






概括
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
联邦学习作为分布式学习的一种形式,其目的是在利用分布式数据训练全局模型的同时保护本地数据。然而,联邦学习仍然面临着物联网(IoT)中隐私泄露的挑战。研究表明,服务器可以从局部梯度中推断出隐私信息。此外,恶意参与者可能会上传中毒的局部模型,这会污染全局模型并导致准确性下降。此外,真实的世界中具有低质量数据的不规则参与者也会影响全局模型的性能。同时解决这三个问题是一项重大挑战。这是因为FL中的隐私保护策略旨在防止访问局部梯度以避免信息泄漏。然而,具有拜占庭鲁棒性和防御不规则参与者的策略通常需要访问局部梯度来计算每个参与者的可靠性。因此,我们使用秘密共享作为底层技术,提出了一个3PC隐私保护的联邦学习框架BPFL,可以抵抗拜占庭攻击和非常规参与者。与已有的方案相比,该方案不仅能够保护数据隐私,而且能够最大限度地减少恶意或非正常参与者对全局模型的负面影响。我们实现了BPFL,并与Mkrum和PPFL进行了比较。实验结果表明,该方法在面对恶意攻击者和不规则参与者时保持了较高的性能。
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
提示:这里可以添加本文要记录的大概内容:
然而,在物联网场景中,深度学习仍面临许多挑战和问题。深度学习通常依赖于集中式训练方法,其中大量客户端将本地数据发送到云服务器进行集中式模型训练[5],这可能导致敏感数据泄露。在今天的数字经济中,数据是基础资源,数据隐私保护是物联网治理的基础。因此,提出了一种分布式学习方法——联邦学习(Federated Learning, FL)。在联邦学习中,客户端将本地模型发送到云服务器,而不会暴露本地敏感数据。联邦学习实现了数据本地存储,显著增强了数据隐私保护,同时也促进了联邦学习在各个领域的广泛应用。例如,在智能交通管理系统中,联邦学习的重要性不可忽视。这种先进的分布式学习技术不仅显著提升了道路交通管理的智能化水平,而且在保护数据隐私方面起着至关重要的作用。具体来说,联邦学习允许不同的交通管理设备在本地进行模型训练,即本地数据无需传输到中心服务器,从而大大减少了数据泄露的风险。此外,联邦学习为不同地区的交通管理部门提供了协作的机会。传统的交通管理系统通常是地区性的,跨地区的协作管理较为困难。然而,通过联邦学习,来自不同地区的交通管理部门可以共享本地模型参数,共同训练全局模型。这不仅有助于提高预测准确性,还促进了不同地区之间的信息交换和管理协作,实现了更加高效和智能的跨地区交通管理。
然而,一些研究[6][7]表明,在联邦学习中,服务器可以从接收到的本地梯度中推断出一些私密信息。为了解决这个问题,研究人员采用了保护措施,如差分隐私[8]、安全多方计算[9][10]和同态加密[11][12],以确保私密数据的安全。不同的保护措施采取不同的形式进行保护。尽管隐私保护的联邦学习保护了参与者的数据隐私,但另一个挑战是,大多数物联网场景假设联邦学习中的参与者都是诚实的。然而,由于联邦学习缺乏鲁棒性,它仍然容易受到来自恶意参与者的中毒攻击。拜占庭攻击者可以更改本地数据集[13][14][15],或直接将不正确的参数上传到云服务器,导致模型无法正确收敛或大幅度降低模型准确性。为应对拜占庭攻击并提高联邦学习的鲁棒性,提出了多项研究[18][19][20][21]。这些研究通过减少恶意攻击者的负面影响来提高鲁棒性,但并未考虑数据隐私保护。因此,另一些研究[22][23][24][25]提出了在保护本地模型隐私的同时,解决拜占庭攻击问题。例如,FLOD[22]基于FLTrust[20]和FLGUARD[26]提出了改进方案,通过使用汉明距离分析本地模型的重要性,并去除具有较大距离的恶意攻击者。然而,FLOD使用了同态加密和电路加扰,导致一定的计算成本。类似地,PEFL[24]通过计算皮尔逊相关系数来减轻拜占庭攻击,从而区分恶意参与者的本地模型。然而,PEFL也使用了线性同态加密作为底层技术,这也导致了一定的计算开销。因此,我们需要解决的第一个问题是如何在物联网中有效抵抗拜占庭攻击,同时保护参与者的隐私。
第二个问题是,物联网中的联邦学习涉及多个参与者,每个参与者的本地数据质量不尽相同,因此在现实世界中存在低质量数据的异常参与者。例如,低质量数据可能存在错误标注和噪声等问题。与恶意攻击者不同,这些异常参与者并不主动攻击模型,而是通过其本地数据的低质量对聚合模型产生负面影响。为减轻上述风险,提出了一些研究[27][28][29][30]。一些研究探索了一种方法,其中参与者在本地计算本地模型的可靠性,然后将可靠性和本地模型发送给服务器。服务器通过聚合来自不同参与者的信息来构建全局模型。然而,需要注意的是,这种策略假设参与者是诚实且非恶意的。因此,在面临潜在的拜占庭攻击时,即当某些恶意参与者可能发送错误或恶意数据时,这种策略是脆弱的,并且对这种攻击无效。例如,Xu等人[30]提出了双重掩码机制,旨在减少不可靠参与者的负面影响并保护本地模型的隐私。然而,可靠性是由参与者自己计算的,因此该方案无法抵御拜占庭攻击。因此,我们的第二个问题是如何在物联网中减少异常参与者的负面影响,同时抵御拜占庭攻击。
为了解决上述问题,我们提出了BPFL,一个具有拜占庭鲁棒性并能够应对异常参与者的安全联邦学习框架。BPFL与其他方案的比较如表I所示。BPFL的贡献可以总结如下:
我们提出了一种基于三方计算(3PC)的隐私保护联邦学习框架BPFL。以秘密共享为底层技术,BPFL保证了参与者的私密数据(包括本地模型、可靠性和全局模型)的机密性。
我们在3PC设置中提出了两个子协议FClipping和FReliability,以抵御拜占庭攻击和异常参与者,并提出了FAggregate进行安全聚合。此外,为了确保协议的准确性和安全性,我们提供了BPFL及其三个子协议的全面安全分析。
提示:以下是本篇文章正文内容,下面案例可供参考
相关工作
抗拜占庭攻击
A. 针对拜占庭攻击的隐私保护联邦学习
Cao等人[20]提出了一种名为FLTrust的联邦学习方案,具有拜占庭鲁棒性,其中服务器持有一个干净的小规模数据集,并基于该数据集维护一个服务器模型。服务器为每个参与者分配一个信任分数,该分数是基于各自本地模型与服务器模型之间的偏差程度计算的。然而,在这个方案中,参与者直接将其本地模型以明文形式传输给服务器。因此,尽管FLTrust在处理恶意参与者方面表现出了鲁棒性,但在保护参与者数据隐私方面存在不足。
Lu等人[32]提出了RVPFL,一个鲁棒且可验证的隐私保护联邦学习方案。RVPFL的核心思想是将隐私计算技术与联邦学习相结合,利用同态加密来确保数据在传输和计算过程中的隐私。具体来说,通过使用同态加密,本地梯度在上传到服务器之前会进行加密,从而确保本地数据的隐私。在服务器端,RVPFL使用中值梯度和调整过的余弦相似度来衡量梯度在密文状态下的方向和幅度。这种测量方法有效防止了恶意对手通过计算梯度与基准之间的方向和距离差异来破坏聚合结果。然而,RVPFL利用同态加密进行复杂操作,导致了较高的计算开销。
Dong等人[22]提出了一种名为FLOD的联邦学习系统,旨在保护隐私并防御拜占庭攻击。FLOD通过计算每个本地模型与聚合模型之间的汉明距离来衡量相似性,并去除距离较大的本地模型更新。为了抵抗拜占庭攻击,他们引入了支持XOR的sgn/布尔转换方法,并提出了基于Yao电路的预设阈值来修剪距离。
Liu等人[24]提出了一个名为PEFL的隐私保护联邦学习框架,用于抵御中毒攻击。他们采用同态加密作为底层技术,并使用皮尔逊相关系数和对数函数来惩罚低相关度的参与者。然而,该框架以明文形式计算可靠性,因此恶意服务器可能会发起推断攻击。此外,该框架还存在单点故障问题。
Zhang等人[25]提出了一个名为LSFL的轻量级联邦学习框架,该框架使用秘密共享来去除攻击者,并在两个服务器之间聚合全局模型,在抵抗拜占庭攻击的同时保护参与者本地模型的隐私。然而,参与者的可靠性和聚合模型在服务器上以明文形式暴露,这导致该方案的安全性不足。
Dong等人[23]提出了一个隐私保护且具有拜占庭鲁棒性的联邦学习方案,名为P2Brofl,该方案使用秘密共享和MAC来提高鲁棒性,并在三个不合谋的服务器中安全聚合。但该方法没有考虑现实世界中的异常参与者。
算数秘密共享






