jdk 7.0);
-
case子句中的值必须是常量,不能是变量名或不确定的表达式值或范围;
-
同一个switch语句,所有case子句中的常量值互不相同;
-
break语句用来在执行完一个case分支后使程序跳出switch语句块;
如果没有break,程序会顺序执行到switch结尾;
-
default子句是可选的。同时,位置也是灵活的。当没有匹配的case时,执行default语句。
第04章_数组的使用
1. 数组的概述
1.1 数组的概念
-
数组(Array),是多个相同类型数据按一定顺序排列的集合,并使用一个名字命名,并通过编号的方式对这些数据进行统一管理。
-
数组中的概念
-
数组名
-
下标(或索引)
-
元素
-
数组的长度
-
数组的特点:
-
数组本身是
引用数据类型,而数组中的元素可以是任何数据类型,包括基本数据类型和引用数据类型。 -
创建数组对象会在内存中开辟一整块
连续的空间。占据的空间的大小,取决于数组的长度和数组中元素的类型。 -
数组中的元素在内存中是依次紧密排列的,有序的。
-
数组,一旦初始化完成,其长度就是确定的。数组的
长度一旦确定,就不能修改。 -
我们可以直接通过下标(或索引)的方式调用指定位置的元素,速度很快。
-
数组名中引用的是这块连续空间的首地址。
1.2 数组的分类
1、按照元素类型分:
-
基本数据类型元素的数组:每个元素位置存储基本数据类型的值
-
引用数据类型元素的数组:每个元素位置存储对象(本质是存储对象的首地址)(在面向对象部分讲解)
2、按照维度分:
-
一维数组:存储一组数据
-
二维数组:存储多组数据,相当于二维表,一行代表一组数据,只是这里的二维表每一行长度不要求一样。
2. 一维数组的使用
2.1 一维数组的声明
格式:
//推荐
元素的数据类型[] 一维数组的名称;
//不推荐
元素的数据类型 一维数组名[];数组的声明,需要明确:
(1)数组的维度:在Java中数组的符号是[],[]表示一维,[][]表示二维。
(2)数组的元素类型:即创建的数组容器可以存储什么数据类型的数据。元素的类型可以是任意的Java的数据类型。例如:int、String、Student等。
(3)数组名:就是代表某个数组的标识符,数组名其实也是变量名,按照变量的命名规范来命名。数组名是个引用数据类型的变量,因为它代表一组数据。
注意:Java语言中声明数组时不能指定其长度(数组中元素的个数)。 例如: int a[5];
2.2 一维数组的初始化
2.2.1 静态初始化
-
如果数组变量的初始化和数组元素的赋值操作同时进行,那就称为静态初始化。
-
静态初始化,本质是用静态数据(编译时已知)为数组初始化。此时数组的长度由静态数据的个数决定。
-
一维数组声明和静态初始化格式1:
数据类型[] 数组名 = new 数据类型[]{元素1,元素2,元素3,...};
或
数据类型[] 数组名;
数组名 = new 数据类型[]{元素1,元素2,元素3,...};-
-
new:关键字,创建数组使用的关键字。因为数组本身是引用数据类型,所以要用new创建数组实体。
-
一维数组声明和静态初始化格式2:
数据类型[] 数组名 = {元素1,元素2,元素3...};//必须在一个语句中完成,不能分成两个语句写2.2.2 动态初始化
数组变量的初始化和数组元素的赋值操作分开进行,即为动态初始化。
动态初始化中,只确定了元素的个数(即数组的长度),而元素值此时只是默认值,还并未真正赋自己期望的值。真正期望的数据需要后续单独一个一个赋值。
格式:
数组存储的元素的数据类型[] 数组名字 = new 数组存储的元素的数据类型[长度];
或
数组存储的数据类型[] 数组名字;
数组名字 = new 数组存储的数据类型[长度];-
[长度]:数组的长度,表示数组容器中可以最多存储多少个元素。
-
注意:数组有定长特性,长度一旦指定,不可更改。和水杯道理相同,买了一个2升的水杯,总容量就是2升是固定的。
2.3 一维数组的使用
2.3.1 数组的长度
-
数组的元素总个数,即数组的长度
-
每个数组都有一个属性length指明它的长度,例如:arr.length 指明数组arr的长度(即元素个数)
-
每个数组都具有长度,而且一旦初始化,其长度就是确定,且是不可变的。
2.3.2 数组元素的引用
如何表示数组中的一个元素?
每一个存储到数组的元素,都会自动的拥有一个编号,从0开始,这个自动编号称为数组索引(index)或下标,可以通过数组的索引/下标访问到数组中的元素。
数组的下标范围?
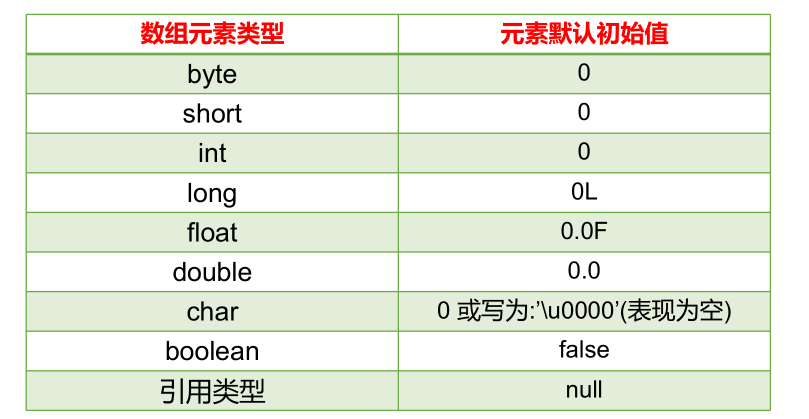
Java中数组的下标从[0]开始,下标范围是[0, 数组的长度-1],即[0, 数组名.length-1]
对于基本数据类型而言,默认初始化值各有不同。
对于引用数据类型而言,默认初始化值为null(注意与0不同!)
