






Elasticsearch 是一个非常强大的搜索引擎。它目前被广泛地使用于各个 IT 公司。Elasticsearch 是由 Elastic 公司创建。它的代码位于 GitHub - elastic/elasticsearch: Free and Open, Distributed, RESTful Search Engine。Elasticsearch 是一个分布式、免费和开放的搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。 Elasticsearch 基于 Apache Lucene 构建,并于 2010 年由 Elasticsearch N.V. 首次发布(现在称为 Elastic)。Elasticsearch 以其简单的 REST API、分布式特性、速度和可扩展性而闻名,是 Elastic Stack 的核心组件,Elastic Stack 是一组用于数据摄取、丰富、存储、分析和可视化的免费开放工具。 通常被称为 ELK Stack。Elastic 公司也同时拥有 Logstash 及 Kibana 开源项目。这个三个项目组合在一起,就形成了 ELK 软件栈。他们三个共同形成了一个强大的生态圈。简单地说,Logstash 负责数据的采集,处理(丰富数据,数据转换等),Kibana 负责数据展示,分析,管理,监督,警报及方案。Elasticsearch 处于最核心的位置,它可以帮我们对数据进行存储,并快速地搜索及分析数据。随着后来的 Beats 加入,ELK 软件栈,也被称为 ELKB。
要想快速入门新技术,英文文档的阅读能力必不可少。本篇文章主要参考《Spring Data Elasticsearch》Spring Boot整合Elasticsearch的官方文档。
Elasticsearch官网参考文档:[https://www.elastic.co/guide/index.html]
Elasticsearch官方下载地址:[https://www.elastic.co/cn/downloads/elasticsearch]
Elasticsearch 能做什么?
Elasticsearch 的速度和可扩展性及其为多种类型的内容编制索引的能力意味着它可用于多种用例:
应用搜索,比如我们常见的 github,linkedin,滴滴,美团里的搜索
全局搜索 减轻数据库压力
网站搜索
企业搜索
日志记录和日志分析
使用linux Elasticsearch
根据自己的springboot版本选择合适的es版本和分词器版本
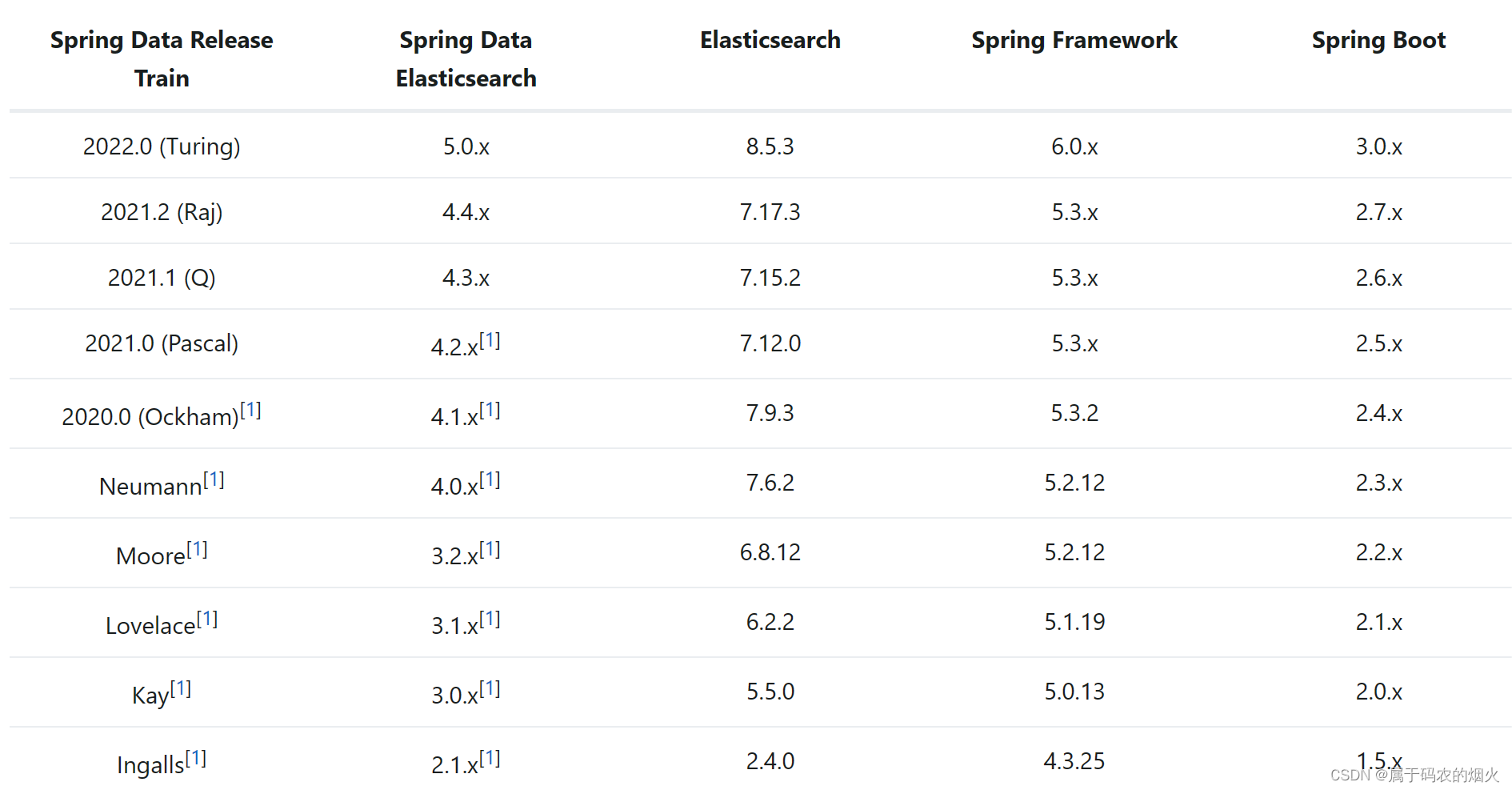
直接去https://www.elastic.co/guide/index.html官网下载对应的系统文件
copy到服务器或者虚拟机上 – 执行tar -zxvf elasticsearch.7.4.2.xxx进行压缩
进入到bin目录执行,./elasticsearch 启动,或者./elasticsearch -d后台启动
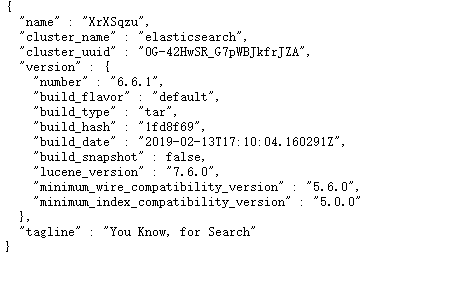
执行curl localhost:9200命令,如图所示,启动成功
但一般不会这么顺利 es也会报错
elasticsearch不能用root用户来运行**
报错信息:org.elasticsearch.bootstrap.StartupException: java.lang.RuntimeException:can not run elasticsearch as root
使用useradd xxx passwd 密码 创建用户
使用用户身份进行操作
chown 777 -R path // elasticsearch解压文件下的具体路径,一定要切换到root用户在给estest用户赋予权限
垃圾回收机制被标记废弃问题
报错信息:Java HotSpot(TM) 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
// 这个报错是告诉我们UseConcMarkSweepGC垃圾回收机器过时了,在未来可能被删除,我们要改成jdk11的垃圾回收机器
cd usr/local/elasticsearch/config
更改目录下的 jvm.options 文件 把垃圾回收机制 改成如下图片

如果还继续报错 elasticsearch占用内存问题
报错信息:Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000ca660000, 899284992, 0) failed; error='Not enough space' (errno=12)
修改jvm.options文件
-Xms512m
-Xmx512m
注意当您用user用户操作时 再bin目录下执行./elasticsearch 可能会报【Elasticsearch】bootstrap checks failed
ERROR: [2] bootstrap checks failed
[1]: initial heap size [4294967296] not equal to maximum heap size [8589934592]; this can cause resize pauses and prevents mlockall from locking the entire heap
