






目录
一、Makefile 文件
Makefile 用来管理代码的编译和链接。
1、Makefile 语法
用法规则(格式)
![]()
例如:
a.out:main.c link.c
gcc main.c link.c -o a.out| 对于 gcc main.c link.c -o a.out |
| 目标文件:a.out |
| 依赖文件(源文件):main.c link.c |
2、Makefile 中的变量
1)自定义变量(无数据类型)
统一当字符串处理,
定义时:变量名=值
引用时:$(变量名)
头文件引用 ( 指定头文件位置 ) :-I$((变量名)
库文件引用 ( 指定使用的库文件位置 ) :-L$(变量名)
例如: 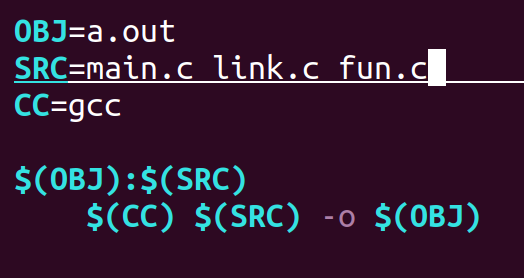
2)系统变量
$^: :所有依赖文件
$<: :第一个依赖文件
$@: :生成的目标
例如: 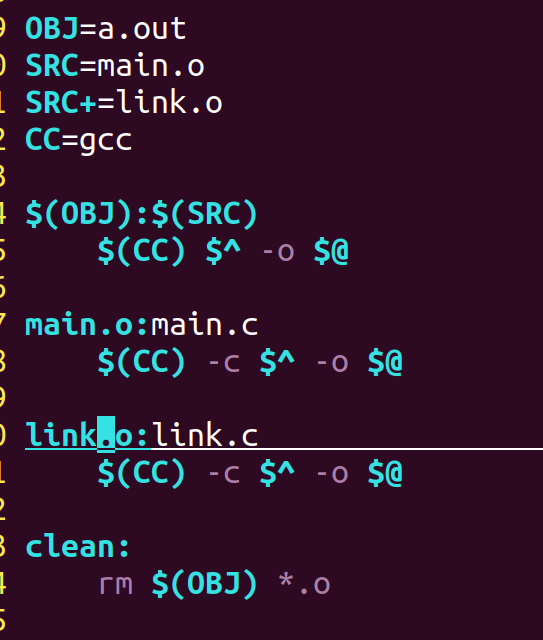
3、gcc 编译的四个步骤
在正式使用 Makefile 之前,我们需要了解 gcc 的四个编译步骤,以便更好地理解、应用 Makefile 文件。gcc 编译的四个步骤为:(格式中皆以 main.c 文件为例)
1)预处理:处理和 “ # ” 相关的指令(头文件展开与条件声明等);
格式:gcc -E main.c -o main.i
2)编译:将源程序转换成汇编指令;
格式:gcc -S main.i -o main.s
3)汇编:将汇编指令生成二进制指令;
格式:gcc -c main.c -o main.o
4)链接:实现多文件以及函数的链接关系;
格式:gcc main.o(其他 .o 文件) -o app
4、调用执行 Makefile
在终端输入 make ,可以执行当前文件路径下的 Makefile(编译),然后运行。
在终端输入 make clen 执行伪目标。当重复输入 make 会重复执行 Makefile 导致出现 “ make: 'a.out' is up to date. ” 字样,为防止这种现象出现,需再在 Makefile 中加入伪目标指令,其一般格式为:

例如:删除目标文件
| clean: |
| rm $(OBJ) |
5、通配符(%)
在文件夹中,存在多个 .c 、.o 文件,可以通过在 Makefile 中使用通用符来简化该过程,使得修改方便
例如将注释掉的 main.o 与 link.o 几行,可整体写为含 % 号的两行:

