






$ pip install scikit-learn
$ pip install scipy
本文选取的示例数据是最近几天从某网站获取的实际生产日志数据,从技术层面来看,这些数据并不能算作是大数据,因为它的大小只有大约2Mb,但就演示来说已经足够了。
如果你想获取这些示例数据,可以使用git从作者的公共GitHub存储库中下载:admintome / access-log-data
$ git clone https://github.com/admintome/access-log-data.git
数据是一个简单的CSV文件,因此每行代表一个单独的日志,字段用逗号分隔:
2018-08-01 17:10,‘www2’,‘www_access’,‘172.68.133.49 - - [01/Aug/2018:17:10:15 +0000] “GET /wp-content/uploads/2018/07/spark-mesos-job-complete-1024x634.png HTTP/1.0” 200 151587 “https://dzone.com/” “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36”’
以下是日志行架构:
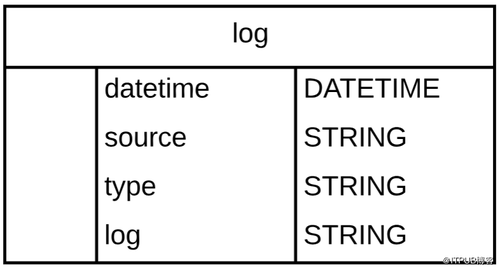
由于对数据可执行的操作的复杂性不确定,因此本文重点选取加载数据和获取数据样本两个操作来讲解三个工具。
**1、Python Pandas**
我们讨论的第一个工具是Python Pandas。正如它的网站所述,Pandas是一个开源的Python数据分析库。它最初由AQR Capital Management于2008年4月开发,并于2009年底开源,目前由专注于Python数据包开发的PyData开发团队继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。
首先,启动IPython并对示例数据进行一些操作。(因为pandas是python的第三方库所以使用前需要安装一下,直接使用pip install pandas 就会自动安装pandas以及相关组件)
import pandas as pd
headers = [“datetime”, “source”, “type”, “log”]
df = pd.read_csv(‘access_logs_parsed.csv’, quotechar=“'”, names=headers)
大约一秒后,我们会收到如下回复:
[6844 rows x 4 columns]
In [3]:
如上所见,我们有大约7000行数据,它从中找到了四个与上述模式匹配的列。
Pandas自动创建了一个表示CSV文件的DataFrame对象,Pandas中的DataFrame数据既可以存储在SQL数据库中,也可以直接存储在CSV文件中。接下来我们使用head()函数导入数据样本。
In [11]: df.head()
Out[11]:
datetime source type log
2018-08-01 17:10 www2 www_access 172.68.133.49 - - [01/Aug/2018:17:10:15 +0000]…
2018-08-01 17:10 www2 www_access 162.158.255.185 - - [01/Aug/2018:17:10:15 +000…
2018-08-01 17:10 www2 www_access 108.162.238.234 - - [01/Aug/2018:17:10:22 +000…
2018-08-01 17:10 www2 www_access 172.68.47.211 - - [01/Aug/2018:17:10:50 +0000]…
2018-08-01 17:11 www2 www_access 141.101.96.28 - - [01/Aug/2018:17:11:11 +0000]…
使用Python Pandas可以做很多事情, 数据科学家通常将Python Pandas与IPython一起使用,以交互方式分析大量数据集,并从该数据中获取有意义的商业智能。
**2、PySpark**
我们讨论的第二个工具是PySpark,该工具来自Apache Spark项目的大数据分析库。
PySpark提供了许多用于在Python中分析大数据的功能,它自带shell,用户可以从命令行运行。
$ pyspark
这会加载pyspark shell:
(python-big-data)[email protected]:~/Development/access-log-data$ pyspark Python 3.6.5 (default, Apr 1 2018, 05:46:30) [GCC 7.3.0] on linux Type “help”, “copyright”, “credits” or “license” for more information. 2018-08-03 18:13:38 WARN Utils:66 - Your hostname, admintome resolves to a loopback address: 127.0.1.1; using 192.168.1.153 instead (on interface enp0s3) 2018-08-03 18:13:38 WARN Utils:66 - Set SPARK_LOCAL_IP if you need to bind to another address 2018-08-03 18:13:39 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform… using builtin-java classes where applicable Setting default log level to “WARN”. To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Welcome to ____ __ / / ___ / / \ / _ / _ `/ __/ '/ / / ._/_,// //_\ version 2.3.1 // Using Python version 3.6.5 (default, Apr 1 2018 05:46:30) SparkSession available as ‘spark’. >>>