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决方案:
max virtual memory areas vm.max_map_count
1.登录root用户,修改/etc/sysctl.conf配置文件,添加一行vm.max_map_count = 262144,然后sysctl -p
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
2./etc/security/limits.conf
追加
* soft nofile 65536
* hard nofile 65536
此文件修改后需要重新登录用户,才会生效
注意 es再linux没有使用docker安装 需要linux自带jdk11版本 且服务器开启9200端口 再root身份分配user权限时 操作es就用用户身份进行
bootstrap checks failed. You must address the points described in the following [1]
配置es.yml文件 打开
network.host: 0.0.0.0
node.name: node-1
cluster.initial_master_nodes: [“node-1”]
安装IK分词器
ElasticSearch v6.8.6: https://elastic.co/downloads/elasticsearch
IK分词器 v6.8.6:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v6.8.6
IK分词器指IK Analyzer,其是一个开源的,基于java语言开发的轻量级的中文分词工具包。
此处使用的ES版本为v6.8.0,所以IK分词器用的版本也是v6.8.0。
安装方法很简单,将下载下来的压缩包通过FTP上传到ElasticSearch安装目录下的/plugins/ik文件夹,并解压,重启ES即可。
Docker安装es和kibana
一.Kibana 介绍
Kibana 是一个开源且用于可视化和分析 Elasticsearch 数据的开源工具。它提供了一个直观的用户界面,使用户能够通过仪表板、图表和图形来探索和理解 Elasticsearch 中的数据。Kibana 是一个强大的工具,可以帮助您通过可视化和分析 Elasticsearch 数据来获得洞察力,并以直观的方式展示和共享数据。
可视化kibana和es版本要一致噢
docker pull kibana:7.17.3
二.在linux宿主机下 opt/目录下创建es文件夹 并进入es下创建config data plugins 文件夹 在plugins下创建elasticsearch.yml文件 回退es文件夹 修改es文件夹权限**
chmod -R 777 es
三.运行es
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx512m" -v /opt/es/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /opt/es/data:/usr/share/elasticsearch/data -v /opt/es/plugins:/usr/share/elasticsearch/plugins -d elasticsearch:7.17.3
docker run: 这是Docker的命令,用于启动一个新的容器。
--name elasticsearch: 这给容器命名为“elasticsearch”。
-p 9200:9200 -p 9300:9300: 这是端口映射。它将容器的9200端口映射到主机的9200端口,以及容器的9300端口映射到主机的9300端口。Elasticsearch默认使用这些端口。9300端口用于es集群之间调用
-e "discovery.type=single-node": 通过设置环境变量,告诉Elasticsearch以单节点模式运行。这意味着它不会尝试形成集群。
-e ES_JAVA_OPTS="-Xms64m -Xmx512m": 设置Elasticsearch的初始内存占用和最大内存占用堆大小。-Xms64m表示初始堆大小为64MB,-Xmx512m表示最大堆大小为512MB。
-v /opt/es/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml: 这是卷(volume)映射。它将主机的/opt/es/config/elasticsearch.yml文件映射到容器的/usr/share/elasticsearch/config/elasticsearch.yml位置。这意味着你可以在主机上修改Elasticsearch的配置文件,并且这些更改将在容器中生效。
-v /opt/es/data:/usr/share/elasticsearch/data: 同样是一个卷映射,用于映射Elasticsearch的数据目录。这允许你在主机上持久存储Elasticsearch的数据,即使容器被删除或重启,数据仍然存在。
-v /opt/es/plugins:/usr/share/elasticsearch/plugins: 这将主机的插件目录映射到容器的插件目录。这允许你在容器中安装额外的插件,并且这些插件将在主机上的相应目录中持久保存。
-d elasticsearch:7.6.2: 这告诉Docker以“分离”模式(后台运行)运行名为“elasticsearch”的7.6.2版本的Elasticsearch容器。
