







本章目标
1.stl的vs的string的内部实现
2.引用计数的写实拷贝
3.编码
1.stl的string的内部实现
我们先来看一个例子
string s1;
cout<<sizeof(s1)<<endl;
我们知道类的内存管理也是遵循内存对齐的规则的.
我们假设当前机器的环境是32位的.string类的内部有三个成员,一个指针,两个是size_t类型的.
那么他们的大小应该是12.
那么实际上真的是这样的吗
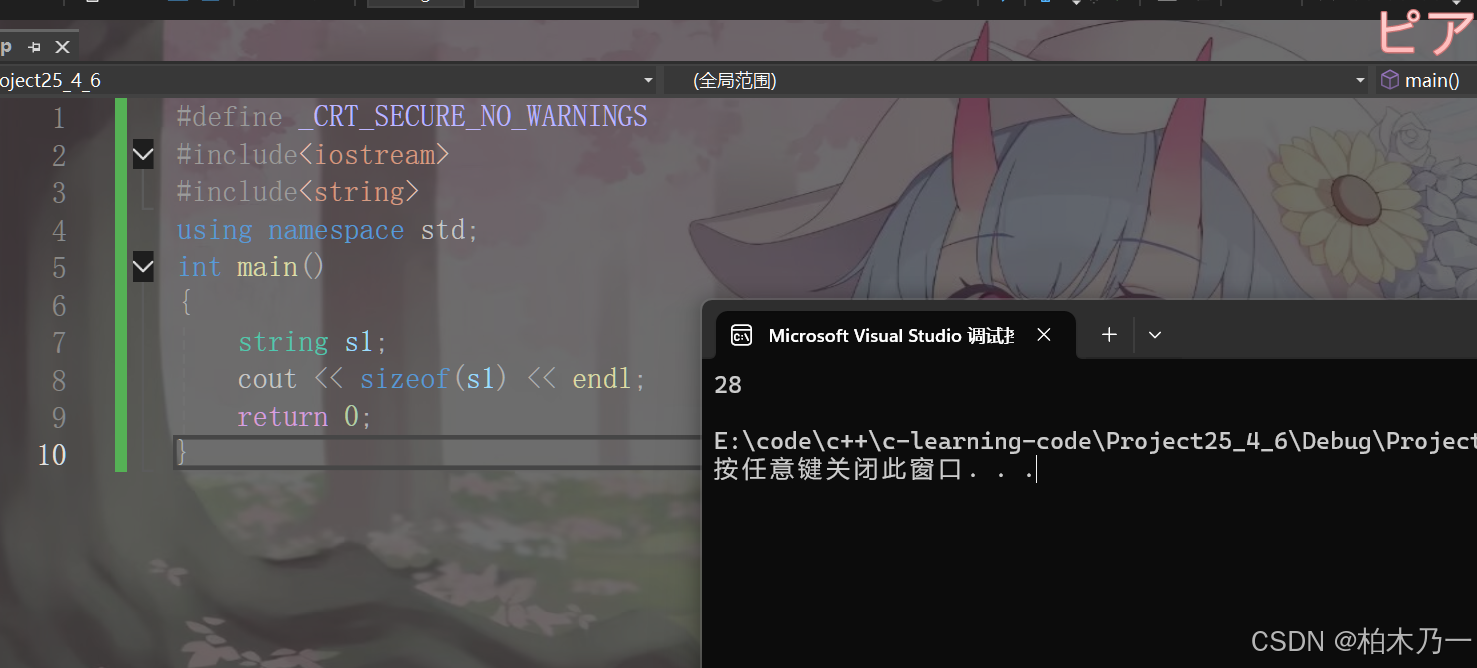
在32位的环境下是28.抛出我们自己算的12,那么多出来的16个字节的空间又是从哪来的呢.
我们进调试看一看
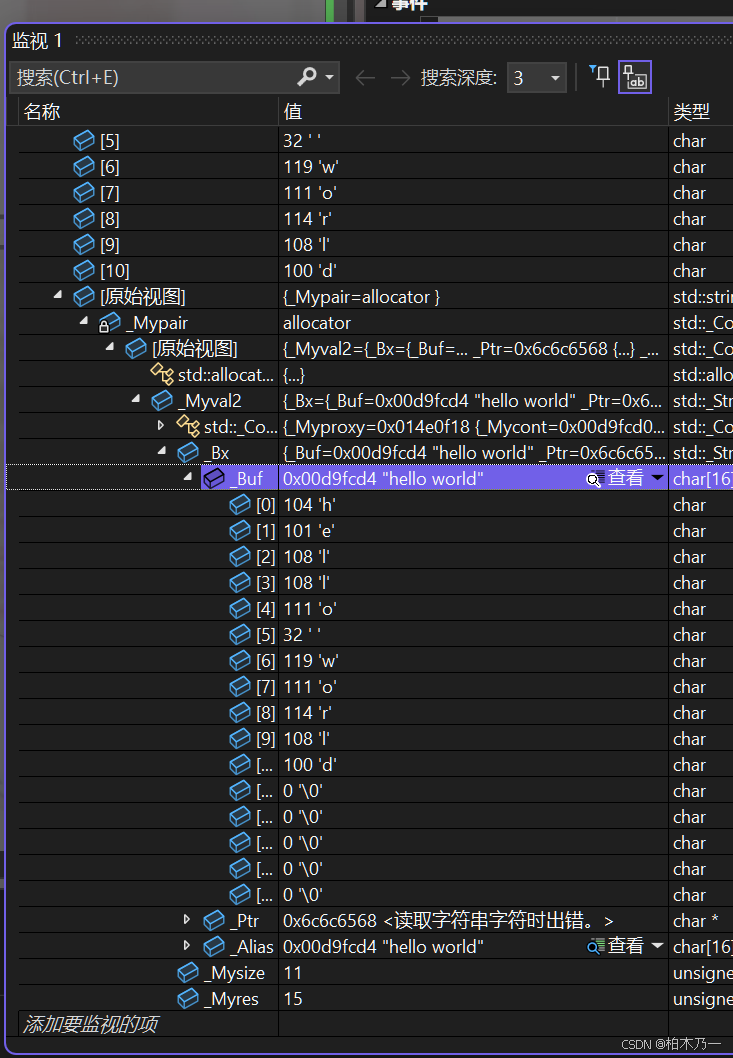
我们给这个字符串一个内容,这个字符串的长度我们已经不能再熟悉了是11字节.