当你启动shell时,你会得到一个Web GUI查看你的工作状态,只需浏览到http:// localhost:4040即可获得PySpark Web GUI。
让我们使用PySpark Shell加载示例数据:
dataframe = spark.read.format(“csv”).option(“header”,“false”).option(“mode”,“DROPMALFORMED”).option(“quote”,“'”).load(“access_logs.csv”)
dataframe.show()
PySpark提供了已创建的DataFrame示例:
dataframe2.show()
±---------------±—±---------±-------------------+
| _c0| _c1| _c2| _c3|
±---------------±—±---------±-------------------+
|2018-08-01 17:10|www2|www_access|172.68.133.49 - -…|
|2018-08-01 17:10|www2|www_access|162.158.255.185 -…|
|2018-08-01 17:10|www2|www_access|108.162.238.234 -…|
|2018-08-01 17:10|www2|www_access|172.68.47.211 - -…|
|2018-08-01 17:11|www2|www_access|141.101.96.28 - -…|
|2018-08-01 17:11|www2|www_access|141.101.96.28 - -…|
|2018-08-01 17:11|www2|www_access|162.158.50.89 - -…|
|2018-08-01 17:12|www2|www_access|192.168.1.7 - - […|
|2018-08-01 17:12|www2|www_access|172.68.47.151 - -…|
|2018-08-01 17:12|www2|www_access|192.168.1.7 - - […|
|2018-08-01 17:12|www2|www_access|141.101.76.83 - -…|
|2018-08-01 17:14|www2|www_access|172.68.218.41 - -…|
|2018-08-01 17:14|www2|www_access|172.68.218.47 - -…|
|2018-08-01 17:14|www2|www_access|172.69.70.72 - - …|
|2018-08-01 17:15|www2|www_access|172.68.63.24 - - …|
|2018-08-01 17:18|www2|www_access|192.168.1.7 - - […|
|2018-08-01 17:18|www2|www_access|141.101.99.138 - …|
|2018-08-01 17:19|www2|www_access|192.168.1.7 - - […|
|2018-08-01 17:19|www2|www_access|162.158.89.74 - -…|
|2018-08-01 17:19|www2|www_access|172.68.54.35 - - …|
±---------------±—±---------±-------------------+
only showing top 20 rows
我们再次看到DataFrame中有四列与我们的模式匹配,DataFrame此处可以被视为数据库表或Excel电子表格。
**3、Python SciKit-Learn**
任何关于大数据的讨论都会引发关于机器学习的讨论,幸运的是,Python开发人员有很多选择来使用机器学习算法。
在没有详细介绍机器学习的情况下,我们需要获得一些执行机器学习的数据,我在本文中提供的示例数据不能正常工作,因为它不是数字类型的数据。我们需要操纵数据并将其呈现为数字格式,这超出了本文的范围,例如,我们可以按时间映射日志以获得具有两列的DataFrame:一分钟内的日志数和当前时间:
±-----------------±–+
| 2018-08-01 17:10 | 4 |
±-----------------±–+
| 2018-08-01 17:11 | 1 |
±-----------------±–+
通过这种形式的数据,我们可以执行机器学习算法来预测未来可能获得的访客数量,SciKit-Learn附带了一些样本数据集,我们可以加载一些示例数据,来看一下具体如何运作。
In [1]: from sklearn import datasets
In [2]: iris = datasets.load_iris()
In [3]: digits = datasets.load_digits()
In [4]: print(digits.data)
[[ 0. 0. 5. … 0. 0. 0.]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