3.2 运行kibana首先确保docker容器的es能访问9200端口
启动ElasticSearch疯狂失败 需要到宿主机opt/es/config修改elasticsearch.yml文件
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
cluster.name: "docker-cluster"
network.host: 0.0.0.0
3.3 如果访问以下图片及成功

3.4 因为部署es在公网ip上 危险系数大 需要给es加访问密码
3.4.1进入es容器 找到/usr/share/elasticsearch/config此路径
3.4.2通过vi编辑 elasticsearch.yml文件
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
cluster.name: "docker-cluster"
network.host: 0.0.0.0
3.4.3重启es容器并输入
./bin/elasticsearch-setup-passwords interactive
一直输入一致的密码,然后重启es容器 访问9200端口需要输入密码即成功
注意如果3.4.3命令一直进不去 则添加网络
docker network create es-network
在运行容器命令加 --net=es-network
四.运行kibana
4.1 在宿主机下opt文件夹下创建kibana文件夹 并在文件夹下创建config,data文件夹 并在config文件夹下创建kibana.yml文件并修改yml文件内容 开启所有人访问 如果配置了es的访问密码则需要在配置文件在kibana的访问账号和密码
4.2 修改kibana.yml文件
# Default Kibana configuration for docker target
server.name: "kibana"
server.host: "0.0.0.0"
#server.shutdownTimeout: "5s"
elasticsearch.hosts: [ "http://ip地址:9200" ]
monitoring.ui.container.elasticsearch.enabled: true
# # 设置中文
i18n.locale: "zh-CN"
elasticsearch.username: "elastic"
elasticsearch.password: "xxx"
4.3 修改ip端口后运行kibana
docker run --name kibana \
-e ELASTICSEARCH_HOSTS=http://ip:9200 \
-p 5601:5601 \
-v /opt/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml -d kibana:7.17.3
4.4如果出现以下界面 则安装kibana成功
 下角标
下角标
##5.docker安装ik分词器
5.1进入es容器plugins文件夹去创建一个ik目录 在ik目录下下载ik包
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.3/elasticsearch-analysis-ik-7.17.3.zip
5.2重启docker es容器 访问kibana页面搜索
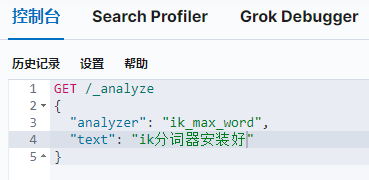
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "ik分词器安装好"
}

出现以上图片则ik分词器安装好
6.1 什么是Elasticsearch索引
ES索引是Elasticsearch中的一个概念,它把数据存放到一个或者多个索引中。索引是用于存储、组织数据的一种方式,类似于关系型数据库中的表。每个索引由一个或多个文档组成,每个文档是一个JSON对象,用于存储实体的数据。在Elasticsearch中,索引是进行搜索、分析、聚合等操作的基本单元。
6.2 什么是索引分片
ES索引分片是指将索引分成多个分片(shards),每个分片是一个最小级别的工作单元,保存了索引中的所有数据的一部分。这个分发的过程称为索引分片(Sharding)。在Elasticsearch集群中,索引分片是自动完成的,而且所有分片索引是作为一个整体呈现给用户的。索引分片有助于将数据分布在多个存储Lucene索引的物理机上,从而能够存储超出单机容量的信息。ES通过将索引划分为多个分片来允许大规模数据存储,并且能够水平扩展,每个分片可以分布在集群的不同节点上,默认情况下每个索引包含五个主分片。
6.3 什么是索引副本
ES索引副本是Elasticsearch中的一种机制,用于提高系统的容错性和查询效率。默认情况下,一个分片有一个副本。当某个节点或分片损坏或丢失时,可以从副本中恢复。同时,副本也可以提高Elasticsearch的查询效率,因为它会自动对搜索请求进行负载均衡。
ElasticSearch核心概念
7.1 节点
节点是集群中的单个服务器,用于存储数据并参与集群的索引和搜索功能。每个节点都有自己的名称和唯一标识符。
7.2 集群
集群是由一个或者多个节点组成的一组服务器,他们共同存储项目的整个数据,集群提供的高可用性和横向拓展性
7.3 分片和复制