4. 一维数组内存分析
4.1 Java虚拟机的内存划分
为了提高运算效率,就对空间进行了不同区域的划分,因为每一片区域都有特定的处理数据方式和内存管理方式。
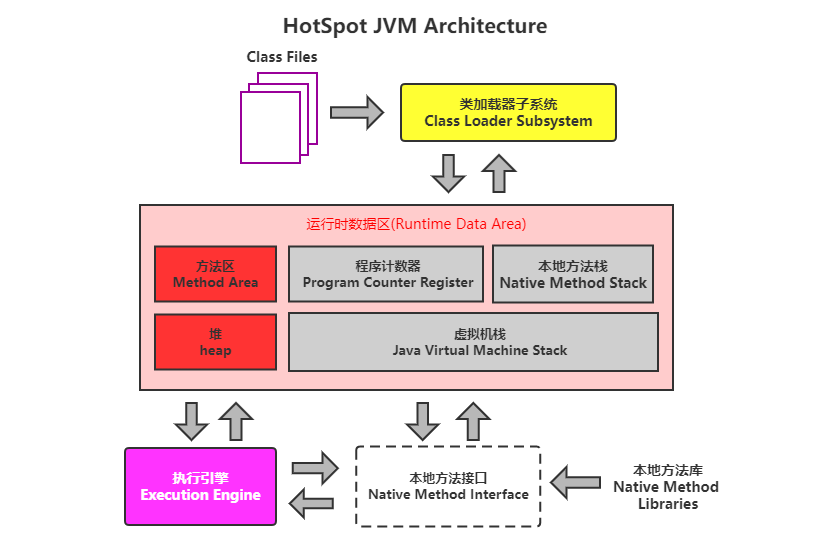
| 区域名称 | 作用 |
|---|---|
虚拟机栈 | 用于存储正在执行的每个Java方法的局部变量表等。局部变量表存放了编译期 可知长度的各种基本数据类型、对象引用,方法执行完,自动释放。 |
堆内存 | 存储对象(包括数组对象),new来创建的,都存储在堆内存。 |
方法区 | 存储已被虚拟机加载的类信息、常量、(静态变量)、即时编译器编译后的代码等数据。 |
| 本地方法栈 | 当程序中调用了native的本地方法时,本地方法执行期间的内存区域 |
| 程序计数器 | 程序计数器是CPU中的寄存器,它包含每一个线程下一条要执行的指令的地址 |
4.2 一维数组在内存中的存储
1、一个一维数组内存图
public static void main(String[] args) {
int[] arr = new int[3];
System.out.println(arr);//[I@5f150435
}5. 数组的常见算法
5.1 数值型数组特征值统计
-
这里的特征值涉及到:平均值、最大值、最小值、总和等
5.2 数组元素的赋值与数组复制
举例1:使用简单数组
(1)创建一个名为ArrayExer的类,在main()方法中声明array1和array2两个变量,他们是int[]类型的数组。
(2)使用大括号{},把array1初始化为8个素数:2,3,5,7,11,13,17,19。
(3)显示array1的内容。
(4)赋值array2变量等于array1,修改array2中的偶索引元素,使其等于索引值(如array[0]=0,array[2]=2)。打印出array1。 array2 = array1;
6. 数组中的常见异常
6.1 数组角标越界异常
当访问数组元素时,下标指定超出[0, 数组名.length-1]的范围时,就会报数组下标越界异常:ArrayIndexOutOfBoundsException。
6.2 空指针异常
public class TestNullPointerException {
public static void main(String[] args) {
//定义数组
int[][] arr = new int[3][];
System.out.println(arr[0][0]);//NullPointerException
}
}因为此时数组的每一行还未分配具体存储元素的空间,此时arr[0]是null,此时访问arr[0][0]会抛出NullPointerException 空指针异常。
7. 二维数组(拓展)
7.1 概述
-
Java 语言里提供了支持多维数组的语法。
-
如果说可以把一维数组当成几何中的
线性图形,那么二维数组就相当于是一个表格,像Excel中的表格、围棋棋盘一样。
7.2 声明与初始化
7.2.1 声明
二维数组声明的语法格式:
//推荐
元素的数据类型[][] 二维数组的名称;
//不推荐
元素的数据类型 二维数组名[][];
//不推荐
元素的数据类型[] 二维数组名[];面试:
int[] x, y[];
//x是一维数组,y是二维数组7.2.2 静态初始化
格式:
int[][] arr = new int[][]{{3,8,2},{2,7},{9,0,1,6}};int[][] arr = {{1,2,3},{4,5,6},{7,8,9,10}};//声明与初始化必须在一句完成
int[][] arr = new int[][]{{1,2,3},{4,5,6},{7,8,9,10}};
int[][] arr;
arr = new int[][]{{1,2,3},{4,5,6},{7,8,9,10}};
arr = new int[3][3]{{1,2,3},{4,5,6},{7,8,9,10}};//错误,静态初始化右边new 数据类型[][]中不能写数字7.2.3 动态初始化
如果二维数组的每一个数据,甚至是每一行的列数,需要后期单独确定,那么就只能使用动态初始化方式了。动态初始化方式分为两种格式:
格式1:规则二维表:每一行的列数是相同的
举例:
int[][] arr = new int[3][2];-
定义了名称为arr的二维数组
-
二维数组中有3个一维数组
-
每一个一维数组中有2个元素
-
一维数组的名称分别为arr[0], arr[1], arr[2]
-
给第一个一维数组1脚标位赋值为78写法是:
arr[0][1] = 78;
格式2:不规则:每一行的列数不一样
举例:
int[][] arr = new int[3][];-
二维数组中有3个一维数组。
-
每个一维数组都是默认初始化值null (注意:区别于格式1)
-
可以对这个三个一维数组分别进行初始化:arr[0] = new int[3]; arr[1] = new int[1]; arr[2] = new int[2];
-
注:
int[][] arr = new int[][3]; //非法
第05章_面向对象编程(基础)
面向对象内容的3条主线:
Java类及类的成员:属性、方法、构造器;代码块、内部类
面向对象的特征:封装、继承、多态、(抽象)
其他关键字的使用:this、super、package、import、static、final、interface、abstract等
1. Java语言的基本元素:类和对象
1.1 引入
人认识世界,其实就是面向对象的。
1.2 类和对象概述
类(Class)和对象(Object)是面向对象的核心概念。
1、什么是类
类:具有相同特征的事物的抽象描述,是抽象的、概念上的定义。
2、什么是对象
对象:实际存在的该类事物的每个个体,是具体的,因而也称为实例(instance)。
可以理解为:类 => 抽象概念的人;对象 => 实实在在的某个人 。
1.3 类的成员概述
面向对象程序设计的重点是
类的设计类的设计,其实就是
类的成员的设计
Java中用类class来描述事物也是如此。类,是一组相关属性和行为的集合,这也是类最基本的两个成员。
-
属性:该类事物的状态信息。对应类中的
成员变量-
成员变量 <=> 属性 <=> Field
-
-
行为:该类事物要做什么操作,或者基于事物的状态能做什么。对应类中的
成员方法-
(成员)方法 <=> 函数 <=> Method
-
1.4 面向对象完成功能的三步骤(重要)
步骤1:类的定义
类的定义使用关键字:class。格式如下:
[修饰符] class 类名{
属性声明;
方法声明;
}步骤2:对象的创建
-
创建对象,使用关键字:new
-
创建对象语法:
//方式1:给创建的对象命名
//把创建的对象用一个引用数据类型的变量保存起来,这样就可以反复使用这个对象了
类名 对象名 = new 类名();
//方式2:
new 类名()//也称为匿名对象
步骤3:对象调用属性或方法
-
对象是类的一个实例,必然具备该类事物的属性和行为(即方法)。
-
使用"
对象名.属性" 或 "对象名.方法"的方式访问对象成员(包括属性和方法)
1.5 匿名对象 (anonymous object)
-
我们也可以不定义对象的句柄,而直接调用这个对象的方法。这样的对象叫做匿名对象。
-
如:new Person().shout();
-
-
使用情况
-
如果一个对象只需要进行一次方法调用,那么就可以使用匿名对象。
-
我们经常将匿名对象作为实参传递给一个方法调用。
-
2. 对象的内存解析
2.1 JVM内存结构划分
HotSpot Java虚拟机的架构图如下。其中我们主要关心的是运行时数据区部分(Runtime Data Area)。
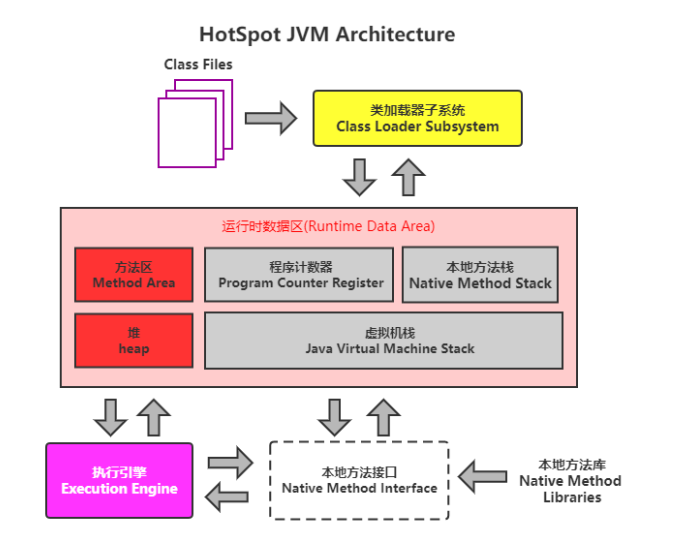
其中:
堆(Heap):此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。这一点在Java虚拟机规范中的描述是:所有的对象实例以及数组都要在堆上分配。
栈(Stack):是指虚拟机栈。虚拟机栈用于存储局部变量等。局部变量表存放了编译期可知长度的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference类型,它不等同于对象本身,是对象在堆内存的首地址)。 方法执行完,自动释放。
方法区(Method Area):用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
2.2 对象内存解析
说明:
-
堆:凡是new出来的结构(对象、数组)都放在堆空间中。
-
对象的属性存放在堆空间中。
-
创建一个类的多个对象(比如p1、p2),则每个对象都拥有当前类的一套"副本"(即属性)。当通过一个对象修改其属性时,不会影响其它对象此属性的值。
-
当声明一个新的变量使用现有的对象进行赋值时(比如p3 = p1),此时并没有在堆空间中创建新的对象。而是两个变量共同指向了堆空间中同一个对象。当通过一个对象修改属性时,会影响另外一个对象对此属性的调用。
面试题:对象名中存储的是什么呢?
