






AlexNet 是一种经典的卷积神经网络(CNN)架构,在 2012 年的牛津大学计算机视觉组计算机大赛中表现优异,将 CNN 引入深度学习的新时代。AlexNet 的设计在多方面改进了卷积神经网络的架构,使其能够在大型数据集上有效训练。
1. AlexNet 架构概述
Alexnet由8层权重层+3层全连接层组成,其中权重层组合有5层卷积层,3层池化层。
新手友好:
简记(卷——池——卷——池——卷——卷——卷——池——全链接——全链接——全链接)
2. AlexNet 架构细节
为了加深记忆,在下MRS.LEI直接上图好吧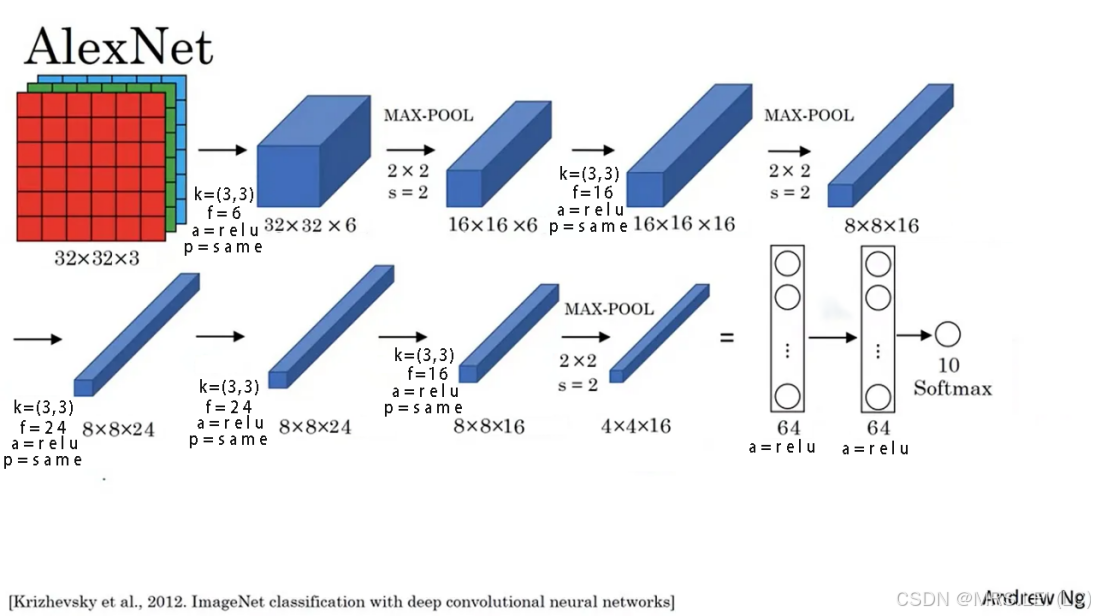
1.输入层:图像尺寸采用32×32×3(宽/高/通道数)。
2.卷积层:卷积核大小(kernel_size)为(3×3),步长(filters)为6,使用激活函数(activation)为relu函数,并使用'same'填充。
3.池化层:最大池化窗口为(2×2),步长(filters)为2。
4.卷积层:卷积核大小(kernel_size)为(3×3),步长(filters)为16,使用激活函(activation)为relu函数,并使用'same'填充。
5.池化层:最大池化窗口为(2×2),步长(filters)为2。
6.卷积层:卷积核大小(kernel_size)为(3×3),步长(filters)为24,使用激活函(activation)为relu函数,并使用'same'填充。
7.卷积层:卷积核大小(kernel_size)为(3×3),步长(filters)为24,使用激活函(activation)为relu函数,并使用'same'填充。
8.卷积层:卷积核大小(kernel_size)为(3×3),步长(filters)为16,使用激活函(activation)为relu函数,并使用'same'填充。
9.池化层:最大池化窗口为(2×2),步长(filters)为2。
10.展平层:Flatten(将数据扩展成一维)
11.全连接层:一共3层,3层数分别64,64,10(或onehot,此处不固定,接下来会讲),以及分别对应的激活函数为relu,relu,softmax(多分类)。
3.AlexNet 的创新之处
ReLU 激活函数的应用:
1.通过使用 ReLU,AlexNet 成功避免了 sigmoid 和 tanh 激活函数可能导致的梯度消失问题,从而加速了训练过程。
重叠池化:
2.重叠池化减小了过拟合风险,使得网络能更好地进行特征提取和层次化表示。
Dropout 正则化:
3.Dropout 的引入在当时是一个非常重要的创新,它通过让神经元随机失活来防止过拟合。
多 GPU 训练:
4.AlexNet 在 GPU 上进行了分布式训练,将不同的卷积层分配到两个 GPU 上,从而加速了计算。
数据增强:
AlexNet 使用数据增强(如随机剪裁、镜像翻转和颜色扰动),进一步增加了训练数据的多样性,减少了过拟合风险。
4.AlexNet 实例应用
上述是关于AlexNet 的一些基本知识点,想必小伙伴们已经开始想跃跃欲试了,那接下来MRS.LEI
带大家上手一些示例项目代码,例如MNIST数据集让大家巩固一遍。
MNIST数据集官网:http://yann.lecun.com/exdb/mnist/
MNIST数据库是非常经典的一个数据集,就像你学编程起初写一个“Hello Word”的程序一样,学Deep Learning你就会写识别MNIST数据集的Model。
MNIST数据集是由0〜9手写数字图片和数字标签所组成的,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。
来,上代码!
(train_x, train_y), (test_x, test_y) = load_data()
print(train_x.shape)
'(60000, 28, 28)'
train_x = train_x.reshape(-1, 28, 28, 1) / 255
test_x = test_x.reshape(-1, 28, 28, 1) / 255
print(train_x, test_x)
'''import numpy as np
from tensorflow.keras import utils
ONE_HOT = len(np.unique(train_y))
train_y = utils.to_categorical(train_y, ONE_HOT)
test_y = utils.to_categorical(test_y, ONE_HOT)
print(train_y, test_y)'''MNIST数据集应被加载并分为训练集和测试集。
自定义训练集测试集,打印出训练集的形状得出(60000,28,28),可得出当前数据集采用的28*28的灰度数据图,随后/255将其标准化,有必要也可将其独热后归一化(如上图注释所示)
**注意**:也会有形状为(50000,32,32),其为彩色数据图
from tensorflow.keras import Model
class AlexNet(Model):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
from tensorflow.keras import Sequential, activations, layers
self.model1 = Sequential([layers.Conv2D(filters=6, kernel_size=(3, 3),