分片是将索引中的数据分割成多个部分,用于提高性能和拓展性,每个分片可以被存储在集群中的一个或者多个节点上。
复制是为了数据的高可用性和容错性每个分片都会有一个或者多个副本文件这些分片会被存储在不同的节点上
7.4 索引
索引是用于存储数据的地方,类似于关系型数据库中的数据库,它是一种用于存储相似性质的文档的数据结构。
7.5 类型
类型在ES6.0之前用于组织索引内部文档的一种方式,在ES7.0版本之后已经被废弃,推荐使用单一索引,多字段代替。
7.6 文档
文档是ES基本数据单元,类似于关系型数据库中的行,每个文档都是一个JSON对象,它们被存储在索引中并可以被搜索。
7.7 字段
字段是ES中文档的组成部分,类似于关系型数据库中的列,每个字段都有自己的数据类型,并且包含特定的数据。
7.8 映射
映射定义了索引中的每个字段的数据类型和属性,它相当于关系型数据库中的模式,告诉ES如何处理索引的每个字段。
熟悉ES命令
8.1 创建索引
PUT /es_demo
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 2
},
"mappings": {
"properties": {
"message": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 20
}
}
}
}
}
}
8.2 创建文档 _doc
POST /taobao_good/_doc
{
"id":"3",
"name":"今麦郎酸萝卜牛肉面",
"price":"5",
"description":"方便面",
"stock":"100"
}
8.2.1 语法规则
_doc:用于早期的ES版本中,同一个索引中单独集合映射类型,从8.x版本开始已经全面废弃。
_index:创建新索引。index索引是创建一个命名空间,将相关文档聚合在一起。
_create:创建新索引,create是创建一个新的文档,并将其添加到指定索引中。
_update:用于更新文档中的一部分内容
_delete:删除文档
8.3 搜索文档 _search
GET /taobao_good/_search
{
"query": {
"match": {
"name": "康师傅"
}
}
}
8.3.1 返回结果

took: 搜索花费的时间,单位是毫秒。这里表示搜索耗时6毫秒。
timed_out: 表示搜索是否超时。这里表示没有超时。
_shards:
total: 参与搜索的shard总数。这里为2,意味着有两个shard参与了搜索。
successful: 成功搜索的shard数量。这里为2,表示两个shard都成功搜索了。
skipped: 被跳过的shard数量。这里为0,表示没有shard被跳过。
failed: 失败的shard数量。这里为0,表示没有shard失败。
hits:
total: 表示搜索到的匹配文档总数。这里只有一个匹配,所以值为1。
max_score: 匹配文档中的最高得分。这里是0.8630463。
hits: 实际的匹配文档列表。这里只有一个文档。
_index: 匹配文档所在的索引名称,这里是"taobao_good"。
_type: 在Elasticsearch 7.x版本之前,每个文档都有一个类型。但在7.x及之后的版本中,类型已被弃用。这里为"_doc",通常用于表示普通的文档类型。
_id: 匹配文档的ID。这里是"U7PrgIwB5SLcd_PQrg5w"。
_score: 匹配文档的得分。这里是0.8630463,它是基于文档与查询之间的相似度得出的。
_source: 匹配文档的原始数据内容。
id: 文档的ID,这里是"1"。
name: 商品的名称,这里是"康师傅红烧牛肉面"。
price: 商品的价格,这里是"5"。
description: 对商品的描述,这里是"方便面"。
stock: 商品的库存数量,这里是"100"。
8.4 查询指定字段的文档
GET /es_demo/_search
{
"query": {
"match": {
"title": "查询信息"
}
}
}
8.5 多条件查询
GET /taobao_good/_search
{
"query": {
"bool": { //多条件查询的一种方式
"must": [ //必须满足以下条件相当于sql当中的and
{"match":{"name": "康师傅"}},
{"match":{"description": "方"}}
]
}
}
}
🎉8.5.1
1.must 必须都匹配相当于逻辑的and
2.must_not 表示条件必须都不匹配相当于逻辑的not
3.should 表示条件可以匹配但不是必须满足相当于逻辑上的or
4.filter 表示条件必须匹配常用于过滤操作
8.6 修改商品
POST /taobao_good/_doc/VLPsgIwB5SLcd_PQHg4K
{
"name": "酸辣牛肉面",
"price": 9.99,
"description": "新商品描述"
}
_doc这种写法会重写原有数据结构,慎用
#修改商品
POST /taobao_good/_update/VbPsgIwB5SLcd_PQyg4b
{
"doc": {
"name": "xx酸辣牛肉面",
"price": 9.99,
"description": "xxxx"
}
}
_update这种写法只会修改对应的字段不会重写 如果没有文档没有值 则会添加文档字段
😃使用_doc操作是覆盖原数据完成修改(8.x版本之后移除),_update操作是非覆盖操作只完成更新