可以简写为:
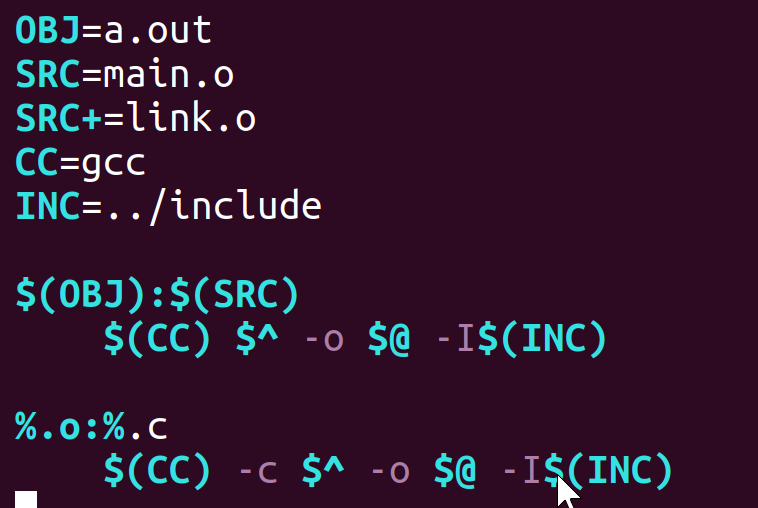
最终书写格式为(注释部分可以删掉):
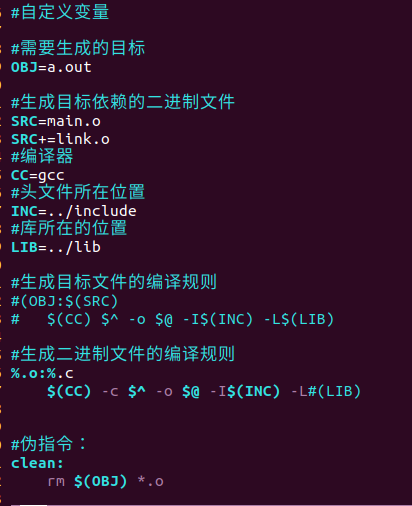
6、时间戳
在编译代码时,只编译修改后的源文件,其他没有修改的,只进行链接即可,提高程序编译效率,节省时间
二、双向链表
1、概念
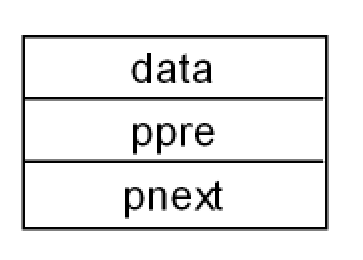
双向链表时一种线形数据结构,由多个结点组成,每个结点包含三部分:
(1) 数据域(data):存储结点的具体信息(如数值、字符等)。
(2) 前驱指针域(ppre):存储前一个结点的地址(或引用),用于指向当前结点的上一个结点。
(3) 后继指针域(pnext):存储后一个结点的地址(或引用),用于指向当前结点的后一个结点。
链表的第一个结点(头结点)的前驱指针为 NULL,最后一个结点(尾结点)的后继指针为 NULL,结点之间通过前驱和后继指针形成 “ 双向链接 ”。
链接效果为:

2、作用
支持双向遍历和高效的结点前后操作。
1)双向遍历
既能从头到尾遍历(通过后继指针),也能从尾到头遍历(通过前驱指针),灵活性更高。
2)高效插入/删除
若已知某节点,无需从头遍历即可直接找到其前驱节点,在该结点进行操作,时间复杂度为 O(1)。
3、应用
1)函数封装
(1) 双向链表的创建函数的封装
DLink_t *create_doulink()
{
DLink_t *pdlink = malloc(sizeof(DLink_t));
if(NULL == pdlink)
{
printf("malloc error!");
return NULL;
}
pdlink -> phead = NULL;
pdlink -> clen = 0;
return pdlink;
}
(2) 双向链表---判断是否为空链表函数的封装
/*是否为空的判断*/
int is_empty_doulink(DLink_t *pdlink)
{
return NULL == pdlink -> phead;
}(3) 双向链表---遍历函数的封装(正反)
/*遍历*/
void dlink_for_each(DLink_t *pdlink, int dir)
{
if(is_empty_doulink(pdlink))
{
return ;
}
DNode_t *ptmp = pdlink -> phead;
if(dir) //正向遍历pnext
{
while(ptmp != NULL)
{
printf("%d %s %d\n", ptmp->data.id, ptmp->data.name, ptmp->data.score);
ptmp = ptmp -> pnext;
}
}
else //反向遍历ppre
{
while(ptmp -> pnext != NULL)
{
ptmp = ptmp -> pnext;
}
while(ptmp != NULL)
{
printf(" %d %s %d\n", ptmp->data.id, ptmp->data.name, ptmp->data.score);
ptmp = ptmp -> ppre;
}
}
printf("\n");
}
(4) 双向链表---头部插入函数的封装
/*头插*/
int insert_doulink_head(DLink_t *pdlink, Data_type_t data)
{
DNode_t *pnode = malloc(sizeof(DNode_t));
if(NULL == pnode)
{
printf("malloc error");
return -1;
}
pnode -> data = data;
pnode -> ppre = NULL;
pnode -> pnext = NULL;
if(is_empty_doulink(pdlink))
{
pdlink -> phead = pnode;
}
else
{
pnode -> pnext = pdlink -> phead;
pdlink -> phead -> ppre = pnode;
pdlink -> phead = pnode;
}
pdlink -> clen++;
return 0;
}(5) 双向链表---头删函数的封装
/*头删*/
int delete_doulink_head(DLink_t *pdlink)
{
if(is_empty_doulink(pdlink))
{
return -1;
}
DNode_t *ptmp = pdlink -> phead;
pdlink -> phead = ptmp -> pnext;
if(pdlink -> phead != NULL)
{
pdlink -> phead -> ppre = NULL;
}
free(ptmp);
pdlink -> clen--;
return 0;
}(6) 双向链表---尾部插入数据函数的封装
/*尾插*/
int insert_doulink_tail(DLink_t *pdlink, Data_type_t data)
{
DNode_t *pnode = malloc(sizeof(DNode_t));
if(NULL == pnode)
{
printf("malloc error!");
return -1;
}
pnode -> data = data;
pnode -> pnext = NULL;
pnode -> ppre = NULL;
if(is_empty_doulink(pdlink))
{
pdlink -> phead = pnode;
}
else
{
DNode_t *ptmp = pdlink -> phead;
while(ptmp -> pnext != NULL)
{
ptmp = ptmp -> pnext;
}
ptmp -> pnext = pnode;
pnode -> ppre = ptmp;
}
pdlink -> clen++;
return 0;
}
(7) 双向链表---尾删函数的封装
/*尾删*/
int delete_doulink_tail(DLink_t *pdlink)
{
if(is_empty_doulink(pdlink))
{
return -1;
}
DNode_t *ptmp = pdlink -> phead;
if(1 == pdlink -> clen)
{
free(ptmp);
pdlink -> phead = NULL;
}
else
{
while(ptmp -> pnext != NULL)
{
ptmp = ptmp -> pnext;
}
ptmp -> ppre -> pnext = NULL;//前结点为NULL
free(ptmp);
}
pdlink -> clen--;
return 0;
}
(8) 双向链表---查找函数的封装
/*查找*/
DNode_t *find_doulink(DLink_t *pdlink, Data_type_t data)
{
DNode_t *ptmp = pdlink -> phead;
while(ptmp != NULL)
{
if(data.id == ptmp -> data.id)
{
return ptmp;
}
ptmp = ptmp -> pnext;
}
return NULL;
}(9) 双向链表---修改成绩函数的封装
/*修改成绩*/
int change_doulink(DLink_t *pdlink, char *olddata, int newdata)
{
DNode_t *ptmp = pdlink -> phead;
if(ptmp != NULL && strcmp(ptmp -> data.name, olddata ))
{
ptmp -> data.score = newdata;
return 0;
}
return -1;
}(10) 双向链表---删除指定结点函数的封装
/*删除指定结点*/
int delete_doulink_num(DLink_t *pdlink, Data_type_t data)
{
DNode_t *ptmp = find_doulink(pdlink, data);
if(ptmp != NULL)
{
ptmp -> ppre -> pnext = ptmp -> pnext;
ptmp -> pnext -> ppre = ptmp -> ppre;
free(ptmp);
return 0;
}
return -1;
}
上述内容需包含以下头文件
#include"doulink.h"
#include<stdio.h>
#include<stdlib.h>
2)头文件(声明)
(1) 封装结点(以将 data 定义为结构体为例)
typedef struct stu
{
int id;
char name[32];
int score;
}Data_type_t;
typedef struct dounode
{
Data_type_t data;
struct dounode *ppre;
struct dounode *pnext;
}DNode_t;
(2) 封装对象
typedef struct doulink
{
DNode_t *phead;
int clen;
}DLink_t;(3) 函数声明
#ifndef _DOULINK_H_
#define _DOULINK_H_
extern DLink_t *create_doulink();
extern int insert_doulink_head(DLink_t *pdlink, Data_type_t data);
extern int is_empty_doulink(DLink_t *pdlink);
extern void dlink_for_each(DLink_t *pdlink, int dir);
extern int insert_doulink_tail(DLink_t *pdlink, Data_type_t data);
extern int delete_doulink_head(DLink_t *pdlink);
extern int delete_doulink_tail(DLink_t *pdlink);
extern DNode_t *find_doulink(DLink_t *pdlink, Data_type_t data);
extern int change_doulink(DLink_t *pdlink, char *olddata, int newdata);
extern int delete_doulink_num(DLink_t *pdlink, Data_type_t data);
#endif3)在主函数中书写格式
#include<stdio.h>
#include"doulink.h"
int main(void)
{
Data_type_t stus[5] = {{1, "zhangsan", 99},
{2, "lisi", 100},
{3, "wangwu", 90},
{4, "maliu", 56},
{5, "tianqi", 66}};
DLink_t *pdlink = create_doulink();
if(NULL == pdlink)
{
return -1;
}
//头插
insert_doulink_head(pdlink, stus[0]);
insert_doulink_head(pdlink, stus[1]);
insert_doulink_head(pdlink, stus[2]);
insert_doulink_head(pdlink, stus[3]);
insert_doulink_head(pdlink, stus[4]);
dlink_for_each(pdlink, 1);//正向遍历pnext
dlink_for_each(pdlink, 0);//反向遍历ppre
//尾插
insert_doulink_tail(pdlink, stus[2]);
insert_doulink_tail(pdlink, stus[3]);
insert_doulink_tail(pdlink, stus[4]);
dlink_for_each(pdlink, 1);//遍历
delete_doulink_head(pdlink);//头删
dlink_for_each(pdlink, 1);
delete_doulink_tail(pdlink);//尾删
DNode_t *ret = NULL;
ret = find_doulink(pdlink, stus[3]);//查找
printf("%d %s %d\n", ret->data.id, ret->data.name, ret->data.score);
printf("\n");
change_doulink(pdlink, i, 83);//修改成绩
dlink_for_each(pdlink, 1);
delete_doulink_num(pdlink, stus[3]);//删除指定结点
dlink_for_each(pdlink, 1);
return 0;
}【END】

















 2045
2045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