我们点开原始视图,在vs的环境下,它的stl实现的string多了一个buf数组,我们之前多出来的那16个字节的空间,就来自这里,如果当前字符大小小于16字节就会把内容存在这个数组里,我们只需要在实现它的接口的时候,将他们的需要的内容从字符数组中来找即可.
我们不难想象,vs会如此实现,肯定是为了减少内存开销.
因为如果我们用这个buf数组,
1.它是在栈上开辟的空间,相对于堆来说它的读取是更加高效的.
2.同时如果我们的字符大小过小的话, 频繁的用调用new在堆上申请空间,会造成内存碎片的问题.
这是sso技术,短字符优化,是vs对string这个类的一个性能优化.
2.引用计数的写实拷贝
为了提高性能,string的优化各个厂商的实现各不相同,而在gcc的SGI版本的stl的实现则是采用的Copy-On-Write技术(cow),"牛"技术.这门技术说白了就是拖延症产物.
我们先来看一段代码
#include <stdio.h>
#include <string>
using namespace std;
main()
{
string str1 = "hello world";
string str2 = str1;
printf ("Sharing the memory:/n");
printf ("/tstr1's address: %x/n", str1.c_str() );
printf ("/tstr2's address: %x/n", str2.c_str() );
str1[1]='q';
str2[1]='w';
printf ("After Copy-On-Write:/n");
printf ("/tstr1's address: %x/n", str1.c_str() );
printf ("/tstr2's address: %x/n", str2.c_str() );
return 0;
}
这段代码要在早期的gcc的环境下运行,
当我们运行这段程序之后我们会发现,前两个地址是相同的.而在经过修改操作,后面的是不同.
我们不难发现,在这个环境下的拷贝构造,如果我们只读的话,他们就会指向一片空间.
那么这样就会出现两个问题.
1.如果我们的这两个string指向同一块空间,就会引发二次析构.
2.如果我们进行修改的话,改一个,另一个也会进行修改.
为了解决第一个问题.
大佬们提出了引用计数这个概念.同过一个数值进行保存有多少个对象指向这片空间.每次构造,拷贝赋值的时候就让这个数值增加,析构一次就让这个数值减少一次.直到引用计数为0才会真正意义上的析构.
那么就引发出另一个问题,这个引用计数我们去在哪里进行保存.如果我们声明成全局变量,或者静态成员变量.他们一个类就会共同拥有一个引用计数.而在实际应用上,并不是这样的.
string h1 = “hello”;
string h2= h1;
string h3;
h3 = h2;
string w1 = “world”;
string w2(“”);
w2=w1;
对于上面的例子我们就可以看到,h1,h2,h3就指向同一片空间,共同共享同一片内存.而w1,w2又共享同一片内存.显而易见,这两片内存空间他们引用计数是不同的.
而在这里我们可以考虑string的实现,既然它们指向的内存是同一片空间,那么我们就可以在在它们开辟空间的时候,除了给\0多申请一个空间之后再多申请一个空间用来保存引用计数.这个问题就解决了.
到了第二个问题.
为了解决在修改的时候会同时修改其他地方.这时就引用了写实拷贝.只有在修改的时候才会进行深拷贝.
/构造函数(分存内存)
string::string(const char* tmp)
{
_Len = strlen(tmp);
_Ptr = new char[_Len+1+1];
strcpy( _Ptr, tmp );
_Ptr[_Len+1]=0; // 设置引用计数
}
//拷贝构造(共享内存)
string::string(const string& str)
{
if (*this != str){
this->_Ptr = str.c_str(); //共享内存
this->_Len = str.szie();
this->_Ptr[_Len+1] ++; //引用计数加一
}
}
//写时才拷贝Copy-On-Write
char& string::operator[](unsigned int idx)
{
if (idx > _Len || _Ptr == 0 ) {
static char nullchar = 0;
return nullchar;
}
_Ptr[_Len+1]--; //引用计数减一
char* tmp = new char[_Len+1+1];
strncpy( tmp, _Ptr, _Len+1);
_Ptr = tmp;
_Ptr[_Len+1]=0; // 设置新的共享内存的引用计数
return _Ptr[idx];
}
//析构函数的一些处理
~string()
{
_Ptr[_Len+1]--; //引用计数减一
// 引用计数为0时,释放内存
if (_Ptr[_Len+1]==0) {
delete[] _Ptr;
}
}
不过stl中的实现与上面的实现有所不同,stl中的引用计数实在-1这个位置.如果放在最后一个位置的话,如果要在后面追加字符又有了内存开销.
3.编码
编码是信息从一种形式或格式转换为另一种形式的过程,也称为计算机编程语言的代码简称编码。用预先规定的方法将文字、数字或其它对象编成数码,或将信息、数据转换成规定的电脉冲信号,这个方法就是编码机制。
统一码是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
这就是Unicode,万国码.最早的编码表是ascll编码表.它主要的是记录了英文字母以及一些符号.
这对于西方世界已经足够.但是对于汉字这种十几万字的便无法存储.
对于Unicode有以下三种大方案





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