答:对象地址
直接打印对象名和数组名都是显示“类型@对象的hashCode值",所以说类、数组都是引用数据类型,引用数据类型的变量中存储的是对象的地址,或者说指向堆中对象的首地址。
3. 类的成员之一:成员变量(field)
3.1 如何声明成员变量
-
语法格式:
[修饰符1] class 类名{
[修饰符2] 数据类型 成员变量名 [= 初始化值];
}说明:
-
位置要求:必须在类中,方法外
-
修饰符2(暂不考虑)
-
常用的权限修饰符有:private、缺省、protected、public
-
其他修饰符:static、final
-
-
数据类型
-
任何基本数据类型(如int、Boolean) 或 任何引用数据类型。
-
-
成员变量名
-
属于标识符,符合命名规则和规范即可。
-
-
初始化值
-
根据情况,可以显式赋值;也可以不赋值,使用默认值
-
3.2 成员变量 vs 局部变量
1、变量的分类:成员变量与局部变量
-
在方法体外,类体内声明的变量称为成员变量。
-
在方法体内部等位置声明的变量称为局部变量。

2、成员变量 与 局部变量 的对比
-
相同点
-
变量声明的格式相同: 数据类型 变量名 = 初始化值
-
变量必须先声明、后初始化、再使用。
-
变量都有其对应的作用域。只在其作用域内是有效的
-
-
不同点
1、声明位置和方式 (1)实例变量:在类中方法外 (2)局部变量:在方法体{}中或方法的形参列表、代码块中
2、在内存中存储的位置不同 (1)实例变量:堆 (2)局部变量:栈
3、生命周期 (1)实例变量:和对象的生命周期一样,随着对象的创建而存在,随着对象被GC回收而消亡, 而且每一个对象的实例变量是独立的。 (2)局部变量:和方法调用的生命周期一样,每一次方法被调用而在存在,随着方法执行的结束而消亡, 而且每一次方法调用都是独立。
4、作用域 (1)实例变量:通过对象就可以使用,本类中直接调用,其他类中“对象.实例变量” (2)局部变量:出了作用域就不能使用
5、修饰符(后面再讲) (1)实例变量:public,protected,private,final,volatile,transient等 (2)局部变量:final
6、默认值 (1)实例变量:有默认值 (2)局部变量:没有,必须手动初始化。其中的形参比较特殊,靠实参给它初始化。
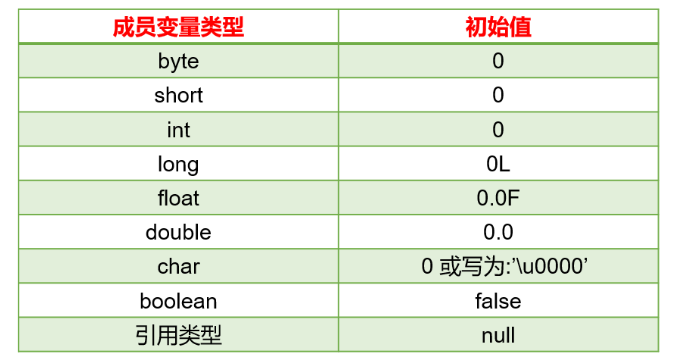
3、对象属性的默认初始化赋值
当一个对象被创建时,会对其中各种类型的成员变量自动进行初始化赋值。
4. 类的成员之二:方法(method)
4.1 方法的引入
.2 方法(method、函数)的理解
-
方法是类或对象行为特征的抽象,用来完成某个功能操作。在某些语言中也称为函数或过程。 -
将功能封装为方法的目的是,可以
实现代码重用,减少冗余,简化代码 -
Java里的方法
不能独立存在,所有的方法必须定义在类里。 -
举例1:
-
Math.random()的random()方法
-
Math.sqrt(x)的sqrt(x)方法
-
System.out.println(x)的println(x)方法
-
new Scanner(System.in).nextInt()的nextInt()方法
-
4.3 如何声明方法
1、声明方法的语法格式
[修饰符] 返回值类型 方法名([形参列表])[throws 异常列表]{
方法体的功能代码
}(1)一个完整的方法 = 方法头 + 方法体。
-
方法头就是
[修饰符] 返回值类型 方法名([形参列表])[throws 异常列表],也称为方法签名。通常调用方法时只需要关注方法头就可以,从方法头可以看出这个方法的功能和调用格式。 -
方法体就是方法被调用后要执行的代码。对于调用者来说,不了解方法体如何实现的,并不影响方法的使用。
(2)方法头可能包含5个部分
-
修饰符:可选的。方法的修饰符也有很多,例如:public、protected、private、static、abstract、native、final、synchronized等,后面会一一学习。
-
其中,权限修饰符有public、protected、private。在讲封装性之前,我们先默认使用pulbic修饰方法。
-
其中,根据是否有static,可以将方法分为静态方法和非静态方法。其中静态方法又称为类方法,非静态方法又称为实例方法。咱们在讲static前先学习实例方法。
-
-
返回值类型: 表示方法运行的结果的数据类型,方法执行后将结果返回到调用者。
-
无返回值,则声明:void
-
有返回值,则声明出返回值类型(可以是任意类型)。与方法体中“
return 返回值”搭配使用
-
-
方法名:属于标识符,命名时遵循标识符命名规则和规范,“见名知意”
-
形参列表:表示完成方法体功能时需要外部提供的数据列表。可以包含零个,一个或多个参数。
4.4 如何调用实例方法
方法通过方法名被调用,且只有被调用才会执行。
4.5 使用的注意点
(1)必须先声明后使用,且方法必须定义在类的内部
(2)调用一次就执行一次,不调用不执行。
(3)方法中可以调用类中的方法或属性,不可以在方法内部定义方法。
4.6 关键字return的使用
-
return在方法中的作用:
-
作用1:结束一个方法
-
作用2:结束一个方法的同时,可以返回数据给方法的调用者
-
-
注意点:在return关键字的直接后面不能声明执行语句
4.7 方法调用内存分析
-
方法
没有被调用的时候,都在方法区中的字节码文件(.class)中存储。 -
方法
被调用的时候,需要进入到栈内存中运行。方法每调用一次就会在栈中有一个入栈动作,即给当前方法开辟一块独立的内存区域,用于存储当前方法的局部变量的值。 -
当方法执行结束后,会释放该内存,称为
出栈,如果方法有返回值,就会把结果返回调用处,如果没有返回值,就直接结束,回到调用处继续执行下一条指令。 -
栈结构:先进后出,后进先出。