activation=activations.relu, padding='same'),
layers.MaxPooling2D(),
layers.Conv2D(filters=16, kernel_size=(3, 3),
activation=activations.relu, padding='same'),
layers.MaxPooling2D(),
layers.Conv2D(filters=24, kernel_size=(3, 3),
activation=activations.relu, padding='same'),
layers.Conv2D(filters=24, kernel_size=(3, 3),
activation=activations.relu, padding='same'),
layers.Conv2D(filters=16, kernel_size=(3, 3),
activation=activations.relu, padding='same'),
layers.MaxPooling2D()
])
self.model2 = layers.Flatten()
self.model3 = Sequential([layers.Dense(units=64, activation=activations.relu),
layers.Dense(units=64, activation=activations.relu),
layers.Dense(units=ONE_HOT, activation=activations.softmax)
])
def call(self, inputs, training=None, mask=None):
out = self.model1(inputs)
out = self.model2(out)
out = self.model3(out)
return out上图所示为本章要点核心代码,阐述了AlexNet深度学习模型的具体流程,从卷积到池化到展平再到全连接
**注意**:不同的学习模型卷积层数和全连接数以及其他细节不同,这里建议小伙伴们初次还可掌握
其他两种常见模型,VGG16模型、LiNet-5模型。
model = AlexNet()
model.build(input_shape=(None, 28, 28, 1))
model.summary()from tensorflow.keras import optimizers, losses, metrics
model.compile(optimizer=optimizers.Adam(), loss=losses.categorical_crossentropy,
metrics=['acc', metrics.Precision(), metrics.Recall()])
log = model.fit(x=train_x, y=train_y, epochs=5, batch_size=100,
validation_data=(test_x, test_y))上图所示分别为定义编译模型函数,损失函数,指标函数。
编译完模型后,模型应在训练集上进行训练,指定批次大小batch_size和训练周期数epochs
大家记住哦,训练周期次数不宜过多,新手一般5-10次,一次代表运行循环一次,多次非常考验电脑性能,想要尽快可以私下研究一下怎样用GPU运行PYTHON哦。
**注意**:图中使用的优化器是Adam,这里建议小伙伴们初次还可掌握Adagrad、Adadelta
其实关于这三种优化器各有千秋,俗称'挨打三剑客'。
1:Adagrad
此方法能对不常见的参数进行较大的更新,对于常见参数更新较小,不用手动调节学习率
缺点:
因为公式中分母上会累加梯度平方,这样在训练中持续增大的话,会使学习率非常小,甚至趋近无穷小
2:Adadelta
Adadelta是对Adagrad的扩展。
Adagrad会累加之前所有的梯度平方,而Adadelta只累加固定大小的项,并且也不直接存储这些项,仅仅是计算对应的平均值。
Adadelta甚至不用设置默认值。
同样还有一种RMSprop也类似于Adadelta
3:Adam
Adam(Adaptive Moment Estimation)加上了bias校正和momentum,在优化末期,梯度更稀疏时,它比RMSprop稍微好点

那上图所示,大家可以看出是哪个优化器哪个颜色的小球先到五角星吗,嘿嘿,答案是紫色NAG
acc = log.history['acc']
val_acc = log.history['val_acc']
import matplotlib.pyplot as plt
plt.plot(acc, color='r')
plt.show()
plt.plot(val_acc, color='b')
plt.show()
model.evaluate(test_x, test_y)
model.save_weights('model.h5')最后自定义变量给历史准确率,此处有两个哦,一个训练集准确率,一个测试集准确率,最后导入画图函数画出准确率曲线图,看看准确率得分多少,一般0.9以上就比较优异了,然后看个人喜好需求保存一下模型权重就行咯
那最后到这里,不知道大家对AlexNet模型又加深了多少印象呢,也许大家远超出自己预期都已经掌握,自己跃跃欲试了呢!
那今天的分享到此结束,我是MR.LEI,大家下期再见!

















 193
193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









