








这里可以看到,拼音分词器不光对每个字用拼音进行分词,还对每个字的首字母进行分词.
1.3、自定义分词器
1.3.1、为什么要自定义分词器
根据上述测试,可以看出.
-
拼音分词器是将一句话中的每一个字都分成了拼音,这没什么实际的用处.
-
这里并没有分出汉字,只有拼英. 实际的使用中,用户更多的是使用汉字去搜,有拼音只是锦上添花,但是也不能只用拼音分词器,把汉字丢了.
因此这里我们需要对拼音分词器进行一些自定义的配置.
1.3.2、分词器的构成
想要自定义分词器,首先要先了解 es 中分词器的构成.
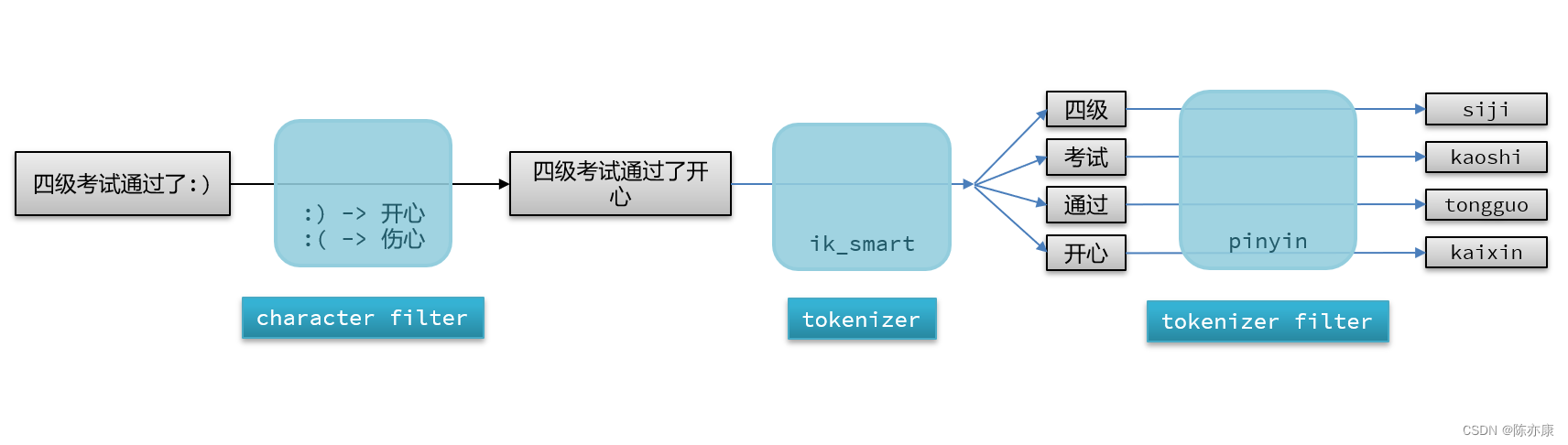
分词器主要由以下三个部分组成:
- character filters:在 tokenizer 之前,对文本的特殊字符进行处理. 比如他会把文本中出现的一些特殊字符转化成汉字,例如 😃 => 开心.
- tokenizer:将文本按照一定的规则切割成词条(term). 例如 “我很开心” 会切割成 “我”、“很”、“开心”.
- tokenizer filter:对 tokenizer 进一步处理. 例如将汉字转化成拼音.
1.3.3、自定义分词器
PUT /test
{
"settings": {
"analysis": {
"analyzer": { //自定义分词器
"my_analyzer": { //自定义分词器名称
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
}
}
- “type”: “pinyin”:指定使用拼音过滤器进行拼音转换。
- “keep_full_pinyin”: false:表示不保留完整的拼音。如果设置为true,则会将完整的拼音保留下来。
- “keep_joined_full_pinyin”: true:表示保留连接的完整拼音。当设置为true时,如果某个词的拼音有多个音节,那么它们将被连接在一起作为一个完整的拼音。
- “keep_original”: true:表示保留原始词汇。当设置为true时,原始的中文词汇也会保留在分词结果中。
- “limit_first_letter_length”: 16:限制拼音首字母的长度。默认为16,即只保留拼音首字母的前16个字符。
- “remove_duplicated_term”: true:表示移除重复的拼音词汇。如果设置为true,则会移除拼音结果中的重复词汇。
- “none_chinese_pinyin_tokenize”: false:表示是否对非中文文本进行拼音分词处理。当设置为false时,非中文文本将保留原样,不进行拼音分词处理
例如,创建一个 test 索引库,来测试自定义分词器.
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
使用此索引库的分词器进行测试

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 608
608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