第06章_面向对象编程(进阶)
1. 再谈方法
1.1 方法的重载(overload)
1.1.1 概念及特点
-
方法重载:在同一个类中,允许存在一个以上的同名方法,只要它们的参数列表不同即可。
-
参数列表不同,意味着参数个数或参数类型的不同
-
-
重载的特点:与修饰符、返回值类型无关,只看参数列表,且参数列表必须不同。(参数个数或参数类型)。调用时,根据方法参数列表的不同来区别。
-
重载方法调用:JVM通过方法的参数列表,调用匹配的方法。
-
先找个数、类型最匹配的
-
再找个数和类型可以兼容的,如果同时多个方法可以兼容将会报错
-
1.2 可变个数的形参
在JDK 5.0 中提供了Varargs(variable number of arguments)机制。即当定义一个方法时,形参的类型可以确定,但是形参的个数不确定,那么可以考虑使用可变个数的形参。
格式:
方法名(参数的类型名 ...参数名)特点:
-
可变参数:方法参数部分指定类型的参数个数是可变多个:0个,1个或多个
-
可变个数形参的方法与同名的方法之间,彼此构成重载
-
可变参数方法的使用与方法参数部分使用数组是一致的,二者不能同时声明,否则报错。
-
方法的参数部分有可变形参,需要放在形参声明的最后
-
在一个方法的形参中,最多只能声明一个可变个数的形参
1.3 方法的参数传递机制
1.3.1 形参和实参
-
形参(formal parameter):在定义方法时,方法名后面括号()中声明的变量称为形式参数,简称形参。
-
实参(actual parameter):在调用方法时,方法名后面括号()中的使用的值/变量/表达式称为实际参数,简称实参。
1.3.2 参数传递机制:值传递
Java里方法的参数传递方式只有一种:值传递。 即将实际参数值的副本(复制品)传入方法内,而参数本身不受影响。
-
形参是基本数据类型:将实参基本数据类型变量的“数据值”传递给形参
-
形参是引用数据类型:将实参引用数据类型变量的“地址值”传递给形参
1.4 递归(recursion)方法
递归方法调用:方法自己调用自己的现象就称为递归。
递归的分类:直接递归、间接递归。
-
直接递归:方法自身调用自己。
-
间接递归:可以理解为A()方法调用B()方法,B()方法调用C()方法,C()方法调用A()方法。
说明:
-
递归方法包含了一种
隐式的循环。 -
递归方法会
重复执行某段代码,但这种重复执行无须循环控制。 -
递归一定要向
已知方向递归,否则这种递归就变成了无穷递归,停不下来,类似于死循环。最终发生栈内存溢出。
2. 关键字:package、import
2.1 package(包)
package,称为包,用于指明该文件中定义的类、接口等结构所在的包。
2.1.1 语法格式
package 顶层包名.子包名;说明:
-
一个源文件只能有一个声明包的package语句
-
package语句作为Java源文件的第一条语句出现。若缺省该语句,则指定为无名包。
-
包名,属于标识符,满足标识符命名的规则和规范(全部小写)、见名知意
-
包通常使用所在公司域名的倒置:com.atguigu.xxx。
-
大家取包名时不要使用"
java.xx"包
-
-
包对应于文件系统的目录,package语句中用 “.” 来指明包(目录)的层次,每.一次就表示一层文件目录。
-
同一个包下可以声明多个结构(类、接口),但是不能定义同名的结构(类、接口)。不同的包下可以定义同名的结构(类、接口)
2.1.2 包的作用
-
包可以包含类和子包,划分
项目层次,便于管理 -
帮助
管理大型软件系统:将功能相近的类划分到同一个包中。比如:MVC的设计模式 -
解决
类命名冲突的问题 -
控制
访问权限
2.1.3 JDK中主要的包介绍
java.lang----包含一些Java语言的核心类,如String、Math、Integer、 System和Thread,提供常用功能。
java.net----包含执行与网络相关的操作的类和接口。
java.io ----包含能提供多种输入/输出功能的类。
java.util----包含一些实用工具类,如定义系统特性、集合框架类、使用与日期日历相关的函数。 java.text----包含了一些java格式化相关的类。
java.sql----包含了java进行JDBC数据库编程的相关类/接口。
java.awt----包含了构成抽象窗口工具集(abstract window toolkits)的多个类,这些类被用来构建和管理应用程序的图形用户界面(GUI)。
2.2 import(导入)
为了使用定义在其它包中的Java类,需用import语句来显式引入指定包下所需要的类。相当于import语句告诉编译器到哪里去寻找这个类。
2.2.1 语法格式
import 包名.类名;2.2.2 注意事项
-
import语句,声明在包的声明和类的声明之间。
-
如果需要导入多个类或接口,那么就并列显式多个import语句即可
-
如果使用
a.*导入结构,表示可以导入a包下的所有的结构。举例:可以使用java.util.*的方式,一次性导入util包下所有的类或接口。 -
如果导入的类或接口是java.lang包下的,或者是当前包下的,则可以省略此import语句。
-
如果已经导入java.a包下的类,那么如果需要使用a包的子包下的类的话,仍然需要导入。
-
如果在代码中使用不同包下的同名的类,那么就需要使用类的全类名的方式指明调用的是哪个类。
-
(了解)
import static组合的使用:调用指定类或接口下的静态的属性或方法
3. 面向对象特征:封装与隐藏性
3.1 为什么需要封装?
随着我们系统越来越复杂,类会越来越多,那么类之间的访问边界必须把握好,面向对象的开发原则要遵循“高内聚、低耦合”。“高内聚,低耦合”的体现:
-
高内聚:类的内部数据操作细节自己完成,不允许外部干涉; -
低耦合:仅暴露少量的方法给外部使用,尽量方便外部调用。
3.2 何为封装性?