8.7 删除文档
DELETE /taobao_good/_doc/VLPsgIwB5SLcd_PQHg4K
通过_doc指定es_id删除
POST /taobao_good/_delete_by_query
{
"query":{
"match":{
"description": "xxxx"
}
}
}
通过mysql_id进行删除
##删除
POST /taobao_good/_delete_by_query
{
"query":{
"match_all":{
}
}
}
删除垃圾索引 删除所有匹配索引 切记 慎用
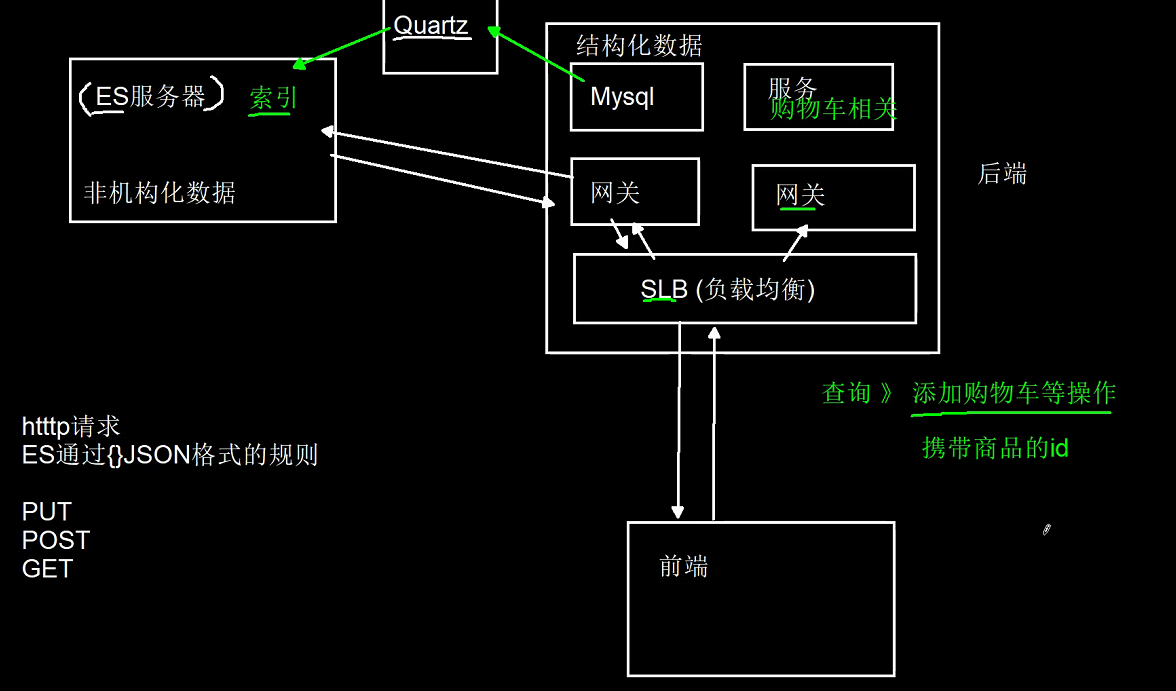
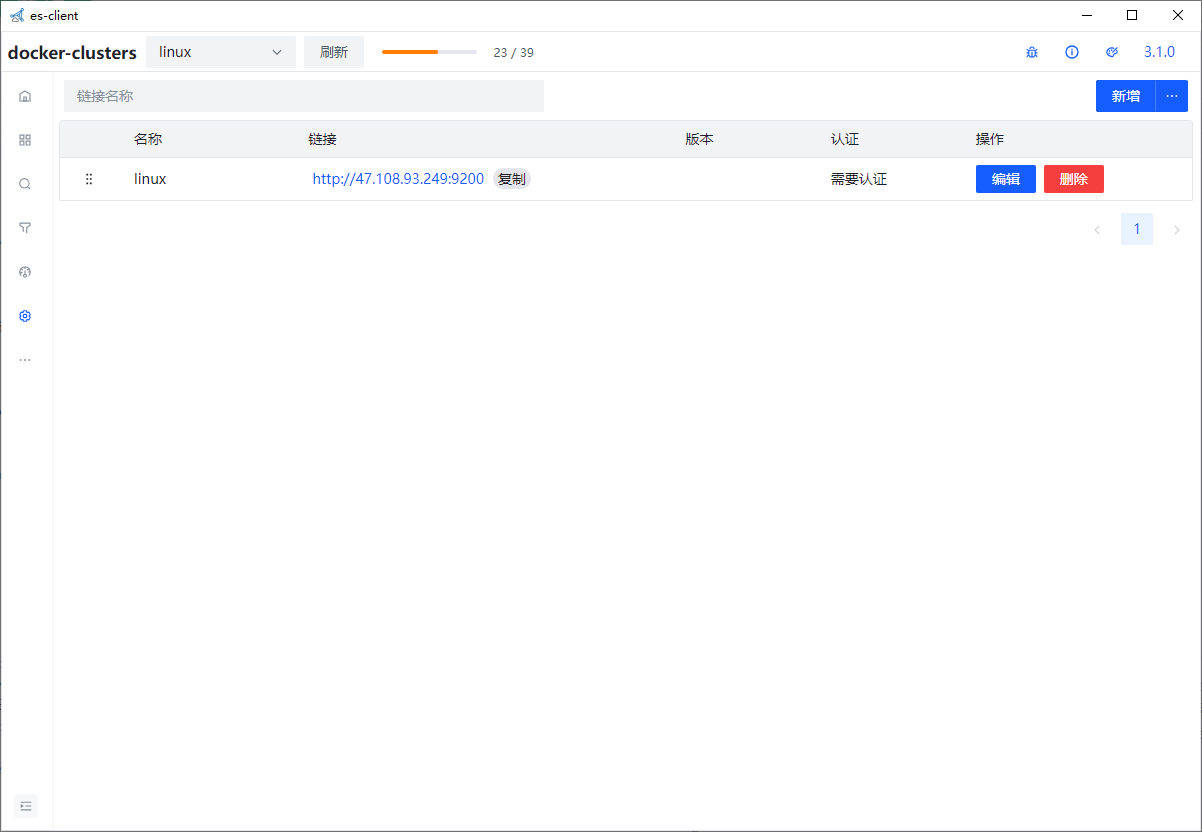
es-client
elasticsearch的客户端比较出名的就是elasticsearch head 和Kibana了, 但是elasticsearch head已经停止更新,且样式老旧,功能不全; 而Kibana虽功能全面,但是启动麻烦,大部分功能用不上,很不灵活,所以采用vite2+vue3+ts+arco-design进行开发了一个elasticsearch的客户端
下载地址
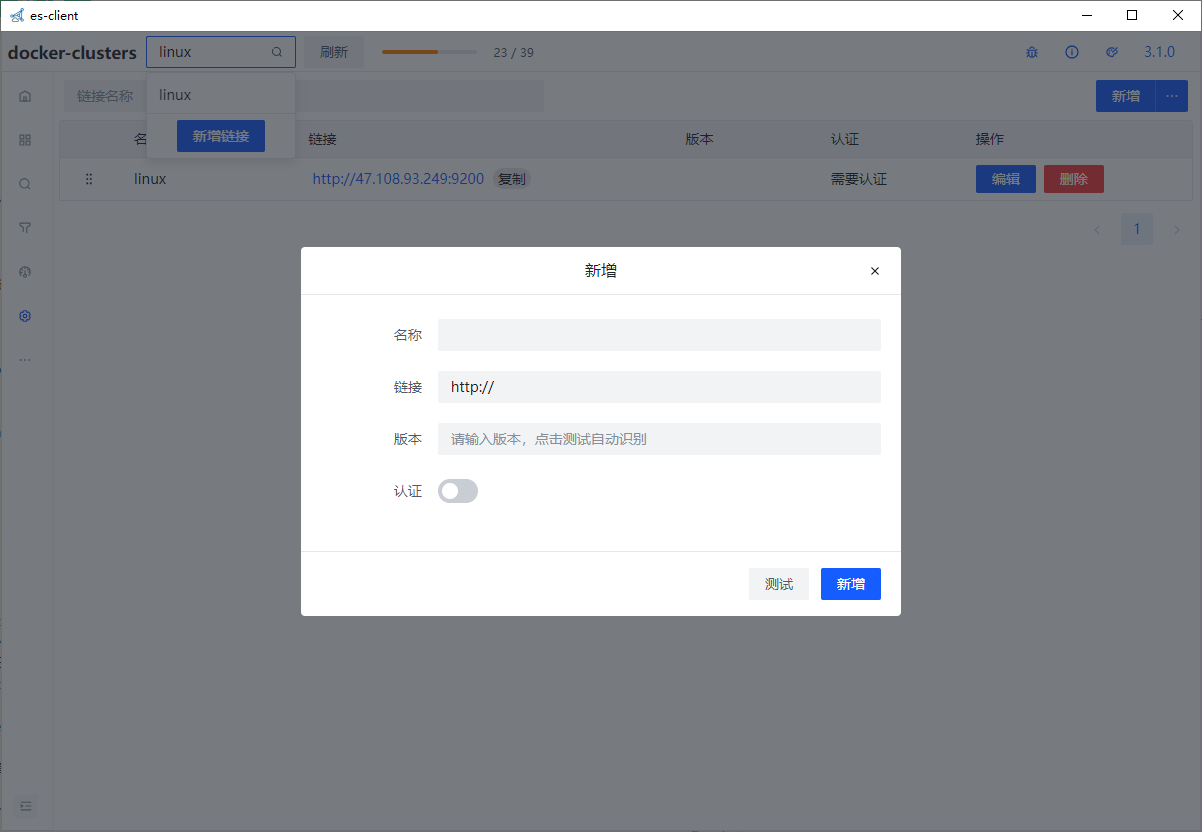
安装成功打开客户端出现以下界面 创建链接
/*
Navicat MySQL Data Transfer
Source Server : manyue
Source Server Version : 50744
Source Host : 47.109.79.147:3306
Source Database : exam
Target Server Type : MYSQL
Target Server Version : 50744
File Encoding : 65001
Date: 2023-12-29 11:08:24
*/
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for QRTZ_BLOB_TRIGGERS
-- ----------------------------
DROP TABLE IF EXISTS `QRTZ_BLOB_TRIGGERS`;
CREATE TABLE `QRTZ_BLOB_TRIGGERS` (
`SCHED_NAME` varchar(120) NOT NULL,
`TRIGGER_NAME` varchar(190) NOT NULL,
`TRIGGER_GROUP` varchar(190) NOT NULL,
`BLOB_DATA` blob,
PRIMARY KEY (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`),
KEY `SCHED_NAME` (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`),
CONSTRAINT `QRTZ_BLOB_TRIGGERS_ibfk_1` FOREIGN KEY (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`) REFERENCES `QRTZ_TRIGGERS` (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ----------------------------
-- Table structure for QRTZ_CALENDARS
-- ----------------------------
DROP TABLE IF EXISTS `QRTZ_CALENDARS`;
CREATE TABLE `QRTZ_CALENDARS` (
`SCHED_NAME` varchar(120) NOT NULL,
`CALENDAR_NAME` varchar(190) NOT NULL,
`CALENDAR` blob NOT NULL,
PRIMARY KEY (`SCHED_NAME`,`CALENDAR_NAME`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ----------------------------
-- Table structure for QRTZ_CRON_TRIGGERS
-- ----------------------------
DROP TABLE IF EXISTS `QRTZ_CRON_TRIGGERS`;
CREATE TABLE `QRTZ_CRON_TRIGGERS` (
`SCHED_NAME` varchar(120) NOT NULL,
`TRIGGER_NAME` varchar(190) NOT NULL,
`TRIGGER_GROUP` varchar(190) NOT NULL,
`CRON_EXPRESSION` varchar(120) NOT NULL,
`TIME_ZONE_ID` varchar(80) DEFAULT NULL,
PRIMARY KEY (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`),