全局更新(抵抗拜占庭攻击)

系统模型
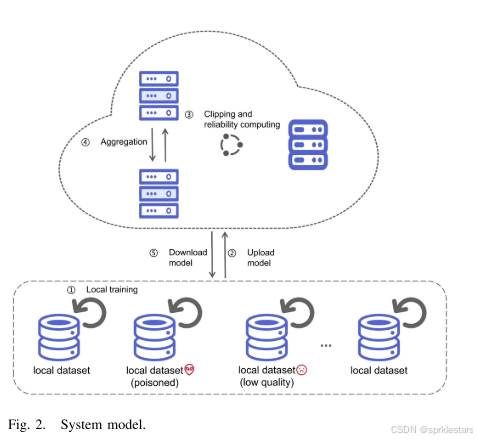





系统流程


BPFL







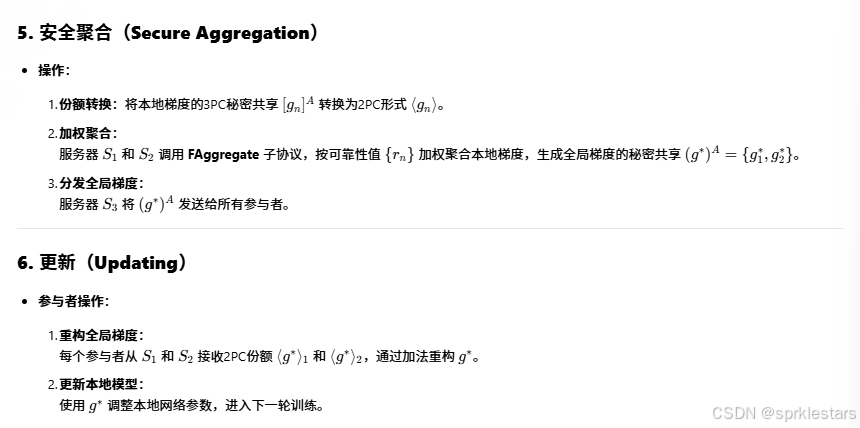
总结:门限密钥共享+过滤恶意模型防拜占庭+效率优化增加聚合速度


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