所谓封装,就是把客观事物封装成抽象概念的类,并且类可以把自己的数据和方法只向可信的类或者对象开放,向没必要开放的类或者对象隐藏信息。
通俗的讲,把该隐藏的隐藏起来,该暴露的暴露出来。这就是封装性的设计思想。
3.3 Java如何实现数据封装
-
实现封装就是控制类或成员的可见性范围。这就需要依赖访问控制修饰符,也称为权限修饰符来控制。
-
权限修饰符:
public、protected、缺省、private。具体访问范围如下:
| 修饰符 | 本类内部 | 本包内 | 其他包的子类 | 其他包非子类 |
|---|---|---|---|---|
| private | √ | × | × | × |
| 缺省 | √ | √ | × | × |
| protected | √ | √ | √ | × |
| public | √ | √ | √ | √ |
具体修饰的结构:
-
外部类:public、缺省
-
成员变量、成员方法、构造器、成员内部类:public、protected、缺省、private
3.4 封装性的体现
3.4.1 成员变量/属性私有化
概述:私有化类的成员变量,提供公共的get和set方法,对外暴露获取和修改属性的功能。
成员变量封装的好处:
-
让使用者只能通过事先预定的方法来
访问数据,从而可以在该方法里面加入控制逻辑,限制对成员变量的不合理访问。还可以进行数据检查,从而有利于保证对象信息的完整性。 -
便于修改,提高代码的可维护性。主要说的是隐藏的部分,在内部修改了,如果其对外可以的访问方式不变的话,外部根本感觉不到它的修改。例如:Java8->Java9,String从char[]转为byte[]内部实现,而对外的方法不变,我们使用者根本感觉不到它内部的修改。
3.4.2 私有化方法
注意:
开发中,一般成员实例变量都习惯使用private修饰,再提供相应的public权限的get/set方法访问。
对于final的实例变量,不提供set()方法。(后面final关键字的时候讲)
对于static final的成员变量,习惯上使用public修饰。
4. 类的成员之三:构造器(Constructor)
我们new完对象时,所有成员变量都是默认值,如果我们需要赋别的值,需要挨个为它们再赋值,太麻烦了。我们能不能在new对象时,直接为当前对象的某个或所有成员变量直接赋值呢?
可以,Java给我们提供了构造器(Constructor),也称为构造方法。
4.1 构造器的作用
new对象,并在new对象的时候为实例变量赋值。
举例:Person p = new Person(“Peter”,15);
4.2 构造器的语法格式
[修饰符] class 类名{
[修饰符] 构造器名(){
// 实例初始化代码
}
[修饰符] 构造器名(参数列表){
// 实例初始化代码
}
}说明:
-
构造器名必须与它所在的类名必须相同。
-
它没有返回值,所以不需要返回值类型,也不需要void。
-
构造器的修饰符只能是权限修饰符,不能被其他任何修饰。比如,不能被static、final、synchronized、abstract、native修饰,不能有return语句返回值。
4.3 使用说明
-
当我们没有显式的声明类中的构造器时,系统会默认提供一个无参的构造器并且该构造器的修饰符默认与类的修饰符相同。
-
当我们显式的定义类的构造器以后,系统就不再提供默认的无参的构造器了。
-
在类中,至少会存在一个构造器。
-
构造器是可以重载的。
5. 关键字:this
5.1 this是什么?
-
在Java中,this关键字不算难理解,它的作用和其词义很接近。
-
它在方法(准确的说是实例方法或非static的方法)内部使用,表示调用该方法的对象
-
它在构造器内部使用,表示该构造器正在初始化的对象。
-
-
this可以调用的结构:成员变量、方法和构造器
5.2 什么时候使用this
5.2.1 实例方法或构造器中使用当前对象的成员
在实例方法或构造器中,如果使用当前类的成员变量或成员方法可以在其前面添加this,增强程序的可读性。不过,通常我们都习惯省略this。
但是,当形参与成员变量同名时,如果在方法内或构造器内需要使用成员变量,必须添加this来表明该变量是类的成员变量。即:我们可以用this来区分成员变量和局部变量。
另外,使用this访问属性和方法时,如果在本类中未找到,会从父类中查找。这个在继承中会讲到。
5.2.2 同一个类中构造器互相调用
this可以作为一个类中构造器相互调用的特殊格式。
-
this():调用本类的无参构造器
-
this(实参列表):调用本类的有参构造器
注意:
-
不能出现递归调用。比如,调用自身构造器。
-
推论:如果一个类中声明了n个构造器,则最多有 n - 1个构造器中使用了"this(形参列表)"
-
-
this()和this(实参列表)只能声明在构造器首行。
-
推论:在类的一个构造器中,最多只能声明一个"this(参数列表)"
-
6.JavaBean 其实就是一个特殊的类,标准的类,有一下三点要求:
1.类必须是public修饰的,公开的。
2.必须有一个无参的公共的构造器。
3.有属性,并为这些属性提供get,set方法。
第07章_面向对象编程(强化)
1. 面向对象特征二:继承(Inheritance)
1.1 继承的概述
1.1.1 生活中的继承
1.1.2 Java中的继承
1.1.3 继承的好处
-
继承的出现减少了代码冗余,提高了代码的复用性。
-
继承的出现,更有利于功能的扩展。
-
继承的出现让类与类之间产生了
is-a的关系,为多态的使用提供了前提。-
继承描述事物之间的所属关系,这种关系是:
is-a的关系。可见,父类更通用、更一般,子类更具体。
-
注意:不要仅为了获取其他类中某个功能而去继承!
1.2 继承的语法
1.2.1 继承中的语法格式
通过 extends 关键字,可以声明一个类B继承另外一个类A,定义格式如下:
[修饰符] class 类A {
...
}
[修饰符] class 类B extends 类A {
...