CONSTRAINT `QRTZ_CRON_TRIGGERS_ibfk_1` FOREIGN KEY (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`) REFERENCES `QRTZ_TRIGGERS` (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ----------------------------
-- Table structure for QRTZ_FIRED_TRIGGERS
-- ----------------------------
DROP TABLE IF EXISTS `QRTZ_FIRED_TRIGGERS`;
CREATE TABLE `QRTZ_FIRED_TRIGGERS` (
`SCHED_NAME` varchar(120) NOT NULL,
`ENTRY_ID` varchar(95) NOT NULL,
`TRIGGER_NAME` varchar(190) NOT NULL,
`TRIGGER_GROUP` varchar(190) NOT NULL,
`INSTANCE_NAME` varchar(190) NOT NULL,
`FIRED_TIME` bigint(13) NOT NULL,
`SCHED_TIME` bigint(13) NOT NULL,
`PRIORITY` int(11) NOT NULL,
`STATE` varchar(16) NOT NULL,
`JOB_NAME` varchar(190) DEFAULT NULL,
`JOB_GROUP` varchar(190) DEFAULT NULL,
`IS_NONCONCURRENT` varchar(1) DEFAULT NULL,
`REQUESTS_RECOVERY` varchar(1) DEFAULT NULL,
PRIMARY KEY (`SCHED_NAME`,`ENTRY_ID`),
KEY `IDX_QRTZ_FT_TRIG_INST_NAME` (`SCHED_NAME`,`INSTANCE_NAME`),
KEY `IDX_QRTZ_FT_INST_JOB_REQ_RCVRY` (`SCHED_NAME`,`INSTANCE_NAME`,`REQUESTS_RECOVERY`),
KEY `IDX_QRTZ_FT_J_G` (`SCHED_NAME`,`JOB_NAME`,`JOB_GROUP`),
KEY `IDX_QRTZ_FT_JG` (`SCHED_NAME`,`JOB_GROUP`),
KEY `IDX_QRTZ_FT_T_G` (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`),
KEY `IDX_QRTZ_FT_TG` (`SCHED_NAME`,`TRIGGER_GROUP`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ----------------------------
-- Table structure for QRTZ_JOB_DETAILS
-- ----------------------------
DROP TABLE IF EXISTS `QRTZ_JOB_DETAILS`;
CREATE TABLE `QRTZ_JOB_DETAILS` (
`SCHED_NAME` varchar(120) NOT NULL,
`JOB_NAME` varchar(190) NOT NULL,
`JOB_GROUP` varchar(190) NOT NULL,
`DESCRIPTION` varchar(250) DEFAULT NULL,
`JOB_CLASS_NAME` varchar(250) NOT NULL,
`IS_DURABLE` varchar(1) NOT NULL,
`IS_NONCONCURRENT` varchar(1) NOT NULL,
`IS_UPDATE_DATA` varchar(1) NOT NULL,
`REQUESTS_RECOVERY` varchar(1) NOT NULL,
`JOB_DATA` blob,
PRIMARY KEY (`SCHED_NAME`,`JOB_NAME`,`JOB_GROUP`),
KEY `IDX_QRTZ_J_REQ_RECOVERY` (`SCHED_NAME`,`REQUESTS_RECOVERY`),
KEY `IDX_QRTZ_J_GRP` (`SCHED_NAME`,`JOB_GROUP`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ----------------------------
-- Table structure for QRTZ_LOCKS
-- ----------------------------
DROP TABLE IF EXISTS `QRTZ_LOCKS`;
CREATE TABLE `QRTZ_LOCKS` (
`SCHED_NAME` varchar(120) NOT NULL,
`LOCK_NAME` varchar(40) NOT NULL,
PRIMARY KEY (`SCHED_NAME`,`LOCK_NAME`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ----------------------------
-- Table structure for QRTZ_PAUSED_TRIGGER_GRPS
-- ----------------------------
DROP TABLE IF EXISTS `QRTZ_PAUSED_TRIGGER_GRPS`;
CREATE TABLE `QRTZ_PAUSED_TRIGGER_GRPS` (
`SCHED_NAME` varchar(120) NOT NULL,
`TRIGGER_GROUP` varchar(190) NOT NULL,
PRIMARY KEY (`SCHED_NAME`,`TRIGGER_GROUP`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ----------------------------
-- Table structure for QRTZ_SCHEDULER_STATE
-- ----------------------------
DROP TABLE IF EXISTS `QRTZ_SCHEDULER_STATE`;
CREATE TABLE `QRTZ_SCHEDULER_STATE` (
`SCHED_NAME` varchar(120) NOT NULL,
`INSTANCE_NAME` varchar(190) NOT NULL,
`LAST_CHECKIN_TIME` bigint(13) NOT NULL,
`CHECKIN_INTERVAL` bigint(13) NOT NULL,
PRIMARY KEY (`SCHED_NAME`,`INSTANCE_NAME`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ----------------------------
-- Table structure for QRTZ_SIMPLE_TRIGGERS
-- ----------------------------
DROP TABLE IF EXISTS `QRTZ_SIMPLE_TRIGGERS`;
CREATE TABLE `QRTZ_SIMPLE_TRIGGERS` (
`SCHED_NAME` varchar(120) NOT NULL,
`TRIGGER_NAME` varchar(190) NOT NULL,
`TRIGGER_GROUP` varchar(190) NOT NULL,
`REPEAT_COUNT` bigint(7) NOT NULL,
`REPEAT_INTERVAL` bigint(12) NOT NULL,
`TIMES_TRIGGERED` bigint(10) NOT NULL,
PRIMARY KEY (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`),
CONSTRAINT `QRTZ_SIMPLE_TRIGGERS_ibfk_1` FOREIGN KEY (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`) REFERENCES `QRTZ_TRIGGERS` (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ----------------------------
-- Table structure for QRTZ_SIMPROP_TRIGGERS
-- ----------------------------
DROP TABLE IF EXISTS `QRTZ_SIMPROP_TRIGGERS`;
CREATE TABLE `QRTZ_SIMPROP_TRIGGERS` (
`SCHED_NAME` varchar(120) NOT NULL,
`TRIGGER_NAME` varchar(190) NOT NULL,
`TRIGGER_GROUP` varchar(190) NOT NULL,
`STR_PROP_1` varchar(512) DEFAULT NULL,
`STR_PROP_2` varchar(512) DEFAULT NULL,
`STR_PROP_3` varchar(512) DEFAULT NULL,
`INT_PROP_1` int(11) DEFAULT NULL,
`INT_PROP_2` int(11) DEFAULT NULL,
`LONG_PROP_1` bigint(20) DEFAULT NULL,
`LONG_PROP_2` bigint(20) DEFAULT NULL,
`DEC_PROP_1` decimal(13,4) DEFAULT NULL,
`DEC_PROP_2` decimal(13,4) DEFAULT NULL,
`BOOL_PROP_1` varchar(1) DEFAULT NULL,
`BOOL_PROP_2` varchar(1) DEFAULT NULL,
PRIMARY KEY (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`),
CONSTRAINT `QRTZ_SIMPROP_TRIGGERS_ibfk_1` FOREIGN KEY (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`) REFERENCES `QRTZ_TRIGGERS` (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ----------------------------