}
1.2.2 继承中的基本概念
类B,称为子类、派生类(derived class)、SubClass
类A,称为父类、超类、基类(base class)、SuperClass
1.4 继承性的细节说明
1、子类会继承父类所有的实例变量和实例方法
从类的定义来看,类是一类具有相同特性的事物的抽象描述。父类是所有子类共同特征的抽象描述。而实例变量和实例方法就是事物的特征,那么父类中声明的实例变量和实例方法代表子类事物也有这个特征。
-
当子类对象被创建时,在堆中给对象申请内存时,就要看子类和父类都声明了什么实例变量,这些实例变量都要分配内存。
-
当子类对象调用方法时,编译器会先在子类模板中看该类是否有这个方法,如果没找到,会看它的父类甚至父类的父类是否声明了这个方法,遵循
从下往上找的顺序,找到了就停止,一直到根父类都没有找到,就会报编译错误。
所以继承意味着子类的对象除了看子类的类模板还要看父类的类模板。
2、子类不能直接访问父类中私有的(private)的成员变量和方法
子类虽会继承父类私有(private)的成员变量,但子类不能对继承的私有成员变量直接进行访问,可通过继承的get/set方法进行访问。
3、在Java 中,继承的关键字用的是“extends”,即子类不是父类的子集,而是对父类的“扩展”
子类在继承父类以后,还可以定义自己特有的方法,这就可以看做是对父类功能上的扩展。
4、Java支持多层继承(继承体系)
说明:
-
子类和父类是一种相对的概念
-
顶层父类是Object类。所有的类默认继承Object,作为父类。
5、一个父类可以同时拥有多个子类
6、Java只支持单继承,不支持多重继承
2. 方法的重写(override/overwrite)
父类的所有方法子类都会继承,但是当某个方法被继承到子类之后,子类觉得父类原来的实现不适合于自己当前的类,该怎么办呢?子类可以对从父类中继承来的方法进行改造,我们称为方法的重写 (override、overwrite)。也称为方法的重置、覆盖。
在程序执行时,子类的方法将覆盖父类的方法。
2.1 方法重写的要求
-
子类重写的方法
必须和父类被重写的方法具有相同的方法名称、参数列表。 -
子类重写的方法的返回值类型
不能大于父类被重写的方法的返回值类型。(例如:Student < Person)。
注意:如果返回值类型是基本数据类型和void,那么必须是相同
-
子类重写的方法使用的访问权限
不能小于父类被重写的方法的访问权限。(public > protected > 缺省 > private)
注意:① 父类私有方法不能重写 ② 跨包的父类缺省的方法也不能重写
-
子类方法抛出的异常不能大于父类被重写方法的异常
此外,子类与父类中同名同参数的方法必须同时声明为非static的(即为重写),或者同时声明为static的(不是重写)。因为static方法是属于类的,子类无法覆盖父类的方法。
4. 关键字:super
4.1 super的理解
在Java类中使用super来调用父类中的指定操作:
-
super可用于访问父类中定义的属性
-
super可用于调用父类中定义的成员方法
-
super可用于在子类构造器中调用父类的构造器
注意:
-
尤其当子父类出现同名成员时,可以用super表明调用的是父类中的成员
-
super的追溯不仅限于直接父类
-
super和this的用法相像,this代表本类对象的引用,super代表父类的内存空间的标识
4.2 super的使用场景
4.2.1 子类中调用父类被重写的方法
-
如果子类没有重写父类的方法,只要权限修饰符允许,在子类中完全可以直接调用父类的方法;
-
如果子类重写了父类的方法,在子类中需要通过
super.才能调用父类被重写的方法,否则默认调用的子类重写的方法
总结:
-
方法前面没有super.和this.
-
先从子类找匹配方法,如果没有,再从直接父类找,再没有,继续往上追溯
-
-
方法前面有this.
-
先从子类找匹配方法,如果没有,再从直接父类找,再没有,继续往上追溯
-
-
方法前面有super.
-
从当前子类的直接父类找,如果没有,继续往上追溯
-
4.2.2 子类中调用父类中同名的成员变量
-
如果实例变量与局部变量重名,可以在实例变量前面加this.进行区别
-
如果子类实例变量和父类实例变量重名,并且父类的该实例变量在子类仍然可见,在子类中要访问父类声明的实例变量需要在父类实例变量前加super.,否则默认访问的是子类自己声明的实例变量
-
如果父子类实例变量没有重名,只要权限修饰符允许,在子类中完全可以直接访问父类中声明的实例变量,也可以用this.实例访问,也可以用super.实例变量访问
总结:起点不同(就近原则)
-
变量前面没有super.和this.
-
在构造器、代码块、方法中如果出现使用某个变量,先查看是否是当前块声明的
局部变量, -
如果不是局部变量,先从当前执行代码的
本类去找成员变量 -
如果从当前执行代码的本类中没有找到,会往上找
父类声明的成员变量(权限修饰符允许在子类中访问的)
-
-
变量前面有this.
-
通过this找成员变量时,先从当前执行代码的==本类去找成员变量==
-
如果从当前执行代码的本类中没有找到,会往上找==父类声明的成员变量(==权限修饰符允许在子类中访问的)
-
-
变量前面super.
-
通过super找成员变量,直接从当前执行代码的直接父类去找成员变量(权限修饰符允许在子类中访问的)
-
如果直接父类没有,就去父类的父类中找(权限修饰符允许在子类中访问的)
-
特别说明:应该避免子类声明和父类重名的成员变量
4.2.3 子类构造器中调用父类构造器
① 子类继承父类时,不会继承父类的构造器。只能通过“super(形参列表)”的方式调用父类指定的构造器。
② 规定:“super(形参列表)”,必须声明在构造器的首行。
③ 我们前面讲过,在构造器的首行可以使用"this(形参列表)",调用本类中重载的构造器, 结合②,结论:在构造器的首行,"this(形参列表)" 和 "super(形参列表)"只能二选一。
④ 如果在子类构造器的首行既没有显示调用"this(形参列表)",也没有显式调用"super(形参列表)", 则子类此构造器默认调用"super()",即调用父类中空参的构造器。
⑤ 由③和④得到结论:子类的任何一个构造器中,要么会调用本类中重载的构造器,要么会调用父类的构造器。 只能是这两种情况之一。
⑥ 由⑤得到:一个类中声明有n个构造器,最多有n-1个构造器中使用了"this(形参列表)",则剩下的那个一定使用"super(形参列表)"。
开发中常见错误:
如果子类构造器中既未显式调用父类或本类的构造器,且父类中又没有空参的构造器,则
编译出错。
4.3 小结:this与super
1、this和super的意义
this:当前对象
-
在构造器和非静态代码块中,表示正在new的对象
-
在实例方法中,表示调用当前方法的对象
super:引用父类声明的成员
2、this和super的使用格式
-
this
-
this.成员变量:表示当前对象的某个成员变量,而不是局部变量
-
this.成员方法:表示当前对象的某个成员方法,完全可以省略this.