-- Table structure for QRTZ_TRIGGERS
-- ----------------------------
DROP TABLE IF EXISTS `QRTZ_TRIGGERS`;
CREATE TABLE `QRTZ_TRIGGERS` (
`SCHED_NAME` varchar(120) NOT NULL,
`TRIGGER_NAME` varchar(190) NOT NULL,
`TRIGGER_GROUP` varchar(190) NOT NULL,
`JOB_NAME` varchar(190) NOT NULL,
`JOB_GROUP` varchar(190) NOT NULL,
`DESCRIPTION` varchar(250) DEFAULT NULL,
`NEXT_FIRE_TIME` bigint(13) DEFAULT NULL,
`PREV_FIRE_TIME` bigint(13) DEFAULT NULL,
`PRIORITY` int(11) DEFAULT NULL,
`TRIGGER_STATE` varchar(16) NOT NULL,
`TRIGGER_TYPE` varchar(8) NOT NULL,
`START_TIME` bigint(13) NOT NULL,
`END_TIME` bigint(13) DEFAULT NULL,
`CALENDAR_NAME` varchar(190) DEFAULT NULL,
`MISFIRE_INSTR` smallint(2) DEFAULT NULL,
`JOB_DATA` blob,
PRIMARY KEY (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`),
KEY `IDX_QRTZ_T_J` (`SCHED_NAME`,`JOB_NAME`,`JOB_GROUP`),
KEY `IDX_QRTZ_T_JG` (`SCHED_NAME`,`JOB_GROUP`),
KEY `IDX_QRTZ_T_C` (`SCHED_NAME`,`CALENDAR_NAME`),
KEY `IDX_QRTZ_T_G` (`SCHED_NAME`,`TRIGGER_GROUP`),
KEY `IDX_QRTZ_T_STATE` (`SCHED_NAME`,`TRIGGER_STATE`),
KEY `IDX_QRTZ_T_N_STATE` (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`,`TRIGGER_STATE`),
KEY `IDX_QRTZ_T_N_G_STATE` (`SCHED_NAME`,`TRIGGER_GROUP`,`TRIGGER_STATE`),
KEY `IDX_QRTZ_T_NEXT_FIRE_TIME` (`SCHED_NAME`,`NEXT_FIRE_TIME`),
KEY `IDX_QRTZ_T_NFT_ST` (`SCHED_NAME`,`TRIGGER_STATE`,`NEXT_FIRE_TIME`),
KEY `IDX_QRTZ_T_NFT_MISFIRE` (`SCHED_NAME`,`MISFIRE_INSTR`,`NEXT_FIRE_TIME`),
KEY `IDX_QRTZ_T_NFT_ST_MISFIRE` (`SCHED_NAME`,`MISFIRE_INSTR`,`NEXT_FIRE_TIME`,`TRIGGER_STATE`),
KEY `IDX_QRTZ_T_NFT_ST_MISFIRE_GRP` (`SCHED_NAME`,`MISFIRE_INSTR`,`NEXT_FIRE_TIME`,`TRIGGER_GROUP`,`TRIGGER_STATE`),
CONSTRAINT `QRTZ_TRIGGERS_ibfk_1` FOREIGN KEY (`SCHED_NAME`, `JOB_NAME`, `JOB_GROUP`) REFERENCES `QRTZ_JOB_DETAILS` (`SCHED_NAME`, `JOB_NAME`, `JOB_GROUP`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ----------------------------
-- Table structure for user
-- ----------------------------
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT 'id',
`name` varchar(20) NOT NULL COMMENT '姓名',
`password` varchar(255) NOT NULL COMMENT '密码',
`phone` varchar(11) NOT NULL COMMENT '手机号',
`salt` varchar(50) NOT NULL COMMENT '盐',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=21 DEFAULT CHARSET=utf8mb4;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