-
this()或this(实参列表):调用另一个构造器协助当前对象的实例化,只能在构造器首行,只会找本类的构造器,找不到就报错
-
-
super
-
super.成员变量:表示当前对象的某个成员变量,该成员变量在父类中声明的
-
super.成员方法:表示当前对象的某个成员方法,该成员方法在父类中声明的
-
super()或super(实参列表):调用父类的构造器协助当前对象的实例化,只能在构造器首行,只会找直接父类的对应构造器,找不到就报错
-
6. 面向对象特征三:多态性
6.1 多态的形式和体现
6.1.1 对象的多态性
多态性,是面向对象中最重要的概念,在Java中的体现:对象的多态性:父类的引用指向子类的对象
格式:(父类类型:指子类继承的父类类型,或者实现的接口类型)
6.1.2 多态的理解
Java引用变量有两个类型:编译时类型和运行时类型。编译时类型由声明该变量时使用的类型决定,运行时类型由实际赋给该变量的对象决定。简称:编译时,看左边;运行时,看右边。
-
若编译时类型和运行时类型不一致,就出现了对象的多态性(Polymorphism)
-
多态情况下,“看左边”:看的是父类的引用(父类中不具备子类特有的方法) “看右边”:看的是子类的对象(实际运行的是子类重写父类的方法)
多态的使用前提:① 类的继承关系 ② 方法的重写
6.2 多态的好处和弊端
好处:变量引用的子类对象不同,执行的方法就不同,实现动态绑定。代码编写更灵活、功能更强大,可维护性和扩展性更好了。
弊端:一个引用类型变量如果声明为父类的类型,但实际引用的是子类对象,那么该变量就不能再访问子类中添加的属性和方法。
开发中:
使用父类做方法的形参,是多态使用最多的场合。即使增加了新的子类,方法也无需改变,提高了扩展性,符合开闭原则。
【开闭原则OCP】
-
对扩展开放,对修改关闭
-
通俗解释:软件系统中的各种组件,如模块(Modules)、类(Classes)以及功能(Functions)等,应该在不修改现有代码的基础上,引入新功能
6.3 虚方法调用(Virtual Method Invocation)
在Java中虚方法是指在编译阶段不能确定方法的调用入口地址,在运行阶段才能确定的方法,即可能被重写的方法。
6.4 成员变量没有多态性
-
若子类重写了父类方法,就意味着子类里定义的方法彻底覆盖了父类里的同名方法,系统将不可能把父类里的方法转移到子类中。
-
对于实例变量则不存在这样的现象,即使子类里定义了与父类完全相同的实例变量,这个实例变量依然不可能覆盖父类中定义的实例变量
6.6 向上转型与向下转型
首先,一个对象在new的时候创建是哪个类型的对象,它从头至尾都不会变。即这个对象的运行时类型,本质的类型用于不会变。但是,把这个对象赋值给不同类型的变量时,这些变量的编译时类型却不同。
6.6.1 为什么要类型转换
因为多态,就一定会有把子类对象赋值给父类变量的时候,这个时候,在编译期间,就会出现类型转换的现象。
但是,使用父类变量接收了子类对象之后,我们就不能调用子类拥有,而父类没有的方法了。这也是多态给我们带来的一点"小麻烦"。所以,想要调用子类特有的方法,必须做类型转换,使得编译通过。
-
向上转型:当左边的变量的类型(父类) > 右边对象/变量的类型(子类),我们就称为向上转型
-
此时,编译时按照左边变量的类型处理,就只能调用父类中有的变量和方法,不能调用子类特有的变量和方法了
-
但是,运行时,仍然是对象本身的类型,所以执行的方法是子类重写的方法体。
-
此时,一定是安全的,而且也是自动完成的
-
-
向下转型:当左边的变量的类型(子类)<右边对象/变量的编译时类型(父类),我们就称为向下转型
-
此时,编译时按照左边变量的类型处理,就可以调用子类特有的变量和方法了
-
但是,运行时,仍然是对象本身的类型
-
不是所有通过编译的向下转型都是正确的,可能会发生ClassCastException,为了安全,可以通过isInstanceof关键字进行判断
-
7. Object 类的使用
7.1 如何理解根父类
类 java.lang.Object是类层次结构的根类,即所有其它类的父类。每个类都使用 Object 作为超类。
Object类型的变量与除Object以外的任意引用数据类型的对象都存在多态引用。
-
所有对象(包括数组)都实现这个类的方法。
-
如果一个类没有特别指定父类,那么默认则继承自Object类。
第08章_面向对象编程(高级)
7. 接口(interface)
7.1 类比
生活中大家每天都在用USB接口,那么USB接口与我们今天要学习的接口有什么相同点呢?
USB,(Universal Serial Bus,通用串行总线)是Intel公司开发的总线架构,使得在计算机上添加串行设备(鼠标、键盘、打印机、扫描仪、摄像头、充电器、MP3机、手机、数码相机、移动硬盘等)非常容易。
只要设备遵循USB规范的,那么就可以与电脑互联,并正常通信。至于这个设备、电脑是哪个厂家制造的,内部是如何实现的,我们都无需关心。
Java的软件系统会有很多模块组成,那么各个模块之间也应该采用这种面向接口的低耦合,为系统提供更好的可扩展性和可维护性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









